




让我们深入探讨 Kubernetes 控制器范式如何在大规模上用于支持 Elastic Cloud Serverless服务。
作为我们 Elastic Cloud Serverless服务开发的一部分,我们经历了一次 云架构的重大改造[1]。新的架构让我们可以利用 Kubernetes 生态系统,在全球多个区域的 3 个云服务提供商上提供弹性和可扩展的服务。
早期我们就决定采用 Kubernetes 作为后端编排工具,以运行数百万个Serverless项目容器,同时也作为一个可以轻松扩展的平台,支持各种用例。例如,按需提供新项目、配置带有对象存储账户的 Elasticsearch、以最优性能和成本自动扩展 Elasticsearch 和 Kibana、按需提供快速本地 SSD 卷、资源使用计量、请求认证、在更多区域和集群中扩展集群等等。
许多 Kubernetes 设计原则[2] 指导了我们的这一过程。我们自然地构建了一组遵循 Kubernetes 规范的 API 和控制器,但我们也在更高层次上适应了控制器范式,作为我们在全球范围内协调资源的方式。
实际操作是什么样的呢?让我们深入探讨一些重要方面。
全球控制平面,区域数据平面
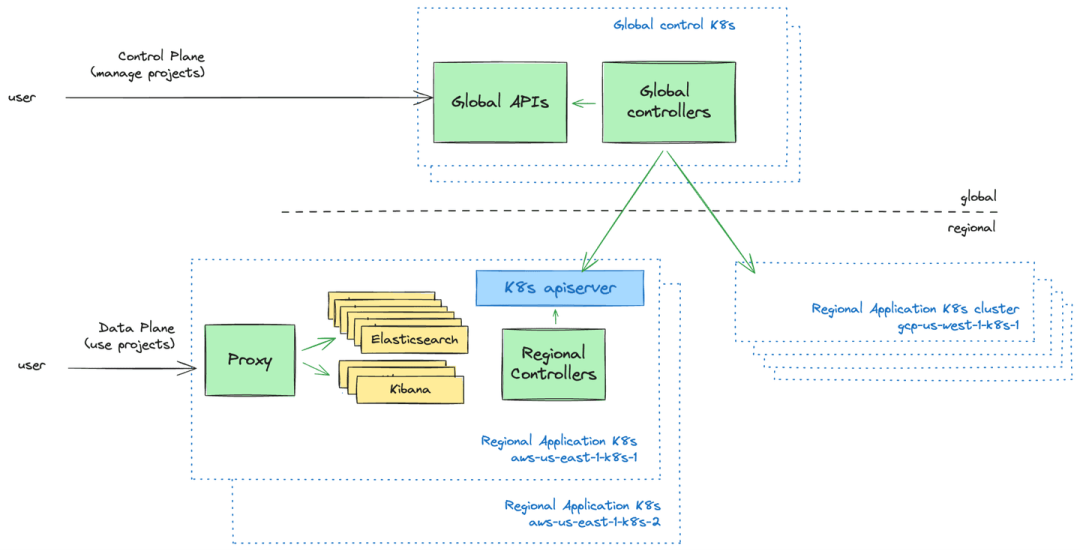
从高层次来看,我们可以区分两个主要组件:
• 全球控制平面服务,负责跨区域和集群的项目全局编排。它还充当调度器,决定哪个区域的 Kubernetes 集群将承载哪个 Elastic Cloud Serverless项目。
• 区域数据平面服务,负责在单个 Kubernetes 集群范围内编排和运行工作负载。每个区域可以由多个 Kubernetes 集群组成,我们将其视为可随时重建的资源。这包括存储在 Kubernetes API 服务器中的资源,这些资源是从全球控制平面状态派生的。
这两个组件都包含各种服务,尽管许多实际上实现为 API 和控制器:
• 在区域数据平面级别,这些服务表现为 自定义资源定义[3] (CRDs),以声明性方式指定系统操控的实体。它们作为自定义资源存储在 Kubernetes API 服务器中,由我们的自定义控制器持续协调。
• 在全球控制平面级别,这些服务表现为 HTTP REST API,将数据持久化在一个全球可用、可扩展且具有弹性的数据库中,并由控制器持续协调这些资源。需要注意的是,尽管它们看起来和感觉像“正常”的 Kubernetes 控制器,但全球控制器从全球 API 和全球数据库中获取输入,而不是从 Kubernetes API 服务器和 etcd[4] 获取输入!
Kubernetes 控制器
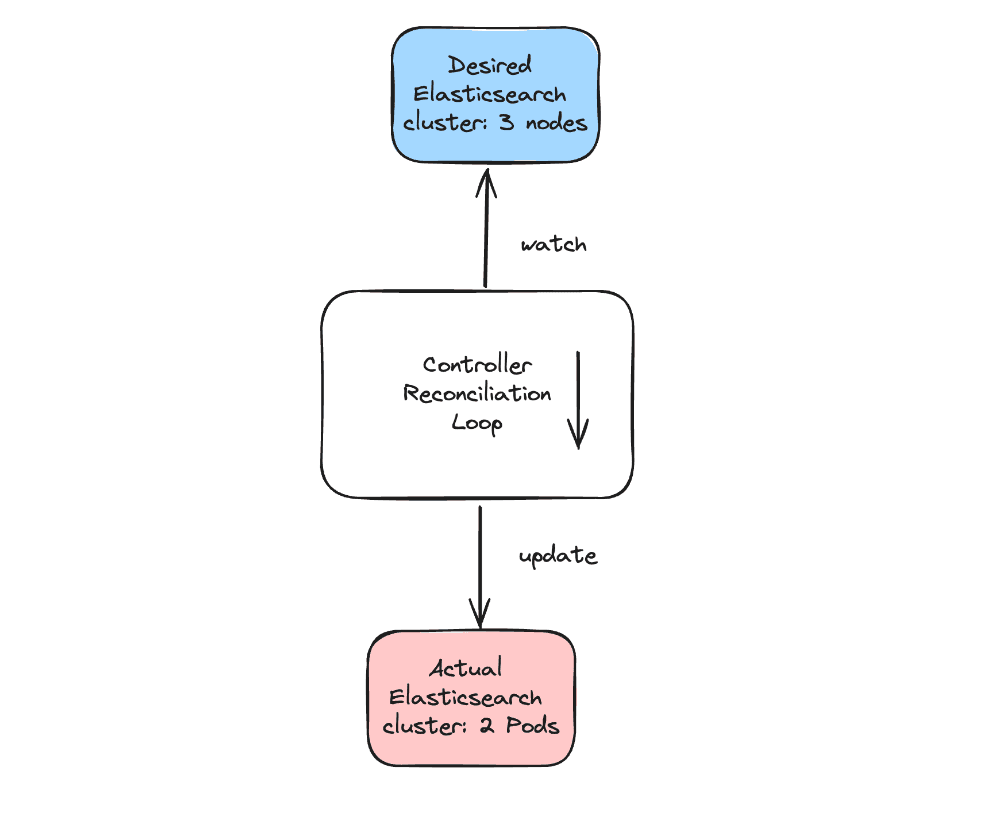
Kubernetes 控制器[5] 以一种简单、可重复和可预测的方式运行。它们被编程为 监视 事件源。在任何事件(创建、更新、删除)发生时,它们总是触发相同的 协调 函数。该函数负责比较资源的 期望状态(例如,一个 3 节点的 Elasticsearch 集群)与该资源的 实际状态(例如当前的 Elasticsearch 集群有 2 个节点),并采取行动使实际状态向期望状态靠拢(增加 Elasticsearch 部署的副本数)。
控制器模式因以下原因便于使用:
• 电平触发范式易于理解。系统中的异步流程始终以向声明的期望状态移动的方式编码,而不管导致该期望状态的事件是什么。这与考虑每个状态变化(配置更改、版本升级、扩展、资源创建等)的边缘触发流程形成对比,有时会导致建模复杂的状态机。
• 它对故障具有弹性,自然导致资源自动自修复和自愈设计。只要能保证处理最新的期望状态,错过中间事件并不重要。
• Kubernetes 生态系统的一部分,controller-runtime[6] 库包含了许多重要技术考虑的抽象,例如与自定义资源交互、高效监视 API 服务器、缓存对象以便廉价读取,并通过工作队列自动排队进行协调,从而轻松构建新控制器。
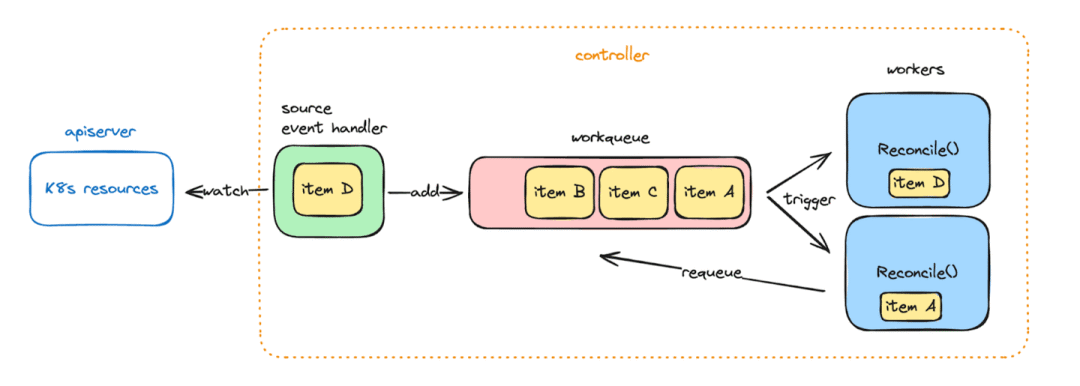
工作队列本身具有一些有趣的特性:
• 项目是去重的。如果一个项目由于连续的监视事件需要被协调两次,我们只需确保至少处理过该对象的最新版本一次。
• 失败的协调可以通过将项目再次添加到同一工作队列中轻松重试。这些重试会自动进行速率限制,并带有指数回退。
• 在控制器启动时,工作队列会自动填充所有现有资源。这确保了所有项目至少被协调过一次,并涵盖了控制器不可用期间错过的任何事件。
全球控制器和全球数据存储
控制器模式及其内部工作队列非常适合我们的区域数据平面控制器的需求。从概念上讲,它也非常适用于我们的全球控制平面控制器!然而,事情在这里变得更加复杂:
1. 作为我们后端设计的一个重要原则,Kubernetes 集群及其存储在 etcd 中的状态应该是一次性的。我们希望具备轻松从头重建和重新填充 Kubernetes 集群的操作能力,而不会丢失重要数据或元数据。这使我们对全球状态数据存储提出了一个强烈要求:在区域故障的情况下,我们希望实现多区域故障转移,并且 恢复点目标[7] (RPO) 为 0,以确保我们的客户数据不丢失。默认情况下,apiserver 和 etcd 并不保证这一点。
2. 此外,尽管区域数据平面 Kubernetes 集群有严格的可扩展性上限(它们 不能增长到我们不希望的程度[8]!),但全球控制平面数据存储中的数据在概念上是无界的。我们希望平台上能够运行数百万个Serverless项目,因此需要数据存储能够随持久化数据和查询负载一起扩展,总数据量可以远大于单台机器的内存量。
3. 最后,全球 API 服务能够与全球控制器监视的完全相同的数据一起工作,并能够提供任意复杂的 SQL 类查询来获取这些数据是很方便的。Kubernetes apiserver 和 etcd 作为键值存储,主要并不是为此用例设计的。
考虑到这些需求,我们决定不将全球控制平面数据持久化在 Kubernetes API 中,而是在一个外部强一致性、高可用和可扩展的通用数据库中。
幸运的是,controller-runtime[9] 允许我们轻松定制触发协调的事件源。通过几行代码,我们就能够将从全球数据存储监视事件的逻辑传递到控制器中。这样,我们的全球控制器代码在很大程度上看起来像常规的 Kubernetes 控制器,但与完全不同的数据存储进行交互。
func setupController(mgr ctrl.Manager, opts controller.Options) error {
// 创建一个新的 controller-runtime 控制器
ctrl, err := controller.New("project-controller", mgr, opts)
if err != nil {
return err
}
// 通过类似 K8s 的事件通道传递数据存储事件
events := make(chan event.GenericEvent)
datastore.Watch(func(change T) {
objectID := change.ID()
// 将项目更改转换为类似 K8s 的通用事件
events <- event.GenericEvent{Object: &Event[T]{ObjectMeta: metav1.ObjectMeta{Name: objectID}}},
})
// 从事件通道触发控制器协调
return ctrl.Watch(
&source.Channel{Source: events},
GenericEventHandler(events)
)
}
func (c *Controller[T]) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
id := ProjectID(req.Name)
err := c.GetProject(id)
// 协调!
}
大规模下的工作队列优化
当全球数据存储中有 200,000 个项目需要在全球控制器启动时协调时会发生什么?我们可以控制协调的并发性 (_MaxConcurrentReconciles=N),以并行处理工作队列,并确保避免同时处理同一项目。
并行度需要仔细考虑。如果设置得太低,处理所有项目将花费很长时间。例如,200,000 个项目,平均每次协调持续 1 秒,且 MaxConcurrentReconciles=1,意味着所有项目将在 2.3 天后才会被处理完。更糟糕的是,如果在此期间创建了一个新项目,可能要等到 2.3 天后才会第一次处理!另一方面,如果 MaxConcurrentReconciles 设置得太高,同时处理大量项目将显著增加 CPU 和 IO 使用量,这通常也意味着增加基础设施成本。全球数据存储能处理 200,000 个并发请求吗?那样会花费多少?
为了更好地应对这种权衡,我们决定将协调分为三个优先级:
1. 需要尽快协调的项目。因为它们最近被创建/更新/删除,并且自那时起从未成功协调过。这些项目属于“高优先级协调”。
2. 至少一次成功协调过的项目。需要再次协调的主要原因是确保控制器中的任何代码更改最终都会通过协调反映在现有资源上。这些项目可以慢慢处理,因为延迟协调不应对客户产生影响。这些项目属于“低优先级协调”。
3. 需要在未来特定时间点协调的项目。例如,为了遵守 30 天的软删除期,或确保每 24 小时轮换一次凭证。这些项目属于“计划协调”。
这可以通过类似 Generation 和 ObservedGeneration 的机制在一些 Kubernetes 资源中实现。在项目规范发生任何更改时,我们会持久化该规范的 修订版(一个单调递增的整数)。在成功协调结束时,我们会持久化成功协调的修订版。要知道一个项目是否值得立即协调,从而放入高优先级队列,我们可以比较两个修订版的值。如果协调失败,则会重新排队进行重试。
type Project struct {
ID string
Revision int64
// ...
Status struct {
LastReconciledRevision int64
}
}
func (p Project) IsPendingChanges() bool {
return p.Revision != p.LastReconciledRevision
}
func (e *PrioritizedEventHandler) Generic(_ context.Context, evt event.GenericEvent) {
project := fromEvent(evt) // 通用监视事件包含整个对象
if project.IsPendingChanges() {
// 高优先级
e.workqueue.Add(reconcileReq)
} else {
// 低优先级
e.workqueue.AddLowPriority(reconcileReq)
}
}
然后,我们可以将控制器协调事件处理逻辑插入到适当的工作队列中。一个单独的低优先级工作队列以固定速率(例如每分钟 300 个项目)异步消费。消费的项目然后被添加到主高优先级工作队列中,由可用的控制器工作线程立即处理。
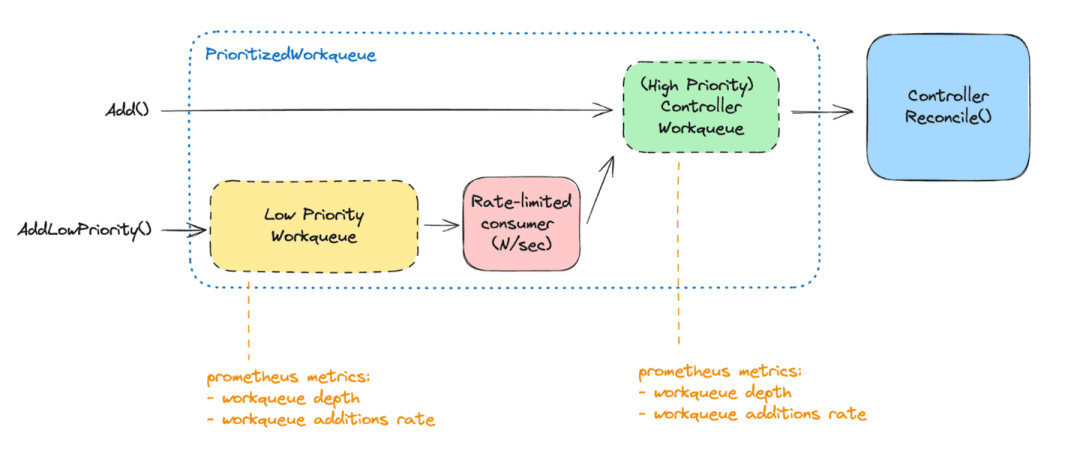
实践中,控制器使用两个不同的工作队列。由于两者都依赖于常规的 controller-runtime 工作队列实现,我们受益于内置的 Prometheus 指标。这些指标允许监控低优先级工作队列的深度,作为控制器启动时仍待协调项目数量的良好信号。同时还能监控高优先级工作队列的添加率,指示我们要求控制器执行的“紧急”工作量。
结论
Kubernetes 是一个迷人的项目。我们从其设计原则和扩展机制中汲取了很多灵感。对于其中一些,我们将其范围扩展到管理单个 Kubernetes 集群中的资源,扩展到能够与高度可扩展的数据存储一起工作,控制器能够协调数千个 Kubernetes 集群中的资源,跨越多个云服务提供商区域。这已被证明是我们在 Elastic 内部平台的一个基本部分,并允许我们每天向 Elastic 用户开发和交付新服务和功能。
请关注未来的技术细节更新。您还可以查看 Elastic 工程师在最近的 Kubecon + CloudNativeCon 2024 上的演讲:
• 使用 Kubernetes 控制器构建大规模多云多区域 SaaS 平台[10]
• 使用 Argo 生态系统进行平台工程:Elastic 的故事[11]。
引用链接
[1]
云架构的重大改造: https://www.elastic.co/search-labs/blog/building-elastic-cloud-serverless[2]
Kubernetes 设计原则: https://github.com/kubernetes/design-proposals-archive/blob/main/architecture/principles.md[3]
自定义资源定义: https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/[4]
etcd: https://etcd.io/[5]
Kubernetes 控制器: https://kubernetes.io/docs/concepts/architecture/controller/[6]
**controller-runtime**: https://github.com/kubernetes-sigs/controller-runtime[7]
恢复点目标: https://en.wikipedia.org/wiki/IT_disaster_recovery#Recovery_Point_Objective[8]
不能增长到我们不希望的程度: https://kubernetes.io/docs/setup/best-practices/cluster-large/[9]
controller-runtime: https://github.com/kubernetes-sigs/controller-runtime[10]
使用 Kubernetes 控制器构建大规模多云多区域 SaaS 平台: https://www.youtube.com/watch?v=AYNaaXlV8LQ[11]
使用 Argo 生态系统进行平台工程:Elastic 的故事: https://www.youtube.com/watch?v=8XzDV3i_vaI
