




参考文档
mysql主从配置及搭建(gtid方式)_mysql gtid-CSDN博客
复制虚拟机
1.修改主机ip
[root@test2 network-scripts]# vi ifcfg-enp0s3
2.修改mysql UUID标识
vi /var/lib/mysql/auto.cnf
systemctl mysql restart
3.修改hostname
hostnamectl set-hostname test1
重新登录
4.添加/etc/hosts
5.vi /etc/my.cnf
修改server-id=5
一、搭建主从-gtid方式
1.0 GTID的工作原理
GTID以事务为单位管理复制,不再需要靠log_file和log_pos来定位复制位置。以下是GTID在主从复制中的工作流程:
当主库提交一个事务时,主库将UUID和最小的非0序列号组成GTID分配给此事务,并将GTID和事务本身写入二进制日志(gtid_log_event),这是一个原子操作,保证GTID和事务内容同时写入日志。
事务提交后很短的时间内,将GTID写入@@global.gtid_executed状态变量。此变量包含了所有已执行的事务,代表了主库的当前状态。
将二进制日志数据传输到从库并存储在从库的中继日志中,从库读取GTID并将其设置为gtid_next系统变量的值,表示从库下一个即将执行的事务。
从库在执行事务前会先进行检查,保证此GTID没有被执行,且当前的没有其他会话读取此GTID。如果有多个会话读取了此GTID,只有1个可以执行,其他的都会阻塞。
如果此GTID未执行过,从库应用此事务,并使用主库生成的GTID,不会重新分配。
如果从库开启了二进制日志(log_slave_updates),则GTID和主库一样通过gtid_log_event原子事件写入自身的二进制日志。
1.1 gtid和二进制的优缺点
使用 GTID 的主从复制优点: 1、简化配置:使用 GTID 可以简化主从配置,不需要手动配置每个服务器的二进制日志文件和位置。 2、自动故障转移:GTID 可以在主从切换时自动识别和处理已复制和未复制的事务,使主从切换更加可靠和快速。 3、避免重复复制:GTID 可以避免主从复制中的重复复制问题,确保每个事务只被复制一次。
使用 GTID 的主从复制缺点: 1、兼容性:GTID 是从 MySQL 5.6 版本开始引入的特性,如果使用旧版本的 MySQL,无法使用 GTID 进行主从复制。 2、系统资源占用:启用 GTID 可能会增加一些系统资源的占用,包括存储和计算资源。
使用二进制日志的主从复制优点: 1、兼容性:二进制日志是 MySQL 自带的特性,从较早的版本开始就支持,可以在各个版本之间进行主从复制。 2、灵活性:使用二进制日志可以根据需要进行更精细的配置,如指定复制的数据库、表,过滤不需要复制的操作等。
使用二进制日志的主从复制缺点: 1、配置复杂:相对于 GTID,使用二进制日志需要手动配置主库和从库的二进制日志文件和位置,配置过程相对复杂。 2、容易出错:配置不当或操作失误可能导致主从复制出现问题,如数据不一致、延迟等。 3、复制延迟:在高写入负载的情况下,从库可能会有一定的复制延迟,导致从库数据相对于主库稍有滞后
1.2 配置主库
1.配置基础数据
mysql> create database test;
Query OK, 1 row affected (0.00 sec)
mysql> use test
mysql> CREATE TABLE test(id INT(2),name VARCHAR(25));
mysql> INSERT INTO test VALUES(1, 'a');
mysql> INSERT INTO test VALUES(2, 'b');
mysql> INSERT INTO test VALUES(3, 'c');
mysql> INSERT INTO test VALUES(4, 'd');
2.配置my.cnf文件
[root@mysql-master ~]# cat /etc/my.cnf | tail -n 4 #可以去掉log-bin和serverid只通过gtid的方式进行主从
log_bin=mysql-bin #开启二进制日志
server-id=1 #用于表示mysql实例在集群中的标识符。必须唯一
gtid_mode=ON #GTID 是一个全局唯一的事务标识符,用于标识数据库集群中的事务。启用 GTID 后,每个事务都会被分配一个唯一的 GTID。
enforce_gtid_consistency=1 #当启用 GTID 后,该选项用于强制要求从库只能复制具有与主库一致的 GTID 链的事务,以确保数据一致性。
[root@mysql-master ~]# systemctl restart mysqld #重启mysql配置文件生效
1.3 创建复制用户
#主库操作
mysql> grant replication slave, replication
-> client on *.* to 'slave'@'192.168.17.%' identified by 'SqlBack@123456';
Query OK, 0 rows affected, 1 warning (0.00 sec)
查看用户权限
show grants for user@'%';
#查看用户
select user from mysql.user;
1.4 备份主库
mkdir /bk
cd /bk
[root@mysql-master ~]# mysqldump -uroot -p123456 test --single-transaction --master-data=2 --flush-logs > `date +%F`-mysql-all.sql
#针对数据库进行备份 #因为是开启了gtid方式进行备份所有sql中没有Master_Log_File和pos位置
[root@mysql-master ~]# scp 2023-06-27-mysql-all.sql root@192.168.17.130:/root
-uroot: 这部分指定了连接数据库时使用的用户名。在这个例子中,使用的是
root用户。-u参数后面紧跟用户名,没有空格。-p123456: 这部分指定了连接数据库时使用的密码。在这个例子中,密码是
123456。-p参数后面直接跟密码(没有空格)是不安全的做法,因为它会在命令历史中留下密码。更安全的方式是使用-p后不加密码,系统会提示你输入密码。test: 这是要备份的数据库的名称。在这个例子中,数据库名为
test。--single-transaction: 这个选项用于在备份时启动一个事务,但不提交它,直到
mysqldump完成。这确保了在备份过程中,数据库的一致性快照被创建,适用于支持事务的存储引擎(如 InnoDB)。这对于备份正在被活跃使用的数据库特别有用,因为它可以避免锁定表。--master-data=2: 这个选项用于在生成的备份文件中包含二进制日志的位置信息(即
CHANGE MASTER TO语句),这对于基于时间点的恢复(PITR)非常有用。=2的意思是包含这些信息,但会注释掉CHANGE MASTER TO语句,以避免在执行恢复时不小心改变主从复制的配置。--flush-logs: 这个选项会在备份开始前刷新 MySQL 的二进制日志和重做日志(如果是 InnoDB 存储引擎)。这有助于确保备份与二进制日志之间的一致性,并可以减小二进制日志文件的大小,因为它们会在备份后被轮换。
`date +%F`这部分指定了备份文件的名称和位置。date +%F是一个命令替换,它会被替换为当前日期的YYYY-MM-DD格式。因此,如果今天是 2023 年 4 月 1 日,那么备份文件的名称将是2023-04-01-mysql-all.sql。>是重定向操作符,用于将mysqldump命令的输出重定向到指定的文件中。
1.5 配置从库
1.配置my.cnf配置文件
[root@mysql-slave ~]# cat /etc/my.cnf | tail -n 4
#log_bin=mysql-bin #从库可以不开启二进制日志
server-id=2
gtid_mode=ON
enforce_gtid_consistency=1
2.重启mysqld
[root@mysql-slave ~]# systemctl restart mysqld
3.导入备份数据
mysql> set sql_log_bin=0; ###禁用二进制日志
mysql> create database test; #因为是恢复单个库。所以需要提前创建好恢复的库
Query OK, 1 row affected (0.00 sec)
mysql> use test
mysql> source /bk/2023-06-27-mysql-all.sql; #恢复数据库
4.配置主从
mysql> change master to
-> master_host='192.168.56.76',
-> master_user='test',
-> master_password='123456',
-> master_auto_position=1; #自动获取二进制的位置
Query OK, 0 rows affected, 2 warnings (0.53 sec)
mysql> start slave;
5.监控信息(解析)
mysql> show slave status\G
*************************** 1. row ***************************
1)主库有关信息(来自master.info)
Slave_IO_State: Waiting for master to send event ##不用管 无用
Master_Host: 192.168.56.76
Master_User: repl_master
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000002 ##从库已经获取到的日志位置点
Read_Master_Log_Pos: 154 ##在主库show master status 是一样的
##flush logs 主从这两参数都会切换
2)从库relay_log应用信息(来自relay.info)
Relay_Log_File: test2-relay-bin.000002 <--- 从库的relay_log对应主库的
Relay_Log_Pos: 367 | 从sql执行哪个relaylog 的
Relay_Master_Log_File: mysql-bin.000002 <---| 哪个号码了
3)从库线程运行状态(排错)
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
4)过滤复制有关
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 154
Relay_Log_Space: 574
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
5)从库延时的时间
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
3)从库线程运行状态(排错)
具体内容要看log-error文件
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 9
Master_UUID: 38677762-c0d1-11ef-ad40-080027206d98
Master_Info_File: /var/lib/mysql/master.info
6)延时从库
可以设置从库延时多少同步主库
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
7) GTID复制的有关信息
Retrieved_Gtid_Set:
Executed_Gtid_Set: 38677762-c0d1-11ef-ad40-080027206d98:1-10
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
6.验证主从{主库操作}
mysql> INSERT INTO test VALUES(5, 'e');
mysql> select * from test.test;
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
5 rows in set (0.00 sec)
7.查询具体错误信息
select * from performance_schema.replication_applier_status_by_worker\G
二、模拟主从不同步(gtid)
1.1 故障描述
#开始模拟:这里我们模拟一个主从复制架构中,从服务器中途异常宕机,不再同步主服务器的场景,假设该情况 #宕机时间较长,数据量较大,GTID无法短时间恢复,并要求不停业务进行数据同步修复,恢复一致
AI助手
1.2 配置测试库
1、#master操作
mysql> create database demon; Query OK, 1 row affected (0.00 sec)
mysql> CREATE TABLE demon.t1( id INT(2) NOT NULL AUTO_INCREMENT, name VARCHAR(255) NOT NULL, age INT(255) NOT NULL, PRIMARY KEY (id) );
2、编写脚本实现重复插入数据
#!/usr/bin/bash
values=find /usr/ -type d | awk -F '/' '{print $NF}' | sort -u
while true do age=$(($RANDOM % 100)) # random随机数 name=$(echo "$values" | shuf -n 1) #随机获取find查到的值 mysql -uroot -p123456 -e "insert into demon.t1(name,age) values ('$name',$age)" #插入到mysql中 sleep $(($RANDOM%5)) #睡眠小于5s之内的数字 done
3、后台运行脚本模拟客户数据
[root@mysql-master ~]# nohup /bin/bash 1.sh &
1.3 模拟从库宕机
#从库操作 mysql> stop slave; #手动停止mysql主从复制 Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM demon.t1;
160 rows in set (0.00 sec) #此时从库有160条数据。主库由于还在执行脚本,数据还在不断插入
1.4 恢复数据
#主库操作 思路: 先通过mysqldump全量备份当前的数据,由于不能影响业务,所以在mysqldump数据时不能造成锁表。要保持数据写入,由于mysqldump时数据还在写入,所以有一部分数据还是会同步不全,所以导入mysqldump的数据后,跳过dump中包含的GTID事务,再重新建立一次主从配置,开启slave线程,恢复数据并同步。
1、主库备份现在的数据。并且不锁表进行备份
mysql> SELECT * FROM demon.t1;
322 rows in set (0.00 sec) #备份前有322条数据
[root@mysql-master ~]# mysqldump -uroot -p123456 demon --single-transaction --master-data=2 > date +%F-mysql-demon.sql
#备份测试库demon
#--master-data=2:生成的备份文件中包含用于主从复制的二进制日志文件名和位置的注释。值为 2 表示将 CHANGE MASTER TO 语句和位置信息添加到导出文件的注释中。
mysql> SELECT * FROM demon.t1;
428 rows in set (0.00 sec) #备份后数据没有影响写入。存在428条记录。
2、从库恢复数据主库依然在写入数据
[root@mysql-master ~]# scp 2023-06-28-mysql-demon.sql root@192.168.17.130:/root #把数据传给从库
#从库操作 mysql> use demon #因为是备份的单个库需要先use到库 mysql> source /root/2023-06-28-mysql-demon.sql #恢复数据 #但是查看主从的结果还是不一致的。需要重新设定主从
source过程中会出现ERROR 1840 (HY000): @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty. 这种报错不用管,不会影响数据的写入。接着往下走。数据正常写入了就OK!!!!! #这个问题是因为备份的时候可能加入了--flush-logs。不影响主从重做和数据写入
1.5 恢复主从
#从库操作 mysql> start slave; #先直接开启主从看看 mysql> show slave status\G Slave_IO_Running: Yes Slave_SQL_Running: No Last_SQL_Error: Could not execute Write_rows event on table demon.t1; Duplicate entry '161' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysql-bin.000002, end_log_pos 27863 #存在报错。需要重新配置主从
1、当前gtid_purged不为空,所以我们要先设置它为空
mysql> show global variables like '%gtid%';
+----------------------------------+--------------------------------------------+
| Variable_name | Value |
+----------------------------------+--------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | ee194423-1405-11ee-a122-000c29b3572a:1-163 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | ee194423-1405-11ee-a122-000c29b3572a:1-163 |
| session_track_gtids | OFF |
+----------------------------------+--------------------------------------------+
mysql> reset master;
#将gtid_purged参数设为空字符
#将gtid_executed设为空字符
#清空mysql.gtid_executed表
Query OK, 0 rows affected (0.00 sec)
mysql> show global variables like '%gtid%';
+----------------------------------+-------+
| Variable_name | Value |
+----------------------------------+-------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
| session_track_gtids | OFF |
+----------------------------------+-------+
8 rows in set (0.00 sec)
2、重置salve
mysql> stop slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> reset slave all;
Query OK, 0 rows affected (0.01 sec)
3、查看主库当前mysqldump导出数据的GTID号
[root@mysql-slave ~]# grep GLOBAL.GTID 2023-06-28-mysql-demon.sql
SET @@GLOBAL.GTID_PURGED='ee194423-1405-11ee-a122-000c29b3572a:1-401';
4、重置后,设置跳过的GTID,并重新同步MASTER
mysql> SET @@GLOBAL.GTID_PURGED='ee194423-1405-11ee-a122-000c29b3572a:1-401'; #从库将跳过指定范围内的 GTID,确保不会重复执行已经在主库上执行过的事务,从而避免数据的重复修改。这样,主从复制可以从当前的 GTID 位置继续进行 Query OK, 0 rows affected (0.00 sec) mysql> change master to -> master_host='192.168.17.129', -> master_user='slave', -> master_password='SqlBack@123456', -> master_auto_position=1; Query OK, 0 rows affected, 2 warnings (0.01 sec)
5、恢复主从线程
mysql> start salve; mysql> show slave status\G Slave_IO_Running: Yes #线程正常 Slave_SQL_Running: Yes
6、查看数据是否正常
mysql> SELECT * FROM demon.t1;
595 rows in set (0.01 sec) #数据和此时的主库条目一致。完美恢复
1.6 清空主从配置
mysql> stop slave; Query OK, 0 rows affected (0.00 sec) mysql> reset master; Query OK, 0 rows affected (0.01 sec) mysql> reset slave all; Query OK, 0 rows affected (0.00 sec) mysql> show slave status; Empty set (0.00 sec)
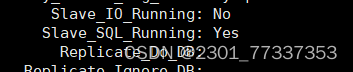
问题1 slave_io_running: no
原因:
在配置主从复制的时候,只安装了一台linux,又克隆了一台,一主一从,关键点就是克隆的,才导致了报Slave_IO_Running: NO
解决方法:
1·使用 find / -iname "auto.cnf" 命令查找你数据库的auto.cnf 配置文件。
find / -iname "auto.cnf"

2.uuid是唯一标识,所以克隆过来的uuid是一样的,只需要修改一下其中一个节点的uuid就可以了

3.修改之后,记得重新启动数据库,两个库都重启
systemctl restart mysqld
service mysqld restart
三、搭建主主-gtid方式
参考文档
https://blog.csdn.net/tb_problem/article/details/143344862
1. 配置 主节点1 my.cnf
主1 10.255.131.9 vim /etc/my.cnf
[mysqld] 中加入以下内容
配置server-id 每个MySQL实例的server-id都不能相同
server-id=9
MySQL的日志文件的名字
log-bin=mysql_master
作为从库时 更新操作是否写入日志 on:写入 其他数据库以此数据库做主库时才能进行同步
log-slave-updates=on 强制开启日志 作从库时同步
同步DML
binlog_format = ROW
开启GTID
gtid-mode = ON
enforce-gtid-consistency = ON
log-slave-updates = ON
多线程复制
slave_parallel_workers = 4
MySQL系统库的数据不需要同步 我们这里写了3个 更加保险
同步数据时忽略一下数据库 但是必须在使用use db的情况下才会忽略;如果没有使用use db 比如create user 数据还是会同步的
replicate-ignore-db=information_schema
replicate-ignore-db=mysql
replicate-ignore-db=performance_schema
replicate-ignore-db=sys
使用通配符忽略MySQL系统库的表 这样在create user时也不会进行同步了
replicate_wild_ignore_table=information_schema.%
replicate_wild_ignore_table=mysql.%
replicate_wild_ignore_table=performance_schema.%
replicate_wild_ignore_table=sys.%
MySQL系统库的日志不计入binlog 这样更加保险了
binlog-ignore-db=information_schema
binlog-ignore-db=mysql
binlog-ignore-db=performance_schema
binlog-ignore-db=sys
2. 配置 主节点2 my.cnf
主2 10.255.131.10 修改my.cnf, 只需要修改其中的两个地方,其他内容一样
配置server-id 每个MySQL实例的server-id都不能相同
server-id=10
MySQL的日志文件的名字
log-bin=mysql_slave
my.cnf文件修改完成后,重启mysql
systemctl restart mysql
3. 配置主主
主主模式就是配置两个主从。
10.255.131.9(主)->10.255.131.10(从)
10.255.131.10(主)->10.255.131.9(从)
1) 配置主1 10.255.131.9
先登录10.255.131.9(主1)的数据库,依次执行如下命令:
#创建备份的账号 使用MYSQL_NATIVE_PASSWORD的方式加密
create user 'repl_master'@'%' identified by '123456';
对repl_master授予备份的权限
grant replication slave on *.* to 'repl_master'@'%';
刷新权限
flush privileges;
2) 配置从1 10.255.131.10
登录到10.255.131.10(主2) 中,执行如下命令:
mysql> CHANGE MASTER TO
MASTER_HOST='10.255.131.10',
MASTER_USER='repl_master',
MASTER_PASSWORD='123456',
MASTER_PORT=3306,
MASTER_AUTO_POSITION = 1; ##读取relaylog最后一个事务的GTID
mysql> START SLAVE;
mysql> SHOW SLAVE STATUS\G;
这样,
10.255.131.9(主1)->10.255.131.10(主2)的主从就搭建好了。
3) 配置主2 10.255.131.10
然后,我们再反过来,搭建
10.255.131.10(主2)->10.255.131.9(主1)的主从。
登录10.255.131.10(主2)的数据库,依次执行如下命令:
#创建备份的账号 使用MYSQL_NATIVE_PASSWORD的方式加密
create user 'repl_slave'@'%' identified by '123456';
对repl_slave授予备份的权限
grant replication slave on *.* to 'repl_slave'@'%';
刷新权限
flush privileges;
查看MySQL主节点的状态
show master status;
binlog文件的名字,mysql_master.000001,和位置,也就是830。
4) 配置从2 10.255.131.9
登录到10.255.131.9(主1),执行如下命令:
mysql> CHANGE MASTER TO
MASTER_HOST='10.255.131.9',
MASTER_USER='repl_slave',
MASTER_PASSWORD='123456',
MASTER_PORT=3306,
MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;
mysql> SHOW SLAVE STATUS\G;
4. 验证
由于上述的my.cnf中将创建用户,创建表的行为给屏蔽同步了。
注释相关代码后 重启,发现在10.255.131.9上执行的创建用户与表的动作;
10.255.131.10上已经同步过去了。
此外创建分区并不会导致同步的报错以及异常;
CALL P_ADD_TAB_PARTITION_THAT_VERY_DAY(‘MON_DATA_CUR’);
两台服务器均正常创建了今天的分区;
5. 同步问题排查以及恢复
1) 查看同步状态
同步状态是否正常可通过sql查询;
mysql> show slave status\G;
以下两个属性均为yes;说明同步状态正常
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
如果有任何为No,可以查询Last_SQL_Error上次同步失败的sql;如何恢复,请看5.4
2) 查看同步是否数据一致性,延迟多少
mysql> show slave status\G;
Seconds_Behind_Master: 为0说明数据同步完成,这个属性表示的是从库同步主库的延迟时间,单位秒;
3) 过滤掉常见错误
常见的有1032错误码;
binlog中变更的那行在表中不存在,导致主从失败; 该错误很常见,可屏蔽
my.cnf可配置slave-skip-errors=1032
重启mysql,就可以跳过日志中的1032错误码
也可以配置
跳过所有错误 slave-skip-errors=all
4 ) 同步失败如何恢复
如果主库有个错误的sql执行导致报错,或者主从库数据结构不一致等原因导致同步报错;
这种情况如何恢复同步呢;
基本上就这三步;
mysql> stop slave;
mysql> reset slave;
mysql> start slave;
如果起不来可能是binlog记录的位置不一致。这时候reset slave下再重启;
复杂的错误导致数据不一致的情况
全量同步 可以采取删除从库数据库,主库锁库只读。然后全量备份再恢复到从库中,再建立主从同步的链接,以此来恢复。
锁表:FLUSH TABLES WITH READ LOCK;
解锁:UNLOCK TABLES;
跳过部分错误(没啥用)
mysql>stop slave ;
~~mysql>SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1;~~跳过一个事务
mysql>start slave;
对于复杂的报错无法解决的时候如果同步并恢复主从呢 在此举例主从,主主的模式一样,就是操作两遍。
首先从数据库停止同步;并删除主从连接配置信息
mysql> stop slave;
mysql> reset slave all;
主数据库中删除binlog,重新记录binlog
mysql> reset master;
借助工具,手动的同步两个数据库,主数据库数据同步到从数据库中;Navicat,SQLyog 均可,好用。
从数据库上建立连接GTID
mysql> CHANGE MASTER TO
MASTER_HOST='10.255.131.9',
MASTER_USER='repl_master',
MASTER_PASSWORD='123456',
MASTER_PORT=3306,
MASTER_AUTO_POSITION = 1;
启动从库同步;
mysql> start slave;
这样就可以恢复主从的同步了。
这是没法通过 reset slave; 恢复同步时候的实用的解决方式,要注意mysql同步之前最好做下必要的备份,防止数据丢失。
总之数据库的同步是一个复杂的情况,如果生产上发现同步异常,数据库数据不一致等情况,可以找专业DBA。
6.延时从库配置
stop slave;
CHANGE MASTER TO MASTER_DELAY = 300; ###秒为单位 此处是5分钟
start slave;
四、GTID存在的问题
问题1
参考文档
https://blog.csdn.net/u013810234/article/details/109248066
Background 在主库上删除了一个数据库用户后,从库不同步了。。
mysql> SHOW SLAVE STATUS\G查看从库状态,可以看到SQL线程已停止,同时报错:
Last_SQL_Errno: 1396
Last_SQL_Error: Error 'Operation DROP USER failed for 'prod'@'%'' on query. Default database: ''. Query: 'drop user prod@'%''
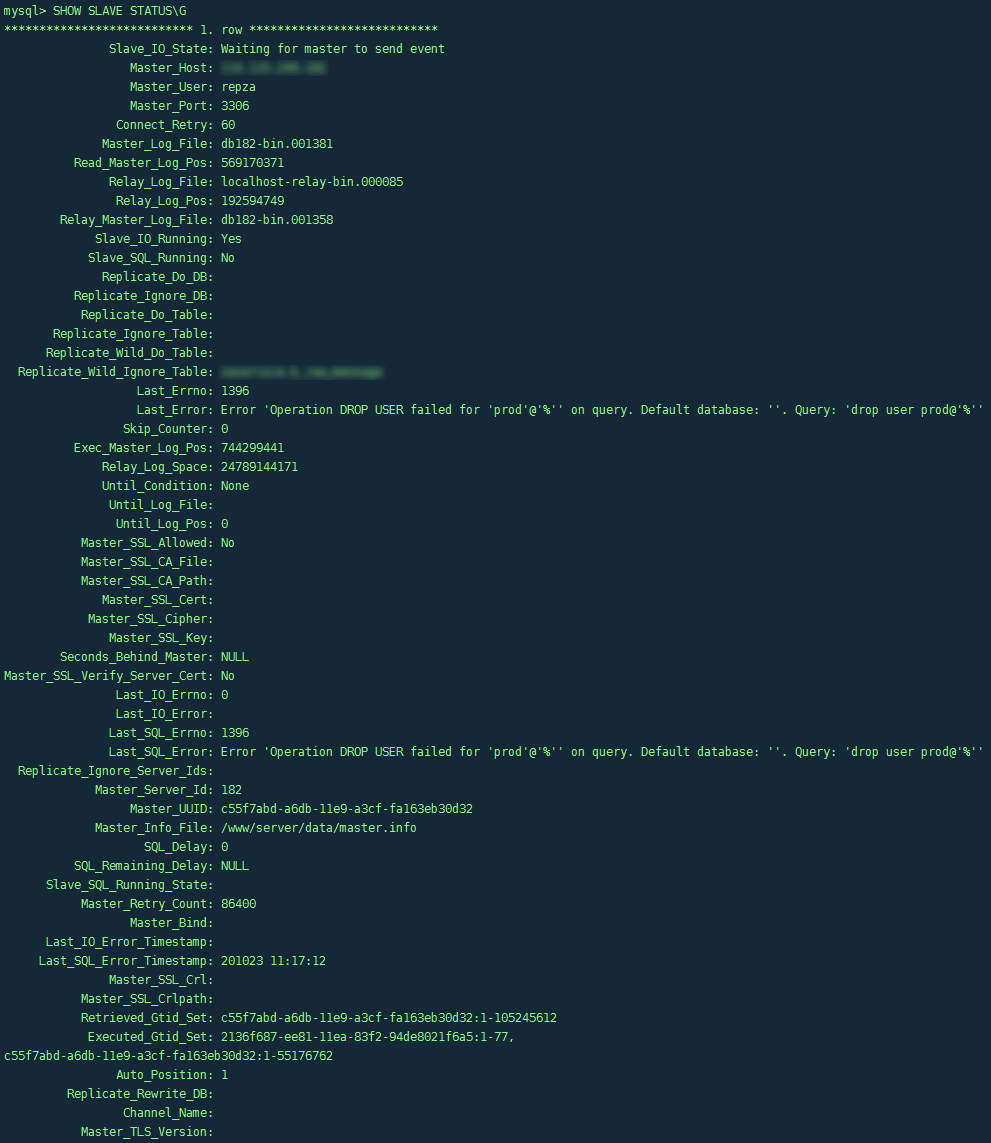
莫名其妙,进行主从同步的数据库根本没有包含数据库用户相关的数据库、表,主库删除用户怎么会导致从库同步报错呢??
Solution 现在,主从数据不一致了,考虑从库的查询会影响到线上业务,来不及分析,先跳过这个错误再说。
1.跳过一类错误 这种方式,简单粗暴,可以解决问题。
修改MySQL从库的配置文件
vi /etc/my.cnf
配置跳过当前的错误类型
slave_skip_errors=1396
重启从库服务
service mysqld restart
跳过一条或N条报错信息 若使用的传统的指定MASTER_LOG_POS的同步方式,可在从库执行以下命令,跳过一条错误即可
STOP SLAVE;
SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
START SLAVE;
SHOW SLAVE STATUS\G
若使用的是GTID的同步方式,则上述命令会报错:
2.跳过一条或N条报错信息 若使用的传统的指定MASTER_LOG_POS的同步方式,可在从库执行以下命令,跳过一条错误即可
若使用的是GTID的同步方式,则上述命令会报错:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.00 sec)
mysql> SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
ERROR 1858 (HY000): sql_slave_skip_counter can not be set when the server is running with @@GLOBAL.GTID_MODE = ON. Instead, for each transaction that you want to skip, generate an empty transaction with the same GTID as the transaction
这时候,即在GTID同步方式时,如果从库同步错误,如何跳过这个错误呢?
这时候,即在GTID同步方式时,如果从库同步错误,如何跳过这个错误呢?
先查看SHOW GLOBAL VARIABLES LIKE '%GTID%';
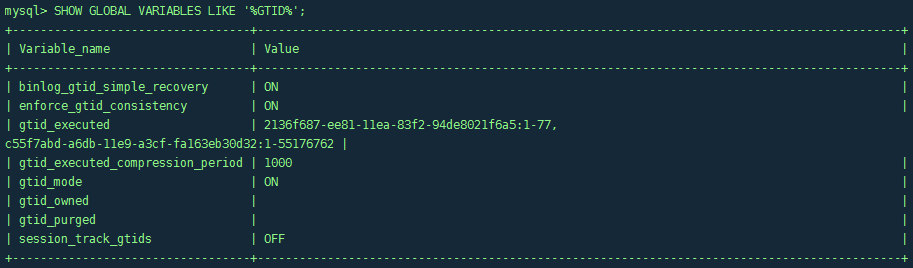
可以看到其中gtid_executed的值与SHOW SLAVE STATUS\G执行结果中的值一致,记录下来这个值。
Note: 这里的gtid_executed的值有两个,是由于其他操作导致,此处忽略,我们以后一个为准。
在从库执行以下命令:
#重置master, slave
```
RESET MASTER;
STOP SLAVE;
RESET SLAVE;
```
#重新设置GTID
SET GLOBAL GTID_PURGED='c55f7abd-a6db-11e9-a3cf-fa163eb30d32:1-55176762';
(原文中是标记为前面的值+1,但是+1我没成功,原值成功了)
#重新配置执行的master
CHANGE MASTER TO MASTER_HOST='YOURIP',MASTER_PORT=3306,MASTER_USER='YOURNAME',MASTER_PASSWORD='YOURPASSWORD',MASTER_AUTO_POSITION = 1;
#启动从库同步
START SLAVE;
#查看同步状态
SHOW SLAVE STATUS\G
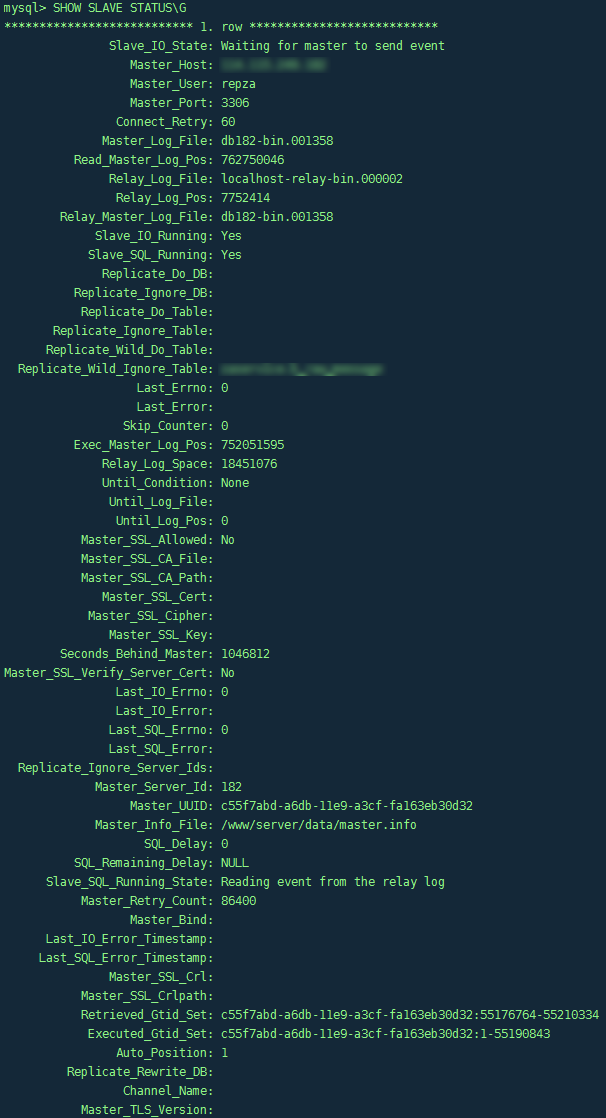
Analysis 仔细回想一下删除用户前后的操作流程:
一开始,一直在sync-db的employee表(即使用了USE employee)中做一些查询操作; 然后,执行了DROP USER prod@'%'; 接着,就出事了,从库报错,不同步了。。 其实,我们在搭建主从时,配置了binlog-do_db=sync-db,那么,为什么对主库mysql数据库的操作会在同步的从库sync-db中执行呢? 原来,问题就出在我们在执行DROP USER时,未使用 USE mysql;语句(执行DROP USER不需要进入mysql系统数据库,也可以执行成功); 然而,MySQL的机械地认为DROP USER操作我们是在USE employee之后执行的,所以认为是针对employee数据库的操作,便执行了同步,而从库中根本不存在prod@%这样的用户,所以便报错,导致主从同步中断。
Summary 在数据库中操作时,一定要注意当前所在的数据库是哪个,作为一个良好的实践:在SQL语句前加USE dbname。
操作不规范,亲人两行泪…
五、传统主从复制搭建
1)2个以上的数据库实例
2)主库需要开启二进制日志
3)server_id 不同,区分不同节点
4)主库建立专用的复制用户(replication slave)
5)从库应该通过备份主库,恢复的方法进行‘补课’
6)人为告诉从库一些复制信息(ip port user passwd,二进制日志起点)
7)从库开启专门的复制线程
1.配置主my.cnf
server_id=7
log_bin=mysql-bin ###或者指定路径log_bin=/data/mysql-bin
2.配置从my.cnf
server_id=8
log_bin=mysql-bin ###或者指定路径log_bin=/data/mysql-bin
3.主 创建复制用户
grant replication slave on *.* to 'repl'@'192.168.56.%' identified by '123456';
4.主库备份
生产中不用备份 可以用之前最近的一次时间点的备份
全备
mysqldump -uroot -p123456 -S /tmp/mysql.sock -A --single-transaction --master-data=2 -R -E --triggers > `date +%F`-mysql-all.sql
5.恢复从库
mysql> set sql_log_bin=0;
mysql> source /bk/xxx.sql
6.从库搭建主从复制
help change master to ##可以查看所有的 参数
vi 备份文件
查找这句
/CHANGE MASTER
找到的master_log_file和master_log_pos在下面语句输入
change master to
master_host='192.168.33.55',
master_user='snails',
master_password='snails',
master_port=3306,
master_log_file='mysql-bin.000001',
master_log_pos=1254;
master_connect_retry=10 ##允许重新连接的次数 这条不加
7 开启复制线程
从
start slave
8.检查状态
从
show slave status\G
六、传统主从复制问题
1.主从复制IO线程故障
1)从库:
IO 线程故障
连接主库
网络
连接信息错误或变更了
防火墙(端口)
连接数上限
排错方法:用复制用户连接
解决:
1.stop slave;
2.reset slave all;
3.change master to
4.start slave
2)请求binlog
binlog没开
binlog 损坏,不存在
reset master
解决方法:
查看主从binlog点
stop slave
reset slave all
重新设置change master to
start slave
3)存储binlog到relay_log
设置权限
stop
start
2.sql线程故障
把握一个原则,一切以主库为主
1.relay-log损坏
2.如果在从库 误操作(建表、插入数据什么的)
解决:1.stop slave
优先在从库进行反操作
start slave
2.或者 直接重新搭建主从
3.主从操作结构一致的前提下可以进行跳过错误
stop slave
set global sql_stave_skip_couter=1
start slave
或者
在my.cnf
加入slave-skip-errors = 1032,1062,1007
常见错误:
1007 对象已存在
1032 无法执行DML
1062 主键冲突,或约束冲突
3.主键冲突问题
在从库执行了主键插入
主库update 修改
跳过
stop slave
set global sql_stave_skip_couter=1
start slave
3.避免上述问题
1.从库只读
show variables like '%read_only%';
在my.cnf中加入
read_only = on
super_read_only = on
2.使用中间键读写分离
atlas
mycat
proxysql
maxscale
4.主从延时监控及原因
1)主库方面
1.binlog 写入不及时
没设置sync_binlog=1 ##每次binlog及时写入磁盘
2.默认情况下dump_t 是串行(每个事务一个个传,不能同时并行)传输binlog
在并发事务量大或者大事务,由于dump_t 是串行工作的 导致传输速度慢,导致主从延时
解决:
必须GTID,使用Group commit方式,可以支持DUMP_T并行操作
5.延时从库逻辑故障处理
主库
create database test
use test
create table test(id int);
insert into test values(1),(2)
drop database test
七、主从切换
参考文档:
https://blog.csdn.net/weixin_43816711/article/details/134779989
1.切断应用对主库的流量 2.主库从库设置只读
mysql> set global read_only=on
mysql> set global super_read_only=on
3.查看从库复制进程状态
show slave status\G #确认从库已复制完成

4.对比两边GTID是否一致
mysql> select @@global.gtid_executed;
+------------------------------------------+
| @@global.gtid_executed |
+------------------------------------------+
| abc82989-c104-11ef-a12e-0800271b8b7c:1-6 |
+------------------------------------------+
1 row in set (0.00 sec)
5.确认是否真的同步完成
mysql> show processlist;


6.从库停掉复制进程并清空主从信息
mysql> stop slave;
Query OK, 0 rows affected (0.01 sec)
mysql> reset slave all;
Query OK, 0 rows affected (0.01 sec)
7.从库关闭只读开启读写,转为新主库
mysql> set global read_only=off;
Query OK, 0 rows affected (0.01 sec)
mysql> set global super_read_only=off;
Query OK, 0 rows affected (0.01 sec)
8.主库设置执行新主库复制链路,转为新从库,完成主从切换
mysql>change master to
master_host='',
master_port= ,
master_user='',
master_password='',
master_auto_position=1;
Query OK, 0 rows affected (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
mysql> show slave status\G
9.应用流量切向新主库
