




数据拯救是专业DBA绕不开的一个话题,当数据库遇到正常途径无法开库、备份失效或干脆没有备份、常规方式已无法恢复等极端情况时,想要获取原数据库中的数据,唯一可行的手段就是直接对数据文件进行抽取。
极端场景下的数据拯救也是各种数据库的生态中重要的一环。在此类场景中,Oracle可以用odu/dul直接对数据文件或者ASM磁盘进行数据提取;Postgresql也有生态中的pg_filedump工具可以在知道表结构的情况下对单表进行挖掘。
而openGauss虽然是基于Postgresql 9.2进行重构,但是由于数据页的结构存在差异、TOAST表不严格按照seq排序等原因,pg_filedump这款工具是没有办法用于openGauss的。
经过很长一段时间的开发与验证,我终于可以向各位介绍这款面向openGauss系数据库的数据拯救工具——pdu。
首先让我们明确pdu的使用场景:在无法使用备份进行恢复,且数据文件的一致性被破坏,无法通过gs_ctl start起库的情况下,可使用pdu工具直接从数据文件中进行数据抽取,是用于极端场景下的数据恢复手段,为用户的数据安全提供最后一道屏障。
pdu工具由两部分组成,pdu可执行文件+PGDATA.ini配置文件,整体的设计理念就是降低使用者的学习成本。
--------使用指南 起始位置--------
1、配置PGDATA路径
用户只需要在PGDATA.ini中配置数据目录所在的路径即可,无需其他配置。

2、Bootstrap 初始化
路径配置完成后,执行./pdu,即可进入使用界面。


3、Use Database/Set Schema 指定数据库与模式
初始化完毕后的使用方式参考了openGauss本身gsql客户端的使用逻辑,用户在抽取数据之前首先需要指定当前的Database与Schema。

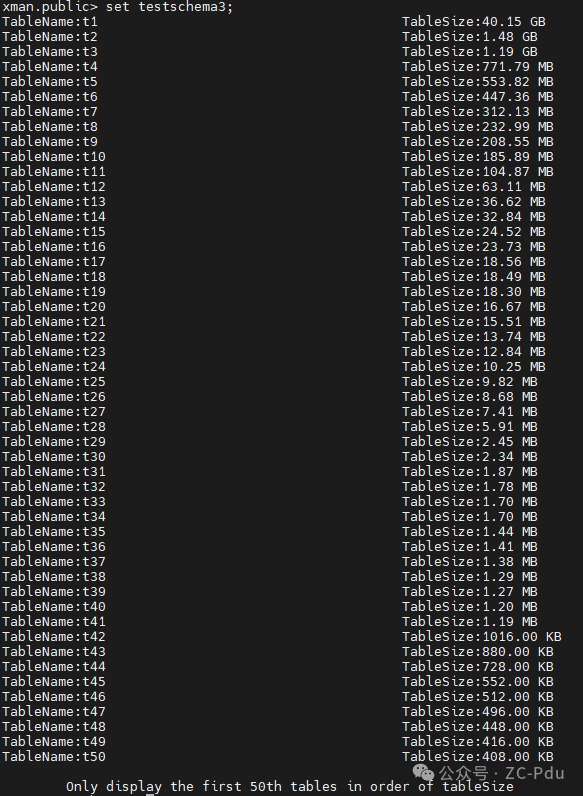





--------使用指南 结束位置--------

数据类型方面,当前支持的数据类型如下,_前缀表示一维数组类型:
smallserial、tinyint、smallint、int、oid、xid、bigint、bigserial
time、timetz、date、timestamp、timestamptz
real、float4、float8、bool、numeric、number
name、char、charn、varchar、varcharn、varchar2、text、json、xml、blob
_int4、_text、_varchar、_float4、_float8、_timestamp
不支持解析加密过的数据;
BLOB类型的16进制数据会被直接解析为字符串;
对于表对象数量xx的大库初始化较慢;
不支持并行解析表
...
本次发出的版本不对数据抽取做任何限制,包含当前的所有功能和数据类型,仅存在有效期的限制。
希望大家在使用的过程中可以反馈一些意见和建议,应该也会有很多我没测出的bug,希望大家多多包涵🌝。以及大家如果能想到一些有意义发但是当前没有的功能也可以在公众号中私信我。
--在文章的结尾特别感谢我的女朋友在计算机底层专业知识上给予我的帮助❤
