





想学会更多实用技巧,欢迎加入青学会MOP技术社区(实名社区)。
加入方法:公众号后台回复关键字“加入”获取小助手微信,添加后登记入会。
同时欢迎大家在评论区留言互动交流!社区会不定期举行相关的抽奖、公开分享活动。
如果你有想了解的知识点希望我们发文可以后台私信。
正文开始
分区表的概念
分区表是数据库中的一种表设计方式,它将表的数据分割成多个,称之为分区的逻辑存储单元。每个分区可以独立管理,包括存储、备份、维护和查询,从而提高了更高效的数据管理和查询性能。
通俗来说,就是当表中的数据不断地增大时,查询速度就会变得非常慢,应用程序的性能就就会下降,这个时候就应该考虑对表进行分区。表进行分区以后,逻辑上仍然是一张完整的表,只是将表里的数据在物理上存放到多个表空间中,这样在查询数据时,就不用每次查询都进行整张表的扫描,提高了查询速度。
分区表的好处
l 性能提升:查询和维护特定分区的数据比全表扫描快
l 数据管理:容易管理大量数据,可以针对特定的分区进行备份、恢复和数据清理
l 查询优化:数据库优化器可以根据分区键进行优化查询计划
l 维护方便:如果表的某个分区出现故障,需要修复数据,只需要修复该分区即可
l 增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用。
分区表的种类
分区表包含:
范围分区表:分区数值按照选定的一个范围的值进行分区(例如时间范围)
列表分区表:分区数值按照一个离散的数值进行分区(例如部门的名称)
哈希分区表:数据根据哈希算法进行均匀分布分区
复合分区表:由上面三种分区表的类型组合成的二级分区表
由于语法树较为晦涩,下面直接从给的用例中进行学习和理解
范围分区表
CREATE TABLE range_tab1(
i INT,
j NUMBER,
f VARCHAR2(20),
k VARCHAR2(20)
)PARTITIONBYRANGE(j)
(
PARTITION p1 VALUESLESSTHAN(10),
PARTITION p2 VALUESLESSTHAN(20),
PARTITION p3 VALUESLESSTHAN(30),
PARTITION p4 VALUESLESSTHAN(40),
PARTITION p5 VALUESLESSTHAN(50),
PARTITION p6 VALUESLESSTHAN(MAXVALUE)
);
INSERTINTO range_tab1 VALUES(1,1,'p1','p1');
INSERTINTO range_tab1 VALUES(10,10,'p2','p2');
INSERTINTO range_tab1 VALUES(21,21,'p3','p3');
INSERTINTO range_tab1 VALUES(31,31,'p4','p4');
INSERTINTO range_tab1 VALUES(41,41,'p5','p5');
INSERTINTO range_tab1 VALUES(51,51,'p6','p6');
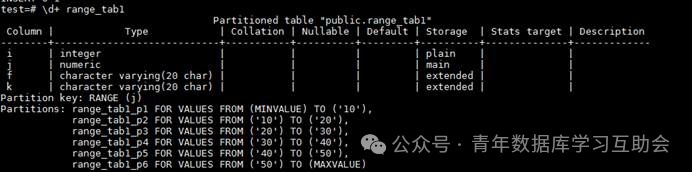
上面是一个简单的范围分区表的案例,表range_tab1共包含6个分区,其中分区p1的取值为小于10的数,分区p6为任何大于50的数,PARTITION BY RANGE(j)语句中的j代表的是根据表中的j****列的数值来进行分区。
下图所示为分区的详细信息。
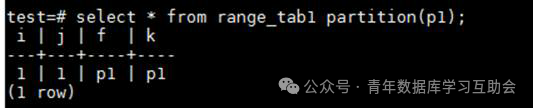
使用select * from range_tab1 partition(p1);语句可以查询具体分区中的存在的数值
列表分区
create table list_tab1(
col1 int,
col2 varchar(50)
)partitionbylist(col1)(
partition p1 values(1),
partition p2 values(2),
partition p3 values(3),
partition p4 values(4)
);
insertinto list_tab1 values(1,'p1');
insertinto list_tab1 values(2,'p2');
insertinto list_tab1 values(3,'p3');
insertinto list_tab1 values(4,'p4');
上面是简单的list分区的例子,插入的col1列的值会根据你插入的数值自动匹配与这个数值相等的分区。

hash分区
create table hash_tab1(
col1 int,
col2 varchar(50),
col3 varchar(50)
)partition by hash(col1)(
partition p1,
partition p2,
partition p3
);
insert into hash_tab1 values(1,'a','A');
insert into hash_tab1 values(2,'b','B');
insert into hash_tab1 values(3,'c','C');
insert into hash_tab1 values(4,'a','A');
insert into hash_tab1 values(5,'b','B');
insert into hash_tab1 values(6,'c','C');
要注意hash分区中分区的定义只需要写分区名即可,不需要定义分区规则

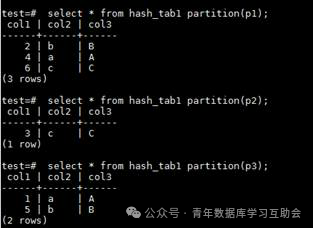
上图所示为分数数据的分布情况,这里要注意,与其他数据库不同的是,这里无法自主定义hash分区的分区规则,即哈希函数,使用的是数据库内置的hash函数定义的分区规则,这一点与Oracle数据库保持一致。
interval分区
interval分区实际上就是range分区的一种不同的写法,只是这种写法要求分区的数值分布要按照一定的规律增长。
例如下面的例子中,只定义了一个分区p1,数值为minvalue-10,
注意INTERVAL(10)这句话的意思是每一个分区都按照10的倍数这个层级一个一个上涨,并且在发现插入的数不在当前已经定义好的分区内的时候,数据库会自动创建一个新的分区,
例如,执行INSERT INTO interval_tab1 VALUES(11,'p2','p2');
CREATE TABLE interval_tab1(
j NUMBER,
f VARCHAR2(20),
k VARCHAR2(20)
)PARTITION BY RANGE(j)
INTERVAL(10)
(
PARTITION p1 VALUES LESS THAN(10)
);
INSERT INTO interval_tab1 VALUES(1,'p1','p1');
可以看到,原来只有一个分区的表,数据库自动创建了一个p2的分区,用来存放新的数值,且分区的范围是10的倍数往上涨的。
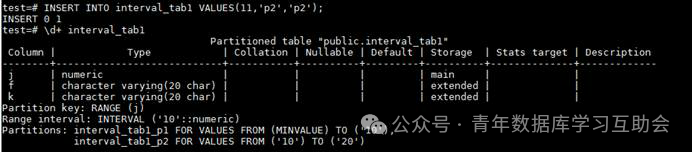
这里因为是按顺序插入的语句,看不出10的倍数的规律,这里重新执行两条语句
INSERT INTO interval_tab1 VALUES(31,'new','new');**
**INSERT INTO interval_tab1 VALUES(65,'new','new');
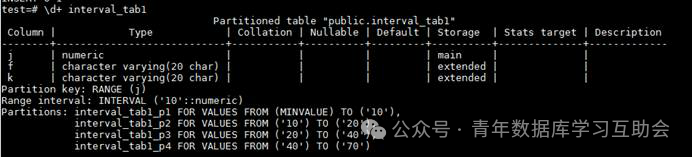
可以看到此时新创建了两个分区,且分区的范围都是10的倍数级,分区的最大值为插入数据往上一个的10的倍数值。
合并分区
合并分区就是将两个小的分区合并成一个大的分区,且原先存在的分区被销毁,换成新创建的这个分区,原来分区的数据都放在这个新的分区中。
range分区
range分区的合并严格按照分区的顺序进行合并,不能够跨越分区或者是跨越层级进行合并,例如存在p1,p2,p3这三个分区,那么就不能直接对p1和p3这两个分区进行合并,只能对相邻的分区进行合并。
执行分区表合并的语法是
alter table range_tab1 merge partition p1 to p3 into partition p3
上面是一条合法的合并分区的语句,也可以写成
alter table range_tab1 merge partition p1, p2, p3 into partition p3
alter table range_tab1 merge partition for(1), for(11), for(21) into partition p3
上面两种写法都是符合规则的写法,for的意思就是说括号里随便放一个这个分区里的数值,就可以代表这个整个分区
下面说一些不合法的写法
alter table range_tab1 merge partition p2, p1 into partition p3
l 这个不合法是因为合并的分区书写的顺序要符合从小到大的规则书写,且新创建的分区的名字不能和已经存在的分区的名字重合。
alter table range_tab1 merge partition p1, p3, p2 into partition p3
l 这个不合法原因同上
alter table range_tab1 merge partition p1, p2, p3 into partition p2
l 这个不合法是因为合并的分区只能向大范围进行合并,不能像小范围进行合并,这里p2处在中间,如果改成最边上的p3就可以成功合并
alter table range_tab1 merge partition p1,p2 to p3 into partition p3
l 这个是因为to前面的分区数量超过了一个,所以不合法,to的意思就是从多少到多少都进行合并。同样的to后面也不支持这么写。
list分区
list分区合并的规则写法与range类型有较大的差异,主要差异如下
l 不支持上面的to关键字写法
l 可以进行跨分区的合并,只要合并的分区都属于同一层级
例如下面的语句是可以成功执行的
alter table list_tab1 merge partition p1, p3 into partition ps1
l 对分区的书写顺序没有要求,都可以进行合并,只要是新创建的分区的名字不要与现有的分区的名字冲突就行。
例如下面的语句也是可以成功执行的
alter table list_tab1 merge partition p3, p1 into partition ps2
hash分区
注意!!!
hash****分区不支持分区合并!!!
往期文章回顾
MOP社区新闻
金仓专栏
告别繁琐!KingbaseES v9数据库一键安装-青学会&金仓专栏(1)
KingbaseES v9数据库Docker安装-青学会&金仓专栏(2)
DBA实战小技巧
实战:记一次RAC故障排查
DBA实战运维小技巧安装篇(一)Oracle 主流版本不同架构下的静默安装指南
DBA实战运维小技巧存储篇(一)根目录满了如何处理
DBA实战运维小技巧存储篇(二)打包迁移单机数据库至新存储
MOP社区投稿-内核开发
简单解析 IvorySQL 增强 Oracle xml 兼容能力的原理
简单讨论 PostgreSQL C语言拓展函数返回数据表的方式
简单分析 pg_config 程序的作用与原理
Redis 日志机制简介(一):SlowLog
Redis 日志机制简介(二):AOF 日志
Redis 日志机制简介(三):RDB 日志
pg_cron插件使用介绍
Redis 的指令表实现机制简介
pg几款源码工具介绍
Redis 事务功能简介
