




01
问题复现
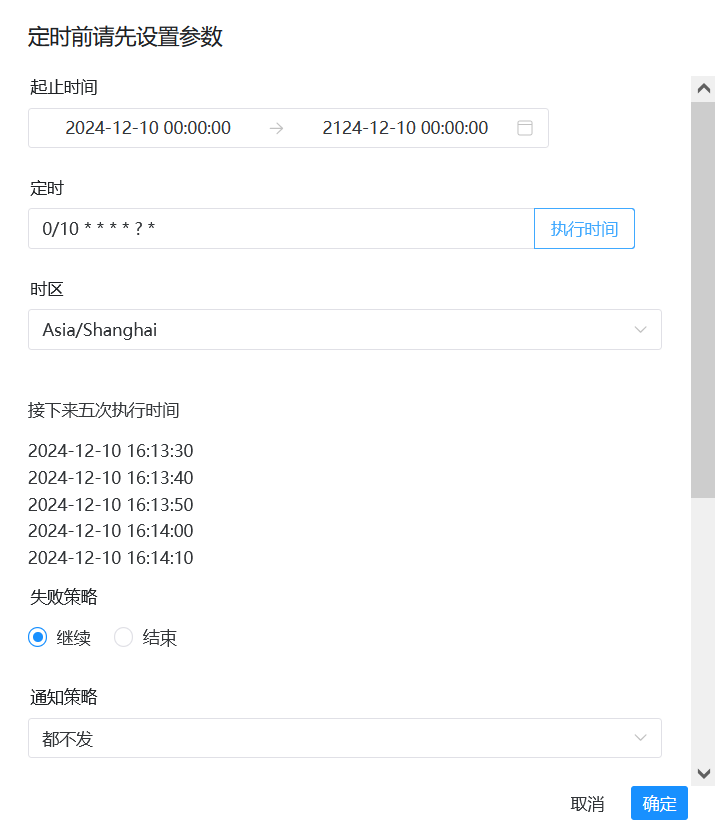
current_timestamp() {date +"%Y-%m-%d %H:%M:%S"}TIMESTAMP=$(current_timestamp)echo $TIMESTAMPsleep 60
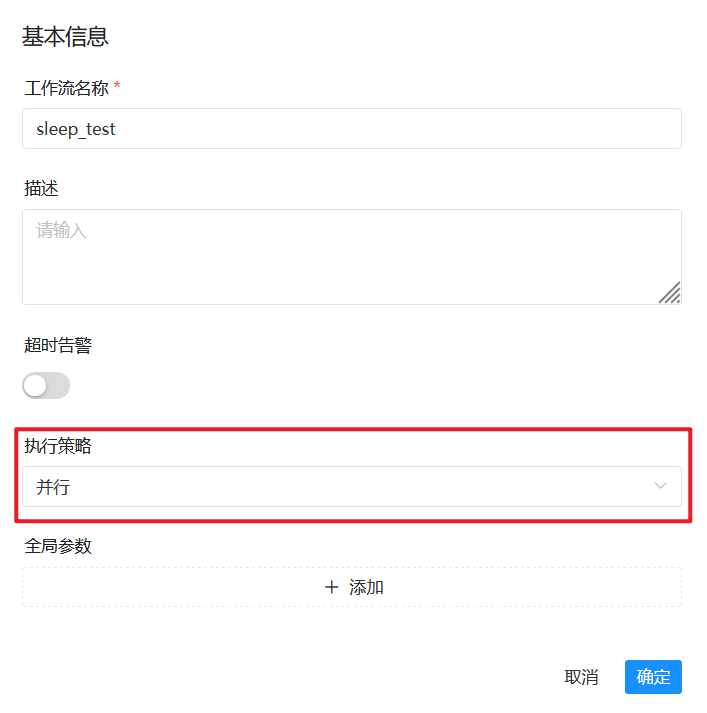
在DolphinScheduler将工作流执行策略设置为并行:
$ jps1979710 AlertServer1979626 WorkerServer1979546 MasterServer1979794 ApiApplicationServer1980483 Jps$ kill -9 1979546
sh bin/stop-all.shsh bin/start-all.sh
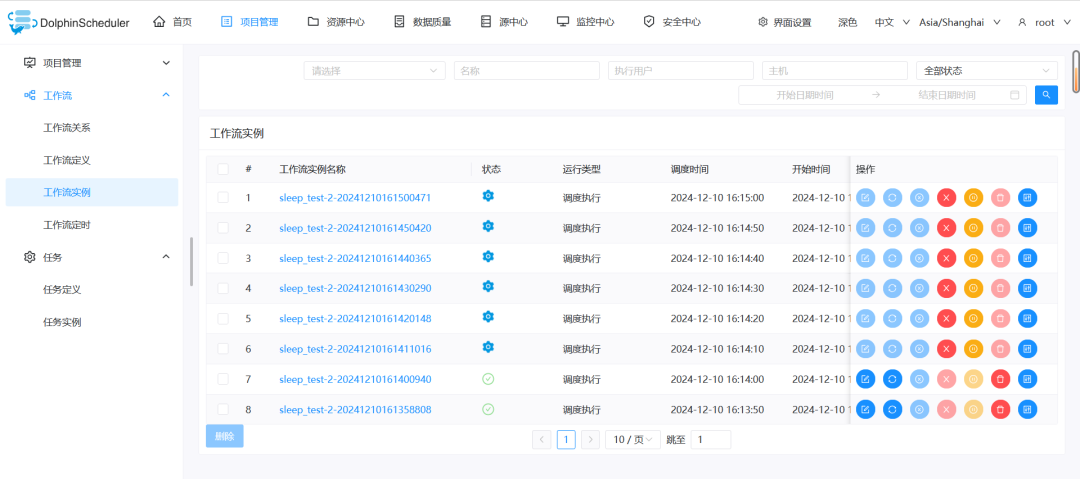
重启完成后,就会将之前没有执行成功的任务,包括没有执行的调度任务,全部都执行一次:
02
多场景测试
Master宕机后,重启整个DS:会产生上述问题。
Master宕机后,重启相应的Master:会产生上述问题。——有缺陷,官方没有单独的Master后台启动,只有前台启动的脚本,但可以重复执行start-all.sh。 Worker宕机后,重启整个DS:不会产生上述问题。——因为Master会持续的调度任务,而Worker宕机后的结果就是调度任务直接失败。 Worker宕机后,重启相应的Worker:不会产生上述问题。——有缺陷,官方没有单独的Worker后台启动,只有前台启动的脚本,但可以重复执行start-all.sh。 DS整个宕机后,重启整个DS:会产生上述问题。 DS使用stop-all.sh停止后,重启整个DS:会产生上述问题。
其核心就是在于Master,只要配置了周期任务,无论Master是宕机还是调用脚本关闭的,其都会产生上述问题。
03
原理分析
MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。 WorkerServer主要负责任务的执行和提供日志服务。WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。 ApiServer主要负责处理前端UI层的请求。
在API-Server中创建任务,并将元数据持久化到DB中。 通过手动点击或定时执行生成一个触发工作流执行的Command写入DB。 Master消费DB中的Command,开始执行工作流,并将工作流中的任务分发给Worker执行。 当整个工作流执行结束之后,Master结束工作流的执行。 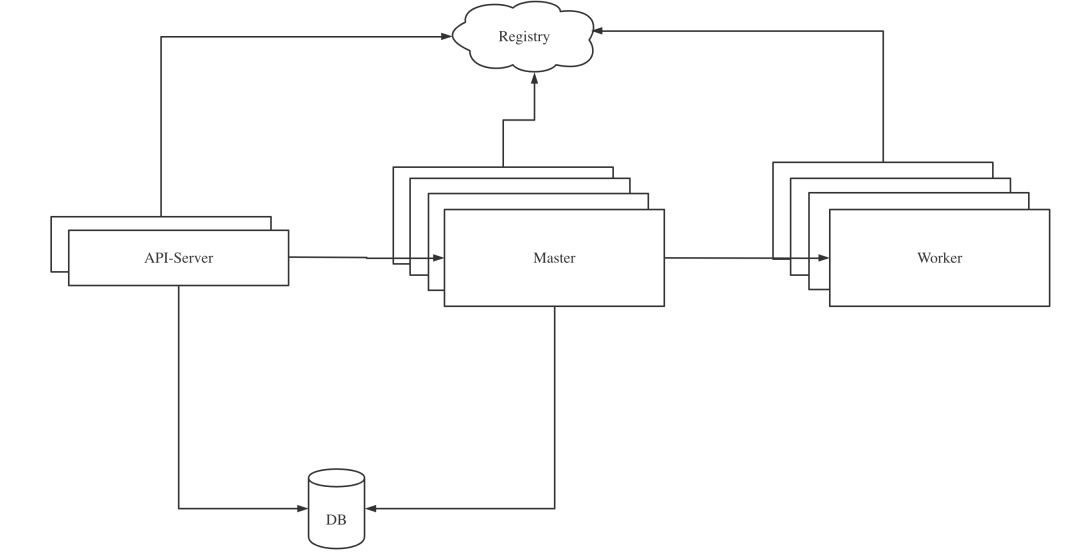

{"commandType": "START_PROCESS","processDefinitionCode": 14285512555584,"executorId": 1,"commandParam": "{}","taskDependType": "TASK_POST","failureStrategy": "CONTINUE","warningType": "NONE","startTime": 1723444881372,"processInstancePriority": "MEDIUM","updateTime": 1723444881372,"workerGroup": "default","tenantCode": "default","environmentCode": -1,"dryRun": 0,"processInstanceId": 0,"processDefinitionVersion": 1,"testFlag": 0}
<select id="queryCommandPageBySlot" resultType="org.apache.dolphinscheduler.dao.entity.Command">select *from t_ds_commandwhere id % #{masterCount} = #{thisMasterSlot}order by process_instance_priority, id asclimit #{limit}</select>
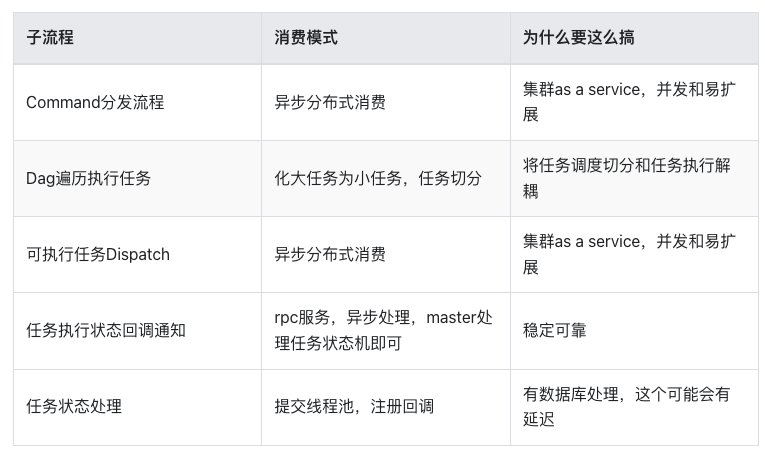
iii.MasterSchedulerBootstrap loop轮训查到待处理的command任务,将command任务和master host生成ProcessInstance,将ProcessInstance对象插入到t_ds_process_instance表中, 同时生成包含运行所需要的上下文信息的可执行任务workflowExecuteRunnable。将workflowExecuteRunnablecache到本地cache processInstanceExecCacheManager,同时生产将ProcessInstance的WorkflowEventType.START_WORKFLOW生产到workflowEventQueue队列中。
上面的步骤是用户在Web页面点击启动任务后的流程,而本次的问题是Master周期调度的问题。经过查阅资料,周期调度任务则是MasterServer将其封装为命令数据并插入t_ds_process_instance表中,后续步骤如上,大致流程如下:
命令分发:以用户提交的工作流请求为触发,MasterServer将其封装为命令数据并插入数据库中。 任务分配:MasterServer循环查询待处理的命令,依照负载情况将任务分配到对应的ProcessInstance中。 任务执行:根据DAG的依赖关系,WorkerServer会优先执行无依赖的任务,然后根据优先级逐步执行其他任务。 状态反馈:任务执行过程中,WorkerServer会定期回调MasterServer,通知任务的进展和执行状态。
id |command_type|process_definition_code|process_definition_version|process_instance_id|command_param |task_depend_type|failure_strategy|warning_type|warning_group_id|schedule_time |start_time |executor_id|update_time |process_instance_priority|worker_group|tenant_code|environment_code|dry_run|test_flag|----+------------+-----------------------+--------------------------+-------------------+-------------------------------------+----------------+----------------+------------+----------------+-------------------+-------------------+-----------+-------------------+-------------------------+------------+-----------+----------------+-------+---------+1988| 6| 15921642898976| 4| 0|{"schedule_timezone":"Asia/Shanghai"}| 2| 1| 0| 0|2024-12-11 00:36:40|2024-12-11 00:39:01| 2|2024-12-11 00:39:01| 2|default |default | -1| 0| 0|1989| 6| 15921642898976| 4| 0|{"schedule_timezone":"Asia/Shanghai"}| 2| 1| 0| 0|2024-12-11 00:36:50|2024-12-11 00:39:01| 2|2024-12-11 00:39:01| 2|default |default | -1| 0| 0|1990| 6| 15921642898976| 4| 0|{"schedule_timezone":"Asia/Shanghai"}| 2| 1| 0| 0|2024-12-11 00:37:00|2024-12-11 00:39:01| 2|2024-12-11 00:39:01| 2|default |default | -1| 0| 0|
/*** command types* 0 start a new process* 1 start a new process from current nodes* 2 recover tolerance fault process* 3 recover suspended process* 4 start process from failure task nodes* 5 complement data* 6 start a new process from scheduler* 7 repeat running a process* 8 pause a process* 9 stop a process* 10 recover waiting thread* 11 recover serial wait* 12 start a task node in a process instance*/START_PROCESS(0, "start a new process"),START_CURRENT_TASK_PROCESS(1, "start a new process from current nodes"),RECOVER_TOLERANCE_FAULT_PROCESS(2, "recover tolerance fault process"),RECOVER_SUSPENDED_PROCESS(3, "recover suspended process"),START_FAILURE_TASK_PROCESS(4, "start process from failure task nodes"),COMPLEMENT_DATA(5, "complement data"),SCHEDULER(6, "start a new process from scheduler"),REPEAT_RUNNING(7, "repeat running a process"),PAUSE(8, "pause a process"),STOP(9, "stop a process"),RECOVER_WAITING_THREAD(10, "recover waiting thread"),RECOVER_SERIAL_WAIT(11, "recover serial wait"),EXECUTE_TASK(12, "start a task node in a process instance"),DYNAMIC_GENERATION(13, "dynamic generation"),;
1)Master自身的容错:如果是多Master同时运行,其中一个作为Active Master负责处理任务调度请求,其他节点作为Standby Master。当Active Master出现故障时,Standby Master将自动接管其工作,确保系统的正常运行。这是通过ZooKeeper实现的,ZooKeeper负责选举Active Master节点,并监控节点的状态。 2)状态同步:多Master节点之间会进行状态同步,以确保在Active Master宕机时,Standby Master能够接管任务调度。 3)故障恢复:当Master节点宕机后,其他Master节点会通过ZooKeeper的Watcher机制监听到这一事件,并触发故障恢复。 4)正在运行任务的容错:当前Master节点宕机后,新Master会通过已下线的Master的地址和正在运行的工作流状态数组获取需要容错的ProcessInstance列表,之后将其放入t_ds_command表中(后续流程就是Master获取到并调度+Worker执行了)。 5)分布式锁:在容错过程中,Master节点会使用ZK分布式锁+采用指定command表分配ID的形式来确保只有一个Master节点执行容错操作,避免多个Master节点同时接管同一个任务。 6)定时容错线程:除了ZooKeeper的事件触发容错外,DolphinScheduler还实现了一个定时线程FailoverExecuteThread,用于Master重启后恢复自身之前的工作流实例。 7)任务重试:DolphinScheduler还支持任务失败后的重试机制,这与服务宕机容错相辅相成,确保任务的最终执行成功。
04
源码解析
/*** run master server*/@PostConstructpublic void run() throws SchedulerException {init rpc serverthis.masterRPCServer.start();install task pluginthis.taskPluginManager.loadPlugin();this.masterSlotManager.start();self tolerantthis.masterRegistryClient.start();this.masterRegistryClient.setRegistryStoppable(this);this.masterSchedulerBootstrap.start();this.eventExecuteService.start();this.failoverExecuteThread.start();this.schedulerApi.start();this.taskGroupCoordinator.start();MasterServerMetrics.registerMasterCpuUsageGauge(() -> {SystemMetrics systemMetrics = metricsProvider.getSystemMetrics();return systemMetrics.getTotalCpuUsedPercentage();});MasterServerMetrics.registerMasterMemoryAvailableGauge(() -> {SystemMetrics systemMetrics = metricsProvider.getSystemMetrics();return (systemMetrics.getSystemMemoryMax() - systemMetrics.getSystemMemoryUsed()) 1024.0 / 1024 / 1024;});MasterServerMetrics.registerMasterMemoryUsageGauge(() -> {SystemMetrics systemMetrics = metricsProvider.getSystemMetrics();return systemMetrics.getJvmMemoryUsedPercentage();});Runtime.getRuntime().addShutdownHook(new Thread(() -> {if (!ServerLifeCycleManager.isStopped()) {close("MasterServer shutdownHook");}}));}
masterRPCServer.start():初始化并启动RPC服务器,用于节点间通信。 taskPluginManager.loadPlugin():加载任务插件,这些插件可以扩展DolphinScheduler的任务类型。 masterSlotManager.start():启动Master的Slot管理器,它负责管理Master的资源槽位,用于任务调度。 masterRegistryClient.start():启动Master的注册客户端,它负责将Master节点注册到分布式协调服务(如ZooKeeper)中。 masterRegistryClient.setRegistryStoppable(this):设置注册客户端的可停止对象,以便在Master停止时能够进行清理工作。 masterSchedulerBootstrap.start():启动Master的调度引导服务,它负责初始化调度相关的服务。 eventExecuteService.start():启动事件执行服务,它负责处理工作流中的事件,如任务状态变化。 failoverExecuteThread.start():启动故障恢复执行线程,它负责在Master宕机后恢复任务执行。 schedulerApi.start():启动调度API服务,提供调度相关的接口供外部调用。 taskGroupCoordinator.start():启动任务组协调器,它负责协调任务组内的任务执行。
首先发现重启恢复后,Web页面上的“运行类型”是“调度执行”,而数据库的“command_type”是“6”,那就意味着必须有一个服务会有往数据库里面去插入command_type为6的方法。并且其会去获取t_ds_schedules表中的任务定时调度实例。 根据源码,排查到dolphinscheduler-dao项目下会存放所有的数据库操作DAO,遂可以找到ScheduleMapper类,此类是和t_ds_schedules相关的DAO类;之后根据t_ds_command反查,找到了CommandServiceImpl类中的createCommand方法;再根据两者反查+command_type为6,找到了ProcessScheduleTask类中的executeInternal方法。 ProcessScheduleTask类中的executeInternal方法,同时满足:获取了调度任务、插入command数据、类型为6这三个条件。 查看ProcessScheduleTask的executeInternal源码,前半部分是从Quartz上下文中获取到预定义的调度时间和调度实际运行时间,下半部分是校验这个调度Cron是否存在和上线。 在executeInternal中,最关键的其实就是scheduledFireTime和fireTime。
Web页面设置调度,其会通过SchedulerController中的createSchedule()来创建调度,并往t_ds_schedules中插入一条数据; Web页面设置调度上线,其会通过QuartzScheduler中的insertOrUpdateScheduleTask()向Quartz中创建Trigger触发器,并往QRTZ_CRON_TRIGGERS中插入一条数据; 之后定期调用ProcessScheduleTask中的executeInternal()来往t_ds_command中插入数据; 之后就是Master-Worker的执行流程了;
一个是job到达触发时间时没有被执行; 二是被执行的延迟时间超过了Quartz配置的misfireThreshold阀值;
当job达到触发时间时,所有线程都被其他job占用,没有可用线程。; 在job需要触发的时间点,scheduler停止了(可能是意外停止的);【——当前的问题属于这种类型】 job使用了@DisallowConcurrentExecution注解,job不能并发执行,当达到下一个job执行点的时候,上一个任务还没有完成; job指定了过去的开始执行时间,例如当前时间是8点00分00秒,指定开始时间为7点00分00秒;
public interface Trigger extends Serializable, Cloneable, Comparable<Trigger> {long serialVersionUID = -3904243490805975570L;int MISFIRE_INSTRUCTION_SMART_POLICY = 0;int MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY = -1;int DEFAULT_PRIORITY = 5;......


SimpleTrigger是一个简单的触发器,用于执行重复任务。它可以指定一个起始时间,然后按照固定的间隔时间重复执行任务,直到达到指定的重复次数。SimpleTrigger的属性包括重复间隔(repeatInterval)和重复次数(repeatCount),实际执行次数是repeatCount + 1,因为在开始时间(startTime)时会执行一次。 CronTrigger:CronTrigger使用Cron表达式来定义复杂的调度计划。Cron表达式由6或7个空格分隔的时间字段组成,分别表示秒、分、小时、一个月中的日期、月份、一周中的日期和可选的年份。CronTrigger允许设定非常复杂的触发时间表,基本上覆盖了其他触发器的绝大部分能力。 CalendarIntervalTrigger:CalendarIntervalTrigger指定从某一个时间开始,以一定的时间间隔执行的任务。不同于SimpleTrigger只支持毫秒单位的时间间隔,CalendarIntervalTrigger支持的间隔单位有秒、分钟、小时、天、月、年。它适合的任务类似于每周执行一次。 DailyTimeIntervalTrigger:DailyTimeIntervalTrigger指定每天的某个时间段内,以一定的时间间隔执行任务。并且它可以支持指定星期。它适合的任务类似于每天9:00到18:00,每隔70秒执行一次,并且只要周一至周五执行。 ......
/**公共的Misfire机制,在Trigger类中**/// 这是一个智能策略,Quartz会根据Trigger的类型自动选择一个合适的misfire策略。对于CronTrigger,默认使用MISFIRE_INSTRUCTION_FIRE_ONCE_NOW。int MISFIRE_INSTRUCTION_SMART_POLICY = 0;// 这个策略会将所有错过的触发事件,立即执行所有补偿动作。即使定时任务执行的时间已经结束,它也会把所有应该执行的任务一次性全部执行完。int MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY = -1;/**SimpleTrigger的Misfire机制,在SimpleTrigger类中**/// 如果触发器错过了预定的触发时间,这个策略会立即执行一次任务,然后按照原计划继续执行后续的任务。int MISFIRE_INSTRUCTION_FIRE_NOW = 1;// 这个策略会将触发器的开始时间设置为当前时间,并立即执行错过的任务,包括已经错过的重复次数。int MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT = 2;// 类似于MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT,但是会忽略已经错过的触发次数,只执行剩余的重复次数。int MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT = 3;// 这个策略会忽略已经错过的触发次数,并在下一个预定的触发时间执行任务,执行剩余的重复次数。int MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT = 4;// 类似于MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT,但是会包括所有错过的重复次数。int MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT = 5;/**CronTrigger的Misfire机制,在CronTrigger类中**/// 如果触发器错过了预定的触发时间,这个策略会立即执行一次任务,然后按照原计划继续执行后续的任务。int MISFIRE_INSTRUCTION_FIRE_ONCE_NOW = 1;// 对于CronTrigger,这个策略会忽略所有错过的触发事件,直接等待下一次预定的触发时间。int MISFIRE_INSTRUCTION_DO_NOTHING = 2;......
CronTrigger cronTrigger = newTrigger().withIdentity(triggerKey).startAt(startDate).endAt(endDate).withSchedule(cronSchedule(cronExpression).withMisfireHandlingInstructionIgnoreMisfires().inTimeZone(DateUtils.getTimezone(timezoneId))).forJob(jobDetail).build();// 往下走public CronScheduleBuilder withMisfireHandlingInstructionIgnoreMisfires() {this.misfireInstruction = -1;return this;}
/**CronTrigger,引用CronScheduleBuilder中的设置**/public CronScheduleBuilder withMisfireHandlingInstructionIgnoreMisfires() {this.misfireInstruction = -1;return this;}public CronScheduleBuilder withMisfireHandlingInstructionDoNothing() {this.misfireInstruction = 2;return this;}public CronScheduleBuilder withMisfireHandlingInstructionFireAndProceed() {this.misfireInstruction = 1;return this;}/**SimpleTrigger,引用SimpleScheduleBuilder的设置**/public SimpleScheduleBuilder withMisfireHandlingInstructionIgnoreMisfires() {this.misfireInstruction = -1;return this;}public SimpleScheduleBuilder withMisfireHandlingInstructionFireNow() {this.misfireInstruction = 1;return this;}public SimpleScheduleBuilder withMisfireHandlingInstructionNextWithExistingCount() {this.misfireInstruction = 5;return this;}public SimpleScheduleBuilder withMisfireHandlingInstructionNextWithRemainingCount() {this.misfireInstruction = 4;return this;}public SimpleScheduleBuilder withMisfireHandlingInstructionNowWithExistingCount() {this.misfireInstruction = 2;return this;}public SimpleScheduleBuilder withMisfireHandlingInstructionNowWithRemainingCount() {this.misfireInstruction = 3;return this;}
05
解决方案
将任务设置为“串行等待”。——可行,但无法发挥出大数据集群的并行化优势。并且有一个致命的缺陷,就是串行等待的任务无法在页面数手动停止,需要去到t_ds_process_instance中更改状态或删除数据。 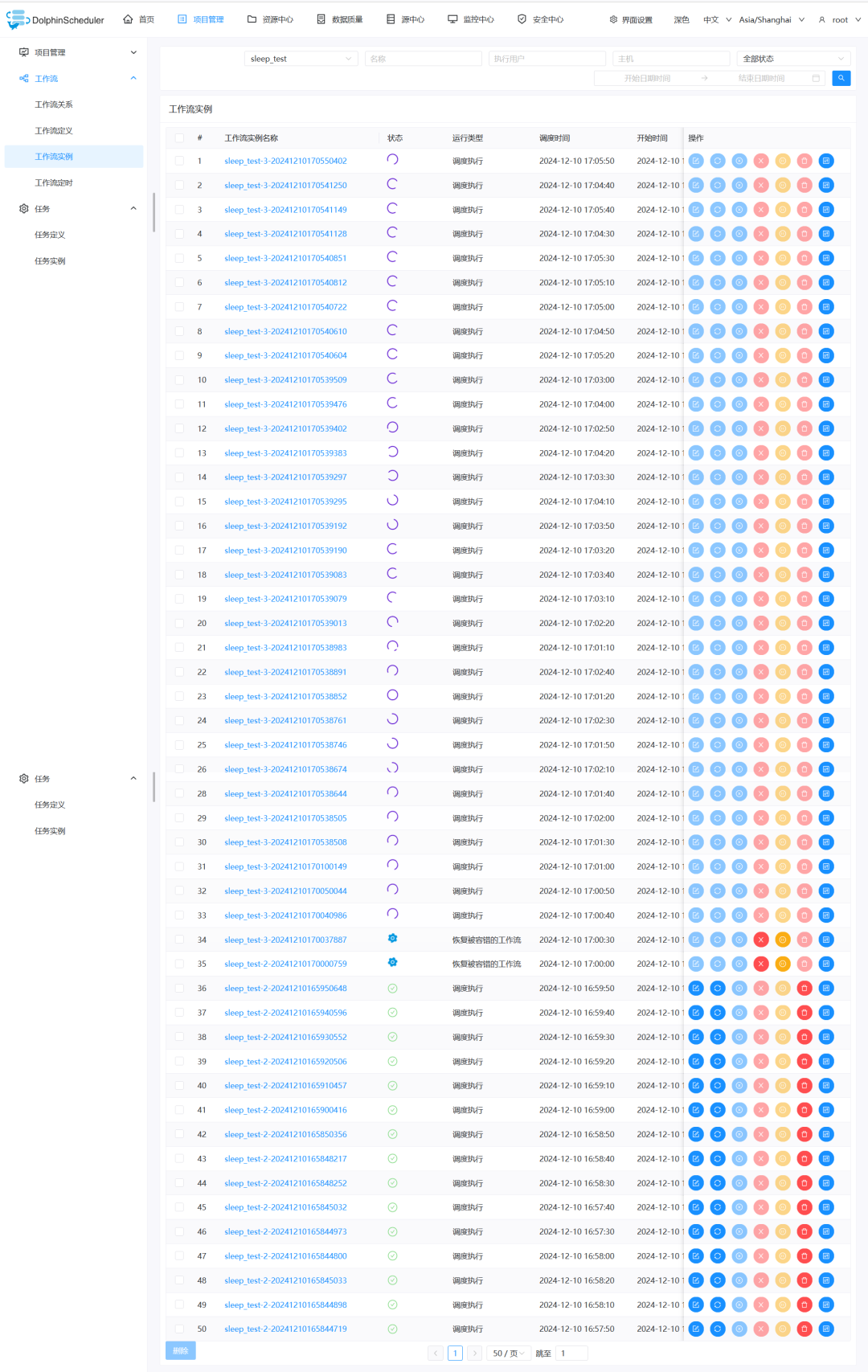
Master HA:单机Master时,对Master设置守护,宕机后自动拉起(但也有无法拉起的时候);多机Master时,部署多台Master,使其可以实现HA。 DolphinScheduler监控告警:持续监控DolphinScheduler运行状态,当有角色宕机后,及时发出告警信息(会有半夜宕机而运维人员没有及时发现告警信息的情况)。 设置DolphinScheduler的CPU和内存使用阈值:在配置文件中,默认的CPU和内存阈值是70%,以为着当服务器的CPU和内存占用达到了70%后,DolphinScheduler就不会在这台服务器上调度任务了。这种方式的好处是可以保证服务器资源不被打满,弊端是如果Master容错的旧任务打满了资源,那就会影响DolphinScheduler正常状态下的新任务了。并且有的任务是非常关键的任务,必须要跑成功的。 设置DolphinScheduler的任务数:在配置文件中,DolphinScheduler默认的任务数是单Worker100个,单Master是1000个。而在现网中,无法对任务数去做到精细的控制,并且DolphinScheduler也无法做到自动调配。 在宕机后重新启动前删除t_ds_command表中的数据:经过验证,Master在宕机后是不会往t_ds_command中写数据了。其会在重启启动后,将数据写到t_ds_command后执行,但其中的时间大概就1~2秒钟,手工无法去执行删除。 修改t_ds_process_instance中的数据:根据时间周期,修改t_ds_process_instance中所有这个范围内的工作流的状态,人工使其结束(但如果DolphinScheduler和元数据库在一台服务器上,容易DolphinScheduler启动后里面把服务器资源打满,造成无法操作元数据库了)。
避免或减少Master的宕机; 在Master宕机后,不要运行MisFire的任务;
06
修改源码
CronTrigger cronTrigger = newTrigger().withIdentity(triggerKey).startAt(startDate).endAt(endDate).withSchedule(cronSchedule(cronExpression).withMisfireHandlingInstructionDoNothing()// .withMisfireHandlingInstructionIgnoreMisfires().inTimeZone(DateUtils.getTimezone(timezoneId))).forJob(jobDetail).build();
07
开发环境验证
spring:config:activate:on-profile: mysqldatasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://IP地址:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=falseusername: 账号password: 密码quartz:properties:org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
registry:type: zookeeperzookeeper:namespace: dolphinscheduler_devconnect-string: IP地址:2181retry-policy:base-sleep-time: 60msmax-sleep: 300msmax-retries: 5session-timeout: 30sconnection-timeout: 9sblock-until-connected: 600msdigest: ~
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql-connector.version}</version><!-- <scope>test</scope>--></dependency>
<root level="INFO"><!-- <if condition="${DOCKER:-false}">--><!-- <then>--><!-- <appender-ref ref="STDOUT"/>--><!-- </then>--><!-- </if>--><appender-ref ref="STDOUT"/><appender-ref ref="APILOGFILE"/></root><root level="INFO"><!-- <if condition="${DOCKER:-false}">--><!-- <then>--><!-- <appender-ref ref="STDOUT"/>--><!-- </then>--><!-- </if>--><appender-ref ref="STDOUT"/><appender-ref ref="TASKLOGFILE"/><appender-ref ref="MASTERLOGFILE"/></root><root level="INFO"><!-- <if condition="${DOCKER:-false}">--><!-- <then>--><!-- <appender-ref ref="STDOUT"/>--><!-- </then>--><!-- </if>--><appender-ref ref="STDOUT"/><appender-ref ref="TASKLOGFILE"/><appender-ref ref="WORKERLOGFILE"/></root>
Master VM Options:-Dlogging.config=classpath:logback-spring.xml -Ddruid.mysql.usePingMethod=false -Dspring.profiles.active=mysql Worker VM Options:-Dlogging.config=classpath:logback-spring.xml -Ddruid.mysql.usePingMethod=false -Dspring.profiles.active=mysql Api VM Options:-Dlogging.config=classpath:logback-spring.xml -Dspring.profiles.active=api,mysql 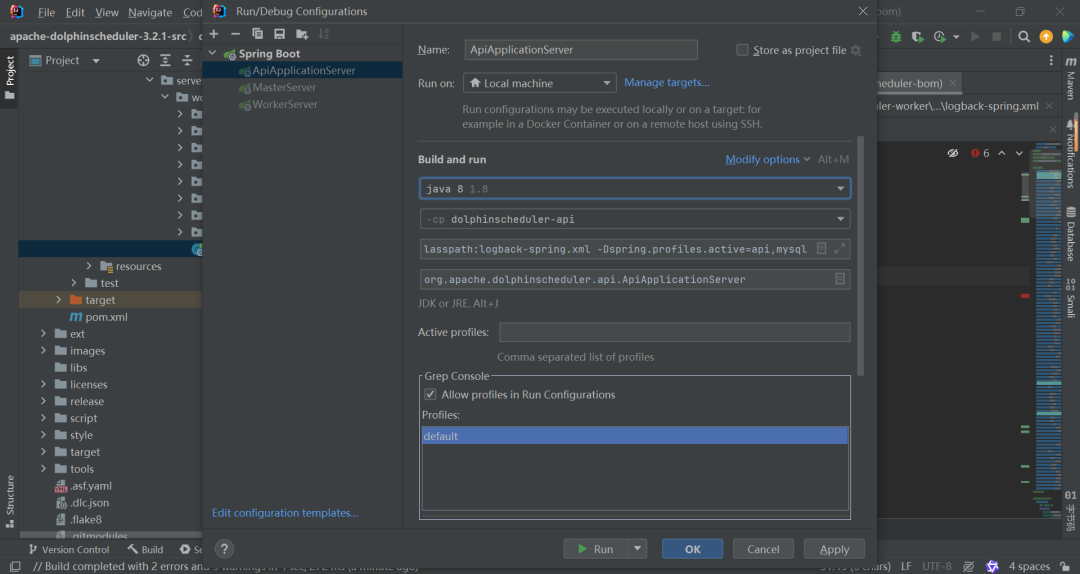
Error running 'ApiApplicationServer'Error running ApiApplicationServer.Command line is too long. Shorten the command line via JAR manifest or via a classpath file and rerun.

<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version></dependency>
08
整体编译打包
09
只编译单个模块
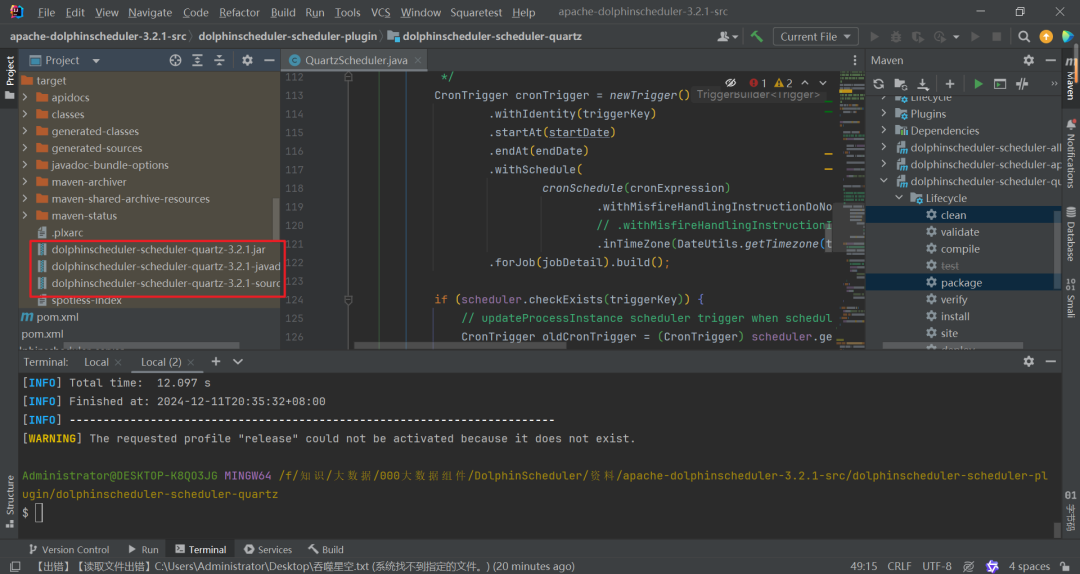
su dolphinscheduler -mv /opt/module/dolphinscheduler-3.2.1/master-server/libs/dolphinscheduler-scheduler-quartz-3.2.1.jar /opt/module/dolphinscheduler-3.2.1/master-server/libs/dolphinscheduler-scheduler-quartz-3.2.1.jar.bakmv /opt/module/dolphinscheduler-3.2.1/api-server/libs/dolphinscheduler-scheduler-quartz-3.2.1.jar /opt/module/dolphinscheduler-3.2.1/api-server/libs/dolphinscheduler-scheduler-quartz-3.2.1.jar.bakcp dolphinscheduler-scheduler-quartz-3.2.1.jar /opt/module/dolphinscheduler-3.2.1/master-server/libs/dolphinscheduler-scheduler-quartz-3.2.1.jarcp dolphinscheduler-scheduler-quartz-3.2.1.jar /opt/module/dolphinscheduler-3.2.1/api-server/libs/dolphinscheduler-scheduler-quartz-3.2.1.jarchown -R dolphinscheduler:dolphinscheduler /opt/module/dolphinscheduler-3.2.1/
10
问题解决

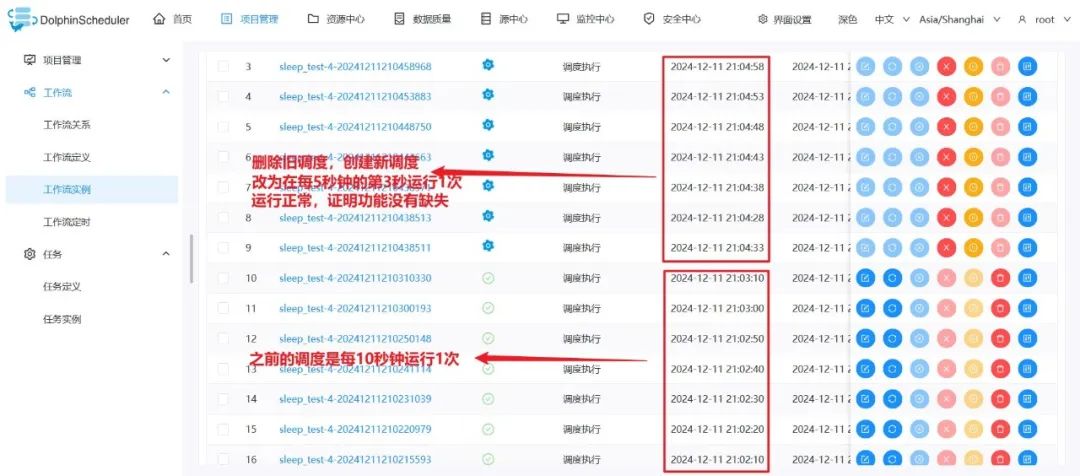
参与Apache DolphinScheduler 社区有非常多的参与贡献的方式,包括:


球分享
球点赞
球在看
文章转载自海豚调度,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
