




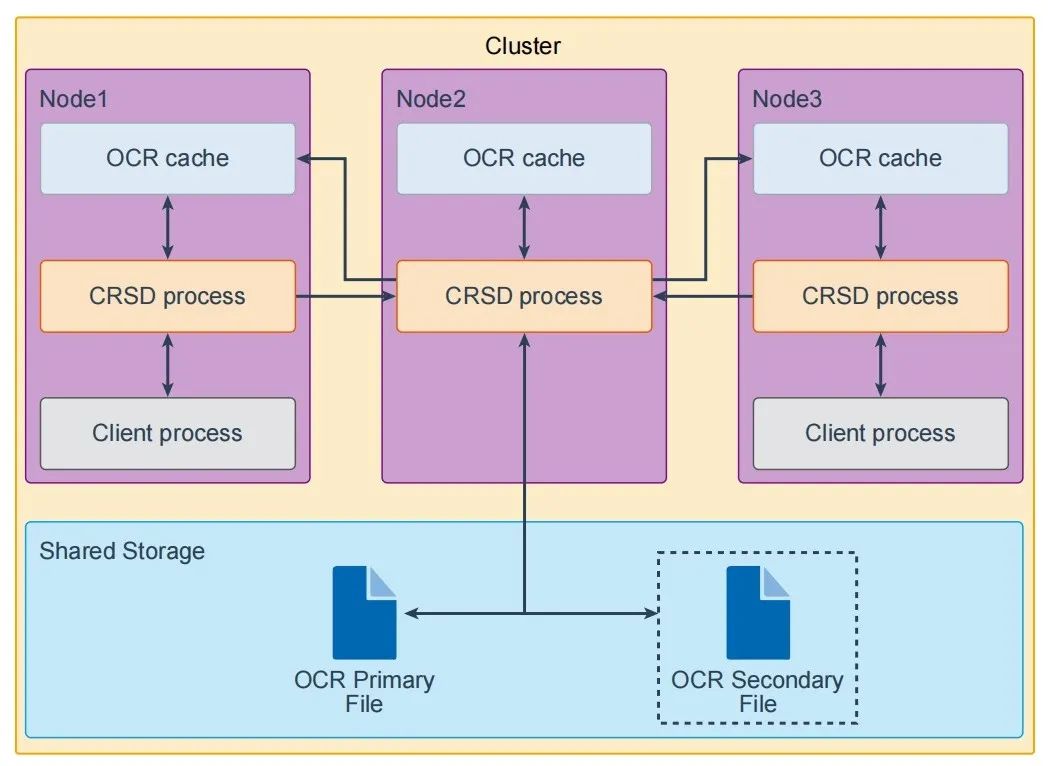
OCR是存放在共享存储中的,所以在整个集群中每个节点都通过本地的CRSD进程去访问OCR缓存在其内存中维护着的一个副本。同时为了保证OCR的完整性,Oracle不允许所有节点都能直接操作OCR,只有一个进程可以对OCR进行修改,这个进程被称为OCR Master。这个进程负责刷新自己本地的OCR cache以及集群中其他节点的OCR cache。换个方式说,每个节点的OCR客户端查询的都是本地的OCR缓存,当这个节点需要对OCR进行一些修改的时候他们将通过本地的CRSD进程与OCR Master进程进行交互来实现自己的修改。
1、ocrdump命令使用
OCR中存储的内容也是常规的键值对的形式,整个OCR的信息是树形结构,有3个分支:SYSTEM、DATABASE和CRS。使用ocrdump命令对其进行导出或者指定参数进行指定分支导出。直接执行会在当前目录下生成OCRDUMPFILE文件。也可以指定一些参数按需求输出。
stdout 直接把内容输出到屏幕上,不生成文件Filename 把内容输出到指定文件(ocrdump.txt)keyname 只打印指定键及其子键内容xml 以xml格式输出样例:ocrdump -keyname SYSTEM -xml ocrdump.txt命令:ocrdump命令:cat OCRDUMPFILE查看集群版本crsctl query crs activeversion
2、OCR健康状态检查
ocrcheck用于检查OCR内容的一致性,直接执行即可不需要参数。执行这个命令的同时也会生成一个日志文件,具体内容如下:
命令:ocrcheckfind u01 -name ocrcheck_*/u01/app/11.2.0/grid/log/nhzhbg-db1/client/ocrcheck_88595.log# more ocrcheck_88595.logOracle Database 11g Clusterware Release 11.2.0.4.0 - Production Copyright 1996, 2011 Oracle. All rights reserved.2025-01-09 22:06:04.415: [OCRCHECK][1104815936]ocrcheck starts...2025-01-09 22:06:06.092: [OCRCHECK][1104815936]protchcheck: OCR status : total = [262120], used = [2956], avail = [259164]2025-01-09 22:06:27.855: [OCRCHECK][1104815936]Exiting [status=success]...
3、手动备份ocr
OCR配置 ocrconfig,需要使用root用户执行。
命令:ocrconfig -manualbackup2025/01/09 22:14:00 /u01/app/11.2.0/grid/cdata/nhzhbg-cluster1/backup_20250109_221400.ocr查看ocr备份,正常自动备份4小时进行一次命令:ocrconfig -showbackup2025/01/07 04:23:03 u01/app/11.2.0/grid/cdata/nhzhbg-cluster1/backup00.ocr
4、OCR修复
健忘就是当一个节点更新了OCR上的部分信息,比如新加了一块磁盘。其他节点因为重启或者别的故障原因导致无法将信息及时收到,这样就造成了故障节点不知道OCR已经被更改。这个情况就被称为健忘。
ocrconfig -repair#修复primary ocrocrconfig -repair ocr device_name#修复mirror ocrocrconfig -repair ocrmirror device_name
5、OCR替换
ocrconfig -replaceocrconfig -replace ocrocrconfig -replace ocrmirror
三、案例受理阶段
1、监控平台监测到两台数据库服务器同时出现异常重启。登录操作系统发现集群状态已异常,OHASD、CRS、CSS、EVM服务已经异常无法通讯。
命令:crsctl check crs输出:CRS-4638: Cannot communicate with Oracle High Availability ServicesCRS-4535: Cannot communicate with Cluster Ready ServicesCRS-4530: Communications failure contacting Cluster Synchronization Services daemonCRS-4534: Cannot communicate with Event Manager命令:ps -ef|grep d.bin 以及 ps -ef|grep ohasd命令:crsctl stat res -t输出:CRS-4535: Cannot communicate with Cluster Ready ServicesCRS-4000: Command Status failed, or completed with errors.
2、及时检查集群的运行日志(alert主机名.log),看到CSS集群同步服务守护进程遇到致命错误被中止。
2025-01-07 11:16:04.793:[cssd(2738)]CRS-1656:The CSS daemon is terminating due to a fatal error;Details at (:CSSSC00012:) in /u01/app/11.2.0/grid/log/节点1主机名/cssd/ocssd.log2025-01-07 11:16:04.910:[cssd(2738)]CRS-1652:Starting clean up of CRSD resources.2025-01-07 11:16:05.409:[cssd(2738)]CRS-1604:CSSD voting file is offline: /dev/oracleasm/disks/VOTE02;details at (:CSSNM00058:) in /u01/app/11.2.0/grid/log/节点1主机名/cssd/ocssd.log.2025-01-07 11:16:05.409:[cssd(2738)]CRS-1604:CSSD voting file is offline: /dev/oracleasm/disks/VOTE03;details at (:CSSNM00058:) in /u01/app/11.2.0/grid/log/节点1主机名/cssd/ocssd.log.
3、进一步查看cssd日志,从报错堆栈里可以看到调用clssnmvReadDskHeartbeat函数后,集群就异常了。即磁盘心跳信号检测进程,检测到磁盘心跳信号失败,触发相应的处理机制,直接把节点被踢出集群,并触发服务器重启。这种机制对于保持集群的稳定性和数据的完整性至关重要。
操作系统日志:Jan 7 11:16:08 abrt-hook-ccpp: Process 2738 (ocssd.bin) of user 54322 killed by SIGABRT - dumping coreCSSD日志:2025-01-07 11:16:04.793: [ CSSD][3252147968]clssnmvReadDskHeartbeat: node 3 record written by node 22025-01-07 11:16:04.793: [ CSSD][3252147968]clssnmRemoveNodeInTerm: node 1, 节点1主机名 terminated due to Normal Shutdown.Removing from member and connected bitmaps2025-01-07 11:16:04.793: [ CSSD][3252147968]###################################2025-01-07 11:16:04.793: [ CSSD][3252147968]clssscExit: CSSD aborting from thread clssnmvWorkerThread2025-01-07 11:16:04.793: [ CSSD][3252147968]###################################2025-01-07 11:16:04.793: [ CSSD][3252147968](:CSSSC00012:)clssscExit: A fatal error occurred and the CSS daemon is terminating abnormally2025-01-07 11:16:04.793: [ CSSD][3252147968]堆栈信息:Call Stack Traceclone-》start_thread-》clssscthrdmain-》clssnmvWorkerThread-》clssnmvReadDskHeartbeat-》clssscExit
2025-01-07 11:16:05.408: [ CSSD][3236308736]clssnmRemoveNodeInTerm: node 1, nhzhbg-db1 terminated due to Normal Shutdown. Removing from member and connected bitmaps2025-01-07 11:16:05.408: [ CSSD][3236308736]clssscExit: abort already set 12025-01-07 11:16:05.409: [ CSSD][3241056000](:CSSNM00058:)clssnmvDiskCheck: No I/O completions for 251143204 ms for voting file dev/oracleasm/disks/VOTE02)2025-01-07 11:16:05.409: [ CSSD][3241056000]clssnmvDiskAvailabilityChange: voting file dev/oracleasm/disks/VOTE02 now offline2025-01-07 11:16:05.409: [ CSSD][3241056000](:CSSNM00058:)clssnmvDiskCheck: No I/O completions for 1643987470 ms for voting file dev/oracleasm/disks/VOTE03)2025-01-07 11:16:05.409: [ CSSD][3241056000]clssnmvDiskAvailabilityChange: voting file dev/oracleasm/disks/VOTE03 now offline2025-01-07 11:16:05.409: [ CSSD][3241056000](:CSSNM00018:)clssnmvDiskCheck: Aborting, 1 of 3 configured voting disks available, need 22025-01-07 11:16:05.409: [ CSSD][3241056000]clssnmRemoveNodeInTerm: node 1, nhzhbg-db1 terminated due to Normal Shutdown. Removing from member and connected bitmaps2025-01-07 11:16:05.409: [ CSSD][3241056000]clssscExit: abort already set 12025-01-07 11:16:05.409: [ SKGFD][3250554624]Lib :UFS:: closing handle 0x7fc698039dc0 for disk :/dev/oracleasm/disks/VOTE02:2025-01-07 11:16:05.409: [ SKGFD][3247400704]Lib :UFS:: closing handle 0x7fc68808e1f0 for disk :/dev/oracleasm/disks/VOTE02:
通过多次尝试重启集群单节点,依旧无法把集群拉起来。因此需要进行OCR重建。
1、查看OCR备份信息
[root@节点1 ~]# ocrconfig -showbackupnhzhbg-db2 2025/01/07 04:23:03 /u01/app/11.2.0/grid/cdata/nhzhbg-cluster1/backup00.ocrnhzhbg-db2 2025/01/07 00:23:01 u01/app/11.2.0/grid/cdata/nhzhbg-cluster1/backup01.ocrnhzhbg-db2 2025/01/06 20:23:00 /u01/app/11.2.0/grid/cdata/nhzhbg-cluster1/backup02.ocrnhzhbg-db2 2025/01/06 00:22:59 u01/app/11.2.0/grid/cdata/nhzhbg-cluster1/day.ocrnhzhbg-db2 2024/12/26 04:22:24 /u01/app/11.2.0/grid/cdata/nhzhbg-cluster1/week.ocrPROT-25: Manual backups for the Oracle Cluster Registry are not available
2、将3块OCR ASM盘进行移除或清理
查看当前服务器挂载磁盘信息[root@~]# lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTfd0 2:0 1 4K 0 disksda 8:0 0 10G 0 disk└─sda1 8:1 0 10G 0 partsdb 8:16 0 10G 0 disk└─sdb1 8:17 0 10G 0 partsdc 8:32 0 10G 0 disk└─sdc1 8:33 0 10G 0 partsdd 8:48 0 500G 0 disk└─sdd1 8:49 0 500G 0 partsde 8:64 0 200G 0 disk└─sde1 8:65 0 200G 0 partsr0 11:0 1 1024M 0 romvda 252:0 0 80G 0 disk├─vda1 252:1 0 1G 0 part /boot└─vda2 252:2 0 78G 0 part├─centos-root 253:0 0 62G 0 lvm /└─centos-swap 253:1 0 16G 0 lvm [SWAP]用dd进行清理(生产环境确认后再操作,否则数据会丢失)dd if=/dev/zero of=/dev/sda1 bs=1024k count=1024[root@ ~]# dd if=/dev/zero of=/dev/sda1 bs=1024k count=10241024+0 records in1024+0 records out1073741824 bytes (1.1 GB) copied, 1.32494 s, 810 MB/s[root@ ~]# dd if=/dev/zero of=/dev/sdb1 bs=1024k count=10241024+0 records in1024+0 records out1073741824 bytes (1.1 GB) copied, 1.33162 s, 806 MB/s[root@ ~]# dd if=/dev/zero of=/dev/sdc1 bs=1024k count=10241024+0 records in1024+0 records out1073741824 bytes (1.1 GB) copied, 1.39061 s, 772 MB/soracleasm deletedisk OCR1oracleasm deletedisk OCR2oracleasm deletedisk OCR3
3、创建新的ASM磁盘
# oracleasm scandisksReloading disk partitions: doneCleaning any stale ASM disks...Cleaning disk "VOTE01"Cleaning disk "VOTE02"Cleaning disk "VOTE03"Scanning system for ASM disks...# oracleasm createdisk OCR1 /dev/sda1Writing disk header: doneInstantiating disk: done# oracleasm createdisk OCR2 /dev/sdb1Writing disk header: doneInstantiating disk: done# oracleasm createdisk OCR3 /dev/sdc1Writing disk header: doneInstantiating disk: done# oracleasm scandisksReloading disk partitions: doneCleaning any stale ASM disks...Scanning system for ASM disks...# oracleasm listdisksARCHDATAOCR1OCR2OCR3
4、以excl方式启动单节点上的集群服务
# crsctl start crs -excl -nocrsCRS-4123: Oracle High Availability Services has been started.CRS-2672: Attempting to start 'ora.mdnsd' on '节点1'CRS-2676: Start of 'ora.mdnsd' on '节点1' succeededCRS-2672: Attempting to start 'ora.gpnpd' on '节点1'CRS-2676: Start of 'ora.gpnpd' on '节点1' succeededCRS-2672: Attempting to start 'ora.cssdmonitor' on '节点1'CRS-2672: Attempting to start 'ora.gipcd' on '节点1'CRS-2676: Start of 'ora.cssdmonitor' on '节点1' succeededCRS-2676: Start of 'ora.gipcd' on '节点1' succeededCRS-2672: Attempting to start 'ora.cssd' on '节点1'CRS-2672: Attempting to start 'ora.diskmon' on '节点1'CRS-2676: Start of 'ora.diskmon' on '节点1' succeededCRS-2676: Start of 'ora.cssd' on '节点1' succeededCRS-2679: Attempting to clean 'ora.cluster_interconnect.haip' on '节点1'CRS-2672: Attempting to start 'ora.ctssd' on '节点1'CRS-2681: Clean of 'ora.cluster_interconnect.haip' on '节点1' succeededCRS-2672: Attempting to start 'ora.cluster_interconnect.haip' on '节点1'CRS-2676: Start of 'ora.ctssd' on '节点1' succeededCRS-2676: Start of 'ora.cluster_interconnect.haip' on '节点1' succeededCRS-2672: Attempting to start 'ora.asm' on '节点1'CRS-2676: Start of 'ora.asm' on '节点1' succeeded# crsctl check crsCRS-4638: Oracle High Availability Services is onlineCRS-4535: Cannot communicate with Cluster Ready ServicesCRS-4529: Cluster Synchronization Services is onlineCRS-4534: Cannot communicate with Event Manager# crsctl status res -t -init
5、重新创建磁盘组,记得磁盘组与旧的OCR磁盘组名称保持一致。命令操作过程中,有遇到报错。
SQL> create diskgroup VOTE normal redundancy disk '/dev/oracleasm/disks/OCR1','/dev/oracleasm/disks/OCR2','/dev/oracleasm/disks/OCR3' ATTRIBUTE 'compatible.rdbms' = '11.2', 'compatible.asm' = '11.2';*ERROR at line 1:ORA-15018: diskgroup cannot be createdORA-15020: discovered duplicate ASM disk "OCR_0002"col path for a60set linesize 1000select group_number,DISK_NUMBER,HEADER_STATUS,NAME,PATH,TOTAL_MB from v$asm_disk;GROUP_NUMBER DISK_NUMBER HEADER_STATU NAME PATH TOTAL_MB------------ ----------- ------------ ------------------------------ ------------------------------------------------------------ ----------0 0 MEMBER ORCL:ARCH 00 1 MEMBER ORCL:DATA 00 2 PROVISIONED ORCL:OCR1 00 3 PROVISIONED ORCL:OCR2 00 9 MEMBER /dev/oracleasm/disks/DATA 00 5 PROVISIONED /dev/oracleasm/disks/OCR3 00 6 PROVISIONED /dev/oracleasm/disks/OCR2 00 7 PROVISIONED /dev/oracleasm/disks/OCR1 00 8 MEMBER /dev/oracleasm/disks/ARCH 00 4 PROVISIONED ORCL:OCR3 0SQL> show parameter asm_diskstringNAME TYPE VALUE------------------------------------ ----------- ------------------------------asm_diskstring stringSQL> alter system set asm_diskstring='/dev/oracleasm/disks';System altered.GROUP_NUMBER DISK_NUMBER HEADER_STATU NAME PATH TOTAL_MB------------ ----------- ------------ ------------------------------ ------------------------------------------------------------ ----------3 1 MEMBER VOTE_0001 dev/oracleasm/disks/OCR2 102392 0 MEMBER DATA_0000 dev/oracleasm/disks/DATA 5119993 2 MEMBER VOTE_0002 /dev/oracleasm/disks/OCR3 102391 0 MEMBER ARCH_0000 /dev/oracleasm/disks/ARCH 2047993 0 MEMBER VOTE_0000 /dev/oracleasm/disks/OCR1 10239SQL> create diskgroup VOTE normal redundancy disk '/dev/oracleasm/disks/OCR1','/dev/oracleasm/disks/OCR2','/dev/oracleasm/disks/OCR3' attribute 'compatible.asm'='11.2.0.4.0', 'compatible.rdbms'='11.2.0.4.0';Diskgroup created.
6、使用ocrconfig命令进行OCR恢复。
# crconfig -restore /u01/app/11.2.0/grid/cdata/rac-cluster/backup00.ocr# ocrcheck# crsctl query css votediskLocated 0 voting disk(s).# crsctl replace votedisk +VOTESuccessful addition of voting disk 9f86cdc3ee0d4fbdbfdb0ff029c22746.Successful addition of voting disk 0022be1f0fe34ff8bf0948096e5e8e8c.Successful addition of voting disk 7f07b3bd08a64f3abfd3102b232b066c.Successfully replaced voting disk group with +VOTE.CRS-4266: Voting file(s) successfully replaced# crsctl query css votedisk## STATE File Universal Id File Name Disk group-- ----- ----------------- --------- ---------1. ONLINE 9f86cdc3ee0d4fbdbfdb0ff029c22746 (/dev/oracleasm/disks/OCR1) [VOTE]2. ONLINE 0022be1f0fe34ff8bf0948096e5e8e8c (/dev/oracleasm/disks/OCR2) [VOTE]3. ONLINE 7f07b3bd08a64f3abfd3102b232b066c (/dev/oracleasm/disks/OCR3) [VOTE]Located 3 voting disk(s).
7、先手动创建一个pfile文件,然后再恢复asm实例的spfile文件,命令操作过程中,有遇到报错。
# su - gridLast login: Fri Nov 22 14:05:46 CST 2024$cat pfile.ora+ASM1.asm_diskgroups='DATA','ARCH'#Manual Mount+ASM2.asm_diskgroups='DATA','ARCH'#Manual Mount*.asm_diskstring='/dev/oracleasm/disks/*'*.asm_power_limit=1*.diagnostic_dest='/u01/app/grid'*.instance_type='asm'*.large_pool_size=12M*.memory_max_target=4294967296*.memory_target=4294967296*.remote_login_passwordfile='EXCLUSIVE'*.sga_max_size=4294967296SQL> show parameter spfile;NAME TYPE VALUE------------------------------------ ----------- ------------------------------spfile stringSQL> create spfile from pfile='/home/grid/pfile.ora';create spfile from pfile='/home/grid/pfile.ora'*ERROR at line 1:ORA-17502: ksfdcre:4 Failed to create file+VOTE/nyzhbg-cluster1/asmparameterfile/registry.253.1181765237ORA-15177: cannot operate on system aliasesSQL> create spfile from memory;File created.
8、重启数据库集群,可以看到集群服务可以正常启动。
# crsctl stop crs -f# crsctl check crsCRS-4638: Oracle High Availability Services is onlineCRS-4535: Cannot communicate with Cluster Ready ServicesCRS-4529: Cluster Synchronization Services is onlineCRS-4534: Cannot communicate with Event Manager# crsctl status res -t -init# crsctl status res -t -init
9、由于业务已经切到ADG备库,并将备库IP调整成SCAN IP。因此,这边增加修改集群IP的步骤。
# srvctl disable scan_listener# srvctl stop scan_listener# srvctl config scan# srvctl modify scan -n nhzhbg-cluster1-scan# vi /etc/hosts# cat /etc/hostsxx.xx.xx.xx nhzhbg-cluster1-scan# srvctl enable scan_listener# srvctl start scan_listener
10、将另一个节点上的集群服务启动起来。
# oracleasm scandisksReloading disk partitions: doneCleaning any stale ASM disks...Scanning system for ASM disks...Instantiating disk "OCR1"Instantiating disk "OCR2"Instantiating disk "OCR3"# crsctl start crs
