




除了节省成本,Iceberg 还有以下特性值得关注:
数据结构化:将混乱的数据湖转变为结构化、可查询的资源。 避免厂商锁定:避免被单一厂商的价格和限制束缚。 多引擎兼容:为每个数据任务选择最佳工具,最大限度地提高效率和成本效益。 面向未来的架构:适应不断发展的技术,无需痛苦的迁移。
在历史分析领域,像 Snowflake[1]、Redshift[2] 和 BigQuery[3] 等平台早已是主流。然而,Apache Iceberg[4] 正成为数据工程领域的热门话题。用户越来越多地将数据直接发送到 Iceberg 来构建湖仓,重新定义他们管理和查询数据的方式。
从本质上说,Iceberg 提供了多个变革性的能力,如模式演进(Schema evolution)、时间旅行(Time travel)、以及使用各种工具进行数据分析(兼容多种引擎)。这些功能在管理庞大数据集时是颠覆性的,同时也不仅仅是技术优势。采用 Iceberg 要求企业从战略上思考——从各个角度:成本、厂商独立性和未来的可扩展性。因此,Iceberg 的兴起不仅仅是由于技术因素,更主要的是体现了一种范式更迭(Paradigm shift),反映了企业在数据架构上更加开放、更加灵活以及面向未来的倾向。
1Apache Iceberg 带来的变革性影响
尽管使用 Iceberg 面临多种挑战,采用它的企业仍在不断增长,这不仅是因为技术层面的原因,还因为它在业务上的变革性影响:


驾驭数据湖
没有 Iceberg 时,在 S3 上的原始数据文件中找到特定信息如同大海捞针。虽然像 AWS Athena[5]这样的工具可以查询文件,但管理数据的结构(Schema)和访问控制(Access control)需要手动设置。Iceberg 可以将 S3 buckets 转变为结构化、可查询的数据集,加上适当的访问控制,兼容任何现代查询引擎。通过在 S3 上层使用 Iceberg,企业可以整合数据湖中不断增长且杂乱无序的数据,让全局分析触手可及。

摆脱厂商锁定
多引擎兼容
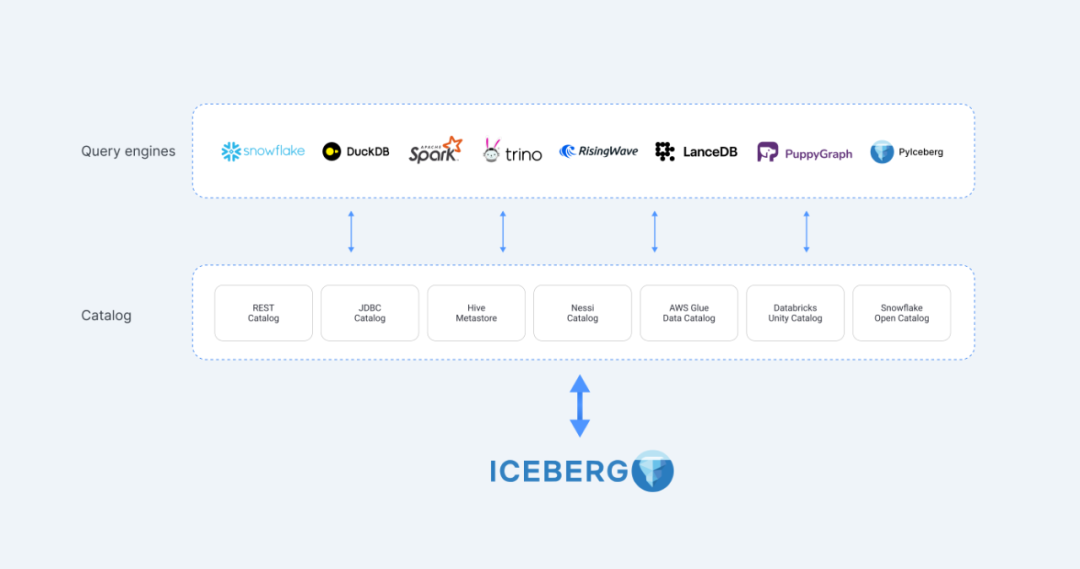
多语言支持
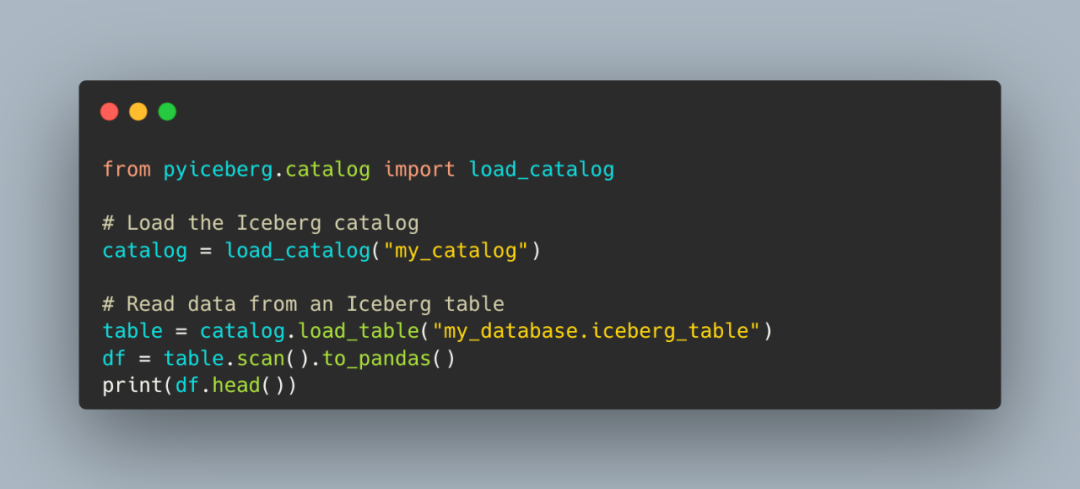
2在 Iceberg 上构建未来的数据仓库
像 Apache Iceberg 这样的开放表格式标志着数据管理的未来。独特的灵活性与生态系统的兼容性让其成为专有系统有力的替代方案,为现代数据架构设定了新标准。
到 2025 年,我相信所有数据库都将发展成本质上以 Iceberg 格式存储数据的数据引擎。如何实现?在 RisingWave Labs,我们已坚定地朝着这一愿景迈进。RisingWave 是一种云原生流数据库,现提供对 Iceberg 表的全面支持,让用户能够无缝地存储和查询Iceberg格式的数据:
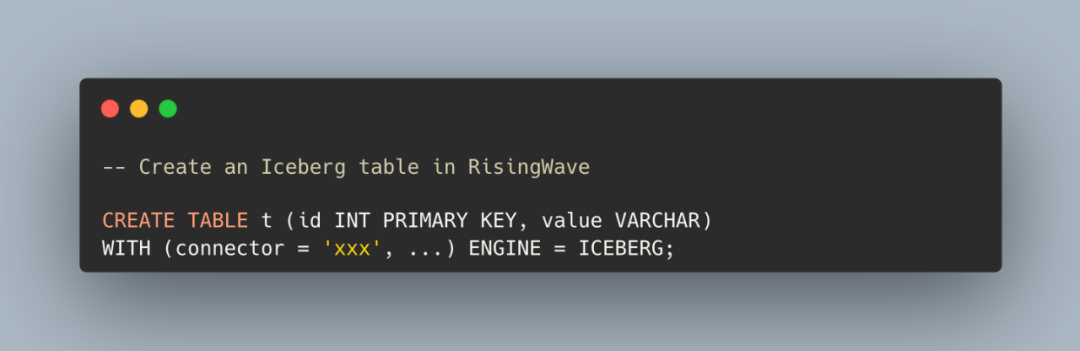
通过这一集成,RisingWave 用户可以轻松接入 Iceberg 生态系统,充分利用其开放且具有未来适应性的设计。用户可以灵活地使用任何引擎或编程语言与数据进行互动,确保在日益扩展的分析环境中保持兼容性。这是迈向真正开放和可互操作数据生态系统的重要一步。
3结语
Apache Iceberg 不仅是一项新技术,还标志着我们管理和利用数据方式的根本变革。通过倡导开放访问、灵活性和厂商独立性,Iceberg 让组织构建起真正具备未来适应性的数据架构。来自 Databricks、Snowflake 及 AWS 等行业巨头的支持进一步巩固了它作为现代数据工程基石的地位。随着数据领域的不断演进,Iceberg 为实现更开放、灵活和强大的未来铺平了道路。你准备好踏出这一步了吗?
Snowflake: https://www.snowflake.com/
[2]Redshift: https://aws.amazon.com/redshift/
[3]BigQuery: https://cloud.google.com/bigquery
[4]Apache Iceberg: https://iceberg.apache.org/
[5]AWS Athena: https://aws.amazon.com/athena/
[6]Amazon EMR: https://aws.amazon.com/emr/
[7]Databricks: https://www.databricks.com/
[8]Trino: https://trino.io/
[9]RisingWave: https://risingwave.com/
[10]LanceDB: https://lancedb.com/
[11]PuppyGraph: https://www.puppygraph.com/
关于 RisingWave


往期推荐
技术内幕
