




从openGauss到Byconity数据同步:
使用kafka实现从openGauss到Byconity数据同步,主要分为以下几个步骤:
1、openGauss通过debezium将数据变更事件写入kafka的消息队列中
2、kafka扮演消息中间件的角色,负责接收、存储和分发消息
3、ByConity从kafka读取消息,进行数据消费,将数据变更实时导入至ByConity中,保持数据的实时性
部署过程
一、openGauss环境部署
参照openGauss官网部署文档进行部署:
https://docs-opengauss.osinfra.cn/zh/docs/latest/docs/InstallationGuide/安装准备_企业版.html
二、openGauss对接kafka,实现数据变更实时推送至kafka
环境依赖:kafka,zookeeper community,confluent,debezium-connector-opengauss
原理:kafka connect 利用debezium-connector-opengauss插件,监控openGauss数据库的逻辑日志。并将数据写入到kafka中。
前置条件:
openGauss开启逻辑复制功能:
(1)仅限初始用户和拥有REPLICATION权限的用户进行操作。
(2)openGauss的库与逻辑复制槽一一对应,当待迁移的库改变时,需要配置新的逻辑复制槽的名字;
openGauss参数配置:wal_level=logical
部署过程:
下载组件:
1、下载kafka (以kafka_2.13-3.6.1为例)
wget -c
https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.6.1/kafka_2.13-3.6.1.tgz
tar -zxf kafka_2.13-3.6.1.tgz
2、下载confluent
community
wget -c
https://packages.confluent.io/archive/5.5/confluent-community-5.5.1-2.12.zip
unzip confluent-community-5.5.1-2.12.zip
3、下载debezium-connector-opengauss
wget -c
https://opengauss.obs.cn-south-1.myhuaweicloud.com/latest/tools/replicate-openGauss2mysql-6.0.0.tar.gz
tar -zxvf
replicate-openGauss2mysql-6.0.0.tar.gz
修改配置文件:
1、Zookeeper
配置文件位置:/kafka_2.13-3.6.1/config/zookeeper.properties
zookeeper的默认端口号为2181,对应参数clientPort=2181。
若端口冲突,需要修改端口号,则同步修改以下文件对应参数:
kafka_2.13-3.6.1/config/zookeeper.properties------clientPort=2181kafka_2.13-3.6.1/config/server.properties------zookeeper.connect=localhost:2181confluent-5.5.1/etc/schema-registry/schema-registry.properties------kafkastore.connection.url=localhost:2181
2、kafka
配置文件位置:/kafka_2.13-3.6.1/config/server.properties
注意topic的分区数必须为1,因此需设置参数num.partitions=1,该参数默认值即为1,因此无需单独修改该参数。
kafka的默认端口是9092,对应参数listeners=PLAINTEXT://:9092。
若端口冲突,需要修改端口号,则同步修改以下文件对应参数:
kafka_2.13-3.6.1/config/server.properties------listeners=PLAINTEXT://:9092confluent-5.5.1/etc/schema-registry/schema-registry.properties------kafkastore.bootstrap.servers=PLAINTEXT://localhost:9092confluent-5.5.1/etc/schema-registry/connect-avro-standalone.properties------bootstrap.servers=localhost:9092confluent-5.5.1/etc/kafka/mysql-source.properties------database.history.kafka.bootstrap.servers=127.0.0.1:9092
3、connect-standalone
配置文件位置:/confluent-5.5.1/etc/schema-registry/connect-standalone.properties
注意在plugin.path配置项中增加debezium-connector-opengauss所在的路径
若debezium-connector-opengauss所在路径为:/data/debezium_kafka/plugin/debezium-connector-opengauss
则配置plugin.path=share/java,/data/debezium_kafka/plugin
4、opengauss-source.properties
配置文件位置:/confluent-5.5.1/etc/kafka/opengauss-source.properties
示例详见opengauss-source.properties:
https://gitee.com/opengauss/debezium/blob/master/debezium-connector-opengauss/patch/opengauss-source.propertiescd
启动服务:
1、启动zookeeper
cd kafka_2.13-3.6.1
./bin/zookeeper-server-start.sh
./config/zookeeper.properties
2、启动kafka
cd kafka_2.13-3.6.1
./bin/kafka-server-start.sh
./config/server.properties
3、启动kafka-connect source端
cd confluent-5.5.1
./bin/connect-standalone
etc/schema-registry/connect-standalone.properties
etc/kafka/opengauss-source.properties
其他命令:
1、查看topic
cd kafka_2.13-3.6.1
./bin/kafka-topics.sh --bootstrap-server
127.0.0.1:9092 --list
2、查看topic的内容
cd confluent-5.5.1
./bin/kafka-console-consumer
--bootstrap-server 127.0.0.1:9092 --topic topic_name --from-beginning
完成以上部署后,在openGauss源数据库中插入、更新、删除数据,查看topic内容,能够看到相关json格式数据:

Kafka的topic数据格式转换:
由于ByConity从kafka消费topic数据只需要{“列名1”:值, “列名2”:值,…}的json数据格式,而debezium的json数据格式包含信息更多,所以在需要对debezium写入kafka的topic数据格式进行处理,可以使用python中的kafka-python库来实现数据格式的转换,并将转换后的消息写入新的topic(ByConity从这个新的topic去消费),转换后的json消息格式如下:

注:当前ByConity仅支持对insert数据进行消费,不支持update、delete消息的同步。
三、ByConity环境部署
参照ByConity官网部署文档进行部署:
https://byconity.github.io/zh-cn/docs/deployment/package-deployment
四、ByConity从kafka导入数据
ByConity支持导入kafka数据源,导入过程对每张OpenGauss数据表,只需要创建3张表:CnchKafka 消费表(需要通过 Setting 参数配置 Kafka 数据源及消费参数)、存储表、物化视图表(必须 Kafka 表和存储表创建成功后才能创建)。三张表创建好以后,消费就会自动开始执行。
具体创建方式参照ByConity官网指导:
https://byconity.github.io/zh-cn/docs/data-import/import-methods/import-from-kafka
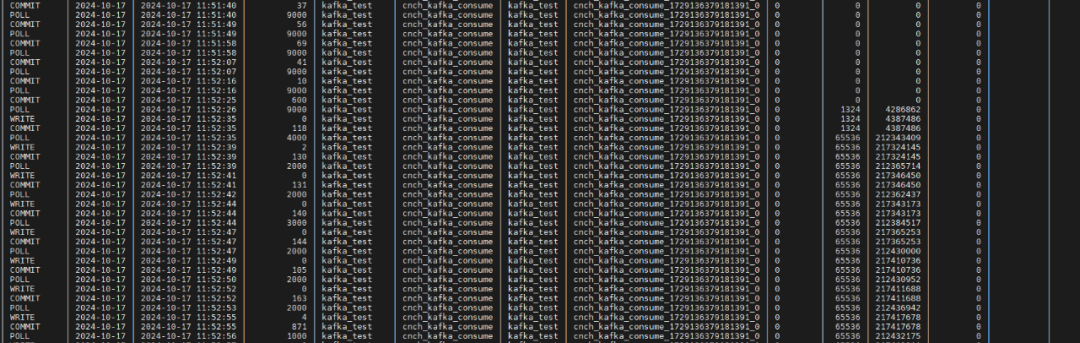
完成以上所有部署后,在ByConity中可查看到相关的数据消费记录:

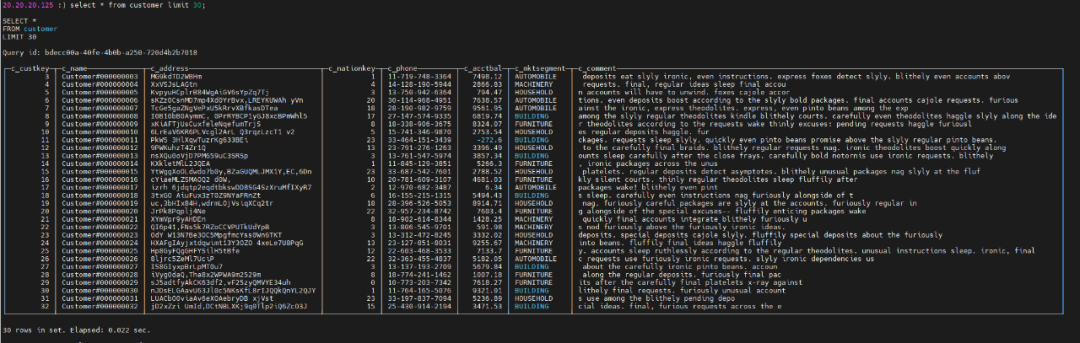
查看对应的数据存储表,可看到数据已经可以同步过来并正常展示:
五、性能测试
(一)硬件环境
设备 | 描述 |
服务器3台 | x86服务器 |
CPU | Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz
56 核 |
内存 | 768G |
磁盘 | 600G |
网络 | 10GE |
软件 | 规格 |
内核版本 | Linux 3.10.0-1160.el7.x86_64 |
操作系统版本 | CentOS Linux release 7.9.2009 (Core) |
软件版本 | FoundationDB - 7.1.25 HDFS - 3.3.4 ByConity - 1.0.0 |
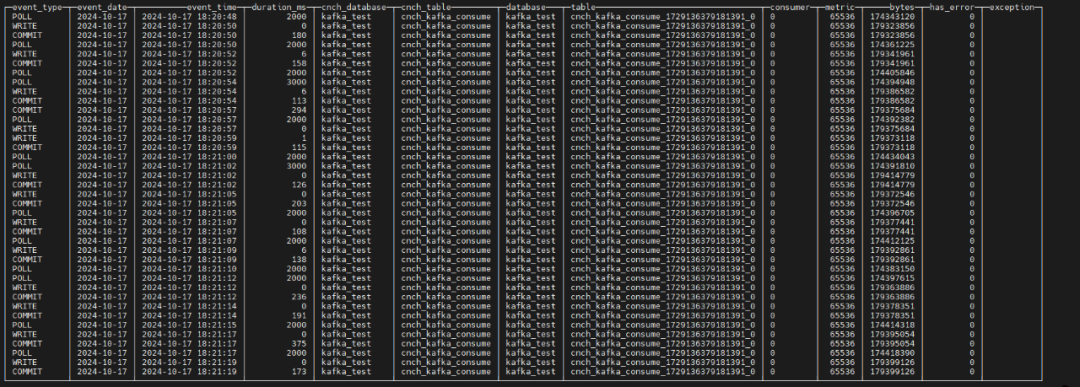
1、在openGauss不断插入数据,ByConity可持续实时进行消费,可以通过metric、bytes查看到数据同步的速率:
2、同时通过tpch测试ByConity中10G数据查询性能为13873ms,详细数据如下:
测试数据:
表名 | 10G数据行数 |
customer | 1500000 |
lineitem | 59986052 |
nation | 25 |
orders | 15000000 |
part | 2000000 |
partsupp | 8000000 |
region | 5 |
supplier | 100000 |
从测试结果看出,对于复杂的查询任务,如多表关联查询、数据聚合查询等,ByConity 能够利用其分布式架构和优化的查询引擎,以较快的速度给出精准的结果。
Query | ByConity-time(ms) |
q1 | 659 |
q2 | 179 |
q3 | 616 |
q4 | 317 |
q5 | 453 |
q6 | 150 |
q7 | 733 |
q8 | 408 |
q9 | 2207 |
q10 | 1935 |
q11 | 129 |
q12 | 315 |
q13 | 851 |
q14 | 296 |
q15 | 278 |
q16 | 362 |
q17 | 178 |
q18 | 952 |
q19 | 739 |
q20 | 279 |
q21 | 1244 |
q22 | 166 |
sum | 13873 |
