




RocketMQ学习笔记——NameServer和Topic
NameServer和Zookeeper的角色定位不同
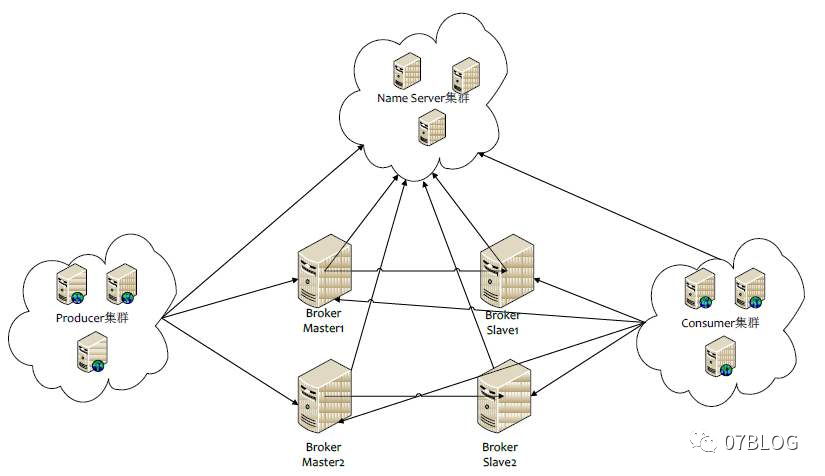
RocketMQ为什么不像Dubbo体系一样,使用一个Zookeeper,而要自己搞一个NameServer呢?Zookeeper它不香吗?了解过ZK的应该知道,NameServer的核心就是一个收集Topic信息,并通过长连接持续提供给Producer和Consumer的能力,这个能力,ZK显然是具备的。并且,ZK还具备服务发现,服务治理,集群Master选举等更强大的功能。为什么不是ZK呢?
事实上,ZK的强大,正是ZK被放弃的原因。
杀鸡焉用牛刀?小区里,搞个货架就行了,建个仓库,又占地方,又费人费钱。
消息服务本身异步的特性,也决定了,它不像Dubbo那种支持微服务的框架,需要很高的实时性,需要时刻关注每个消费者的状态并随时做出调整。所以,NameServer也不需要像ZK那样,甚至,NameServer都不需要有一个集群的管理者。以至于,NameServer看起来都不像一个集群。
事实上,NameServer本质上来看,也不是一个集群。因为它的各个节点是独立的,不相关的。每个NameServer都是独立和Producer,Consumer或Broker来打交道。节点中关于Broker、Topic的信息不会进行持久化,只会放在内存中。(支持持久化,但是一般不用)
保持在线——心跳
RocketMQ使用心跳机制来达到集群中各个角色之间的保持在线。A和B两个人,如何让A知道B保持在线呢?无非几种方式:
B上线或下线时通知A。
A固定时间间隔去看下B。
B固定时间间隔向A汇报自己的状态。
前端也提到,基于消息服务本身的异步特性,消费服务体系中的角色并不需要很及时的知道其它角色的状态,所以,RocketMQ集群中,基本上都采用的是第3种方式来达到“保持在线”的目的,即心跳。
每个Borker和所有NameServer保持在线,心跳间隔为30秒。每次心跳时,还会携带当前的Topic信息,NameServer会把这些信息更新到内存中。当某个Broker两分钟之内没有心跳,则认为该Broker下线,并调整内存中与该Broker相关的Topic信息。
Consumer与Broker维护长连接,间隔30秒发送心跳至Broker(Broker信息是从NameServer中取得的)。Broker检查若发现某Consumer2分钟内无心跳,则认为该Consumer下线,并通知该Consumer所有的消费者集群中的其他实现,触发该消费者集群的负载均衡。
Producer与Consumer一样,也是与Broker维护长连接,并进行30秒心跳(Broker信息是从NameServer中取得的)。Broker也会将2分钟内没有心跳的Producer认为为下线。
在心跳机制中,我们看到,NameServer基本不会承受太大压力,唯一可能是某Broker中的Topic过多,导致Broker每次心跳都要携带大量Topic信息让NameServer接收。如果网络较差,NameServer还会认为Broker心跳失败。这种情况下,应该考虑增加Broker集群的节点数。
NameServer“不重要”
基于前述,我们整理成以下共识:
NameServer主要用于存储Topic,Broker关系信息,功能简单,稳定性高。
各个NameServer节点之间不相关,不需要通信,单台宕机不影响其它节点。
NameServer集群整体宕机不影响已建立关系的Concumer,Producer,Broker。
Topic和Queue
聊完了NameServer,我们来聊聊Topic,为下篇文章做些准备。当前,有JMS学习基础的同学可以跳过。
Java中,通过JMS定义了AMQP协议在Java中落地规范。其中,规定了两种消息传递模型,即Topic和Queue。
Queue主要用于支持点对点的消息传递模式,即生产者将消息发送至队列,消息者从该队列中取出消息。这种传递方式的特点是,一个队列可以被多个生产者或消费者共用,但是某条消息一旦被某消费者取出,它将不再存在于队列中。即一条消息只能传递给一个消费者。
Topic主要用于发布/订阅的传递模式。生产者可将消息发布到Topic中,该Topic可由多个消费者订阅,所有订阅该Topic的消费者都能收到生产者发布的消息。所有订阅的消费者都接收消息后,消息才会从Topic中移除。即一条消息可以传递给多个消费者。
Pull和Push
消费者总是从消息队列中获取消息,获取方式有两种,即pull和push。
push:消息队列主动把消息推送给客户端。
pull:客户端主动到消息队列拉取消息。
基于两种模式的实现,我们可以分析出两种模式的优劣:
压力分布。对于push来说,只要服务端一有消息,就会主动推送给客户端,所以,消息处理的压力主要在客户端。而对于pull来说,客户端可以根据自己承压能力以一定时间间隔去服务端拉取消息,这种情况下,客户端暂时处理不了的消息会积压在服务端,对服务端造成压力。
消息延迟。显然,push比pull能够更及时的把消息送到客户端。就此来说,push模式下,消息延迟会更小。
异常处理。消息服务的异常主要有两个,一个是消息重复消费,另一个是消息丢失。仅仅基于push和pull,我们只能简单的讨论消息传输失败情况下,消息丢失的情况,因为其它的情况可能需要更复杂的机制去处理。在push模式下,如果push失败了,消息就会丢失。这时候,可能需要添加一个反馈和重试的机制,来防止丢失。而在pull模式下,则不会有这种问题。因为消息是放在服务端的,pull失败了,那消息还在服务端,再次拉取就好了。
综上,我们发现,push可能更适用于对消息实时性要求较高,客户端承压能力较强的情形,而pull,则适用于客户端承压能力较弱的情况。事实上,很多的消息中间件,比如RocketMQ,主要采用的是基于pull改变而来的长轮询模式。这种模式的机制和优点,我们下回再聊。
