




作者:王世发,吴艳兴等,58同城数据架构部
小编导读:
日均迁移 SQL 数量约 6.5 万条,查询成功率稳定在 98% 以上。
查询性能较迁移前提升 20 倍以上,平均查询时间缩短至 3.3 秒,P90 查询时间为 5 秒。
背景
“数据探查平台”是 58集团统一的 SQL 开发平台,旨在提供一个便捷的环境,让用户能够轻松编写、调试和执行 SQL 查询,并实时查看结果,每天超过10万+SQL 运行,包括 ETL,AdHoc 等场景,针对存储在 HDFS 上的海量数据查询,其底层执行引擎是由我们数据架构部门来提供的技术支持。
执行引擎原有架构
执行引擎原有架构
在引入 StarRocks 引擎之前,针对存储在 HDFS 上的海量数据查询,底层执行引擎的整体架构如下:
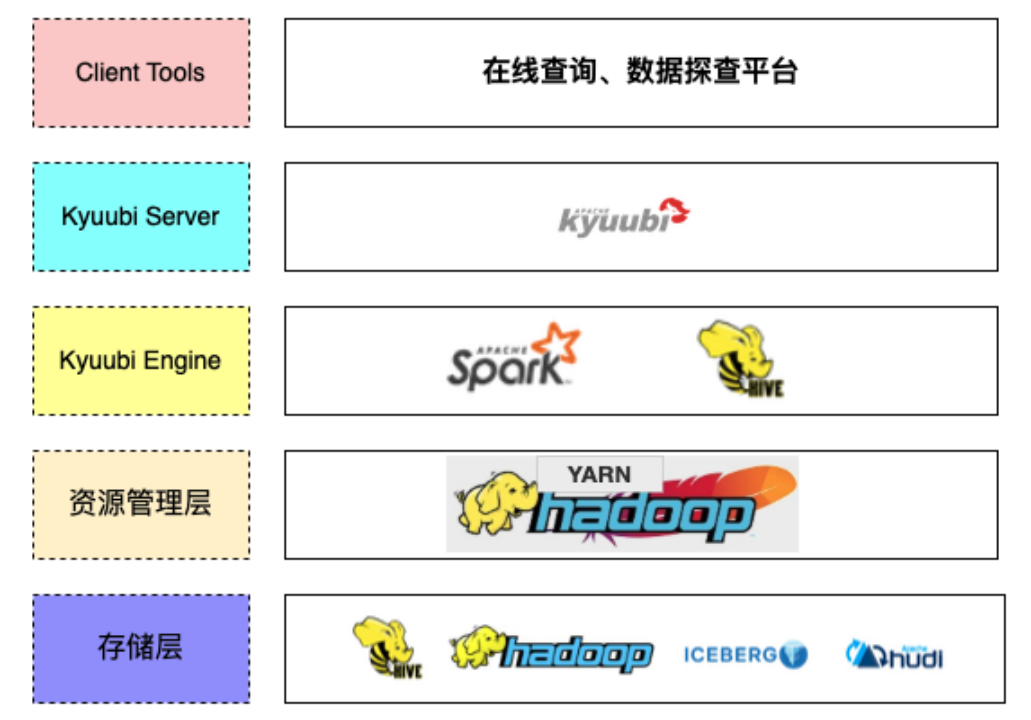
在该架构下,大部分的探查 SQL 是通过 Spark 来执行的,少部分查询会路由到 Hive,查询响应时间整体在分钟级,随着公司对降本增效需求的日益增长,这已经无法满足即席查询(Ad-Hoc)对快速响应时间的要求,因此 Ad-Hoc 查询加速就成为亟待解决的问题。
探查场景引入 StarRocks 引擎
探查场景引入 StarRocks 引擎
统一数据湖分析能力:我们只需要简单的创建一个 Hive Catalog,即可实现无缝衔接查询 Hive 表的数据,无需经过复杂的数据预处理。 MPP 框架与向量化执行引擎:可以大大提升 Ad-Hoc 查询速度,综合官方基准测试结果及我们内部 POC 测试结果,使用 StarRocks 引擎,可以将查询性能提升 10 倍以上。 架构简洁:StarRocks 架构简洁,运维成本较低。
引入 StarRocks 引擎后,数据探查执行引擎的整体架构如下:
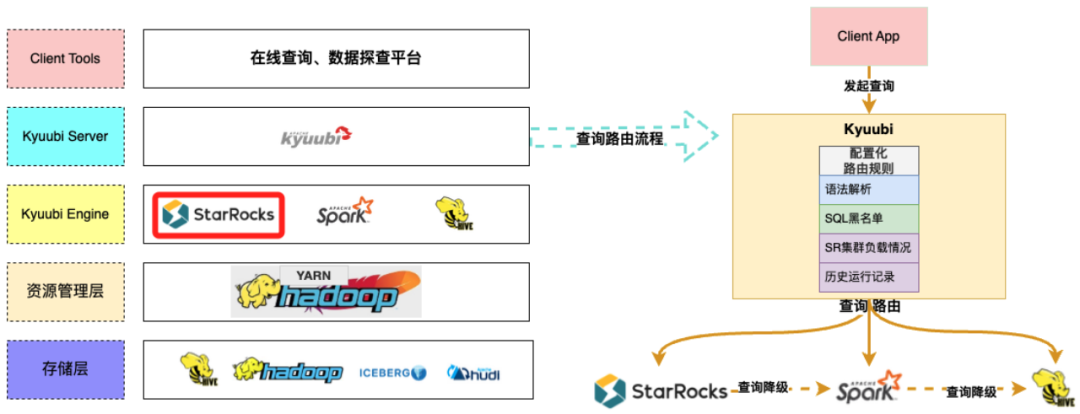
当有查询请求到来时,Kyuubi 会首先根据路由规则判断是否可以使用 StarRocks 执行。如果查询满足 StarRocks 的执行要求,我们将优先使用 StarRocks 进行处理。如果在 StarRocks 执行期间遇到异常情况,系统会自动降级到 Spark 执行,以确保用户的查询结果不会受到影响。
StarRocks 兼容 Spark 改造
在推进探查 SQL 迁移过程中,遇到的最主要的问题就是 StarRocks 与 Spark 查询结果不一致的问题。为了确保迁移过程对用户透明无感知,我们就需要对 StarRocks 进行改造,使其能够兼容 Spark的执行逻辑。
虽然不同查询引擎在架构上存在差异,但概括起来 SQL 语句的执行流程无外乎如下几个步骤:
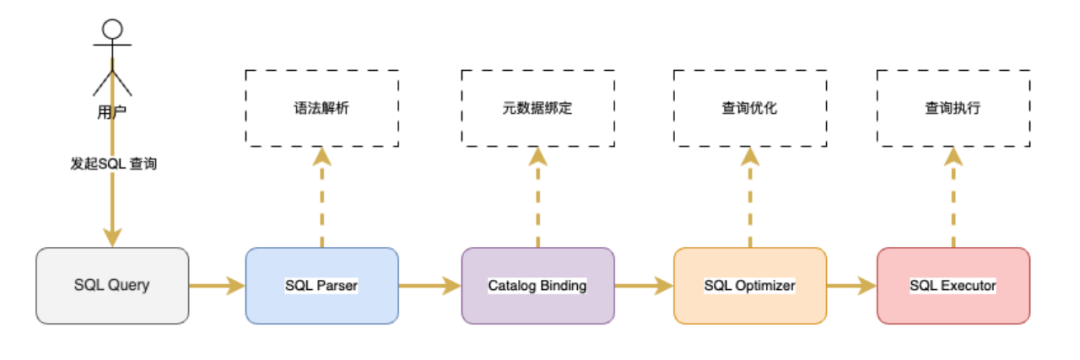
而在我们迁移过程中遇到的 StarRocks 与 Spark 不兼容问题,基本上贯穿了上面整个执行流程,下面我将按照上述执行流程,依次讲解每个环节中我们发现并解决的不兼容问题。
语法解析阶段
语法解析阶段
语法解析阶段主要工作是将查询语句转化成语法树,在这个阶段我们遇到的主要问题就是语法不兼容问题,概括起来包括以下两类问题:
语法不兼容问题
对于另一部分语法不兼容问题,我们是通过在 FE 端集成 SQLGlot 插件修复的,该插件能够实现查询语句在不同的 SQL 方言之间相互转换。例如,一些标识符如 key、show、system、group 等,在 Spark 中是可以在 SQL 语句中直接使用的,但在 StarRocks 中会被识别为关键字,无法直接使用。通过 SQLGlot 插件,可以将 SQL 语句中的这些标识符都加上反引号(`),从而使其在 StarRocks 中可以正常执行。
语法不支持问题
元数据绑定阶段
元数据绑定阶段
例如,当 Hive 表的某个分区数据被重跑后,StarRocks 在一段时间内无法感知到分区元数据的变更,从而导致查询结果不一致。
针对这一问题,经过综合分析后,我们最终决定关闭了 Hive Catalog 的所有元数据缓存功能,这一决定看似简单粗暴,但主要基于以下两点考虑:
我们当前所做的工作是将一部分原来由 Spark 执行的查询迁移到 StarRocks 上执行,而 Spark 本身也并不缓存 Hive 表的元数据,因此即使关闭了 Hive Catalog 的元数据缓存功能,也并不会增加 Hive MetaStore 的整体访问量。
当前我们线上业务的查询并发并不高,缓存元数据并不会带来显著的收益。相反,如果开启了元数据缓存,并且查询了一些分区数很多的 Hive 表(一般为多级分区表),后续元数据缓存功能会周期性的刷新缓存中的元数据,这样反而会增加 Hive MetaStore 的负担。
查询优化阶段
查询优化阶段
在 RBO 规则中,有一类隐式转换规则,可以在优化查询时自动进行数据类型转换。例如,假设有一个分区表 t1,分区字段 dt 为字符串类型。如果用户在查询 t1 表时使用数值类型的分区过滤条件,如 where t1.dt = 20241201,那么针对这种不规范的用法,Spark 和 StarRocks 都会使用各自的隐式转换规则进行数据类型转换。
针对这类问题,我们系统地梳理了 Spark 和 StarRocks 在各类表达式中的隐式转换规则,并将StarRocks 的隐式转换规则与 Spark 进行了兼容,基本上彻底解决了这一类问题。
查询执行阶段
查询执行阶段
4.1 text 格式的 Hive 表兼容性问题
另外,对于 text 格式的 Hive 表,StarRocks 社区版本也不支持查询 Map 类型的字段,我们也扩展了StarRocks 的能力,使其能够支持对 Map 类型字段的查询。
hive 表字段分隔符问题:在某些特殊情况下,StarRocks 在处理 Hive 表字段分隔符时与 Spark 存在不兼容的情况。 临时文件处理问题:StarRocks 在查询 Hive 表时没有忽略存储目录下的临时文件。 空文件处理问题:StarRocks 在解压缩空文件时会抛出异常。
4.2 函数不兼容问题
这类函数处理起来比较简单,只需要在生成执行计划时,将 Spark 中的函数映射到 StarRocks 具有相同功能的函数即可。
逻辑简单的函数:我们通过借助 StarRocks Java UDF 功能,创建 UDF 并在生成执行计划时将这些函数映射到自己实现的 Java UDF 函数来解决。 逻辑复杂的函数:我们直接修改 StarRocks 相关函数的代码,使其兼容 Spark 函数的处理逻辑。
实践经验总结
在使用 StarRocks 的过程中,我们从实践中总结出了关于性能、稳定性和易用性的关键经验。
性能
性能
针对这一问题,我们采用了自研的 HDFS 功能。当系统检测到某个 DataNode 响应缓慢时,会自动切换至其他副本读取数据。为实现这一功能,我们替换了 StarRocks 依赖的 HDFS JAR 包。经过优化后,系统的 P99 查询性能提升了 25%,效果显著。
稳定性
稳定性
其中,一个值得分享的案例是关于 CBO 统计信息的问题。在查询一张包含 3565 列的大宽表时,CBO 优化器会生成一个较大的 SQL 来获取统计信息,这可能导致 FE 内存占用过高,影响集群的正常运行。
注意:稳定性问题在最新版本已优化。
易用性
易用性
Java UDF 支持从 HDFS 下载 JAR 包
增强了 UDF 功能,使 JAR 包可通过 HDFS 下载,简化了运维流程。
SQL 黑名单持久化
StarRocks 上云
背景
背景
然而,由于各种情况的限制,上云使用的宿主机每台只能提供最多 5CORE 15GB 的资源。这给 StarRocks 的上云之路带来了一些挑战。
上云架构
上云架构
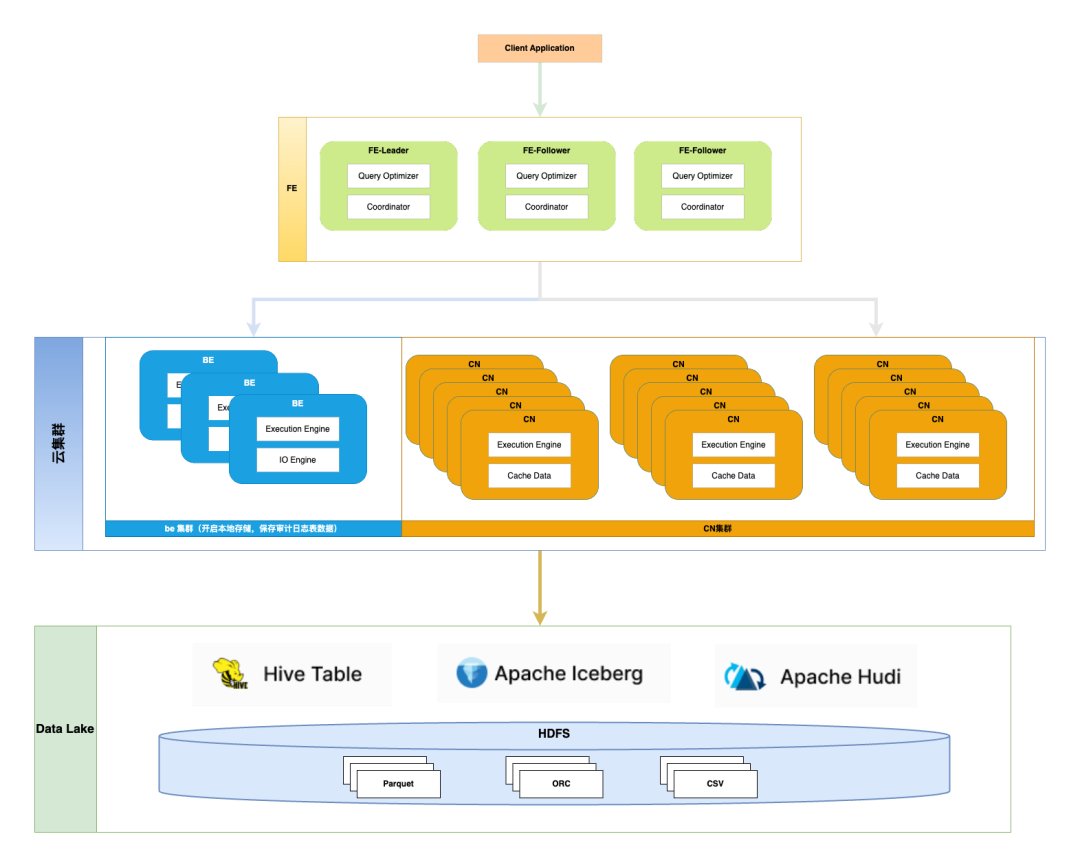
上图为 StarRocks 云集群的整体架构:
由于每个容器使用的资源限制在 5CORE 15GB,而 FE 节点需要存储集群的元数据,对内存资源要求较高,因此FE节点我们并没有上云,仍然使用物理机部署。 BE 集群只是为了存储审计日志表数据,需要开启云集群本地存储,只部署了少量实例。 CN 集群是主要的计算节点,无状态,支持快速的扩缩容。
面临的挑战
面临的挑战
通过设置资源组隔离和查询队列,控制查询并发,确保资源的合理利用。
开启中间结果落盘功能,将部分计算结果暂存到磁盘上,从而降低内存消耗。
CN 进程中有一些与执行线程数相关的参数,默认值通常设置为机器 CPU 的核数。而在容器环境下,CN 进程识别出的 CPU 核数是宿主机整体的 CPU 核数。因此,我们需要根据容器的实际资源配置手动调整这些参数。
在使用 StarRocks 数据湖分析能力查询 Hive 表场景下,有一部分功能是通过 JNI 来实现的,例如读取 HDFS 文件,还有就是一些 JAVA UDF 的使用。然而,由于 JVM 默认堆内存的上限是根据物理机的内存自动设置的,这种默认行为并不适配容器化环境。因此,需要通过设置 CN 进程的 JAVA_OPTS 参数来限制 JVM 内存的使用,从而确保 CN 进程的整体内存消耗不会超出容器的内存限制。
整体收益
项目实施一年多以来:
目前日均透明迁移到 StarRocks 集群的有效 SQL 数量约为 6.5W 条。 路由到 StarRocks 集群的 SQL,整体查询成功率稳定在 98% 以上。 已迁移的 SQL 中,平均查询时间在 3.3s 左右,P90 查询时间在 5s 左右,P99 查询时间在 52s 左右。
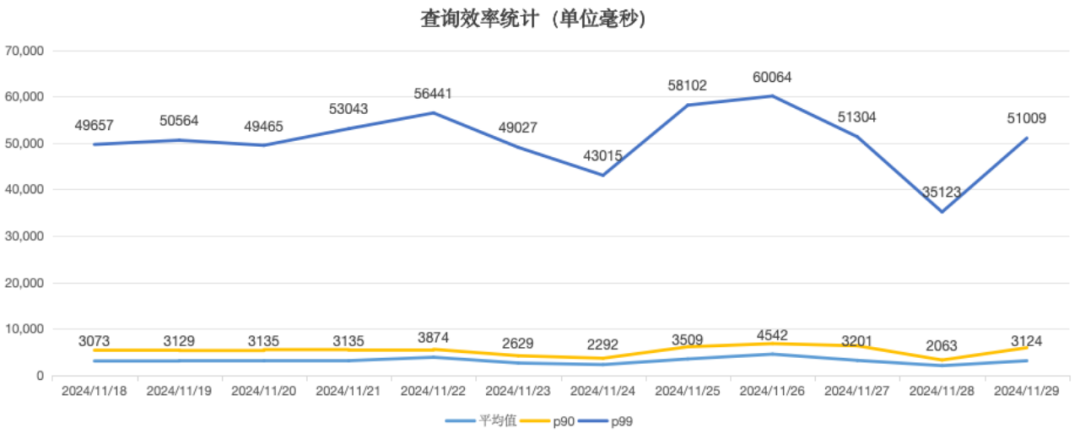
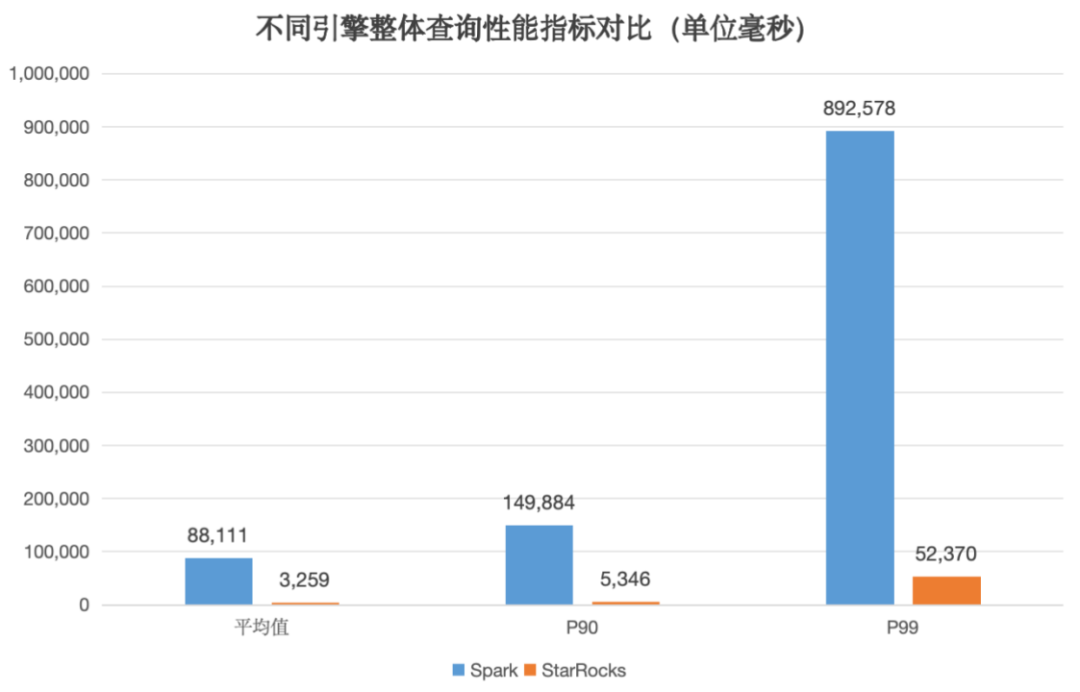
与迁移前相比,平均查询性能提升了 20 倍以上,查询体验得到了很大的提升。
后续规划
统计发现,在我们的数据探查场景中,有相当一部分 SQL 是直接对明细表进行聚合和关联查询,并没有经过数仓建模。这种查询方式不仅效率低下,而且类似的复杂查询重复执行也在很大程度上浪费了计算资源。
如果能够根据这些类似的复杂查询自动提取出公共子查询来创建物化视图,并借助 StarRocks 的物化视图透明改写能力,就可以有效解决这一问题。
事实上,我们已经在进行智能物化视图方面的探索,并将持续关注社区在这方面的进展,尽快完成智能物化视图能力的落地,以助力降本增效战略的持续推进。
关于 StarRocks
StarRocks 是隶属于 Linux Foundation 的开源 Lakehouse 引擎 ,采用 Apache License v2.0 许可证。StarRocks 全球社区蓬勃发展,聚集数万活跃用户,GitHub 星标数已突破 9500,贡献者超过 450 人,并吸引数十家行业领先企业共建开源生态。
StarRocks Lakehouse 架构让企业能基于一份数据,满足 BI 报表、Ad-hoc 查询、Customer-facing 分析等不同场景的数据分析需求,实现 "One Data,All Analytics" 的业务价值。StarRocks 已被全球超过 500 家市值 70 亿元人民币以上的顶尖企业选择,包括中国民生银行、沃尔玛、携程、腾讯、美的、理想汽车、Pinterest、Shopee 等,覆盖金融、零售、在线旅游、游戏、制造等领域。

行业优秀实践案例
泛金融:中国民生银行|平安银行|中信银行|四川银行|南京银行|宁波银行|中原银行|中信建投|苏商银行|微众银行|杭银消费金融|马上消费金融|中信建投|申万宏源|西南证券|中泰证券|国泰君安证券|广发证券|国投证券|中欧财富|创金合信基金|泰康资产|人保财险
互联网:微信|小红书|滴滴|B站|携程|同程旅行|芒果TV|得物|贝壳|汽车之家|腾讯大数据|腾讯音乐|饿了么|七猫|金山办公|Pinterest|欢聚集团|美团餐饮|58同城|网易邮箱|360|腾讯游戏|波克城市|37手游|游族网络|喜马拉雅|Shopee
新经济:蔚来汽车|理想汽车|吉利汽车|顺丰|京东物流|跨越速运|沃尔玛|屈臣氏|麦当劳|大润发|华润集团|TCL |万物新生|百草味|多点 DMALL|酷开科技|vivo|聚水潭|泸州老窖|中免集团|蓝月亮|立白|美的|伊利|公牛
