




今天分享的是人大高瓴实验室的一篇论文:
RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation。
RetroLLM:赋能大型语言模型在生成过程中检索细粒度证据。

论文链接: https://arxiv.org/pdf/2412.11919
代码链接: https://github.com/sunnynexus/RetroLLM
摘要
该论文提出了一种名为RetroLLM的统一框架。通过整合检索和生成过程,RetroLLM能够使大语言模型直接从语料库中生成细粒度证据,并采用约束解码的方式进行自回归解码。论文还引入了层级FM-Index约束和前瞻性约束解码策略,以减少无关解码空间并提高证据准确性。在五个开放域问答数据集上的广泛实验表明,RetroLLM在域内和域外任务上均展现出卓越性能。相关代码已公开。
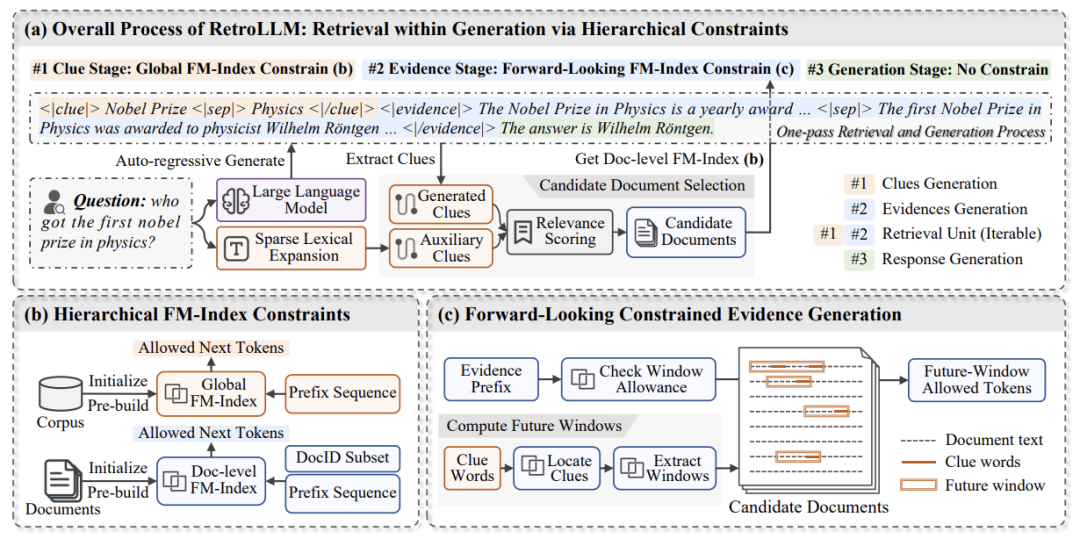
线索生成
通过语料库级别的FM-Index来根据用户的输入来生成线索词。这一步的主要流程就是大模型首先根据用户查询生成多个关键词,然后使用FM-Index来筛选那些在语料库中实际存在的词。
定位文档
基于线索,从语料库检索包含线索的文档。再根据类TF-IDF的评分规则生成候选文档集合。
结合约束解码的证据生成
至此,我们拥有了一个小型候选文档集合。下一步将依据候选文档执行约束解码生成证据。本节将结合一个小例子来理解约束解码如何让模型解码生成的证据和文档尽可能相似。约束解码的核心思想是利用未来窗口的相关性来引导生成,使得生成内容与输入查询和相关文档更加一致。以下是其完整流程:
1. 检索未来窗口
初步定位
根据查询 ,通过文档级别的FM-Index 在候选文档中找到所有包含可能线索的未来窗口集合 。
每个窗口包含以下信息:窗口文本 :如 "convert light energy into chemical energy"
。文档来源 :窗口所在的文档(如文档 A、B、C)。 窗口位置 :窗口在文档中的位置(如第 50-60 个 token)。 评估窗口相关性
使用 重排序模型 计算每个未来窗口 与查询 的语义相关性,得到相关性分数 。
示例:
文档 A 窗口相关性: 文档 B 窗口相关性: 文档 C 窗口相关性:
2. 调整解码 logits
在每一步解码时,模型会生成多个候选词 (词表中的可能生成 token),并根据以下公式调整这些候选词的 logits:
:模型的原始 logits,即生成 的初始倾向。 :包含 的所有未来窗口集合。 :从包含 的窗口中选取最大相关性分数。 :控制相关性分数对 logits 的影响。
3. 生成下一个 token
使用 Softmax 将调整后的 logits 转换为生成概率: 按概率采样或贪心解码生成下一个 token。
4. 重复解码
模型生成下一个 token 后,继续重复上述步骤,逐步生成完整的文本。每一步都会动态调整 logits 以优先生成来自高相关性窗口的词汇。
假设一个查询(注意!这里只是举一个常规的答案生成的例子为了更好的理解,本文这一步的约束解码实际上是用在证据生成的解码过程中并非最终答案的解码过程):"Explain how plants convert light energy."
Step 1: 检索未来窗口
通过 FM-Index,在三篇候选文档中找到以下相关的未来窗口:
文档 A: "convert water and minerals into nutrients."文档 B: "convert light energy into chemical energy."文档 C: "convert CO2 into oxygen efficiently."
Step 2: 调整 logits
假设当前模型需要生成下一个词,候选词为:
Logits 计算
找到包含每个词的未来窗口:
对 ,它在所有三个窗口中都出现,取最大相关性分数: 对 ,它仅在文档 A 中出现,相关性分数: 对 ,它未出现在任何窗口中,相关性分数: 调整 logits:假设原始 logits 为:
调整后 logits:
Step 3: 生成下一个 token
使用 Softmax 计算生成概率:
假设 ,计算得到:模型根据概率选择 作为下一个 token。
Step 4: 重复生成
生成 后,模型会重复上述步骤,继续检索后续窗口,调整 logits,生成完整句子。
最终生成的文本可能是:
"Plants convert light energy into chemical energy through photosynthesis."
答案生成
遵循常规的解码过程,将生成的 evidence 作为上下文信息传递给解码器,帮助解码器更好地理解问题背景和上下文。
实验
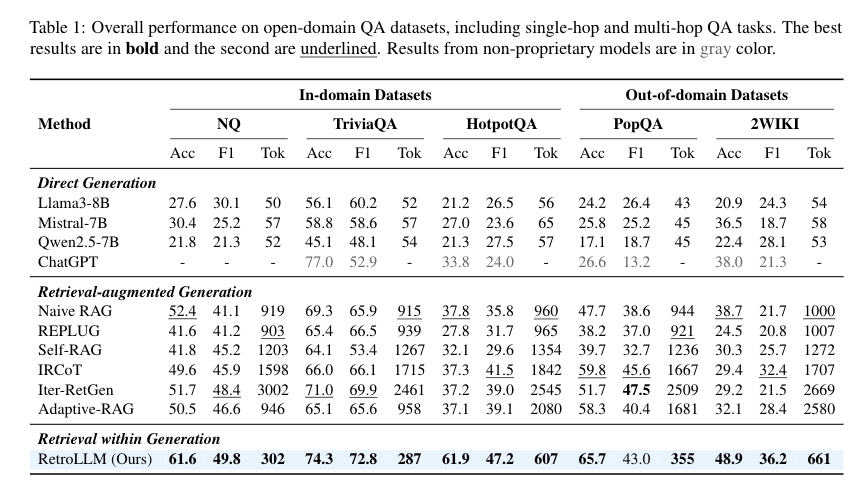 表 1: RetroLLM 和其他方法在五个开放域问答数据集上的整体性能比较
表 1: RetroLLM 和其他方法在五个开放域问答数据集上的整体性能比较1. RAG 方法优于直接生成方法
除了ChatGPT,所有 RAG 方法在所有数据集上的准确率和 F1 分数都显著高于直接生成方法(Llama3-8B、Mistral-7B、Qwen2.5-7B)。这表明对于知识密集型任务,检索增强生成能够显著提高模型的性能。
ChatGPT 的性能之所以突出,可能是因为它拥有更大的模型规模和更先进的训练数据。
2. RetroLLM 的优越性能
RetroLLM 在所有数据集上都取得了最佳的性能,无论是在单跳还是多跳问答任务中,其准确率和 F1 分数都显著高于其他 RAG 方法。
这表明 RetroLLM 的统一框架和前瞻性约束解码策略能够有效地利用外部知识,并生成更准确、更可靠的答案。
3. RetroLLM 的效率优势
RetroLLM 在所有数据集上都显著减少了 token 的消耗,相比于 Naive RAG 和 Iter-RetGen 等方法,token 消耗分别减少了 2.1 倍和 6 倍。
这表明 RetroLLM 能够更有效地检索相关证据,并动态地决定检索证据的数量,从而减少不必要的 token 消耗。
4. 不同数据集上的表现
RetroLLM 在不同数据集上都取得了优异的性能,包括单跳和多跳问答任务,以及 in-domain 和 out-of-domain 任务。
这表明 RetroLLM 具有很强的泛化能力,能够适应不同的问答场景。
总而言之,实验结果表明 RetroLLM 是一种高效的 RAG 框架,能够在不同的问答场景中生成更准确、更可靠的答案,并显著减少 token 的消耗。
编者简介
李剑楠:华东师范大学硕士研究生,研究方向为向量检索。曾作为核心研发工程师参与向量数据库、RAG 等产品研发,代表公司参加 DTCC、WAIM 等会议进行主题分享。
