




问题现象
数据盘使用百分比波动过大:
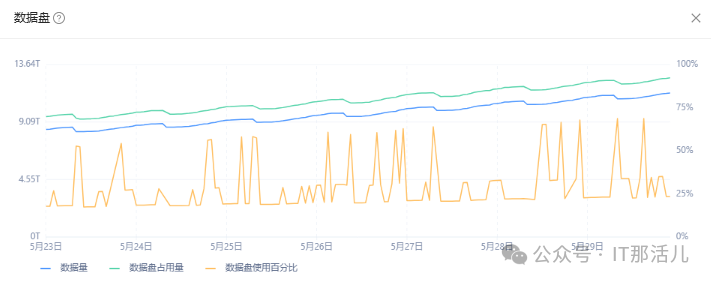
数据盘使用百分比=租户数据盘占用量除以磁盘总量。
问题处理
2.1 排查agent是否采集失败
先确认了问题集群下面的主机ip是不是有采集失败(对应ip的主机还有没有collect failed的情况),如果有的话先重启agent看看日志里还能不能看到对应ip的超时。


日志中未发现问题集群的主机ip采集超时记录,排除 agent采集失败的原因。
2.2 排查server数据落盘是否丢点
根据查询条件拼装sql查询对应的seriesid:
select * from ocp_metric_series_key_id where series_key like
'%ob_tenant_server_required_size%tenant_name=NLPT_PHOENIX_PROD_XIXIAN%';
select * from ocp_metric_series_key_id where series_key like
'%ob_tenant_disk_total_size%1695353072%tenant_name=NLPT_PHOENIX_PROD_XIXIAN%';
根据以上两个sql能各自查出三个seriesid,(seriesid用英文逗号分割)一共六个,修改以下查询url 中的 seriesid字段,url字段(改为ocp的ip),同时替换ocp的admin密码,执行:
curl --location --request POST 'http://127.0.0.1:8080/api/v2/monitor/debugQuery' \
--header 'Content-Type: application/json' \
-u 'admin:aaAA11__' \
--data '{
"queryMetricBySeriesId": {
"seriesId": [645444279763902464
],
"step": 60,
"startTime": 1717117200,
"endTime": 1717138800
}
}'
结果中显示采集的数据都顺利落盘,说明分钟级采集是正确的。
2.3 确认不是版本问题有采集sql或者表达式配置的问题
直连集群的sys租户,执行sql:
SELECT /*+ READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(50000000)
*/ a.tenant_id,a.svr_ip,a.svr_port,sum(data_size) as
data_size, sum(required_size) as required_size FROM
CDB_OB_TABLE_LOCATIONS a LEFTJOIN (SELECT
tenant_id,tablet_id,svr_ip,svr_port,data_size,required_size
FROM __all_virtual_tablet_meta_table) b ON a.TENANT_ID =
b.tenant_id AND a.tablet_id = b.tablet_id AND a.SVR_IP =
b.SVR_IP AND a.SVR_PORT = b.SVR_PORT LEFTJOIN
__all_virtual_table c ON a.TENANT_ID = c.TENANT_ID AND
a.table_id = c.table_id groupby a.tenant_id, a.svr_ip,a.svr_port
在metadb里执行:
select * from ocp_metric_expr_config where metric='ob_tenant_disk_used_percentage';
以上sql查询结果和表达式均没有异常。
2.4 由于采集的是分钟级数据,而查询的是小时级数据,进一步确认小时级数据转换是否异常
直连monitordb查小时级数据:
MySQL [ocp_monitor]> select * from metric_data_hour where series_id in (635060356195581952,635060356287856640,635060356296245248,635054342389923840,635054341165187072,635054341068718080) and timestamp=1717369200;
+--------------------+------------+----------------+
| series_id | timestamp | value |
+--------------------+------------+----------------+
| 635054342389923840 |1717369200| 19623160315904 |
| 635060356287856640 |1717369200| 4995397189632 |
| 635060356195581952 |1717369200| 4995397189632 |
| 635060356296245248 |1717369200| 4995397189632 |
+--------------------+------------+----------------+
4 rows in set (0.006 sec)
发现原本应该采集了六条数据,但是小时级表里指落盘了四条,说明有两条数据在分钟级rollup 时丢失了,正好丢失的两个seriesid是分母的磁盘总量,也可以解释为什么波动的点的结果为75%,是正常值25%的三倍。
根因排查及解决方案
分钟级数据采集的没问题,但是转储到小时级的时候丢点了,有可能是因为ocp的性能瓶颈了。
进一步排查ocp的瓶颈原因:
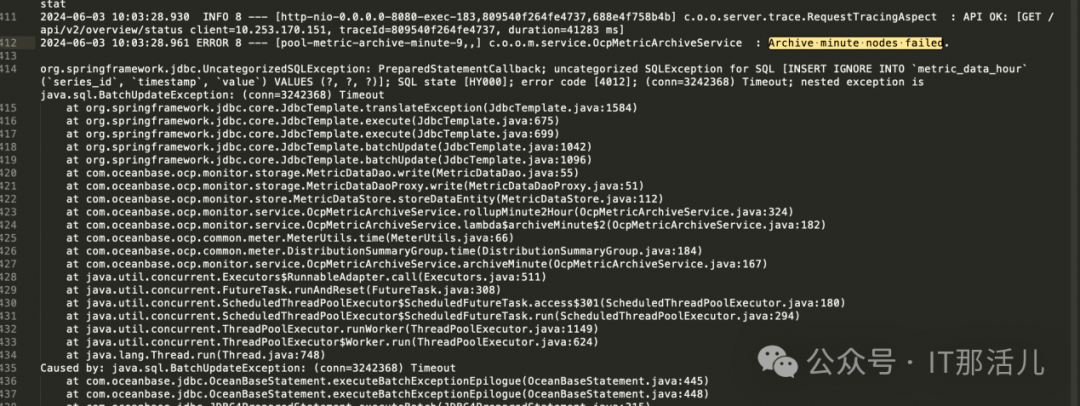
在日志里搜索Archive minute nodes failed.,发现有jdbc超时:
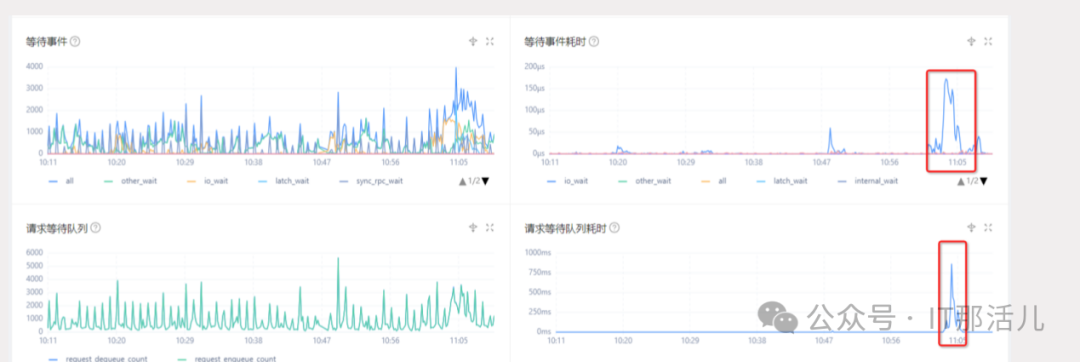
查看monitordb的性能监控,发现做分钟级数据写入和转储为小时级的时间(每小时的前几分钟),出现了性能异常的情况,说明cpu有任务等待,处理不过来:
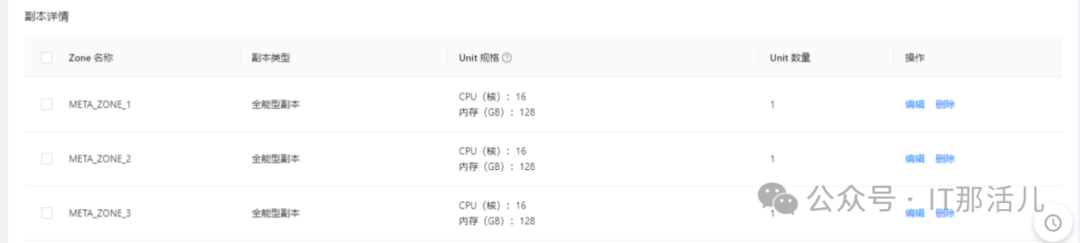
查看主机数,有87台主机,从等待队列耗时来看,monitordb的cpu在峰值等待严重,因此建议扩容cpu资源。
参考官方文档:
https://www.oceanbase.com/docs/common-ocp-1000000000827447
本文作者:郝 斌(上海新炬中北团队)
本文来源:“IT那活儿”公众号

