




导读
在mysql 5.7环境中, tbl_name.frm文件是指表定义文件, 即表的结构信息. 在8.0中由SDI取代了. 那么就可以将frm转为sdi, 这样我们的ibd2sql就不需要额外创建一个8.0的空表了.
在此之前我们得先了解下frm和sdi的结构. sdi就是1条特殊的数据行, 格式是json的, 我们使用ibd2sdi即可查看. 虽然官方没得对各个字段的具体说明, 但也能猜到1,2. 而frm文件则是个纯二进制文件, 虽然也可以使用mysqlfrm之类的工具解析, 但目前都各有小小的BUG. 比如datetime(5)里面的5会被丢掉…
所以我们今天先来看看frm的结构. 其实之前有简单讲解过. 对于简单的表还是能够拼接成DDL的. 但是不够规范. 我们现在来重新整理下frm的存储结构, 尽量向文档的标准靠拢.
对于frm里面的部分信息, 没找到相关的说明, 我也没有参透符文. 就留空了, 请感兴趣的小伙伴自己研究.
FRM
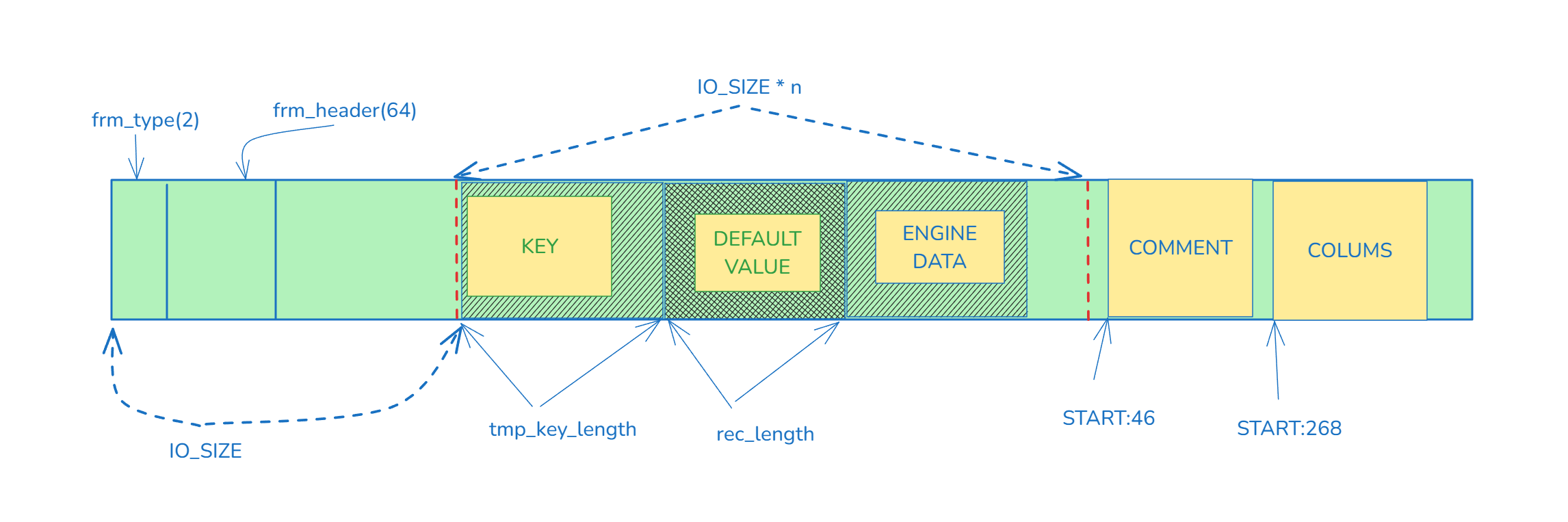
frm主要由FRM_TYPE,FRM_HEADER,KEYS,DEFAULT_VALUE,ENGINE_DATA,COMMENT和COLUMNS组成. 结构如下:
| 对象 | 起始位置 | 描述 |
|---|---|---|
| FRM_TYPE | 0 | 文件类型(510 : TABLE 22868 : VIEW) |
| FRM_HEADER | 2 | 版本,字符集,索引大小等信息 |
| KEYS | iosize:iosize+tmp_key_length | 索引 |
| DEFAULT_VALUE | iosize+tmp_key_length | 默认值 |
| ENGINE_DATA | iosize+tmp_key_length+rec_length | 存储引擎名字,分区信息 |
| COMMENT | record_offset+46 | 表的注释信息 |
| COLUMNS | record_offset+258 | 字段信息(名字,类型,是否为空等) |
结构看起来比较花里胡哨, 不太有规律. 应该是为了后续扩展考虑的. 接下来我们来看看具体的结构.
frm是mysql层实现的, 所以均为小端字节序.
FRM_TYPE
frm_type是frm文件的前2字节, 510表示这个frm是表(table), 22868则代表这个frm是视图(view).
FRM_HEADER
frm_header记录的信息很多, 基本上除了字段,索引,分区这种信息, 其它标记型的都记. 详情如下
| 对象 | 大小 | 描述 |
|---|---|---|
| frm_version | 1 | frm的版本,通常是10 |
| legacy_db_type | 1 | 存储引擎类型, 12是innodb |
| 1 | 固定03 | |
| 1 | 固定00 | |
| io_size | 2 | io_size 通常是4096 |
| 2 | ||
| length | 4 | IO_SIZE+key_length+reclength+create_info->extra_size |
| tmp_key_length | 2 | 就是key长度(含填充的0,估计是为了后面新增索引考虑的) |
| rec_length | 2 | 字段默认值的长度? |
| create_info_max_rows | 4 | |
| create_info_min_rows | 4 | |
| 1 | ||
| 1 | 固定02 | |
| key_info_length | 2 | 实际的key长度 |
| create_info_table_option | 2 | |
| 2 | 00 05 | |
| avg_row_length | 4 | |
| default_table_charset | 1 | |
| 1 | 固定00 | |
| row_type | 1 | 行格式, 0表示默认 |
| charset_left | 1 | charset的高位, (charset_left<<8)+default_table_charset才是真的字符集 |
| stats_sample_pages | 2 | 没想到吧,可以在表级别设置统计信息相关信息 |
| stats_auto_recalc | 1 | |
| 2 | 00 00 | |
| key_length | 4 | 同tmp_key_length? |
| mysql_version_0d | 4 | mysql版本 |
| extra_size | 4 | |
| extra_rec_buf_length | 2 | 保留 |
| default_part_db_type | 1 | 保留 |
| key_block_size | 2 |
对表结构比较熟悉的同学, 应该能看到很多眼熟的信息,比如MAX_ROWS, MIN_ROWS, STATS_AUTO_RECALC, STATS_SAMPLE_PAGES.
KEY
key就是我们说的索引, key的起始位置并不是紧接着frm_header的, 而是从第一个io_size开始. key的总(字节)大小为tmp_key_length, 而实际存放索引的信息要小于tmp_ket_length的, 为了方便后续扩展?
| 对象 | 描述 |
|---|---|
| keys | 索引数量 |
| key_parts | 索引涉及到的字段之和(含重复字段,就是单纯相加) |
| key | 具体的索引, 每个索引由key_info和key_part_info构成 |
| key_name | 索引的名字 |
| key_comment | 索引的注释信息 |
keys & key_parts
先来看看keys和key_parts, 即索引数量和对应字段数量. 该记录方式和索引数量有关, 若索引数量小于128, 则结构如下
| 对象 | 大小 | 描述 |
|---|---|---|
| keys | 1 | 索引数量 |
| key_parts | 1 | 索引涉及的字段之和(含重复的) |
| 4 |
若索引数量>=128, 则结构如下
| 对象 | 大小 | 描述 |
|---|---|---|
| keys | 2 | 索引数量 |
| key_parts | 2 | 索引涉及的字段之和(含重复的) |
| 6 |
key
然后来看看具体的key, 每个key都是由key_info和key_part_info构成
key_info记录key的基础信息, 比如长度(索引对应字段长度之和, 比如一个int和一个varchar(200),则长度就为4+200*3=604), 结构如下
| 对象 | 大小 | 描述 |
|---|---|---|
| flags | 2 | 一些标识,比如是否唯一 |
| key_length | 2 | 索引总长度 |
| user_defined_key_parts | 1 | 索引涉及的字段数量 |
| algorithm | 1 | 索引类型 |
| block_size | 2 |
索引类型中, 0:未定义,默认btr 1:btree 2:rtree 3:hash 4:fulltext 比如这么一张表:
create table db1.t20250117_8(id int, aa varchar(200), key(id) using hash, key(aa));
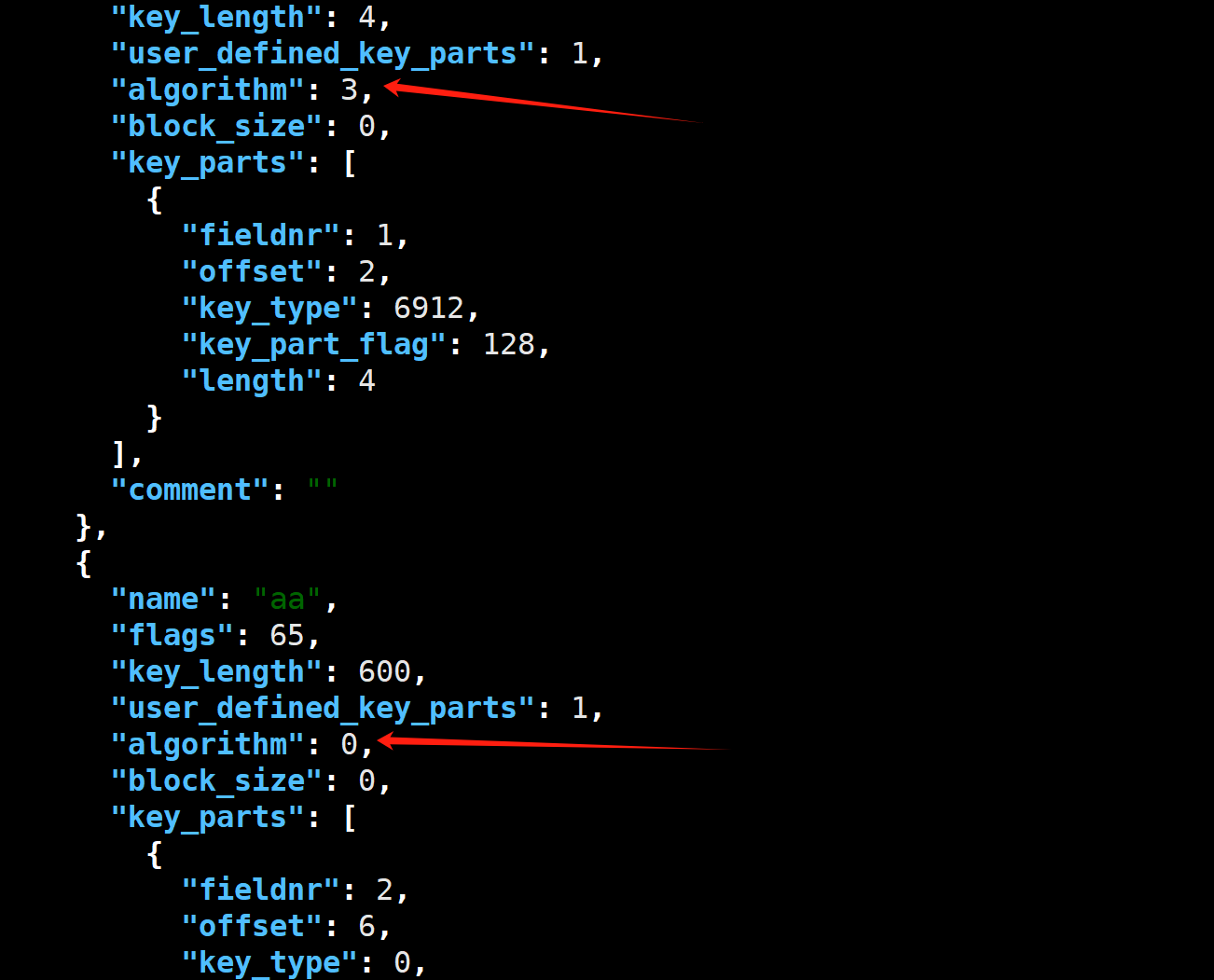
key_part_info这是记录索引对应的具体的字段. 结构如下:
| 对象 | 大小 | 描述 |
|---|---|---|
| fieldnr | 2 | 对应的字段逻辑位置 |
| offset | 2 | |
| key_type | 2 | 字段类型? |
| key_part_flag | 1 | |
| length | 2 | 字段长度 |
索引的类型分为3种(先不考虑fulltext), PRIMARY KEY, UNIQUE KEY, KEY
主键的话, 索引名字一定叫PRIMARY,所以我们可以根据名字来区分主键, 唯一键的话就由HA_NOSAME(high avaiable no same?)来决定, 对应key_info中的flag. 详情可以参考官方源码:
#define HA_NOSAME 1 /* Set if not dupplicated records */
#define HA_PACK_KEY 2 /* Pack string key to previous key */
#define HA_AUTO_KEY 16
#define HA_BINARY_PACK_KEY 32 /* Packing of all keys to prev key */
#define HA_FULLTEXT 128 /* For full-text search */
#define HA_UNIQUE_CHECK 256 /* Check the key for uniqueness */
#define HA_SPATIAL 1024 /* For spatial search */
#define HA_NULL_ARE_EQUAL 2048 /* NULL in key are cmp as equal */
#define HA_GENERATED_KEY 8192 /* Automaticly generated key */
自增的话,是正对于某个字段的, 所以在字段那里我们再讲.
key_name
接着来看看key_name, 索引的名字. 索引名字使用\xff隔开, 以\x00结尾. 比如
b'\xffid\xffaa\xffbb\xff\x00'
表示这3个索引名字为: id, aa, bb
key_comment
索引的最后部分就是索引的注释了, 每个索引使用2字节表示注释大小, 后面仅跟着就是注释内容. 结构如下
| 对象 | 大小 | 描述 |
|---|---|---|
| size | 2 | 注释大小 |
| comment | size | 注释内容 |
主键索引中是不包含非索引字段的, 和sdi的区别
DEFAULT_VALUE
接着就是默认值了, 没想到吧,字段的默认值不和字段放一堆, 而是单独拎出来. (猜测是为了方便修改默认值,甚至还预留了很多空间.)
默认值起始位置是 io_size+tmp_key_length, 即索引后面, 大小为rec_length(实际占用空间小于该值). 格式如下
| 对象 | 大小 | 描述 |
|---|---|---|
| flag | 1 | |
| column_length | 2 | 第1个字段的长度 |
| column_value | column_length | 第1个字段的指 |
| column_length | 2 | 第2个字段的指 |
| … | … | … |
如果是int之类的固定长度类型, 是没得column_length来记录长度的, 仅限varchar等变成类型. 即使某个字段没有设置默认值, 也会在这个default_value中留下相应的位置
ENGINE_DATA
engine_data是记录分区和存储引擎信息的. 分区信息直接是字符串形式. 结构如下
从iosize+tmp_key_length+rec_length开始
| 对象 | 大小 | 描述 |
|---|---|---|
| 2 | 填充\x00\x00 | |
| engine_len | 2 | 存储引擎名字的长度 |
| engine_name | engine_len | 存储引擎名字 |
| partition_len | 4 | 分区(字符串)长度 |
| partition_str | partition_len | 分区信息(字符串) |
例子
create table db1.t20250117_11(id int, name varchar(200)) PARTITION BY HASH(id);
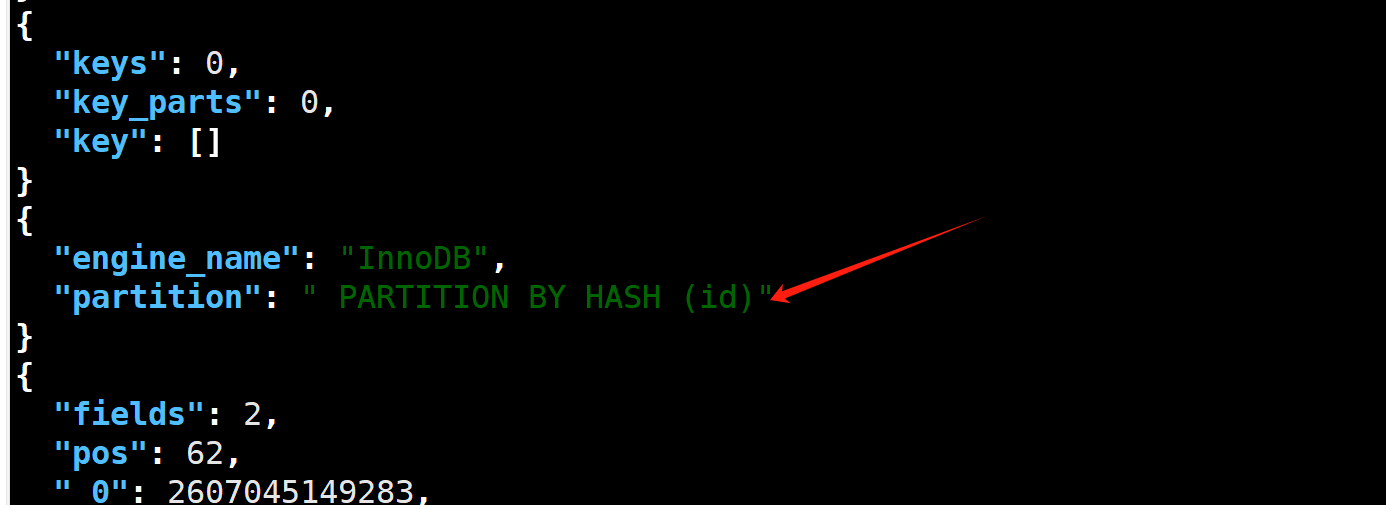
COMMENT
接着就是表的注释了, 前面那些信息对io_size取整(为了方便描述, 我们将其称为record_offset), 然后+46 即为注释的起始位置. 第1字节为注释大小, 后面就是注释的值了. 258的位置就是字段信息了, 那么注释的限制就是258-46吗? 当然不是. 当record_offset+46 之后不够存储comment的时候, 会将comment内容放到engine_data之后16字节后面, 并使用2字节表示大小, 之后存储comment值. 这两种存储方式是相似的, 格式如下:
| column1 | column2 | column3 |
|---|---|---|
| 对象 | 大小 | 描述 |
| comment_size | 1 or 2 | comment的大小 |
| comment | comment_size | comment值 |
而mysqlfrm这个时候又抽风了, 没有考虑这么多. (一般也不会写这么长的comment)
create table db1.t20250117_14(id int, name varchar(200), key(name)) comment 'aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa';
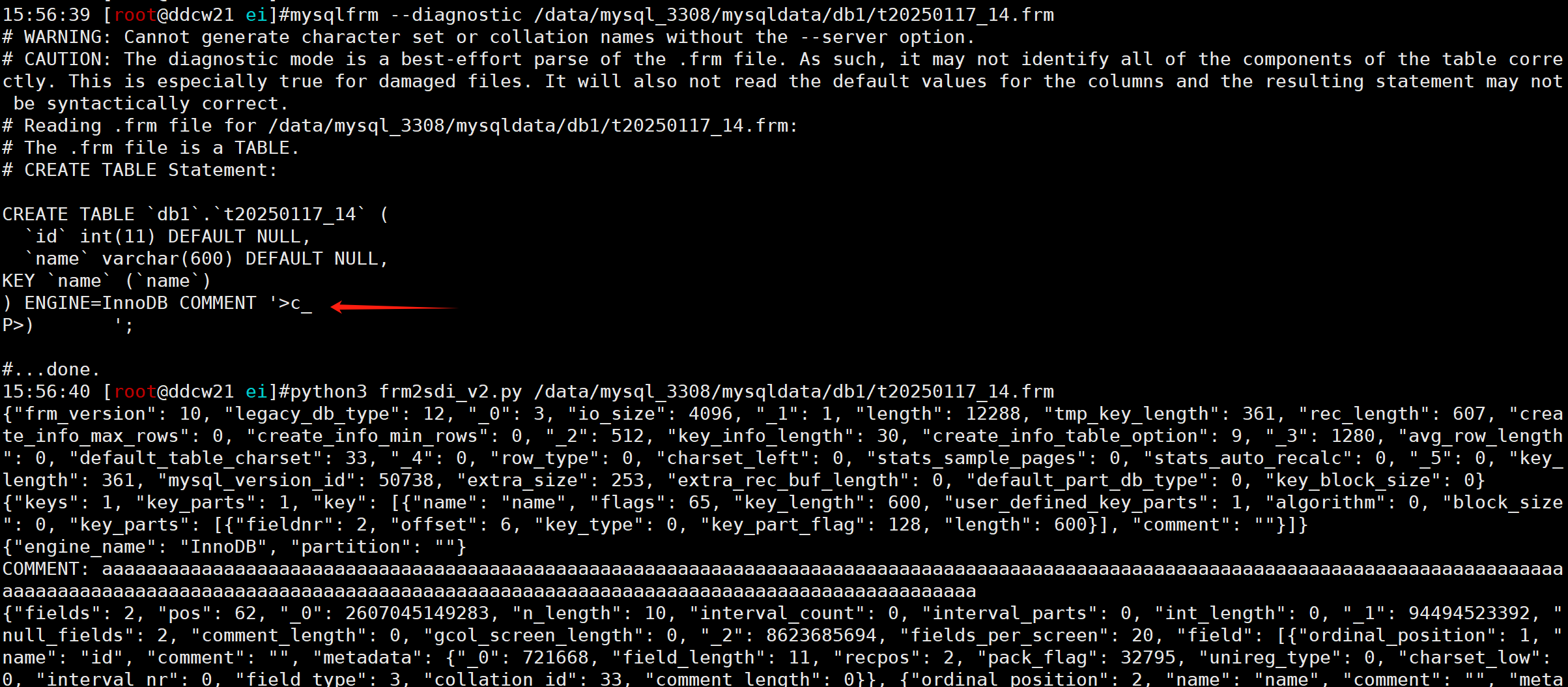
COLUMNS
最后一个就是字段信息了. (讲了这么多终于到字段信息了). 直接看结构吧
从((iosize+tmp_key_length+rec_length)/io_size)+1)*io_size+258开始
| 对象 | 大小 | 描述 |
|---|---|---|
| fields | 2 | 字段数量 |
| pos | 2 | Length of all screens |
| 6 | ||
| n_length | 2 | |
| interval_count | 2 | |
| interval_parts | 2 | |
| int_length | 2 | |
| 6 | ||
| null_fields | 2 | 可以为空的字段数量 |
| com_length | 2 | 注释长度+1 |
| gcol_screen_length | 2 | |
| 5 | ||
| fields_per_screen | 1 | 每这么多个列就刷一屏. 没啥用, 但就这么设计的. |
| 42 | ||
| column_name | 字段名字 | |
| column_metadata | fields*17 | 字段元数据信息, 比如符号,是否允许为空 |
| enum_data | 枚举/set类型的相关信息 | |
| column_comment | n | 字段的注释 |
这里面很多信息我们都是用不上的. 我们只挑部分信息看一下.
null_fields 表示可为空字段之和, 对于解析innodb动态行格式有用(sdi里面还得手动计算…)
fields_per_screen 如果字段多了, 还涉及到分屏, 而这分屏居然放到了frm文件里面, 不是很理解.
column_name就是记录字段的名字了. 由ordinal_position(逻辑位置),namesize和name组成. 需要注意的是fields_per_screen
column_metadata是字段的元数据信息, 每个字段固定使用17字节(不考虑低版本的frm), 比如是否为空,符号等各种信息.格式如下:
| 对象 | 大小 | 描述 |
|---|---|---|
| 1 | ||
| 1 | pos? | |
| 1 | ||
| field_length | 2 | 字段长度, 比如int(11), varchar(200) |
| recpos | 3 | |
| pack_flag | 2 | 比如是否为空.zero fill,signed |
| unireg_type | 1 | 生成列, 自增列之类的信息 |
| charset_low | 1 | 字符集的高位 |
| interval_nr | 1 | |
| field_type | 1 | 字段类型 |
| collation_id | 1 | 字符集 如果是geom的话 ,就是geom类型 |
| comment_length | 2 | 注释长度 |
column_metadata部分比较乱, 我们将其转为sdi的时候再细看.
主要是内容太多了, 比如field_length, 对于固定长度则为字符长度, 对于变长字段, 则为字节长度(需要注意字符集. 比如600, 在utf8mb3对应varchar(200), 在utf8mb4对应varchar(150), 而对于时间类型之类的, 则还包含了精度, 比如datetime(5),即:“char_length”: 25,“datetime_precision”: 5)
如果存在枚举类型, 则又enum_data信息, 格式如下:(这格式是不是看着眼熟)
| 对象 | 大小 | 描述 |
|---|---|---|
| flag | 1 | \xff |
| enum/set value | n | 枚举或者set的值 |
| flag | 1 | \xff |
| … | ||
| \x00 | ||
| flag | 1 | |
| … |
总结
frm文件记录了这么多信息, 那我问你, 表名叫啥呢? frm文件中未记录表的名字和库的名字, 所以库/表名全来源于文件路径. 而sdi中则包含了这部分信息.
对于frm的解析, 我们主要参考mysqlfrm工具和mysql源码(sql/table.cc create_frm open_binary_frm make_field_from_frm include/my_base.h等)
frm转为sdi应该是分3篇来讲, 本篇未frm结构, 下一篇为sdi结构, 最后一篇为frm转sdi.
最终要实现的frm2sdi效果差不多如下:
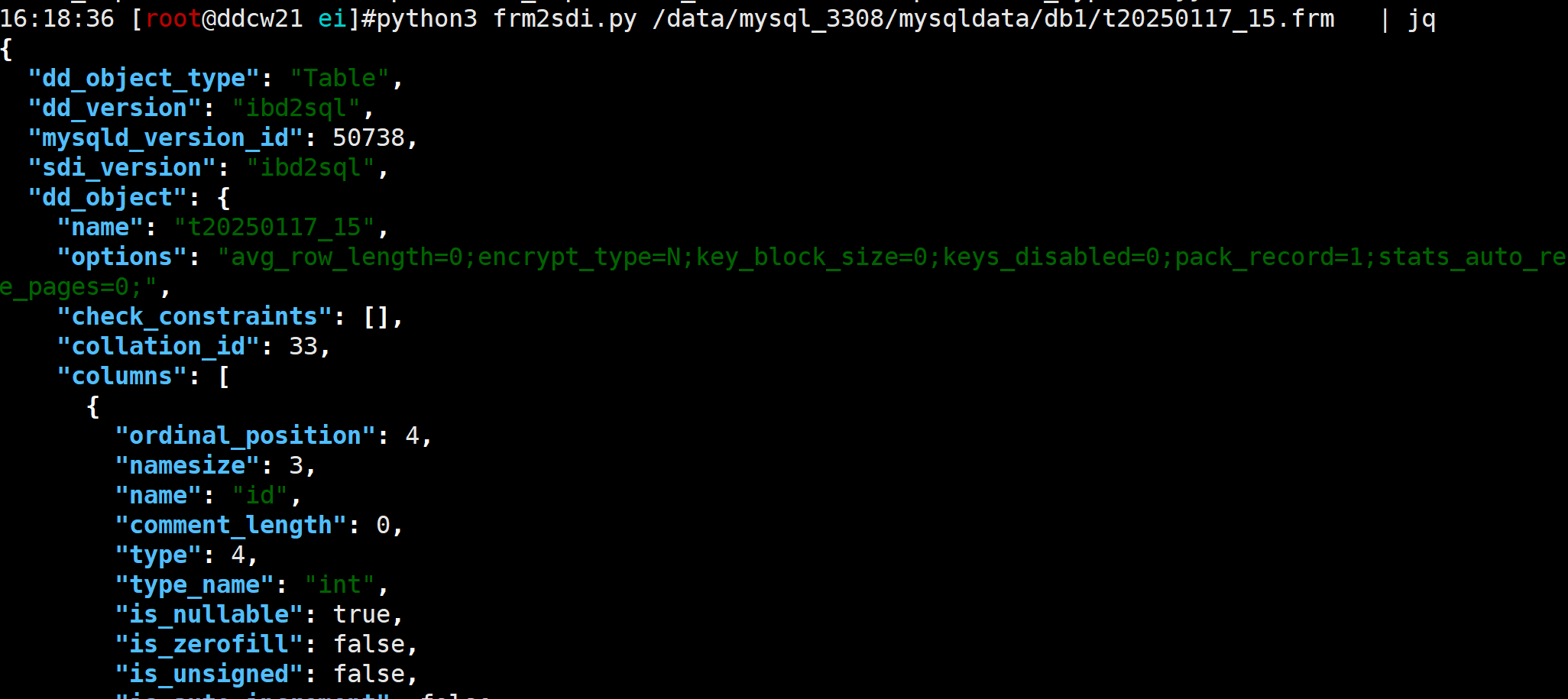
我们还是来画个图总结下吧:
参考:
https://github.com/mysql/mysql-utilities
https://github.com/mysql/mysql-server
