




自 StarRocks 3.0 起,社区明确了以 Lakehouse 为核心的发展方向。Lakehouse 的价值在于融合数据湖与数据仓库的优势,能有效应对大数据量增长带来的存储成本压力,做到 single source of truth 的同时继续拥有极速的查询性能,同时也为 AI 时代的多样化数据需求提供可扩展的高效访问能力。
构建 Lakehouse 后,你将拥有开放统一的数据存储与基于一份数据,支持多样化的 workload,服务企业 AI、BI 的数据应用,进而实现“One Data, All Analytics” 的业务价值。
在之前的版本中,StarRocks 已对 Lakehouse 的性能与易用性进行了一年多的打磨;在 3.4 版本中,我们聚焦 AI 场景的扩展,推出了 Vector Index、Python UDF 支持,并实现了 Arrow Flight 协议,为数据分析和 AI 检索场景提供更强大的功能和性能支持,帮助用户更高效地实现业务目标。
Lakehouse 的优化也在此次版本中得到了进一步的提升:从数据文件管理、数据读取、统计辅助、查询优化到数据缓存等多个环节进行了深度优化,显著提升了系统性能。同时,湖生态对接能力也得到了持续完善,建表、数据导入和系统稳定性等方面的改进进一步增强了 StarRocks 的易用性和可靠性。
更强的 AI 场景支持
Vector Index
向量数据库能够支持快速的高维向量相似性搜索,通过近似最近邻(ANN)算法,高效地找到与给定向量最相似的其他向量,这在推荐系统、自然语言处理、图像和文本检索等领域至关重要。
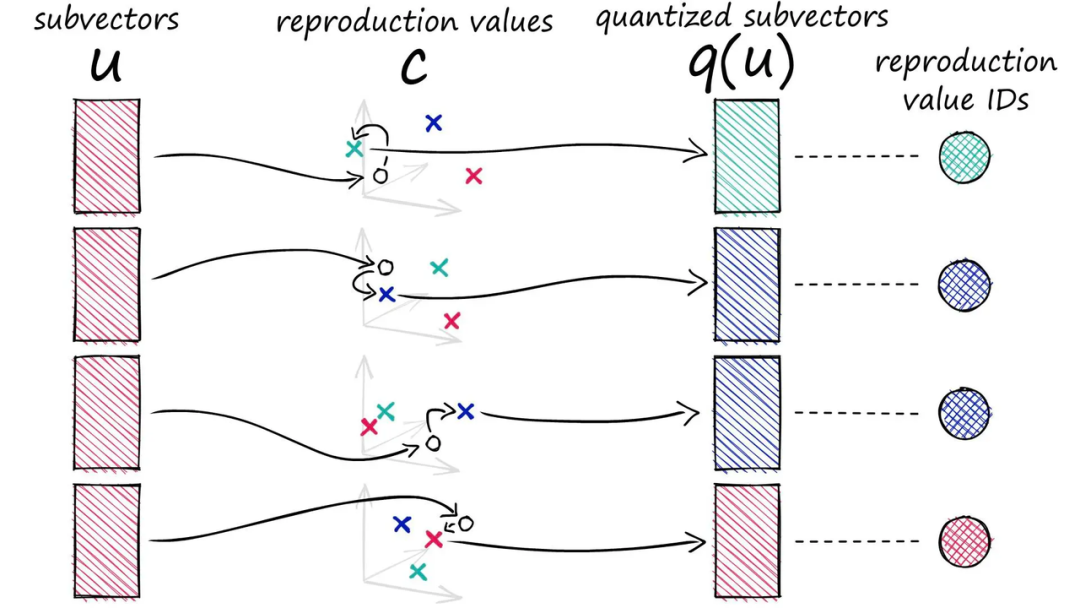
在 StarRocks 3.4 版本中,我们引入了 Vector Index,支持两种重要且常用的索引类型:IVFPQ(Inverted File Index with Product Quantization,倒排乘积量化)和 HNSW(Hierarchical Navigable Small World,分层小世界图)。从而能够在大规模、高维向量数据中进行高效的近似最近邻搜索(ANNS),这一技术在机器学习中尤为重要。
使用方式也很简单,和普通的建表、导入、数据检索没有太大的区别。
-- Create an vector index based on an ARRAY field by using IVFQP (similar to HNSW)CREATE TABLE test_ivfpq (id BIGINT(20),vector ARRAY<FLOAT>,INDEX ivfpq_vector (vector) USING VECTOR ("index_type" = "ivfpq", ... -- some specific parameters));-- Insert some data.INSERT INTO test_ivfpq VALUES (1, [1,2,3,4,5]), (2, [4,5,6,7,8]);-- Do vector index search with normal SQL filter: to find some nearest vectorsSELECT *FROM (SELECT id, approx_l2_distance([1,1,1,1,1], vector) scoreFROM test_ivfpq) aWHERE id in (1, 2, 3) AND score < 40ORDER BY scoreLIMIT 3;
Python UDF[Experimental]
StarRocks 目前提供了数百个常用函数,同时支持 Java UDF,帮助用户实现更多业务需求中的特殊函数。然而,考虑到 AI 领域的用户更为熟悉 Python,StarRocks 3.4 版本新增了对 Python UDF 的支持。这一功能让用户可以灵活高效地定义自己的函数,便于对训练数据进行预处理、嵌入式模型推理或使用机器学习相关的 Python 库等。
使用起来也非常方便,只需通过 Python 代码就能轻松扩展功能,满足复杂的业务需求。
-- Create a python function with inline mode to clean a textCREATE FUNCTION python_clear_text(STRING) RETURNS STRINGtype = 'Python'symbol = 'clear_text'file = 'inline'input = 'scalar' -- you can use arrow to improve the computation performanceAS$$import stringdef clear_text(input_text):translator = str.maketrans('', '', string.punctuation)cleaned_text = input_text.translate(translator)return cleaned_text.lower()$$;-- Do cleaning text like a normal functionSELECT id, python_clear_text(str_field)FROM tbl; -- columns of tbl: id, str_field
目前只支持用户自定义标量函数(Scalar UDF)。
为了提升 Python UDF 的处理性能,也可以使用 vectorized input,使用上基本一样。
创建复杂的处理函数时,也可以使用打成 zip 包的 python 文件。
file
指定 zip 包地址。
Arrow Flight[Experimental]
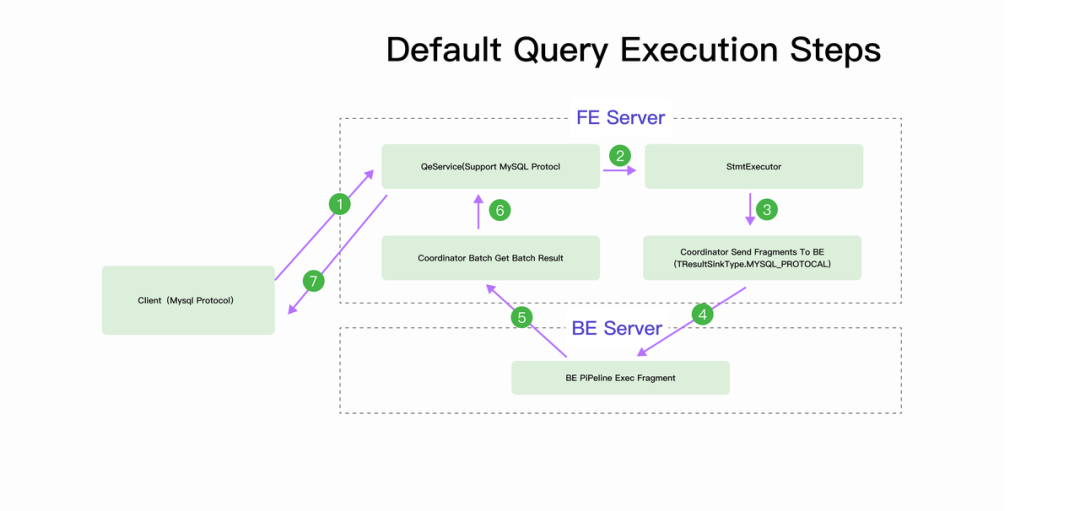
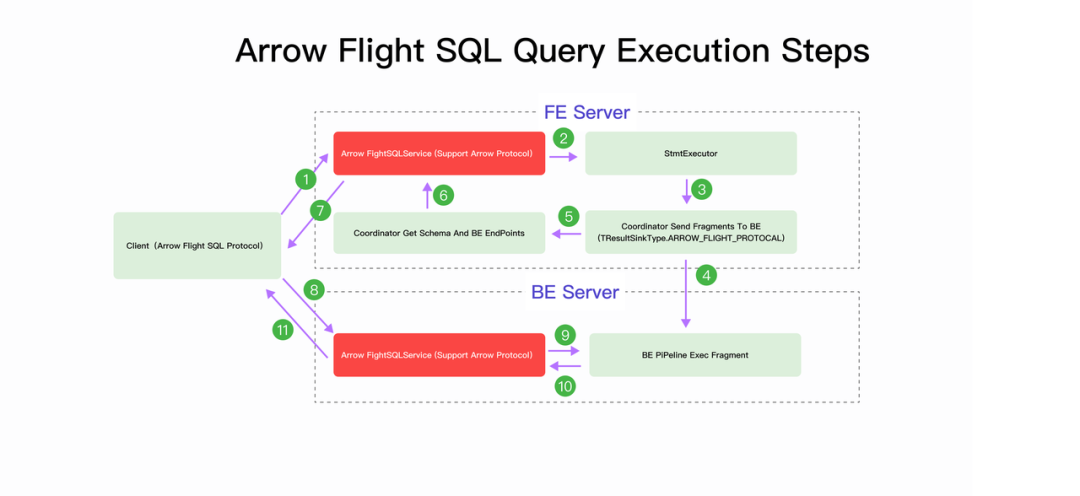
如果经常需要将数据库中的大量数据导出后做机器学习相关工作,V3.4 中提供的 Arrow Flight 就能比较好的满足这个需要。相对于 MySQL 协议,Arrow Flight 协议能够更快速、更高效地获取大批量的查询结果,更好地支持涉及多种数据源和系统的 AI 应用中跨系统间的数据协作。同时,也能减少对 StarRocks FE 的查询压力。
全面进化的 Lakehouse 能力
自 v3.0 起,StarRocks 正式开启了 Lakehouse 新范式。在此过程中,我们通过对存算一体功能和性能的持续对齐,提供了更高性价比的存算分离架构,并不断加强对 Iceberg、Hudi、Delta Lake 等生态的支持,推动高性能湖数据分析的实现。同时,物化视图的持续优化和建表、导入能力的简化,进一步推动了 Lakehouse 新范式的深度落地和快速发展。到 v3.4,StarRocks 在功能、性能、易用性和稳定性等方面进一步提升,全面强化了 Lakehouse 能力。
Data Lake Analytics
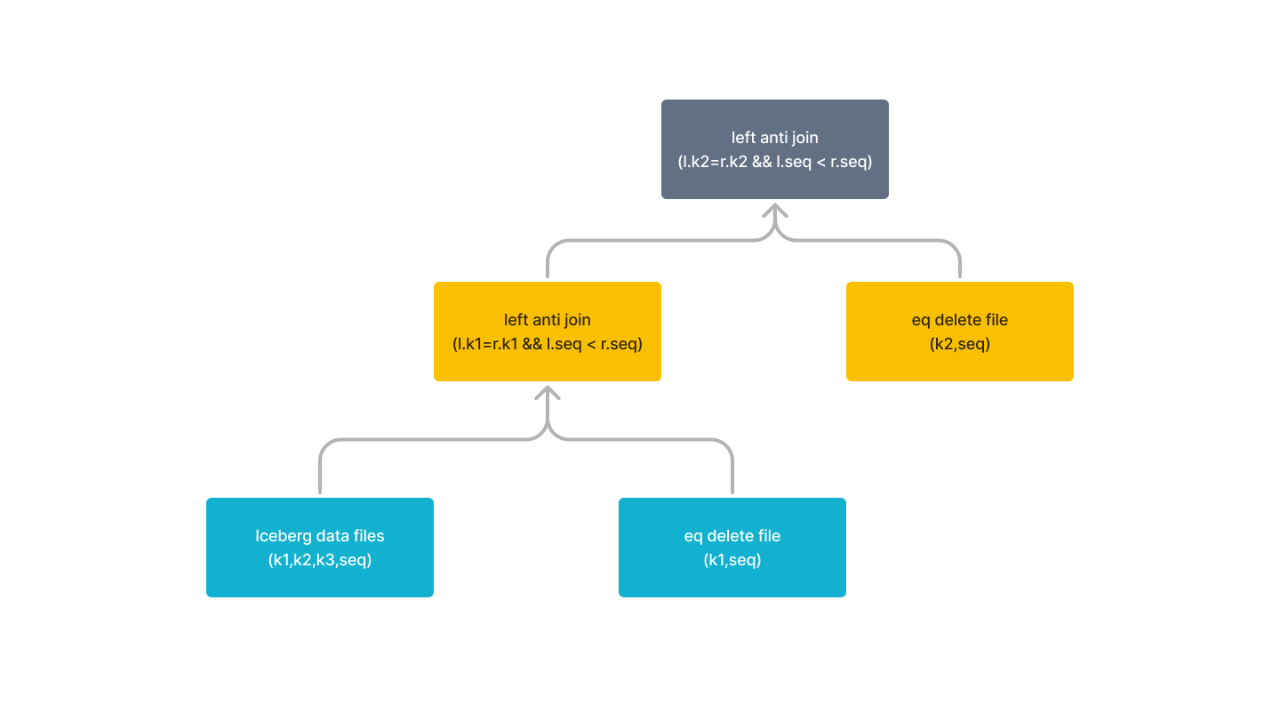
Iceberg v2 equality delete 读取优化
V3.3 中,StarRocks 已经通过优化 page index 处理、使用 SIMD 优化计算、优化 ORC 小文件读取等,优化了读取 data file 时查询性能。同时,V3.3 中增加了对 Iceberg V2 表的 equality delete 的支持,从而使得用户能够高效分析使用 Flink 写入的 Iceberg upsert 数据。然而,当 upsert 操作频繁时,查询大量 Iceberg 数据时可能会重复读取相同的 delete file(一个delete file 可能对应多个data file),导致性能下降并占用大量内存。
为了优化这一问题,3.4 版本通过单独生成一个 Iceberg eq-delete scan node 的方式改写 Query plan,采用 shuffle 或 broadcast delete file 数据,从而避免重复读取。在 delete file 较多的场景中,查询性能可提升数倍。
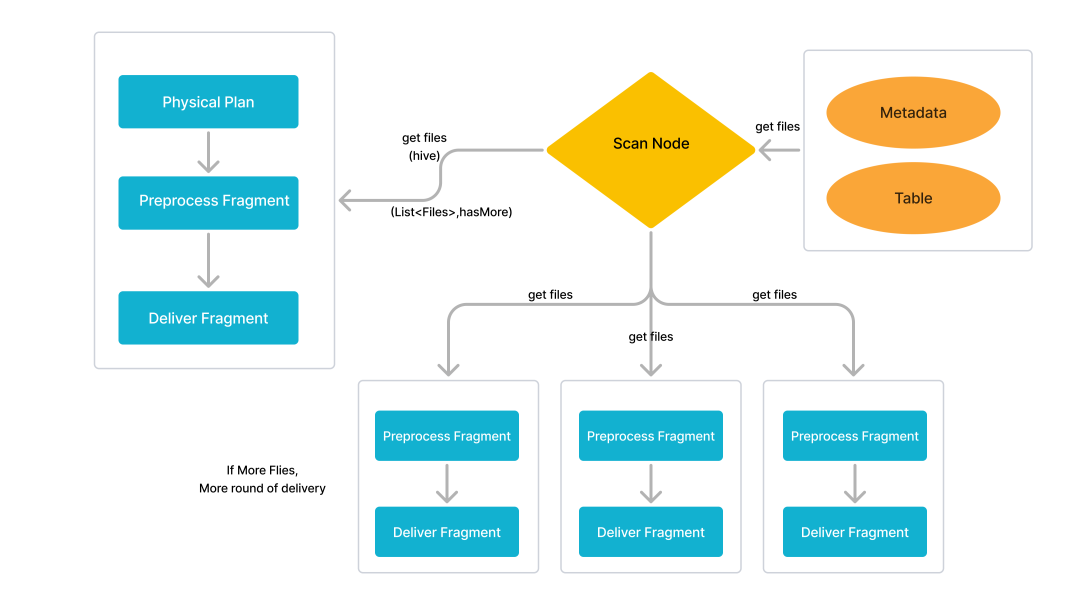
异步投递查询片段(Async scan framework)
异步投递查询片段(Async scan framework)
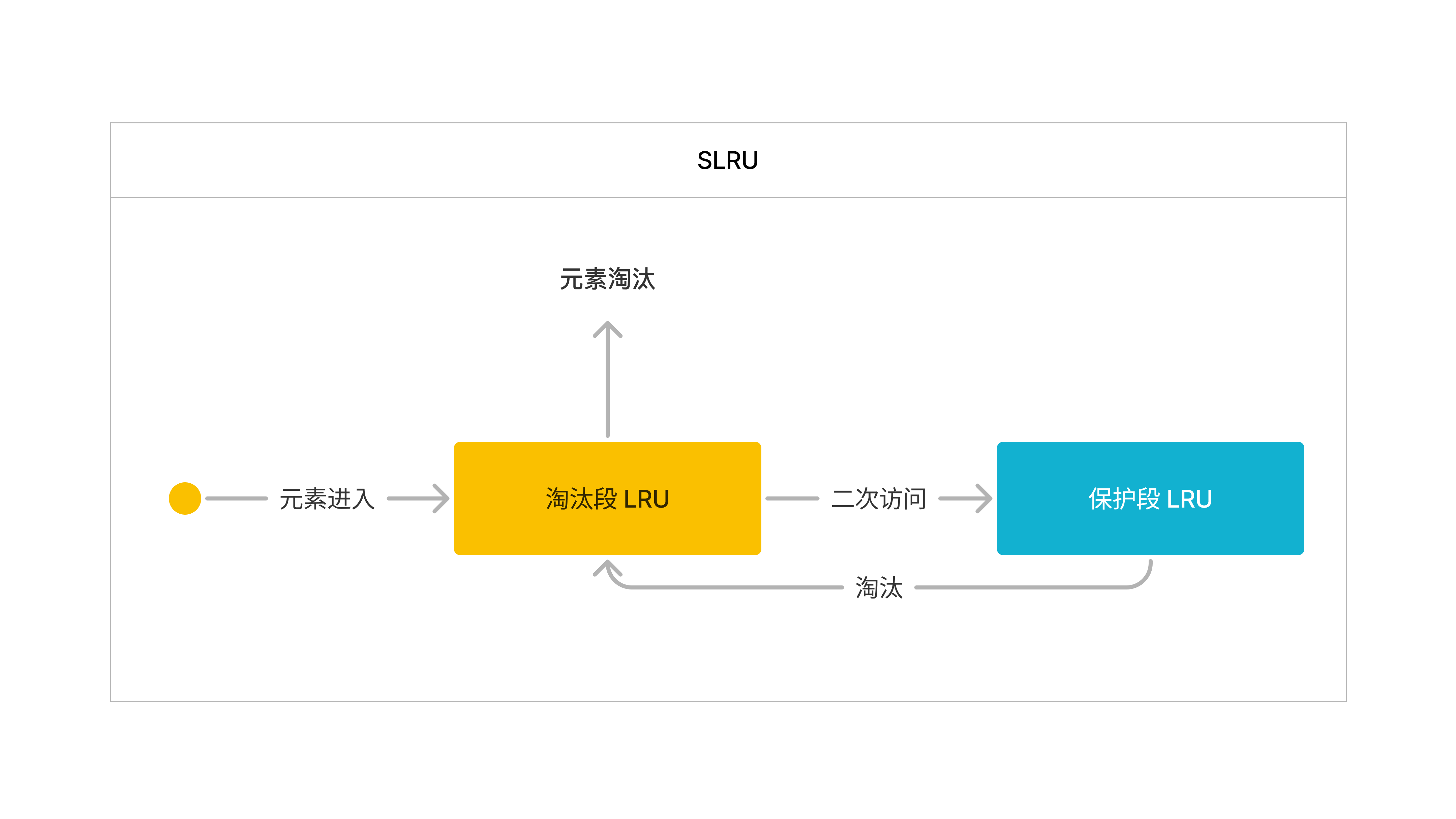
Data cache 优化和统一
Data cache 优化和统一
通过引入全新的 Segmented LRU (SLRU) 缓存淘汰策略,将缓存空间分为淘汰段和保护段,分别采用 LRU 策略进行管理,从而有效减少偶发大查询引起的缓存污染问题,提升缓存命中率并减少查询性能波动。在模拟测试中,查询性能提升幅度可达 70% 至数倍。
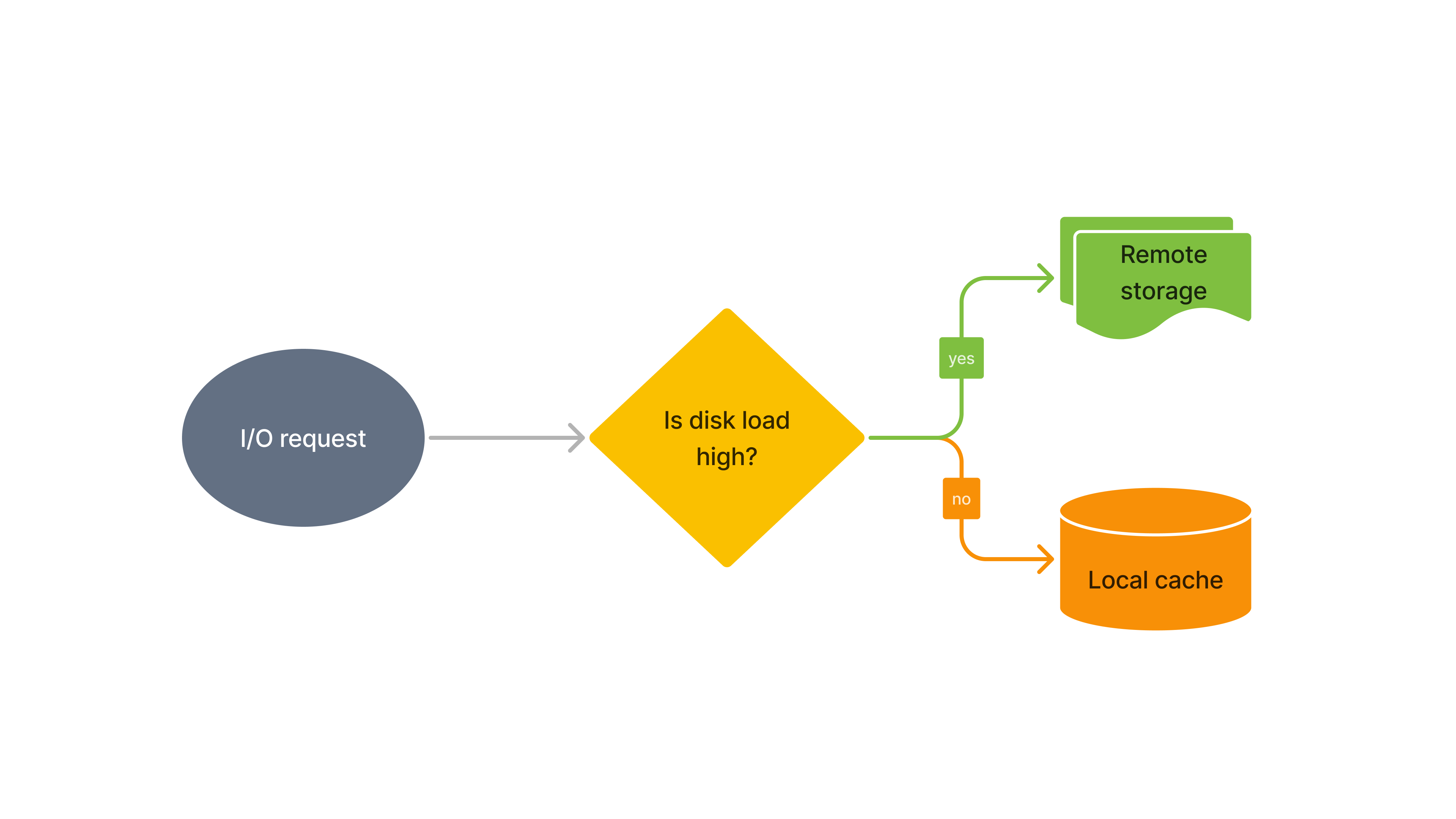
此外,我们还优化了 Data cache 的自适应 I/O 策略,使得系统能够根据缓存盘的负载和性能,自适应地将部分查询请求路由到远端存储。这一优化在高负载场景下显著提升了系统的访问吞吐能力,查询性能可提升 1 倍至数倍。
为了提升易用性,我们统一了存算分离和数据湖查询中 Data Cache 的内部实例、配置参数和观测指标。这不仅简化了配置过程,还优化了资源的使用率,因为不再需要为每个实例单独预留资源。
深入裁剪和谓词下推
深入裁剪和谓词下推
利用数据统计和历史查询优化查询计划
利用数据统计和历史查询优化查询计划
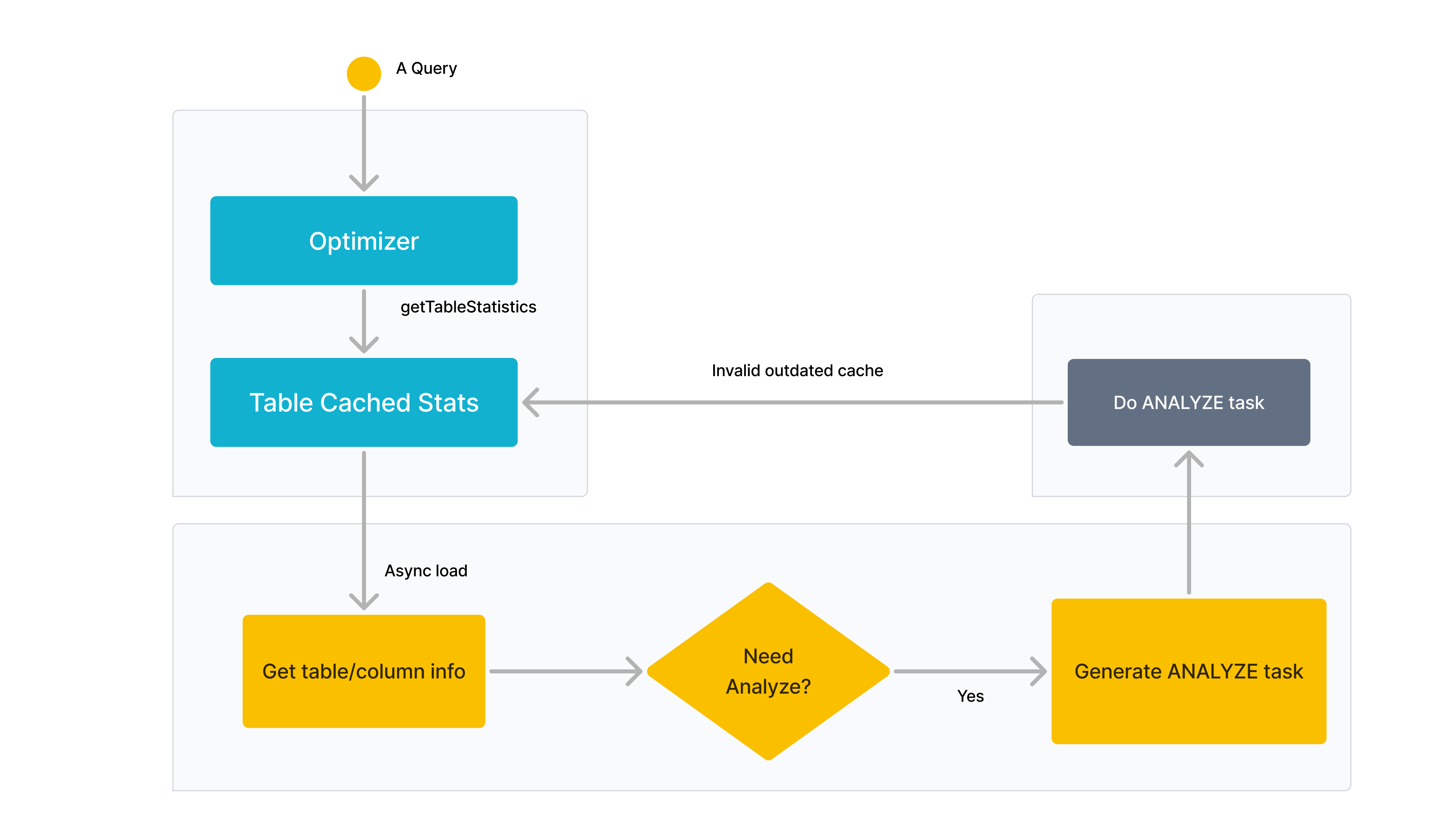
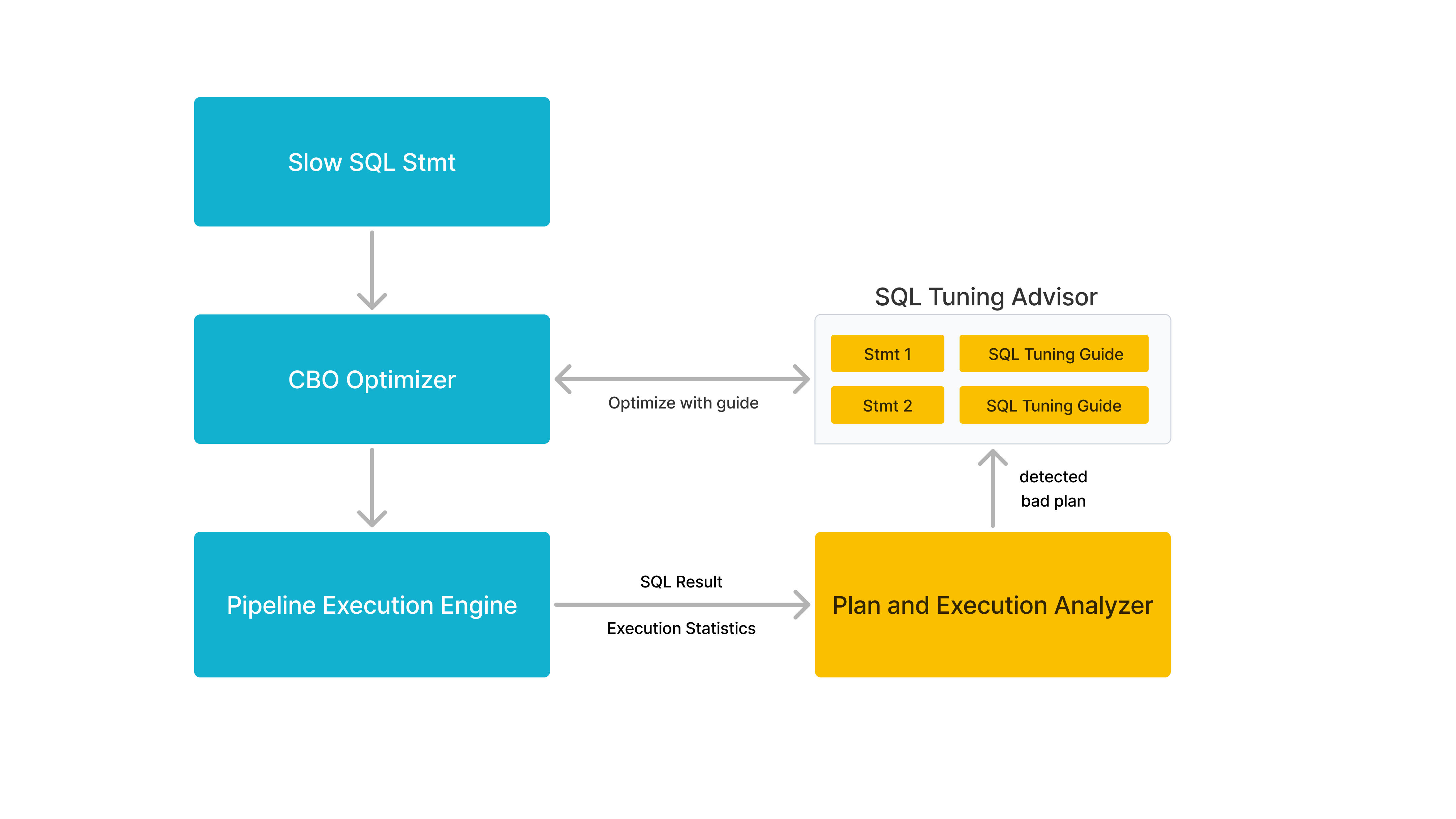
同时,V3.4 还提供了 Query Feedback 功能,这是利用历史查询计划优化未来查询性能的一项重要进展。通过该功能,系统会持续收集慢查询,根据执行详情自动分析一条 SQL 的Query Plan 是否存在潜在的优化空间,并可能生成专属的调优建议。当后续遇到相同的查询时,系统能够对此 Query Plan 进行局部调整,以生成更高效的 Query Plan,从而进一步提升查询性能。
Data Lake 生态支持
Data Lake 生态支持
在持续提升查询性能的同时,StarRocks 也在不断完善 Data Lake 生态的支持。本版本中,我们支持了 Iceberg Time Travel 功能,允许用户创建或删除 BRANCH 和 TAG,并通过指定 TIMESTAMP 或 VERSION 来查询特定分支或标签的数据。这使得用户能够轻松访问不同版本的数据,对于恢复意外删除的数据尤为重要。同时,也支持在不同分支上进行数据写入,以便进行并行开发测试、变更隔离等。
-- Create a BRANCHALTER TABLE iceberg.sales.order CREATE BRANCH `test-branch`AS OF VERSION 12345 -- Create a BRANCH on the specified snapshot idRETAIN 7 DAYSWITH SNAPSHOT RETENTION 2 SNAPSHOTS;-- Write data into the BRANCHINSERT INTO iceberg.sales.order [FOR] VERSION AS OF `test-branch`SELECT k1, v1 FROM tbl;-- Query data on the BRANCHSELECT * FROM iceberg.sales.order VERSION AS OF `test-branch`;-- You can fast forward your main branch to the test-branch after you've finished a testALTER TABLE iceberg.sales.orderEXECUTE fast_forward('main', 'test-branch');
更易用的建表和导入
在专注极速查询性能的同时,StarRocks 也持续关注易用性的提升。在本版本中,我们继续优化了建表和数据导入功能,增加了多个新功能,显著提升了易用性。
建表
建表
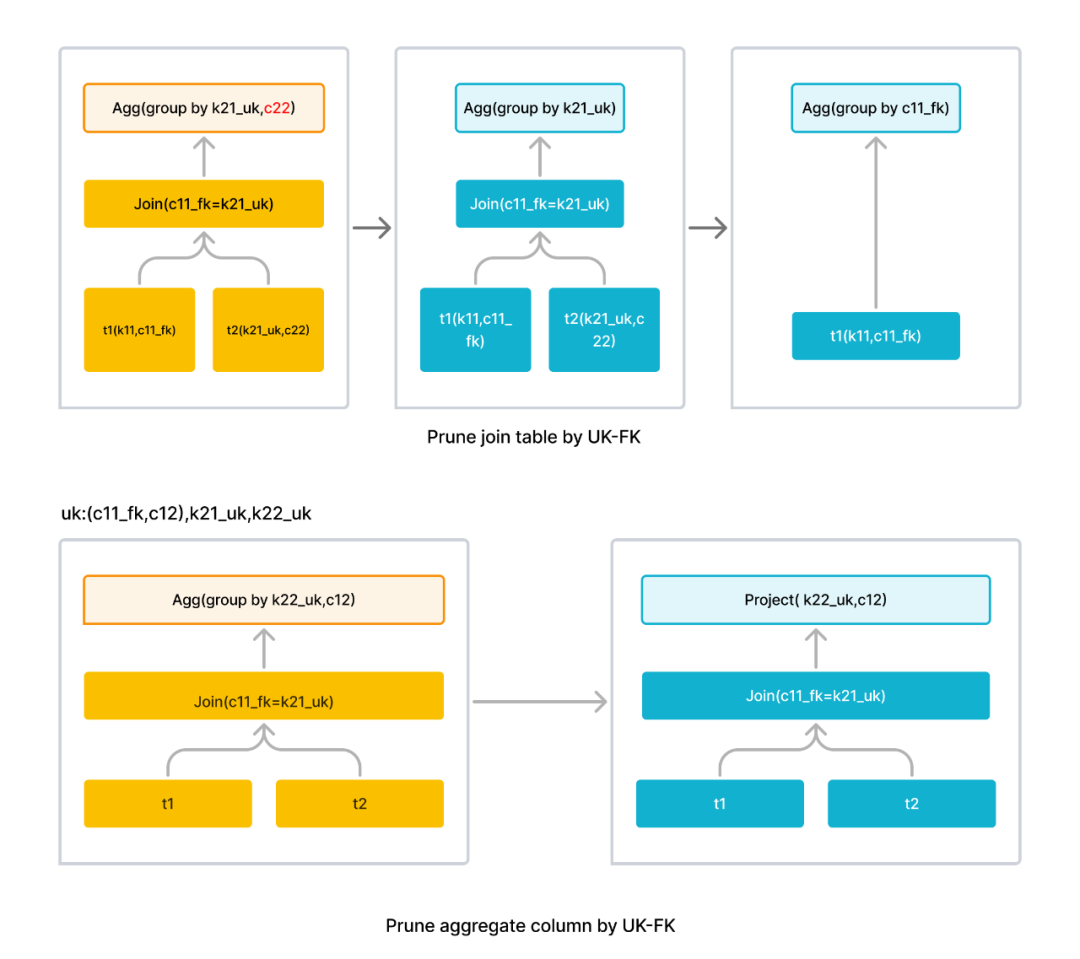
用法上,基本和原有方式一样定义聚合表,只是聚合列指定具体的通用聚合函数即可。然后在使用时,根据不同场合,需要使用到几个不同的函数来处理和实现聚合。
-- Create a AGGR table with some aggregate columnsCREATE TABLE test_create_agg_table (dt VARCHAR(10),v BIGINT sum, -- normal aggregate columnsavg_agg avg(bigint), -- new general aggregate functionsarray_agg_agg array_agg(int),min_by_agg min_by(varchar, bigint))AGGREGATE KEY(dt)PARTITION BY (dt)DISTRIBUTED BY HASH(dt) BUCKETS 4;在创建表后,根据不同使用场景需要,选择聚合函数对应的不同的 combinator 函数:
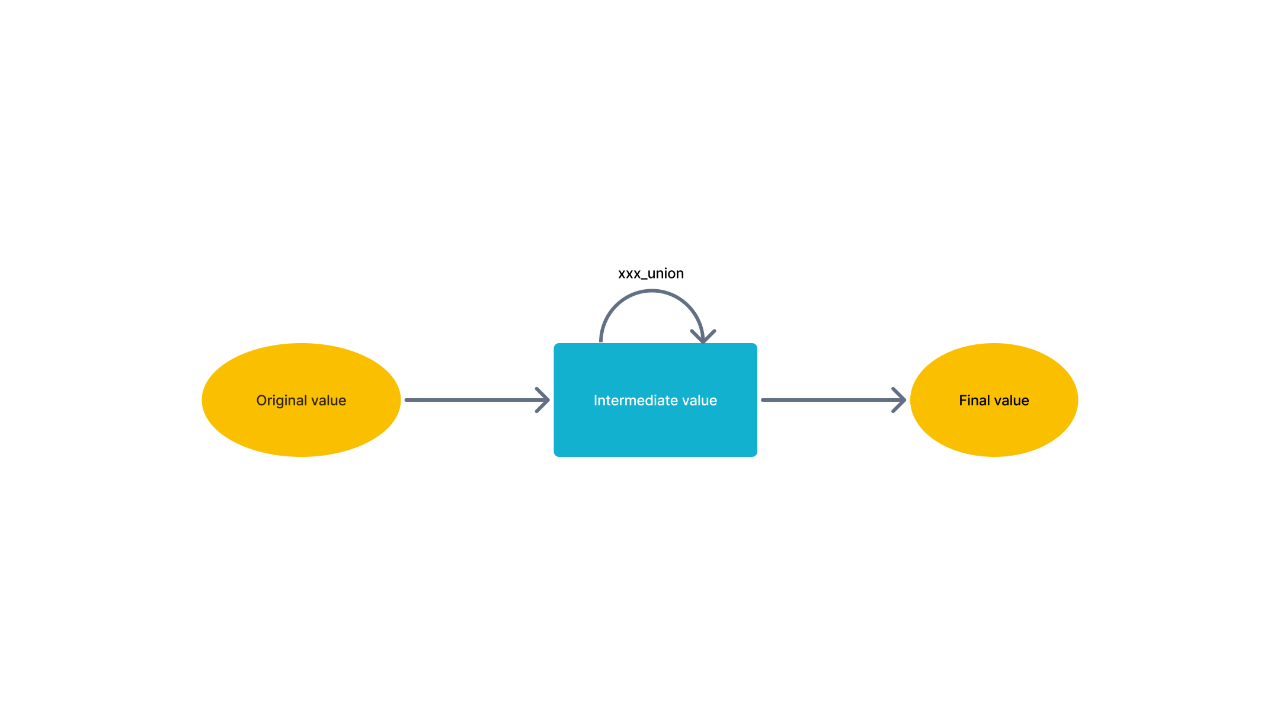
对于导入数据,需要使用
xxx_state(original_value)
函数来转化数据为中间态数据并存储到 StaRocks 中。以聚合函数avg
为例,中间态数据是对输入数据 value 分别求 sum 和 count 后的两个值(实际为一个 binary 类型字段),并存储,而不是一个原值 value。INSERT INTO test_create_agg_tableSELECT dt, v, -- directly use v when the aggregate func is SUMavg_state(id), -- use xxx_state() to get the intermediate valuearray_agg_state(id),min_by_state(province, id)FROM t1;对于中间态数据做聚合并继续存储为中间态数据时,需使用
xxx_union(mid_value)
来部分聚合中间态数据。对于avg
来说,相当于把中间态的 sum/count 做局部聚合,并继续存储为 sum/count 两个值。SELECT dt, sum(v),avg_union(avg_agg),array_agg_union(array_agg_agg),min_by_union(min_by_agg)FROM test_create_agg_tableGROUP BY dt;根据中间态数据计算最终聚合结果时,需要使用
xxx_merge(mid_value)
。对于avg
,相当于计算sum/count
来最终得到average(id)
。SELECT dt, sum(v),avg_merge(avg_agg),array_agg_merge(array_agg_agg),min_by_merge(min_by_agg)FROM test_create_agg_tableGROUP BY dt;对于物化视图,则可以直接使用
xxx_union(xxx_state(origin_value))
来定义聚合列:CREATE MATERIALIZED VIEW test_mv1 ASSELECT dt, min(id) as min_id, sum(id) as sum_id, -- old aggr funcsavg_union(avg_state(id)) as avg_id,array_agg_union(array_agg_state(id)) as array_agg_id,min_by_union(min_by_state(province, id)) as min_by_province_idFROM t1GROUP BY dt;
使用时则很简单,直接在 base 表上调用聚合函数即可,系统会自动进行透明改写。
SELECT dt, min(id), sum(id)avg(id),array_agg(id),min_by(province, id)FROM t1GROUP BY dt;
CREATE TABLE multi_column_part_tbl (dt DATETIME,tenant_id INT,region_id INT,event STRING)PARTITION BY tenant_id, date_trunc('month', dt), FLOOR(FLOOR(region_id/10000) * 10000)DISTRIBUTED BY RANDOM;
这里由 tenant ID、month、以及 region 区间组合成分区列,其中 region 区间是一个函数表达式。从而将数据按照 tenant ID 划分的同时,也按照 month 粒度进一步来划分分区,以适用于一般只查较新数据的场景,并且还按照 region 的大区间进行划分,以适合具有区域查询特点的场景。
导入
导入
2.1 INSERT & FILES
从 V3.1 开始,StarRocks 就引入了 FILES 表函数,用户可以通过 INSERT from FILES 简单实现数据导入。此次版本,我们对该功能进行了全面优化,使得 INSERT from FILES 基本可以替代 Broker Load,成为批量数据导入的首选方式,并且使用起来更加简便、直观。具体优化包括:
支持 LIST 远程存储中的目录和文件,用户可以在导入前轻松查看和核对数据文件及目录结构; 引入了 BY NAME 映射方式,能将数据文件中的列映射到目标表中列,特别适用于列数较多且列名相同的情况; 支持下推 target table schema 及合并不同 schema 的文件,更好地自动推断和处理导入数据的 schema,让导入变得更简单智能; 新增了 PROPERTIES 子句,支持 strict_mode、max_filter_ratio 和 timeout 等参数,从而 INSERT 中也可以根据导入数据的质量控制导入行为。
-- 1. List the data files, check it whether they are indeed what you want to loadSELECT * FROM FILES('path' = 's3://bucket/path/to/file','list_files_only' = 'true', -- list file, not the data content'list_recursively' = 'true',);-- 2. View the data schema by DESC or direct SELECTDESC FILES(...);SELECT * FROM FILES(...) LIMIT 5;-- 3. Use a simple CTAS to create a table and load some dataCREATE TABLE ctas_tbl ASSELECT * FROM FILES (...) LIMIT 10;-- 4. Now, it's time to create the final target table, and load the data.-- 4.a Create a table, refer to the schema of `DESC` command or SELECT statement.CREATE TABLE fine_tbl(id INT,v2 VARCHAR(16),v3 DECIMAL(18, 10));-- 4.b Load the data, no matter the data have done some schema change/evolution or notINSERT INTO fine_tbl BY NAMEPROPERTIES ('strict_mode' = 'true','max_filter_ratio' = '0.001', -- only 0.1% error rows at most are allowed'timeout' = '3600')SELECT * FROM FILES('path' = 's3://bucket/path/to/dir/*/*', -- columns from files are: v2, id, v3'format' = 'parquet','fill_mismatch_column_with' = 'NULL' -- fill NULL if some columns are missed in some files);
/path/to/dir/
目录下一些文件有 3 列,一些文件可能只有 2 列甚至 1 列,FILES 支持合并不同 schema 的文件,并提供fill_mismatch_column_with
参数以控制有缺失列时的行为:补NULL
或报错。数据文件中的 id
列可以直接按照INT
读取数据,并可能过滤溢出的数据。(通过 FE 配置项files_enable_insert_push_down_schema
设置)最终数据文件中的列可以直接按照名字映射导入到目标表中,而不需要一列列对应设置,对于导入几百上千列时的大宽表特别方便。
2.2 INSERT OVERWRITE
除了用于数据导入,INSERT 还广泛应用于 ETL 过程。用户常通过 INSERT INTO SELECT 实现数据的批量处理,将数据导入到另一个表中,甚至形成一个 pipeline 处理。同时,遇到需要修复数据场景时,可以使用 INSERT OVERWRITE 来修复错误数据。
在本版本中,INSERT OVERWRITE 新增支持 Dynamic Overwrite 语义。系统能够自动根据导入的数据创建分区,并只覆盖包含新数据的分区,未涉及的老分区将不被删除。这对于那些在修复数据时仅需覆盖部分分区、但无法明确指定分区或不易指定分区的场景尤为方便。由于新导入的数据可能涉及不存在的分区,而修复数据可能涉及多个分区,且由于使用表达式分区或多列 List 分区,用户可能无法清楚了解所有分区的名称,因此让系统自动确定并替换分区的方式显得尤为实用。
使用方法很简单,设置 session 变量 dynamic_overwrite = true
即可。
SET dynamic_overwrite = true;-- Use INSERT OVERWRITE just as normalINSERT OVERWRITE part_tblSELECT * FROM nonpart_tbl;
当然,也可以设置 dynamic_overwrite = false
以让系统替换所有分区。
2.3 Merge commit
除了上述的易用性改进,本版本的 StarRocks 还新增了 merge commit 功能,以优化高并发实时数据导入的场景。merge commit 功能能够将同一时间区间内针对同一表的多个并发 Stream Load 合并为一个导入事务进行提交,从而提升实时数据导入的吞吐能力,尤其适用于高并发、小批量(从 KB 到几十 MB)的实时导入场景。
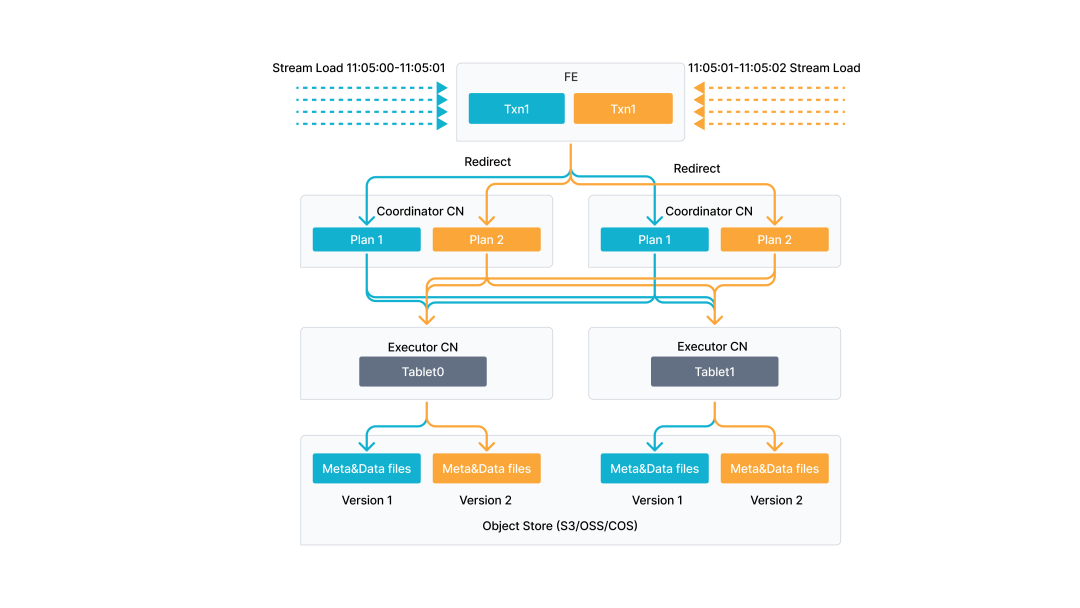
FE 会按照作业配置的允许合并时间划分为一个个时间区间,将一个时间区间内的很多小批量导入作业合并提交为一个新的导入作业,再类似于 Broker Load 一样进行数据导入。
使用方式和原来的 Stream Load 方式基本一样,加入几个 merge commit 控制参数即可:
curl --location-trusted -u <username>:<password> \-H "Expect:100-continue" \-H "column_separator:," \-H "columns: id, name, score" \-H "enable_merge_commit:true" \-H "merge_commit_interval_ms:1000" \-H "merge_commit_parallel:2" \-T example1.csv \-XPUT http://<fe_host>:<fe_http_port>/api/mydb/tbl/_stream_load
Stability & Security
系统的高可用性是作为基于数据多副本的 StarRocks 系统天生注重的一个能力。V3.4 中,StarRocks 提供了 Graceful Exit 功能,确保在 BE/CN 节点退出时查询能够在短时间内继续执行完毕,从而尽量减少节点升降级过程对业务的影响,进一步提升系统的高可用性。
此外,通过实现 Follower FE 支持 Checkpoint,减少了对 Leader FE 的内存压力,进一步增强了系统的稳定性。在细节方面,诸如日志打印优化等小改进,都有效提升了系统的稳定性和整体表现。
在数据保护与容灾方面,StarRocks 在 V3.2 中引入的 Cluster Sync 功能提供了高可用的容灾能力,但备份/恢复依然是最基础且高性价比的容灾手段。因此,StarRocks 3.4 版本进一步完善了备份功能,支持备份 Logical View、External Catalog 等更多对象,同时也支持备份采用表达式分区和 List 分区的表;并且,也优化了备份性能,能达到了每节点 1GB/s 的备份速度,基本能够满足大部分场景的基础需求。
Release note:https://docs.mirrorship.cn/zh/releasenotes/release-3.4/ 下载:https://www.mirrorship.cn/zh-CN/download/starrocks
关于 StarRocks
StarRocks 是隶属于 Linux Foundation 的开源 Lakehouse 引擎 ,采用 Apache License v2.0 许可证。StarRocks 全球社区蓬勃发展,聚集数万活跃用户,GitHub 星标数已突破 9500,贡献者超过 450 人,并吸引数十家行业领先企业共建开源生态。
StarRocks Lakehouse 架构让企业能基于一份数据,满足 BI 报表、Ad-hoc 查询、Customer-facing 分析等不同场景的数据分析需求,实现 "One Data,All Analytics" 的业务价值。StarRocks 已被全球超过 500 家市值 70 亿元人民币以上的顶尖企业选择,包括中国民生银行、沃尔玛、携程、腾讯、美的、理想汽车、Pinterest、Shopee 等,覆盖金融、零售、在线旅游、游戏、制造等领域。


行业优秀实践案例
泛金融:中国民生银行|平安银行|中信银行|四川银行|南京银行|宁波银行|中原银行|中信建投|苏商银行|微众银行|杭银消费金融|马上消费金融|中信建投|申万宏源|西南证券|中泰证券|国泰君安证券|广发证券|国投证券|中欧财富|创金合信基金|泰康资产|人保财险
互联网:微信|小红书|滴滴|B站|携程|同程旅行|芒果TV|得物|贝壳|汽车之家|腾讯大数据|腾讯音乐|饿了么|七猫|金山办公|Pinterest|欢聚集团|美团餐饮|58同城|网易邮箱|360|腾讯游戏|波克城市|37手游|游族网络|喜马拉雅|Shopee
新经济:蔚来汽车|理想汽车|吉利汽车|顺丰|京东物流|跨越速运|沃尔玛|屈臣氏|麦当劳|大润发|华润集团|TCL |万物新生|百草味|多点 DMALL|酷开科技|vivo|聚水潭|泸州老窖|中免集团|蓝月亮|立白|美的|伊利|公牛
