




* GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
本文将介绍如何从 PostgreSQL 到 GreatSQL 的数据迁移,并运用 AI 协助迁移更加方便。迁移的方式有很多,例如:
pg_dump:导出SQL文件,修改后导入 GreatSQL 数据库。 COPY:导出txt文本文件,导入 GreatSQL 数据库。 pg2mysql:从 PostgreSQL 迁移到 MySQL/GreatSQL 工具。 GreatDTS:商业的异构数据库迁移工具。
本文将介绍 pg_dump
和 COPY
两种方法迁移。
PostgreSQL 和 GreatSQL 区别
PostgreSQL
和MySQL也一样,PostgreSQL也是个非常优秀的开源数据库。它的特色是强调扩展性、数据完整性和高级特性,具有出色的可定制性,可以适应各种不同的应用场景。它支持复杂的数据类型、JSON 数据存储、空间数据处理和全文搜索等特性。
GreatSQL
GreatSQL 数据库是一款 开源免费 数据库,可在普通硬件上满足金融级应用场景,具有 高可用、高性能、高兼容、高安全 等特性,可作为 MySQL 或 Percona Server for MySQL 的理想可选替换。
详细区别
对比项目 GreatSQL PostgreSQL 许可证 采用 GPLv2 协议 基于 PostgreSQL 许可下,是一种类似于 BSD 或 MIT 的自由开源许可 对象层次结构 4级(实例、数据库、表、列) 5级(实例、数据库、模式、表、列) ACID事物 支持 支持 安全性 支持 RBAC、逻辑备份加密、CLONE 备份加密、审计、表空间国密加密、敏感数据脱敏 支持 RBAC、行级安全 (RLS) JSON 支持(但和PG语法不同) 支持(但和GreatSQL语法不同) 复制 Binlog 进行逻辑复制 WAL 进行物理复制 大小写敏感 默认不敏感(默认不区分大小写) 默认大小写敏感(默认区分大小写) 参数值引号 使用双引号”“ 使用单引号‘’ 数据类型 支持(但和PG语法不同) 支持(但和GreatSQL语法不同) SQL语法 支持(但和PG语法不同) 支持(但和GreatSQL语法不同) 函数 支持(但和PG语法不同) 支持(但和GreatSQL语法不同) 表和索引 支持(但和PG语法不同) 支持(但和GreatSQL语法不同) 自增 AUTO_INCREMENT SMALLSERIAL、SERIAL、SERIAL 注释 # -- ... ... ...
在迁移过程中,要注意两款数据库产品的差异。
迁移优势
迁移到 GreatSQL 有以下优势:
高可用
针对 MGR 进行了大量改进和提升工作,支持 地理标签、仲裁节点、读写动态 VIP、快速单主模式、智能选主 等特性,并针对 流控算法、事务认证队列清理算法、节点加入&退出机制、recovery机制 等多个 MGR 底层工作机制算法进行深度优化,进一步提升优化了 MGR 的高可用保障及性能稳定性。
高性能
相对 MySQL 及 Percona Server For MySQL 的性能表现更稳定优异,支持 Rapid 引擎、事务无锁化、并行LOAD DATA、异步删除大表、线程池、非阻塞式DDL、NUMA 亲和调度优化 等特性,在 TPC-C 测试中相对 MySQL 性能提升超过 30%,在 TPC-H 测试中的性能表现是 MySQL 的十几倍甚至上百倍。
高兼容
GreatSQL 实现 100% 完全兼容 MySQL 及 Percona Server For MySQL 用法,支持大多数常见 Oracle 用法,包括 数据类型兼容、函数兼容、SQL 语法兼容、存储程序兼容 等众多兼容扩展用法。
高安全
GreatSQL 支持逻辑备份加密、CLONE 备份加密、审计、表空间国密加密、敏感数据脱敏等多个安全提升特性,进一步保障业务数据安全,更适用于金融级应用场景。
迁移准备
业务需求分析
评估哪些业务需要迁移,以及迁移的影响。先明确迁移的范围,需要知道哪些业务系统和服务会受到影响,可以根据优先级进行迁移。了解数据库直接交互的应用程序、服务、脚本等,分析这些依赖关系,有助于制定迁移计划,和减少对业务的影响。同时也要评估迁移带来的风险,比如数据丢失、数据同步延迟、业务中断等。
兼容评估
评估 PostgreSQL 和 GreatSQL 之间的兼容性,包括语法、功能、数据类型、索引等。PostgreSQL 和 GreatSQL 在 SQL 语法和功能上存在一些差异,应特别注意。
在迁移之前,一定要先了解 PostgreSQL 和 GreatSQL 之间的区别:
PostgreSQL:https://postgresql.p2hp.com/index.html GreatSQL:https://greatsql.cn/
备份和恢复
在迁移前确保 PostgreSQL 数据库的备份和恢复机制完善。例如做一次全量备份,在迁移之前,首先进行完整的数据库备份(例如使用 pg_dump
),以确保在迁移过程中遇到问题时可以快速恢复。可以选择基于文件系统的快照备份或基于逻辑备份的 pg_dump,并将备份数据存储在安全位置。
测试环境搭建
安装 PostgreSQL 并生成测试数据
PostgreSQL 版本为 15.8
$ psql --version
psql (PostgreSQL) 15.8 (Debian 15.8-0+deb12u1)
迁移库 pg_to_greatsql 库下的 users 表
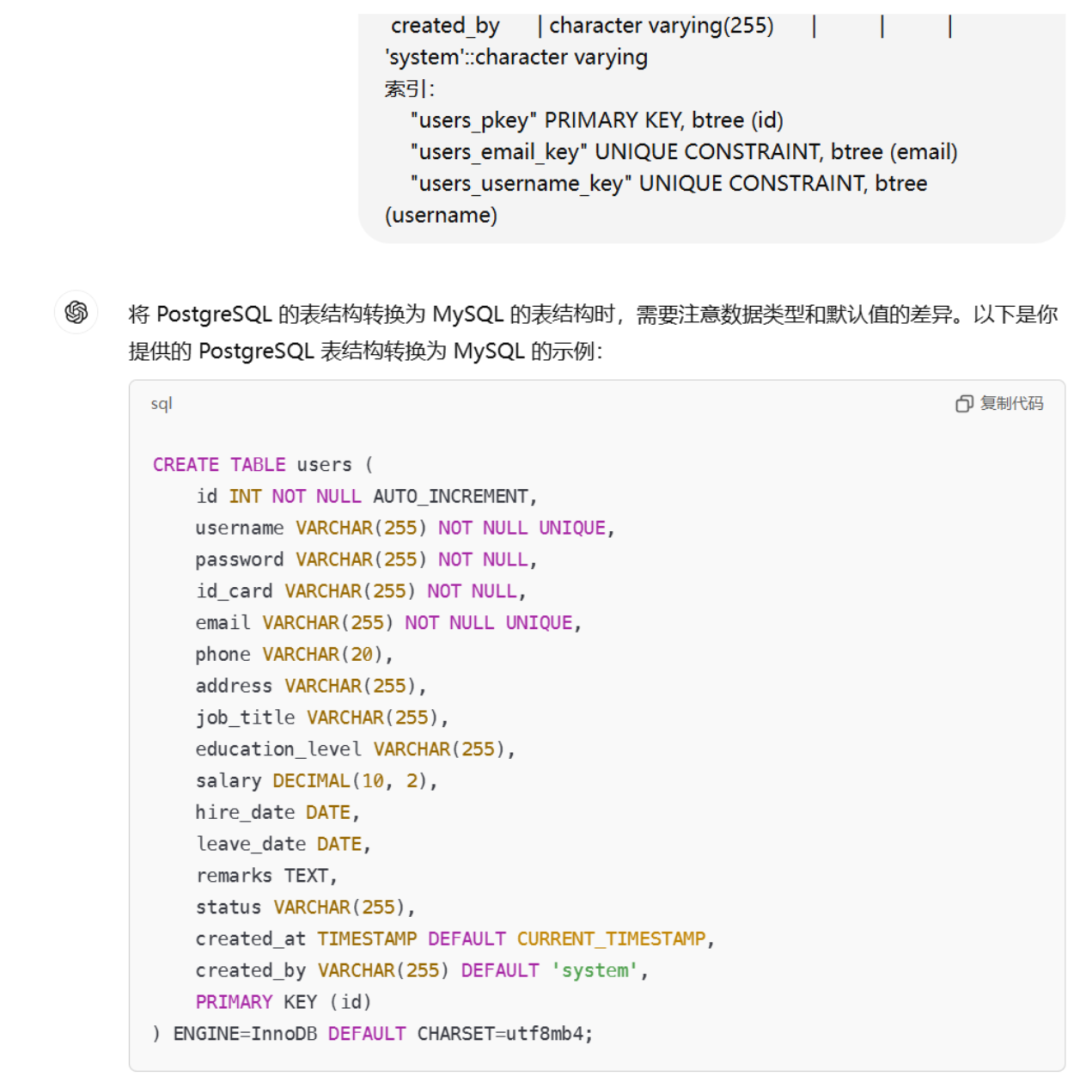
pg_to_greatsql-# \d Users
数据表 "public.users"
栏位 | 类型 | 校对规则 | 可空的 | 预设
-----------------+-----------------------------+----------+----------+-----------------------------------
id | integer | | not null | nextval('users_id_seq'::regclass)
username | character varying(255) | | not null |
password | character varying(255) | | not null |
id_card | character varying(255) | | not null |
email | character varying(255) | | not null |
phone | character varying(20) | | |
address | character varying(255) | | |
job_title | character varying(255) | | |
education_level | character varying(255) | | |
salary | numeric(10,2) | | |
hire_date | date | | |
leave_date | date | | |
remarks | text | | |
status | character varying(255) | | |
created_at | timestamp without time zone | | |
created_by | character varying(255) | | | 'system'::character varying
索引:
"users_pkey" PRIMARY KEY, btree (id)
"users_email_key" UNIQUE CONSTRAINT, btree (email)
"users_username_key" UNIQUE CONSTRAINT, btree (username)
该 user 表的数据量为 1010000 行
pg_to_greatsql=# SELECT COUNT(*) FROM users;
count
---------
1010000
(1 行记录)
安装 GreatSQL 数据库
推荐安装 GreatSQL 最新版本
https://greatsql.cn/docs/8.0.32-26/4-install-guide/1-install-prepare.html
迁移到 GreatSQL 数据库
表结构迁移
此时可以使用 AI 来帮助迁移,例如使用 ChatGPT 将 PostgreSQL 数据库表结构转换为 GreatSQL 数据库的表结构。
AI 生成完成后,需要自行检查下是否正确!
自增字段:id 字段使用 AUTO_INCREMENT
代替 nextval
数据类型:PostgreSQL 的 character varying
对应 GreatSQL 的 VARCHAR
,numeric
对应 DECIMAL
,text
对应 TEXT
,timestamp without time zone
对应 TIMESTAMP
。
默认值:对于 created_at
字段,使用 DEFAULT CURRENT_TIMESTAMP
设置默认值,created_by
字段的默认值保持不变。
字符集:推荐使用 utf8mb4
字符集,以支持更广泛的字符
在 GreatSQL 中创建对应库,并执行由 AI 生成的 SQL 建表语句:
-- 创建 pg_to_greatsql 库
greatsql> CREATE DATABASE pg_to_greatsql;
-- 创建 users 表
greatsql> CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT,
username VARCHAR(255) NOT NULL UNIQUE,
password VARCHAR(255) NOT NULL,
id_card VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE,
phone VARCHAR(20),
address VARCHAR(255),
job_title VARCHAR(255),
education_level VARCHAR(255),
salary DECIMAL(10, 2),
hire_date DATE,
leave_date DATE,
remarks TEXT,
status VARCHAR(255),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
created_by VARCHAR(255) DEFAULT 'system',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
数据迁移
方法一:pg_dump 备份
在 PostgreSQL 执行pg_dump
备份
$ pg_dump --data-only --inserts --column-inserts -U postgres -d pg_to_greatsql > ./pg_to_greatsql.sql
--data-only
:只导出数据,不包括数据库对象的定义(如表结构、索引等)。
--inserts
:以 SQL INSERT
语句的形式导出数据,而不是默认的自定义格式。这样生成的备份文件更易于阅读和编辑。
--column-inserts
:使用带有列名的 INSERT
语句形式,即INSERT INTO table_name (column1, column2,...) VALUES (value1, value2,...);
这种方式在处理包含特殊字符的数据时可能更稳定,并且可以更精确地控制插入的列。
此时会生成 pg_to_greatsql.sql
文件:
$ ls -lh
总计 474M
drwxr-xr-x 3 postgres postgres 4.0K 7月23日 10:49 15
-rw-r--r-- 1 postgres postgres 474M 10月21日 15:36 pg_to_greatsql.sql
去除无用信息
此时还不能将这份 SQL 文件直接导入到 GreatSQL 中。因为上面有介绍,两款数据库的对象层次结构不同。打开 pg_to_greatsql.sql
文件:
-- 语句中有 public. 需要去除
INSERT INTO public.users (id, username, password, id_card, email, phone, address, job_title, education_level, salary, hire_date, leave_date, remarks, status, created_at, created_by) VALUES (1010000, '527d66e0a6cdb128d44fc45', '10cccade4c7c35d553cd23e48b5facd1', '435078200404227108', 'b8a5b05af990ff4bdc9ccdc@qq.com', '18059437765', '讗慹簪瞠珒鸚鼜瘔狹覰', 'C++', '博士', 23592.00, '2020-07-04', '2020-12-29', '0e3801d3e64be7c38d93cb5', '离职', '2023-06-20 22:42:39', 'system');
可以看到 INSERT
语句表前面有 public.
关键词,需要将这个关键词去掉:
$ sed 's/INSERT INTO public\./INSERT INTO /g' pg_to_greatsql.sql > modified_pg_to_greatsql.sql
同时还有一些关于 PostgreSQL 参数的设置,需要去掉:
# 这些要去掉,否则导入不了 GreatSQL
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
my.cnf 参数可以选择 GreatSQL 推荐的参数模板设置:
https://greatsql.cn/docs/8.0.32-26/3-quick-start/3-4-quick-start-with-cnf.html
当然有些参数,例如例子中的 lock_timeout
在 PostgreSQL 中是代表锁超时,在 GreatSQL 中锁超时参数是 lock_wait_timeout
,若有需要可自行查找对应在 GreatSQL 的参数。
pg_dump 导入 GreatSQL
接下来就可以直接将这份 SQL 文件导入到 GreatSQL 数据库中:
$ mysql -u root -p pg_to_greatsql < modified_pg_to_greatsql.sql
greatsql> SELECT COUNT(*) FROM pg_to_greatsql.users;
+----------+
| count(*) |
+----------+
| 1010000 |
+----------+
1 row in set (1.06 sec)
数据量如果很大,该方法导入会特别慢
方法二:COPY 导出数据
使用 INSERT
的方法导入,会比较慢,此时可以用 COPY
的方法导出表数据,在配合 GreatSQL 的并行 Load Data 特性,可以使迁移更加迅速。
使用 COPY
导出数据:
pg_to_greatsql=# COPY users TO '/var/lib/postgresql/output_file.txt' WITH (FORMAT TEXT);
COPY 1010000
COPY 导入 GreatSQL
使用 GreatSQL 中的并行 Load Data 特性:
https://greatsql.cn/docs/8.0.32-26/5-enhance/5-1-highperf-parallel-load.html
greatsql> LOAD /*+ SET_VAR(gdb_parallel_load = ON) SET_VAR(gdb_parallel_load_chunk_size = 65536) SET_VAR(gdb_parallel_load_workers = 16) */ DATA INFILE '/var/lib/mysql/output_file.txt' INTO TABLE pg_to_greatsql.users;
Query OK, 1010000 rows affected (4 min 25.87 sec)
Records: 1010000 Deleted: 0 Skipped: 0 Warnings: 0
greatsql> SELECT COUNT(*) FROM pg_to_greatsql.users;
+----------+
| count(*) |
+----------+
| 1010000 |
+----------+
1 row in set (1.04 sec)
到此迁移完成,下篇将介绍使用 pg2mysql 工具迁移 :D
本文将介绍如何从 PostgreSQL 到 GreatSQL 的数据迁移,并运用 AI 协助迁移更加方便。迁移的方式有很多,例如:
pg_dump:导出SQL文件,修改后导入 GreatSQL 数据库。 COPY:导出txt文本文件,导入 GreatSQL 数据库。 pg2mysql:从 PostgreSQL 迁移到 MySQL/GreatSQL 工具。 GreatDTS:商业的异构数据库迁移工具。
本文将介绍 pg_dump
和 COPY
两种方法迁移。
PostgreSQL 和 GreatSQL 区别
PostgreSQL
和MySQL也一样,PostgreSQL也是个非常优秀的开源数据库。它的特色是强调扩展性、数据完整性和高级特性,具有出色的可定制性,可以适应各种不同的应用场景。它支持复杂的数据类型、JSON 数据存储、空间数据处理和全文搜索等特性。
GreatSQL
GreatSQL 数据库是一款 开源免费 数据库,可在普通硬件上满足金融级应用场景,具有 高可用、高性能、高兼容、高安全 等特性,可作为 MySQL 或 Percona Server for MySQL 的理想可选替换。
详细区别
| 对比项目 | GreatSQL | PostgreSQL |
|---|---|---|
| 许可证 | 采用 GPLv2 协议 | 基于 PostgreSQL 许可下,是一种类似于 BSD 或 MIT 的自由开源许可 |
| 对象层次结构 | 4级(实例、数据库、表、列) | 5级(实例、数据库、模式、表、列) |
| ACID事物 | 支持 | 支持 |
| 安全性 | 支持 RBAC、逻辑备份加密、CLONE 备份加密、审计、表空间国密加密、敏感数据脱敏 | 支持 RBAC、行级安全 (RLS) |
| JSON | 支持(但和PG语法不同) | 支持(但和GreatSQL语法不同) |
| 复制 | Binlog 进行逻辑复制 | WAL 进行物理复制 |
| 大小写敏感 | 默认不敏感(默认不区分大小写) | 默认大小写敏感(默认区分大小写) |
| 参数值引号 | 使用双引号”“ | 使用单引号‘’ |
| 数据类型 | 支持(但和PG语法不同) | 支持(但和GreatSQL语法不同) |
| SQL语法 | 支持(但和PG语法不同) | 支持(但和GreatSQL语法不同) |
| 函数 | 支持(但和PG语法不同) | 支持(但和GreatSQL语法不同) |
| 表和索引 | 支持(但和PG语法不同) | 支持(但和GreatSQL语法不同) |
| 自增 | AUTO_INCREMENT | SMALLSERIAL、SERIAL、SERIAL |
| 注释 | # | -- |
| ... | ... | ... |
在迁移过程中,要注意两款数据库产品的差异。
迁移优势
迁移到 GreatSQL 有以下优势:
高可用
针对 MGR 进行了大量改进和提升工作,支持 地理标签、仲裁节点、读写动态 VIP、快速单主模式、智能选主 等特性,并针对 流控算法、事务认证队列清理算法、节点加入&退出机制、recovery机制 等多个 MGR 底层工作机制算法进行深度优化,进一步提升优化了 MGR 的高可用保障及性能稳定性。
高性能
相对 MySQL 及 Percona Server For MySQL 的性能表现更稳定优异,支持 Rapid 引擎、事务无锁化、并行LOAD DATA、异步删除大表、线程池、非阻塞式DDL、NUMA 亲和调度优化 等特性,在 TPC-C 测试中相对 MySQL 性能提升超过 30%,在 TPC-H 测试中的性能表现是 MySQL 的十几倍甚至上百倍。
高兼容
GreatSQL 实现 100% 完全兼容 MySQL 及 Percona Server For MySQL 用法,支持大多数常见 Oracle 用法,包括 数据类型兼容、函数兼容、SQL 语法兼容、存储程序兼容 等众多兼容扩展用法。
高安全
GreatSQL 支持逻辑备份加密、CLONE 备份加密、审计、表空间国密加密、敏感数据脱敏等多个安全提升特性,进一步保障业务数据安全,更适用于金融级应用场景。
迁移准备
业务需求分析
评估哪些业务需要迁移,以及迁移的影响。先明确迁移的范围,需要知道哪些业务系统和服务会受到影响,可以根据优先级进行迁移。了解数据库直接交互的应用程序、服务、脚本等,分析这些依赖关系,有助于制定迁移计划,和减少对业务的影响。同时也要评估迁移带来的风险,比如数据丢失、数据同步延迟、业务中断等。
兼容评估
评估 PostgreSQL 和 GreatSQL 之间的兼容性,包括语法、功能、数据类型、索引等。PostgreSQL 和 GreatSQL 在 SQL 语法和功能上存在一些差异,应特别注意。
在迁移之前,一定要先了解 PostgreSQL 和 GreatSQL 之间的区别:
PostgreSQL:https://postgresql.p2hp.com/index.html GreatSQL:https://greatsql.cn/
备份和恢复
在迁移前确保 PostgreSQL 数据库的备份和恢复机制完善。例如做一次全量备份,在迁移之前,首先进行完整的数据库备份(例如使用 pg_dump
),以确保在迁移过程中遇到问题时可以快速恢复。可以选择基于文件系统的快照备份或基于逻辑备份的 pg_dump,并将备份数据存储在安全位置。
测试环境搭建
安装 PostgreSQL 并生成测试数据
PostgreSQL 版本为 15.8
$ psql --version
psql (PostgreSQL) 15.8 (Debian 15.8-0+deb12u1)
迁移库 pg_to_greatsql 库下的 users 表
pg_to_greatsql-# \d Users
数据表 "public.users"
栏位 | 类型 | 校对规则 | 可空的 | 预设
-----------------+-----------------------------+----------+----------+-----------------------------------
id | integer | | not null | nextval('users_id_seq'::regclass)
username | character varying(255) | | not null |
password | character varying(255) | | not null |
id_card | character varying(255) | | not null |
email | character varying(255) | | not null |
phone | character varying(20) | | |
address | character varying(255) | | |
job_title | character varying(255) | | |
education_level | character varying(255) | | |
salary | numeric(10,2) | | |
hire_date | date | | |
leave_date | date | | |
remarks | text | | |
status | character varying(255) | | |
created_at | timestamp without time zone | | |
created_by | character varying(255) | | | 'system'::character varying
索引:
"users_pkey" PRIMARY KEY, btree (id)
"users_email_key" UNIQUE CONSTRAINT, btree (email)
"users_username_key" UNIQUE CONSTRAINT, btree (username)
该 user 表的数据量为 1010000 行
pg_to_greatsql=# SELECT COUNT(*) FROM users;
count
---------
1010000
(1 行记录)
安装 GreatSQL 数据库
推荐安装 GreatSQL 最新版本
https://greatsql.cn/docs/8.0.32-26/4-install-guide/1-install-prepare.html
迁移到 GreatSQL 数据库
表结构迁移
此时可以使用 AI 来帮助迁移,例如使用 ChatGPT 将 PostgreSQL 数据库表结构转换为 GreatSQL 数据库的表结构。
AI 生成完成后,需要自行检查下是否正确!
自增字段:id 字段使用
AUTO_INCREMENT
代替nextval数据类型:PostgreSQL 的
character varying
对应 GreatSQL 的VARCHAR
,numeric
对应DECIMAL
,text
对应TEXT
,timestamp without time zone
对应TIMESTAMP
。默认值:对于
created_at
字段,使用DEFAULT CURRENT_TIMESTAMP
设置默认值,created_by
字段的默认值保持不变。字符集:推荐使用
utf8mb4
字符集,以支持更广泛的字符
在 GreatSQL 中创建对应库,并执行由 AI 生成的 SQL 建表语句:
-- 创建 pg_to_greatsql 库
greatsql> CREATE DATABASE pg_to_greatsql;
-- 创建 users 表
greatsql> CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT,
username VARCHAR(255) NOT NULL UNIQUE,
password VARCHAR(255) NOT NULL,
id_card VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE,
phone VARCHAR(20),
address VARCHAR(255),
job_title VARCHAR(255),
education_level VARCHAR(255),
salary DECIMAL(10, 2),
hire_date DATE,
leave_date DATE,
remarks TEXT,
status VARCHAR(255),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
created_by VARCHAR(255) DEFAULT 'system',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
数据迁移
方法一:pg_dump 备份
在 PostgreSQL 执行pg_dump
备份
$ pg_dump --data-only --inserts --column-inserts -U postgres -d pg_to_greatsql > ./pg_to_greatsql.sql
--data-only
:只导出数据,不包括数据库对象的定义(如表结构、索引等)。--inserts
:以 SQLINSERT
语句的形式导出数据,而不是默认的自定义格式。这样生成的备份文件更易于阅读和编辑。--column-inserts
:使用带有列名的INSERT
语句形式,即INSERT INTO table_name (column1, column2,...) VALUES (value1, value2,...);
这种方式在处理包含特殊字符的数据时可能更稳定,并且可以更精确地控制插入的列。
此时会生成 pg_to_greatsql.sql
文件:
$ ls -lh
总计 474M
drwxr-xr-x 3 postgres postgres 4.0K 7月23日 10:49 15
-rw-r--r-- 1 postgres postgres 474M 10月21日 15:36 pg_to_greatsql.sql
去除无用信息
此时还不能将这份 SQL 文件直接导入到 GreatSQL 中。因为上面有介绍,两款数据库的对象层次结构不同。打开 pg_to_greatsql.sql
文件:
-- 语句中有 public. 需要去除
INSERT INTO public.users (id, username, password, id_card, email, phone, address, job_title, education_level, salary, hire_date, leave_date, remarks, status, created_at, created_by) VALUES (1010000, '527d66e0a6cdb128d44fc45', '10cccade4c7c35d553cd23e48b5facd1', '435078200404227108', 'b8a5b05af990ff4bdc9ccdc@qq.com', '18059437765', '讗慹簪瞠珒鸚鼜瘔狹覰', 'C++', '博士', 23592.00, '2020-07-04', '2020-12-29', '0e3801d3e64be7c38d93cb5', '离职', '2023-06-20 22:42:39', 'system');
可以看到 INSERT
语句表前面有 public.
关键词,需要将这个关键词去掉:
$ sed 's/INSERT INTO public\./INSERT INTO /g' pg_to_greatsql.sql > modified_pg_to_greatsql.sql
同时还有一些关于 PostgreSQL 参数的设置,需要去掉:
# 这些要去掉,否则导入不了 GreatSQL
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
my.cnf 参数可以选择 GreatSQL 推荐的参数模板设置:
https://greatsql.cn/docs/8.0.32-26/3-quick-start/3-4-quick-start-with-cnf.html
当然有些参数,例如例子中的
lock_timeout
在 PostgreSQL 中是代表锁超时,在 GreatSQL 中锁超时参数是lock_wait_timeout
,若有需要可自行查找对应在 GreatSQL 的参数。
pg_dump 导入 GreatSQL
接下来就可以直接将这份 SQL 文件导入到 GreatSQL 数据库中:
$ mysql -u root -p pg_to_greatsql < modified_pg_to_greatsql.sql
greatsql> SELECT COUNT(*) FROM pg_to_greatsql.users;
+----------+
| count(*) |
+----------+
| 1010000 |
+----------+
1 row in set (1.06 sec)
数据量如果很大,该方法导入会特别慢
方法二:COPY 导出数据
使用 INSERT
的方法导入,会比较慢,此时可以用 COPY
的方法导出表数据,在配合 GreatSQL 的并行 Load Data 特性,可以使迁移更加迅速。
使用 COPY
导出数据:
pg_to_greatsql=# COPY users TO '/var/lib/postgresql/output_file.txt' WITH (FORMAT TEXT);
COPY 1010000
COPY 导入 GreatSQL
使用 GreatSQL 中的并行 Load Data 特性:
https://greatsql.cn/docs/8.0.32-26/5-enhance/5-1-highperf-parallel-load.html
greatsql> LOAD /*+ SET_VAR(gdb_parallel_load = ON) SET_VAR(gdb_parallel_load_chunk_size = 65536) SET_VAR(gdb_parallel_load_workers = 16) */ DATA INFILE '/var/lib/mysql/output_file.txt' INTO TABLE pg_to_greatsql.users;
Query OK, 1010000 rows affected (4 min 25.87 sec)
Records: 1010000 Deleted: 0 Skipped: 0 Warnings: 0
greatsql> SELECT COUNT(*) FROM pg_to_greatsql.users;
+----------+
| count(*) |
+----------+
| 1010000 |
+----------+
1 row in set (1.04 sec)
到此迁移完成,下篇将介绍使用 pg2mysql 工具迁移 :D
文章推荐:
《GreatSQL 产品体验官》
祝大家
春节快乐,新年幸福吉祥
蛇年行大运,万事皆如愿
使用说明
每个用户ID限领1个红包封面,数量有限,先到先得;
若用户已经领取过红包封面,会看到页面显示“已领取红包封面”;
用户尚未领取时,若红包封面已被全部领取完,会看到页面显示“红包封面已领完”;
红包封面使用有效期为领取后一个月,有效期内可以无限次使用该封面,超过有效期后封面将自动失效,之前已发送的红包不受影响。
