




今天为大家分享华中科技大学与华为2012实验室联合发表的一篇关于大规模向量检索的论文:
Towards High-throughput and Low-latency Billion-scale Vector Search via CPU/GPU Collaborative Filtering and Re-ranking。

论文地址:https://arxiv.org/abs/2409.16576
该论文已经被计算机存储系统领域旗舰会议FAST 2025录用。

01
论文概述
Approximate nearest neighbor search(ANNS)即向量的近似最近邻搜索,是指在一系列给定的高维向量中找到前k个和查询向量最为相似的向量。ANNS在数据挖掘、搜索引擎和人工智能等许多领域有着非常广泛的应用场景,特别是结合RAG方法,可以为大语言模型生成质量带来显著的提高。
然而,规模不断增长的向量数据集在性能、成本和准确性方面对ANNS提出了巨大挑战。现有系统都是在单个方面做出取舍,难以满足大规模ANNS服务的多元化需求。
为此,文章提出了FusionANNS,一种使用SSDs和入门级的GPU实现的高吞吐、低延迟和低成本的大规模向量检索系统。该系统的核心思想是CPU/GPU的协同过滤和重排序机制,并基于此提出了一种分布在GPU/CPU/SSD上的多层级索引,能够显著减少CPUs和GPU之间的数据传输;提出了启发式重排序机制,以消除重排序过程不必要的I/O和计算;提出了冗余感知的I/O去重,基于优化的数据布局进一步提升了I/O效率。对标最先进的基于SSD的系统SPANN 和 GPU 加速的内存系统RUMMY,FusionANNS 在保证低延迟和高精度的同时,分别最高可提高13.1 倍和 4.9 倍的QPS,成本效率可提高 8.8 倍和 6.8 倍。
02
核心方法
2.1 系统架构
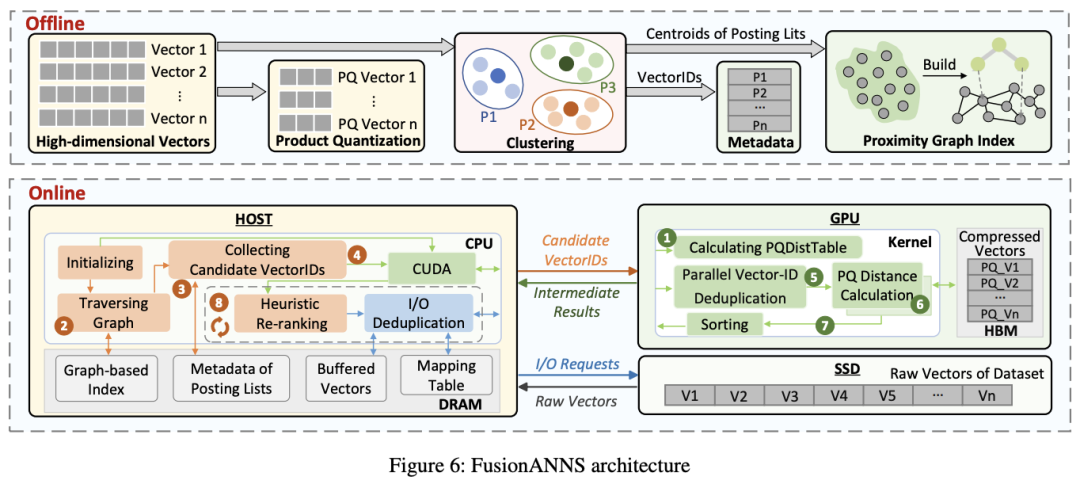
FusionANNS的系统架构如上图所示,分别包含离线的索引处理和在线的协同搜索。
离线部分:FusionANNS先把原始数据进行PQ压缩,并用原始数据进行聚类分成若干个posting lists,然后用每个posting list的聚类中心生成图索引结构,并将每个聚类中的向量ID储存为元数据。最终将图索引和元数据存储在内存中,PQ压缩后的向量存储在GPU的HBM中,原始数据存储在SSD中。
在线部分:当产生新的查询时,FusionANNS的操作顺序如图中数字顺序所示。首先CPU在内存上的导航图中找到距离查询向量最近的前m个posting lists,同时GPU计算查询向量的PQ距离表。然后CPU从元数据里查找这些posting lists中的向量ID,并将这些向量ID发送给GPU。GPU收到向量ID后会先并行地去重,然后从HBM中读取每个向量ID对应的PQ压缩向量,并计算其与查询向量的PQ距离。在这一步,GPU会给压缩向量的每一个维度分配一个进程以访问PQ距离表,然后用一个控制进程统计结果。计算结束之后,GPU按照距离从小到大排序并向CPU返回前n个中间结果。CPU收到后从SSD中读取这些中间结果对应的原始向量数据,然后进行启发式地重排序,最终得到查询结果。
2.2 多层索引结构
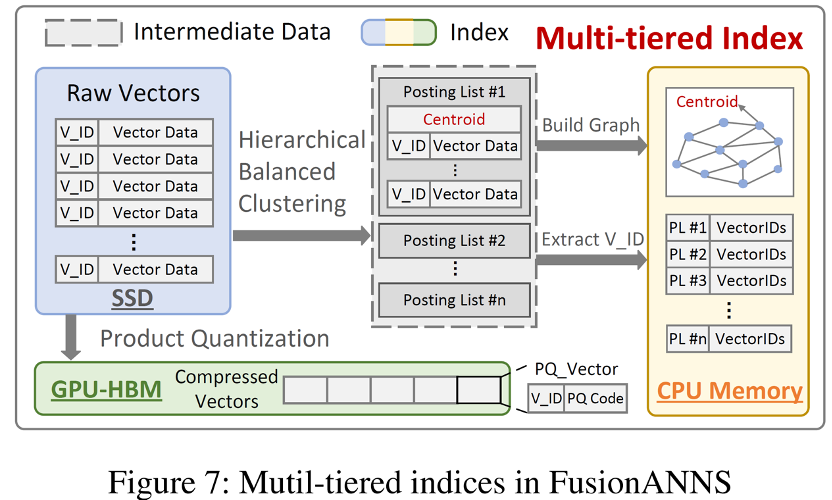
FusionANNS通过精心设计多层索引结构在GPU,CPU和SSD上的布局,支持CPU和GPU之间轻量化的数据传输。如上图所示,FusionANNS对每个posting list的中心构建图索引结构并提取向量ID作为元数据,最后对中间生成的posting list弃而不用。由此得到的图索引和元数据的体积足够小,因此可以完全存储在内存中。同时,抽取向量ID可以使得posting list结构(大小为原始数据集的8倍左右)与原始数据解耦,因此可以直接利用PQ技术压缩原始数据集并完全存储在GPU的HBM中。这种结构使得CPU只需向GPU传送向量ID,显著减少了GPU和CPU之间的数据交换,消除了总线带宽带来的性能瓶颈。同时,FusionANNS仅将原始数据而不是posting lists存储在SSD中,且查询过程中仅有重排时会产生少数的IO操作,减轻了IO带来的性能瓶颈。总体而言,FusionANNS精心设计的多层索引结构很好地利用了各种数据和硬件的特点,突破了许多性能瓶颈。
2.3 启发式重排序
由于不同查询需要重新排序的中间结果数量也不同,FusionANNS设计了一种启发式的重排序方法,其核心思想是,当一个查询的所有top-k结果被全部找到时,后续的重排序操作不会改变最终结果队列。具体而言,重排序过程被分成了多个批次,在每个批次执行结束后,利用一个反馈控制模型来评估后续的批次是否对提升精度是有益的,若否,则提前终止重排序过程。
2.4 冗余感知的IO去重
FusionANNS优化了原始数据在SSD中的布局,在离线阶段将每个posting list中距离相近的向量分桶,并按照SSD页面的大小尽量将桶合并以对齐,最终将所有分桶组织为一整个文件并存储在SSD中,并在内存中创建一个向量到页面的映射表。
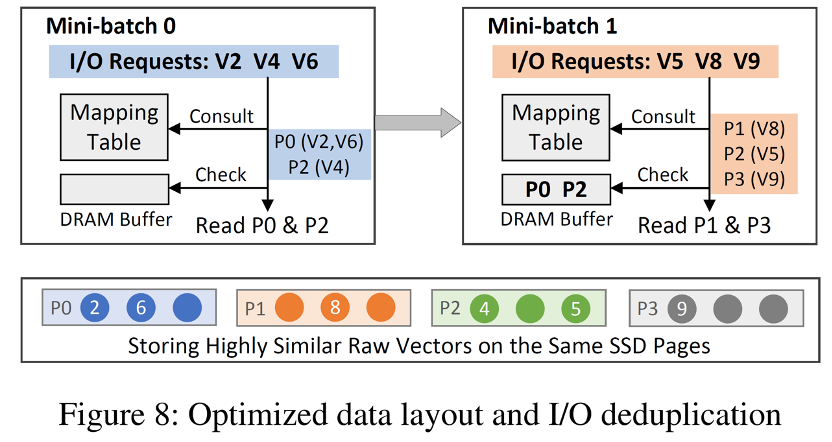
基于该优化的数据布局,FusionANNS在执行每个重排序批次时,首先通过映射表确定每个向量所在的页面,合并页面相同的查询。同时在内存中缓存每个批次查询得到的页面,后续批次若所需页面已在缓存中就直接读取,其过程和例子如上图所示。
03
精彩段落
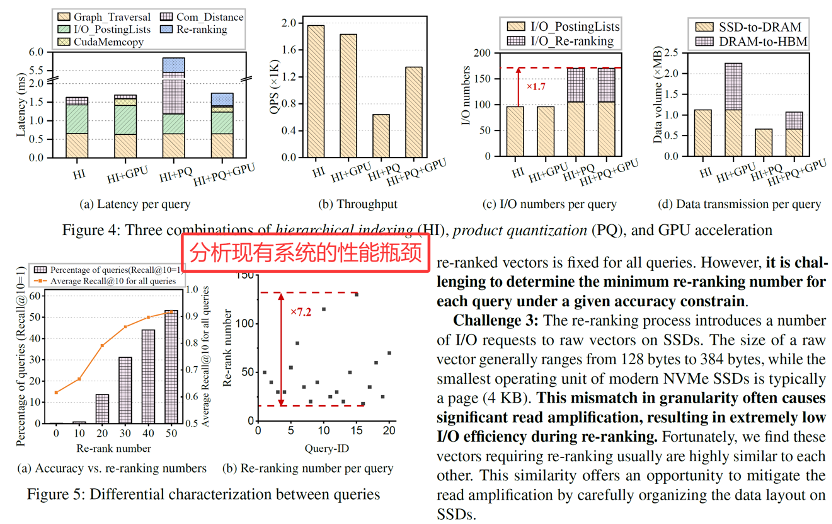
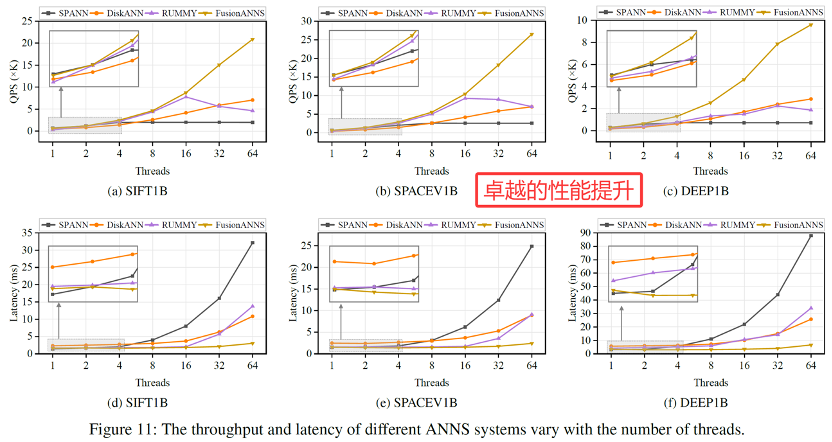
4.
04
总结
FusionANNS利用入门级的GPU来加速基于SSD的大规模向量检索,通过精心设计的多层级索引在GPU/CPU/SSD的布局和一系列IO优化机制,从而实现了高吞吐、低延迟、低成本和高精度的全面优势。
与现有利用GPU加速大规模向量检索的研究思路不同,FusionANNS的核心在于通过构建快速且高效的协同过滤机制,有效突破存储端的I/O瓶颈。
05
延伸阅读
[1] Neruips’21: 基于SSD的大规模近似最近邻搜索
SPANN: Highly-efficient Billion-scale Approximate Nearest Neighbor Search
https://dl.acm.org/doi/10.5555/3540261.3540659
