




1. 概述
索引是数据库系统中一种用于提高查询速度的数据结构。它通过对表中的数据按照一定的规则进行排序或组织,使得数据库在查找特定记录时能够快速定位,而不需要对整个表进行扫描。本章主要介绍btree_gin与btree_gist索引。
btree_gin是一种特殊的GIN(Generalized Inverted Index)索引类型,它结合了 B-Tree 的层次结构和 GIN 索引对多值数据类型的高效处理能力。适用于大部分的数据类型,如整数、字符串等。它以树形结构存储数据,在平衡性方面表现良好,对于等值查询(=)、范围查询(between、>、<等)效率较高。
btree_gist是基于GiST(Generalized Search Tree)框架实现的一种类似于 B - Tree 结构的索引。它不仅支持基本数据类型的精确查询,还能够很好地处理范围查询和其他复杂查询操作。
2. 工作原理
为了更好地理解btree_gin和btree_gist的工作原理和应用场景,我们可以用图示来直观地展示这两种索引的结构和特点。
btree_gin 索引结构
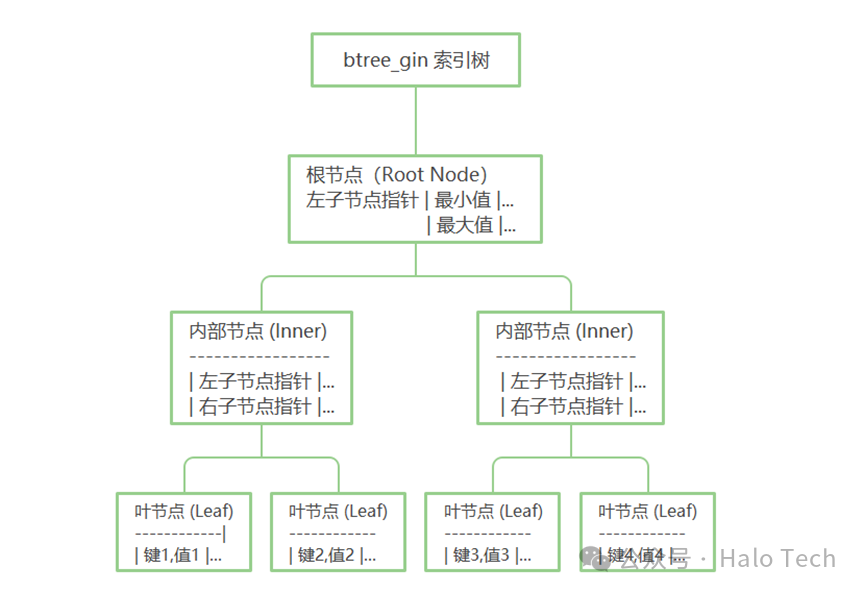
图示详解:
1.层次结构
btree_gin具有类似于 B - Tree 的层次结构,每个节点包含指向子节点的指针以及范围信息(最小值和最大值等)。
2.多值数据支持
对于叶节点中的项,它可以是多值数据类型(如数组、jsonb)。例如,一个叶节点可能包含多个键 - 值对,每个键可以对应多个值。
3.快速查找
在查询时,通过遍历索引树可以快速定位到包含特定值的节点,从而找到对应的表记录。
btree_gist 索引结构
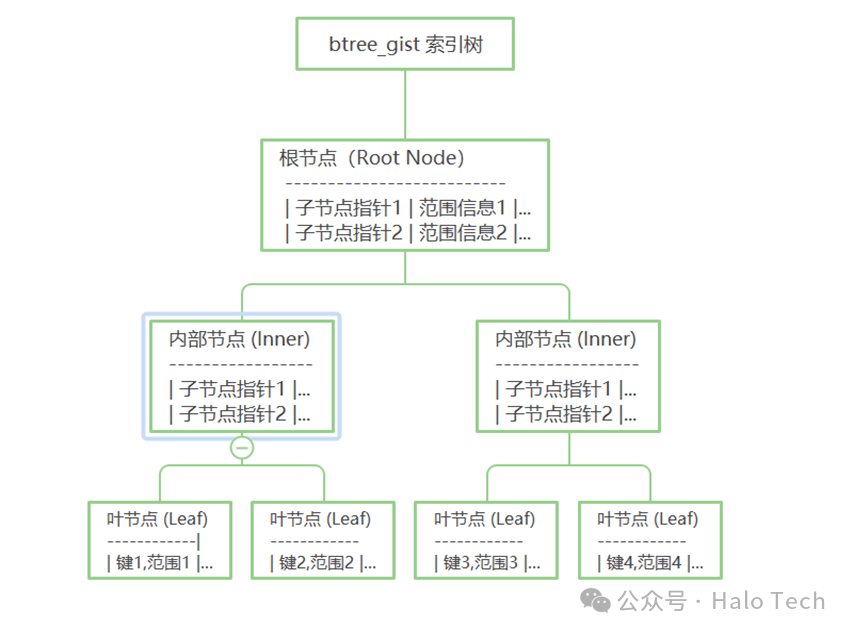
图示详解:
1.范围信息
每个节点不仅包含指向子节点的指针,还包含范围信息(如最小值、最大值等),这对于处理范围查询非常有用。
2.自定义操作符类
GiST框架允许定义不同的操作符类来实现对多种数据类型的索引。这使得 btree_gist能够灵活地适应不同类型的复杂查询。
3.平衡性维护
在插入和更新过程中,GiST 框架能够保持索引的平衡性,避免因大量插入导致索引结构失衡的问题。
3. btree_gin
(1)语法
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ IF NOT EXISTS ] index_nameON table_name USING GIN (column_name | (expression) [ opclass ] [ WITH (storage_parameter = value) ]);
(2)索引创建
创建btree_gin扩展
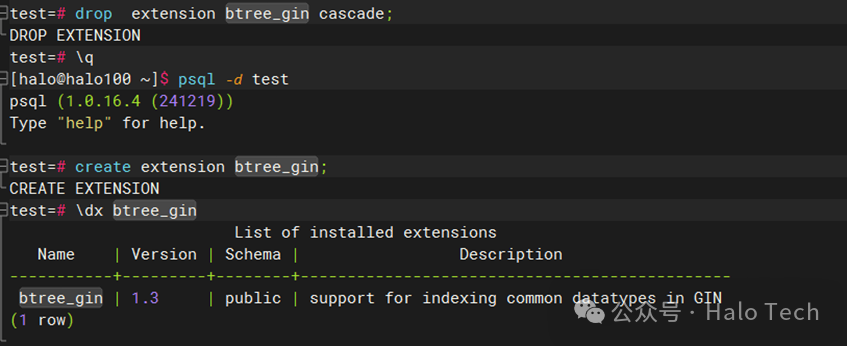
示例1:
CREATE TABLE products (id SERIAL PRIMARY KEY,attributes JSONB -- 存储商品属性);INSERT INTO products (attributes) VALUES('{"color": "red", "size": "L", "brand": "BrandA"}'),('{"color": "blue", "size": "M", "brand": "BrandB"}'),('{"color": "green", "size": "XL", "brand": "BrandC"}');-- 创建 btree_gin 索引:CREATE INDEX idx_products_attributes_btree_gin ON products USING GIN (attributes);-- 多条件查询示例SELECT * FROM products WHERE attributes @> '{"color": "red", "brand": "BrandA"}';
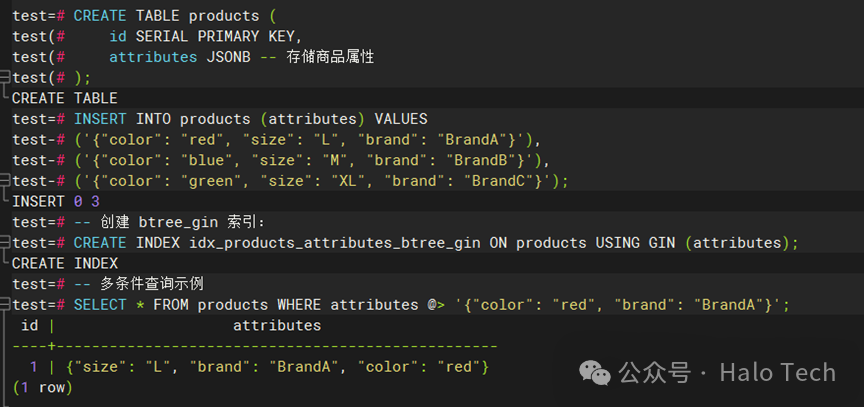
-- 重建索引(对于频繁更新和插入的表,btree_gin 索引的维护成本可能会更高。因此,如果你的表主要是读密集型而不是写密集型,那么 btree_gin 可能是一个更好的选择。
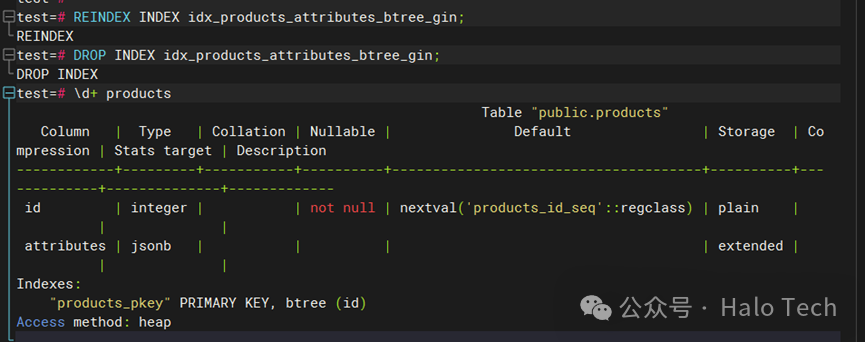
示例2:
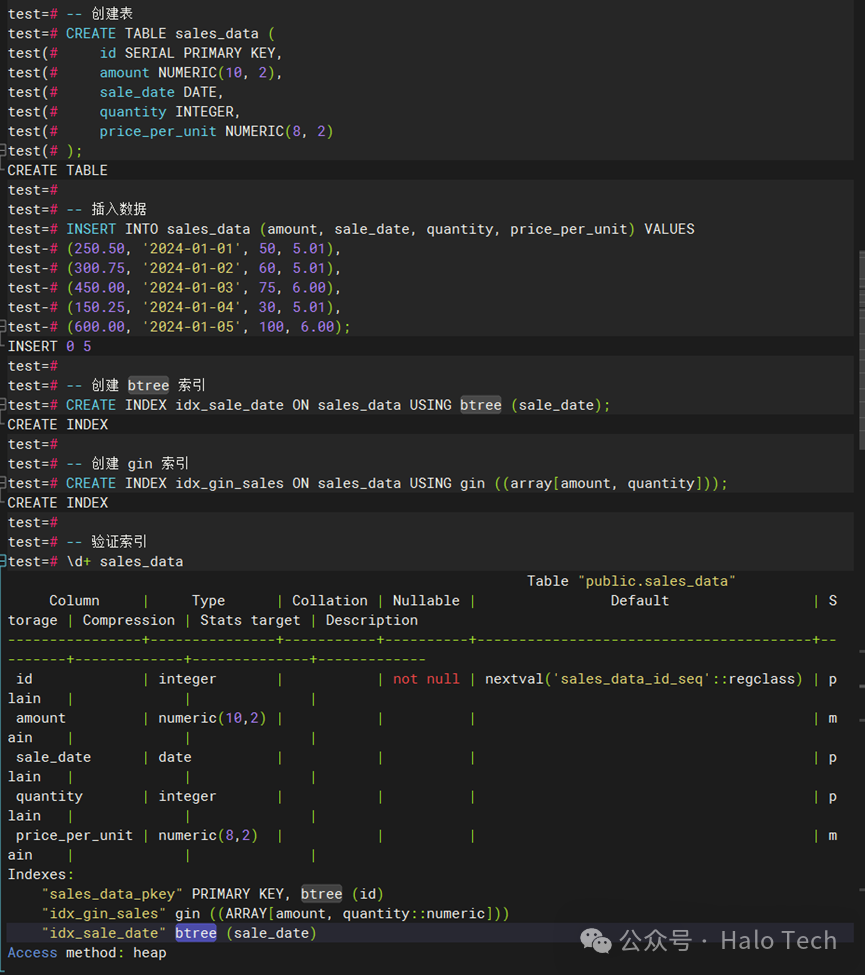
-- 创建表CREATE EXTENSION IF NOT EXISTS btree_gin;CREATE TABLE sales_data (id SERIAL PRIMARY KEY,amount NUMERIC(10, 2),sale_date DATE,quantity INTEGER,price_per_unit NUMERIC(8, 2));-- 插入数据INSERT INTO sales_data (amount, sale_date, quantity, price_per_unit) VALUES(250.50, '2024-01-01', 50, 5.01),(300.75, '2024-01-02', 60, 5.01),(450.00, '2024-01-03', 75, 6.00),(150.25, '2024-01-04', 30, 5.01),(600.00, '2024-01-05', 100, 6.00);-- 创建 btree 索引CREATE INDEX idx_sale_date ON sales_data USING btree (sale_date);-- 创建 gin 索引CREATE INDEX idx_gin_sales ON sales_data USING gin ((array[amount, quantity]));-- 验证索引\d+ sales_data
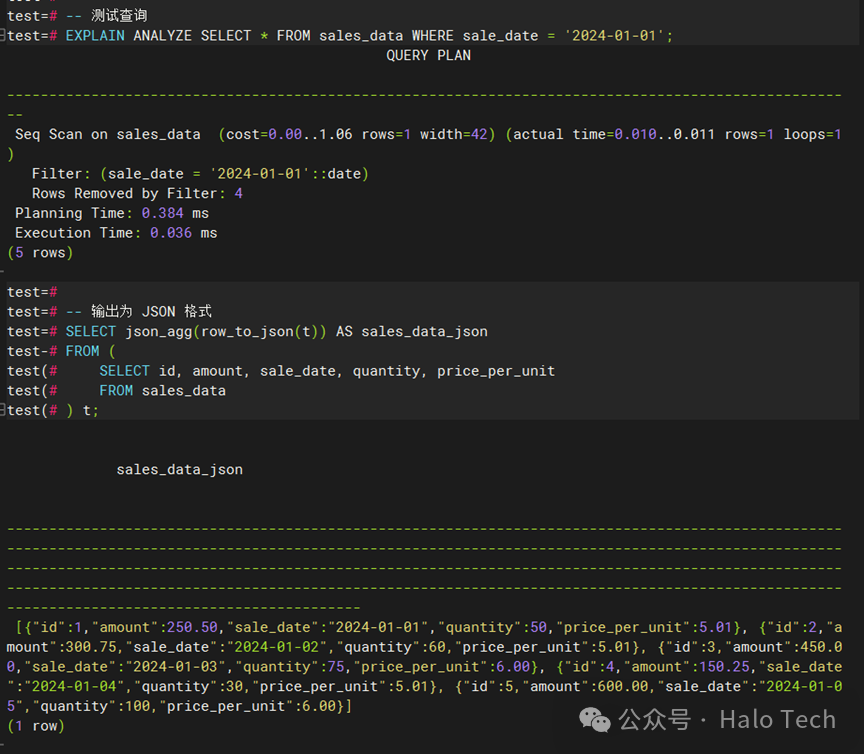
-- 测试查询EXPLAIN ANALYZE SELECT * FROM sales_data WHERE sale_date = '2024-01-01';-- 输出为 JSON 格式SELECT json_agg(row_to_json(t)) AS sales_data_jsonFROM (SELECT id, amount, sale_date, quantity, price_per_unitFROM sales_data) t;
4. btree_gist
(1) 语法
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ IF NOT EXISTS ] index_nameON table_name USING GIST (column_name | (expression) [ opclass ] [ WITH (storage_parameter = value) ]);
(2) 索引创建
-- 创建btree_gist扩展CREATE EXTENSION IF NOT EXISTS btree_gist;
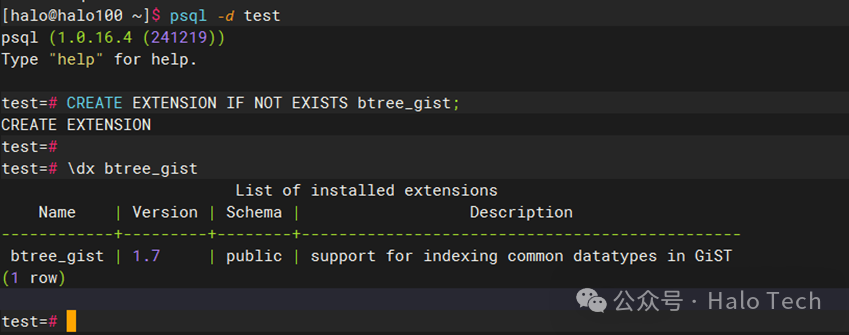
示例1:
-- 创建一个包含书籍信息的表,包括书名、作者、价格等字段。CREATE TABLE books (id SERIAL PRIMARY KEY,title TEXT NOT NULL,author TEXT NOT NULL,price NUMERIC(10, 2) NOT NULL,publication_date DATE NOT NULL,category TEXT NOT NULL);INSERT INTO books (title, author, price, publication_date, category)VALUES('Book A', 'Author 1', 19.99, '2021-05-01', 'Fiction'),('Book B', 'Author 2', 24.99, '2020-07-15', 'Non-Fiction'),('Book C', 'Author 3', 14.99, '2019-12-25', 'Science'),('Book D', 'Author 4', 34.99, '2022-03-10', 'History'),('Book E', 'Author 5', 9.99, '2018-11-05', 'Fiction');-- 创建 GiST 索引CREATE INDEX idx_books_price_gist ON books USING GiST (price);CREATE INDEX idx_books_publication_date_gist ON books USING GiST (publication_date);\d+ books
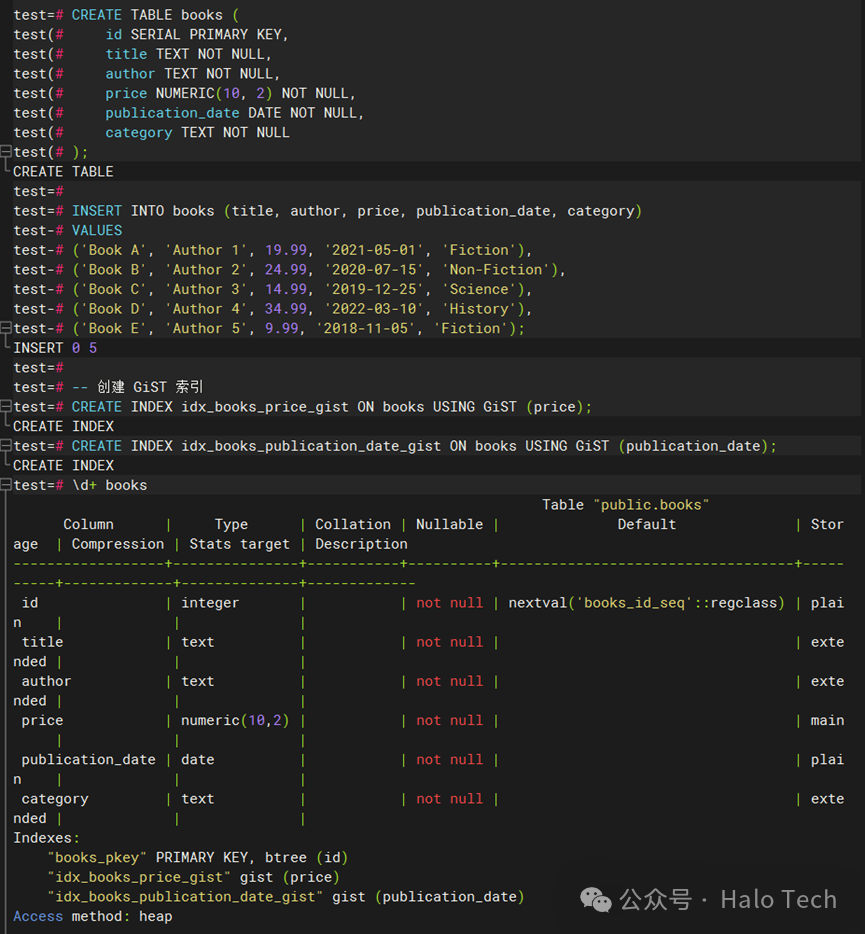
-- 验证索引效果,查看执行计划以确认 GiST 索引是否被有效利用
EXPLAIN ANALYZESELECT * FROM booksWHERE price >= 10 AND price <= 30;
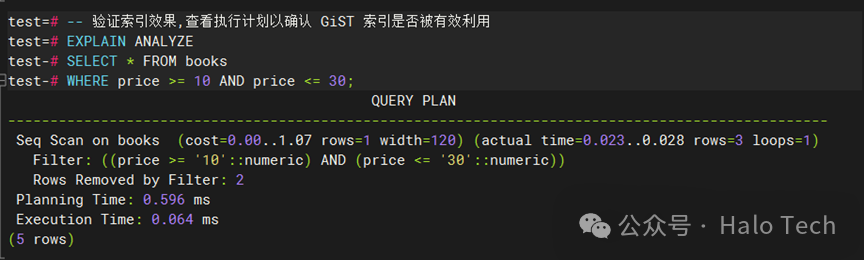
-- 组合查询:查找特定类别并且价格在一定范围内的书籍
SELECT * FROM booksWHERE category = 'Fiction' AND price BETWEEN 10 AND 30;
-- 时间范围查询:查找在过去五年内出版并且价格在一定范围内的书籍
SELECT * FROM booksWHERE publication_date >= NOW() - INTERVAL '5 years'AND price >= 10 AND price <= 30;
-- 重建索引(如高频率的数据修改、性能下降、定期维护任务等需要):REINDEX INDEX idx_books_price_gist;REINDEX INDEX idx_books_publication_date_gist;-- 删除索引DROP INDEX idx_books_price_gist;DROP INDEX idx_books_publication_date_gist;\d+ books-- 删除示例表DROP TABLE books ;
示例2:
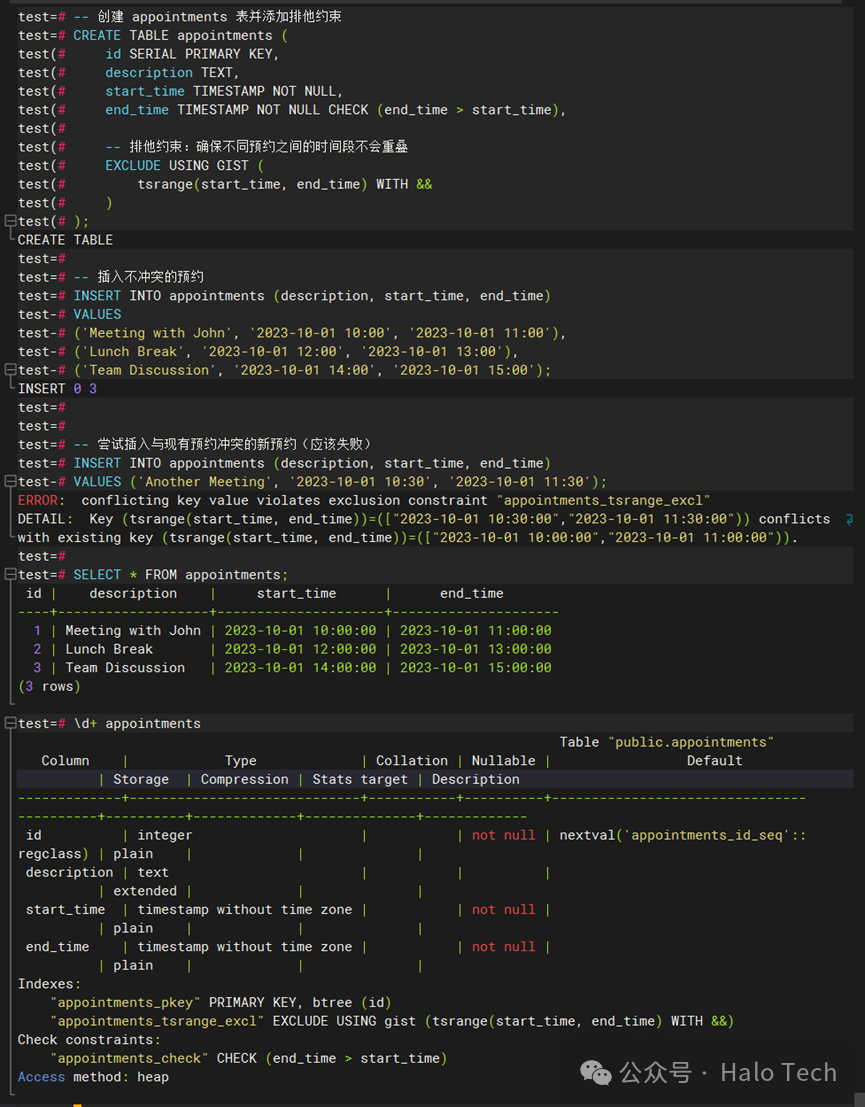
创建一个 appointments 表,并添加排他约束以确保不同预约之间的时间段不会重叠(强一致性)
-- 创建 appointments 表并添加排他约束CREATE TABLE appointments (id SERIAL PRIMARY KEY,description TEXT,start_time TIMESTAMP NOT NULL,end_time TIMESTAMP NOT NULL CHECK (end_time > start_time),-- 排他约束:确保不同预约之间的时间段不会重叠EXCLUDE USING GIST (tsrange(start_time, end_time) WITH &&));-- 插入不冲突的预约INSERT INTO appointments (description, start_time, end_time)VALUES('Meeting with John', '2023-10-01 10:00', '2023-10-01 11:00'),('Lunch Break', '2023-10-01 12:00', '2023-10-01 13:00'),('Team Discussion', '2023-10-01 14:00', '2023-10-01 15:00');-- 尝试插入与现有预约冲突的新预约(应该失败)INSERT INTO appointments (description, start_time, end_time)VALUES ('Another Meeting', '2023-10-01 10:30', '2023-10-01 11:30');SELECT * FROM appointments;
今天简单的分享到这里,有想了解更多的朋友,请留言+关注。
