




在 Redis 8.0 M3 版本中实现了 Async IO Thread,进一步提升 Redis 性能,在部分场景中可突破百万 QPS。本文主要讨论 Redis IO 多线程的必要性,分析现有版本的不足,介绍 Async IO Thread 的实现并进行性能测试。本人 ShooterIT[1] 和 sundb[2] 合作实现了这一功能。
高性能的需求
在介绍 Redis IO 多线程之前,可能有一个问题需要先进行讨论:我们需不需要 IO 多线程,单线程 Redis 性能是否够用?
回答这个问题最简单的方式可能是查看当前 Redis CPU 是否打满,实际上大多数业务不会遇到单线程 Redis 性能瓶颈的问题。另外,部分性能瓶颈问题,IO 多线程也无法解决,IO 多线程主要解决是 IO 密集型场景,即网络 IO 消耗在 Redis 中占比较大的场景,而非计算密集型场景,因为命令处理仍然是单线程的。并且 Redis 提供了集群模式,可以通过增加从库和分片的方式来扩展系统吞吐能力。
但下面几种场景是个人认为需要 IO 多线程的:
热点数据:对于部分业务而言,在突发事件、热门体育赛事、抢购秒杀等场景则会出现热点 Key 问题,QPS 极高,而且无法通过横向扩展方式提升系统吞吐,甚至业务和运维也无法及时做出调整 机器规格:无论是购买服务器还是云厂商的虚机,CPU 和内存比例通常为 1:2、1:4 或 1:8,在大规格机器上部署单线程 Redis 就会造成一部分 CPU 浪费,与其浪费不如增加 IO 线程以应对突发流量 性能和容量不匹配:部分场景中存在数据量不大但 QPS 很高的情况,若增加分片提升性能则会让系统成本变高 TLS 性能退化:现在大家对数据安全越来越重视,TLS 的使用必然会越来越广泛,但 TLS 加解密数据会消耗很多 CPU, 导致单线程 Redis 性能退化严重,尤其是请求和回复比较大的场景 Cluster 模式的限制:虽然 Redis Cluster 提供了横向扩展能力,但是维护使用成本也变高,部分功能缺失或受限,比如,多 Key 命令也必须在属于同一个 Slot 的限制,所以很多用户仍愿意选择使用主备架构
综上,IO 多线程让 Redis 拥有了在单实例内部性能扩展的能力,可给系统架构设计提供更多的灵活性。
现有版本分析
可能大家有一个疑问:为什么 Redis 采用了 IO 多线程的方式提高性能?下面是 Redis 单线程模式下 SET/GET 命令压测时的火焰图,我们清晰地可以看到 Redis 的主要消耗在于网络 IO 读写,而命令执行只占用很小的比例。
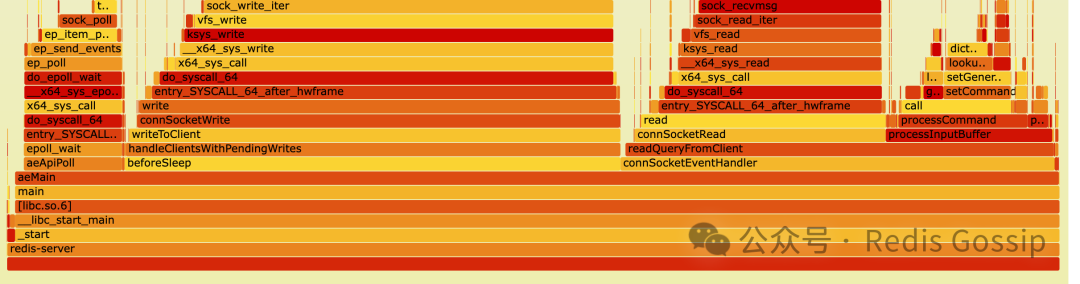
所以 Redis 6.0 引入了 IO 多线程,让 IO 线程处理请求读取、命令解析和回复发送这些 CPU 负载最为繁重的任务,主线程更专注于命令处理,从而提升整体性能。关于现有 IO 多线程模型的实现原理,大家可以阅读网上相关文章,避免篇幅太长,本文不做赘述。
然而,现有的 IO 线程实现存在一些不足之处:
在 IO 线程进行读写操作时,主线程会被阻塞,必须等待所有 IO 线程完成当前任务后才能继续执行;相应地,主线程在执行命令时,IO 线程则通过 busy wait 的方式等待主线程继续分配 IO 任务。这意味着整个过程是同步的,无法有效利用多核 CPU 并行处理能力 当客户端数量和请求量适度增加时,由于 IO 线程采用 busy wait 机制,所有 IO 线程 CPU 几乎都是打满状态,这使得我们很难确定 Redis 的性能瓶颈,也造成 CPU 资源浪费 同时启用 TLS 和 io-threads-do-reads,可能会导致连接断开时会有多个 IO 线程同时处理同一连接,从而引发竞态条件和断言失败等问题,导致 Redis 崩溃退出,Issue: #12540[3]
因此,我们设计了一种异步 IO 线程的方案,IO 线程采用事件驱动模型,并行地处理客户端的读写操作,而主线程专注于命令处理,充分利用多核 CPU 的并行处理能力从而提升 Redis 性能。
Async IO Thread 实现
与之前一样,我们并没有改变所有客户端命令必须在主线程中执行的原则,因为 Redis 最初是设计为单线程的,以多线程方式处理命令将不可避免地引入大量的竞争和同步问题,即使像 PING 命令的执行,也会有多个指标的统计、client eviction 检查等涉及全局数据的操作。现在每个 IO 线程都有独立的事件循环,IO 线程也采用多路复用的方式来处理客户端的读写操作,从而消除了忙等待所带来的 CPU 开销。而主也线程不再需要执行繁重的 epoll_wait 操作来处理客户端读写操作,只需要专注于命令处理。
如下图所示,主线程和 IO 线程交互过程可以简要描述如下:
主线程在 accept 新连接后将客户端分配给 IO 线程 IO 线程在完成客户端的请求读取和命令解析后会通知主线程 主线程处理来自 IO 线程的命令并生成回复并再转回给相应的 IO 线程 IO 线程负责将回复写回客户端,并继续处理客户端的读写事件
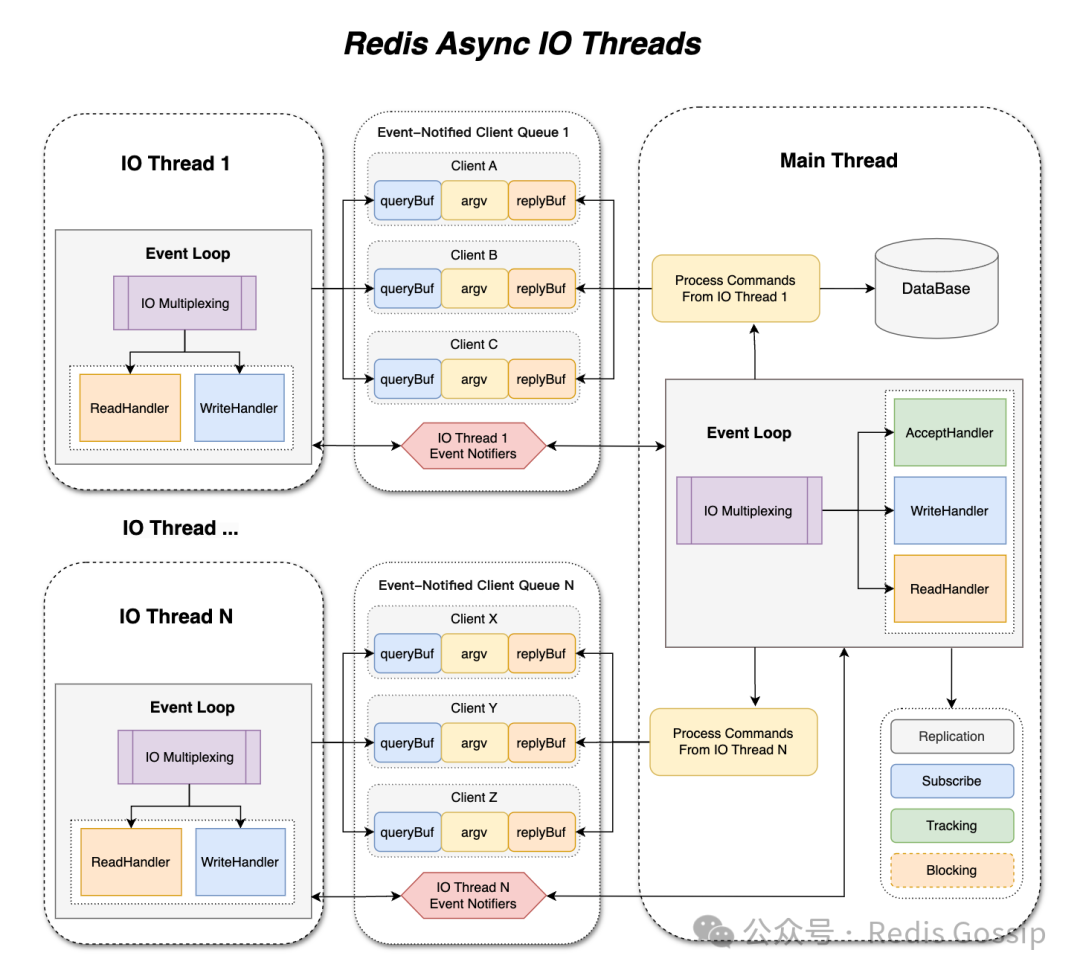
Event-notified client queue
为实现 IO 线程与主线程之间的高效通信,我们设计了一个基于事件通知的客户端队列(event-notified client queue)。每个 IO 线程和主线程各自拥有两个这样的队列,用于存储待处理的客户端列表,这些队列的事件通知器可与 epoll 集成,以实现事件驱动的处理方式。使用 pthread_mutex 来确保队列操作的安全性、数据的可见性和顺序性。因为每个 IO 线程和主线程都在独立的队列上操作,且临界区极小,仅为链表指针交换,从而最小化竞争,避免因锁争用导致的线程挂起。此外,事件通知器是基于 eventfd 或 pipe 实现的,Linux 系统下采用 eventfd,不仅可以与 epoll 集成,而且更轻量高效。
线程安全
将同步的 IO 多线程模型改为异步的 IO 多线程模型,带来了一些列的线程安全问题。在主线程中可能需要操作 IO 线程的数据,例如访问或操作客户端的查询/输出缓冲区、甚至关闭客户端。我们引入了一种 IO 线程暂停和恢复的机制。主线程会暂停 IO 线程,执行一些操作后,再恢复它。为了避免线程挂起,使用忙等待机制来确认目标状态,此外,使用原子变量来确保内存可见性和顺序性。
对于某些特殊类型的客户端,将它们放在 IO 线程中处理会导致严重的竞争问题,这些问题难以解决。对于复制、monitor、订阅和 tracking 客户端,当满足条件时,主线程会直接向它们发送回复,所以我们将这些客户端放在主线程中处理,而非交由 IO 线程。
可观测性
在当前设计中,主线程总是将客户端分配给客户端数最少的 IO 线程。为了清楚地观察每个 IO 线程处理的客户端数量,以及工作负载,我们在 INFO 输出中新增了一个部分。通过INFO THREADS
可以显示每个 IO 线程的客户端数量,IO read/write 的次数:
# Threads
io_thread_0:clients=0,reads=0,writes=0
io_thread_1:clients=2,reads=100,writes=100
io_thread_2:clients=2,reads=100,writes=100
在CLIENT LIST
输出中,也增加了一个字段 io-thread,用于指示客户端被分配到的 IO 线程:
id=244 addr=127.0.0.1:41870 laddr=127.0.0.1:6379 ... resp=2 lib-name= lib-ver= io-thread=1
此外,我们可以通过 top -H -p $redis_pid
清晰地监控主线程和 IO 线程的 CPU 利用率,不会像之前那样所有线程 CPU 利用率几乎都是 100%,所以我们可以轻松识别瓶颈所在。如果 IO 线程是瓶颈,增加 io-threads
的数量可以提高性能。如果主线程是瓶颈,整体性能的提升只能通过增加分片或副本的数量来实现。
性能测试
在 PR #13665[4] 中展示了 Redis IO 多线程在 AMD Ryzen9 7950x 上的测试结果,在小 KV 场景,无论普通模式还是 TLS 模式,Redis 都能突破百万 QPS。为了贴合用户的真实使用场景,我在阿里云上购买了三台 ECS,型号为计算型 c8i, ecs.c8i.4xlarge, 16 vCPU 32 GiB。其中两台部署 Redis,组成主从架构;另外一台作为压测机,部署压测程序 memtier_benchmark[5]。
测试分为两组,区别仅在 KV 大小,其他一致,300 万个 key,400 个 client, 压测时间为 60s, 写读比例有四种:1:0、0:1、1:1、1:10。除了100%读测试外(避免 Key Miss),每次测试前都会重启 Redis,清空数据。在测试时发现 IO 线程数在 6 的时候主线程基本打满,所以 io-threads
配置均为 6。压测程序需要使用多线程模式,否则根本无法压出性能极限,测试时线程数为 8。
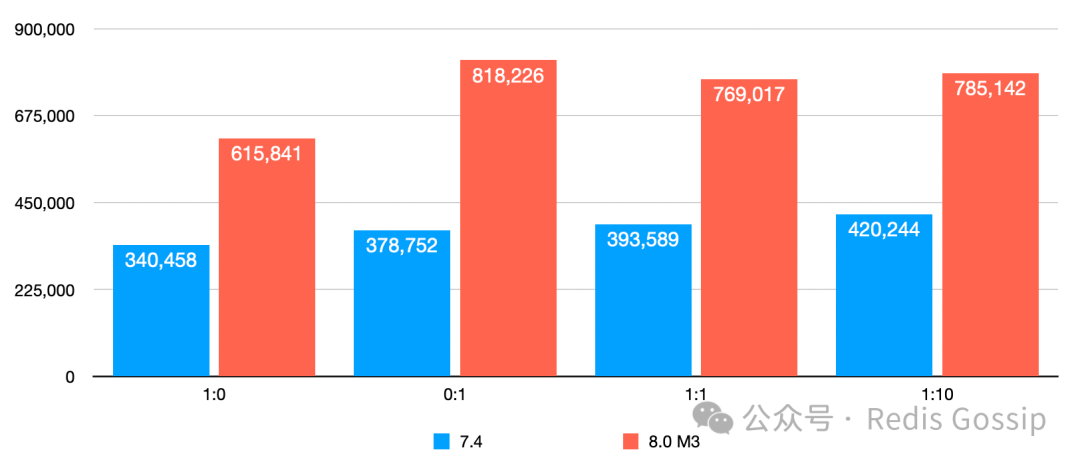
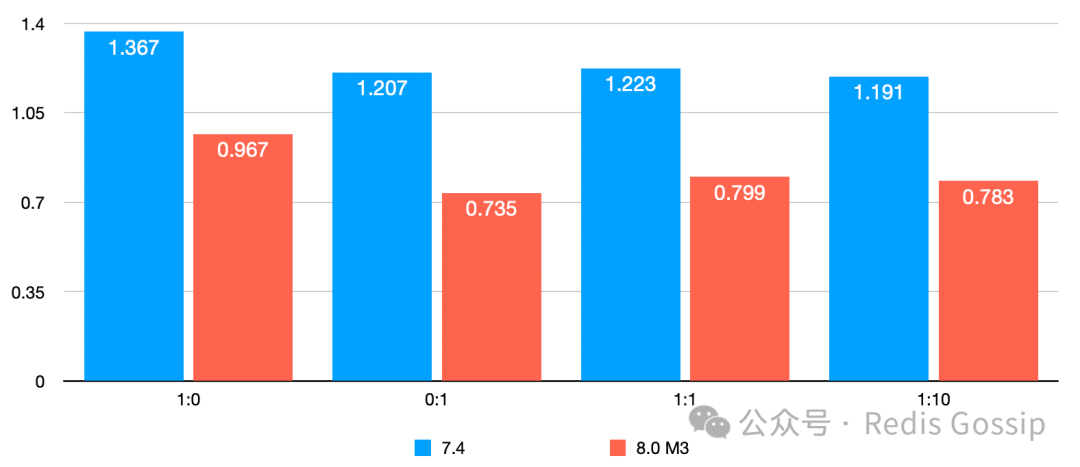
KV 大小 32 字节,QPS 和 P99 延迟如下:
memtier_benchmark -s xxx --data-size 32 --ratio xxx --key-pattern P:P --key-minimum=1 --key-maximum 3000000 --distinct-client-seed --test-time 60 -c 50 -t 8 --hide-histogram
KV 大小 512 字节,QPS 和 P99 延迟如下:
memtier_benchmark -s xxx --data-size 512 --ratio xxx --key-pattern P:P --key-minimum=1 --key-maximum 3000000 --distinct-client-seed --test-time 60 -c 50 -t 8 --hide-histogram
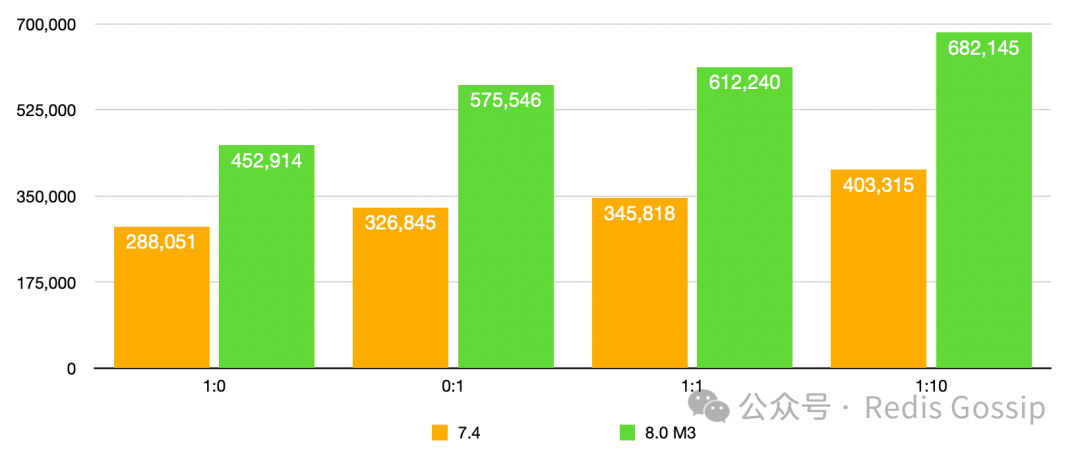
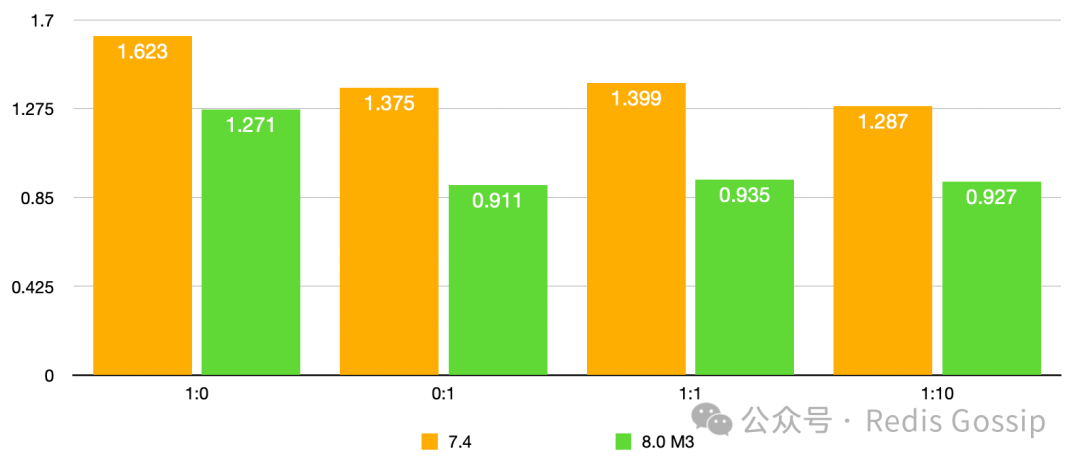
从测试对比来看,新版本的 Async IO Thread 较 7.4 QPS 至多可提升 1 倍以上,P99 延迟下降 30% 以上。需要补充说明的一下,1:10 的写读比例压测时,7.4 版本 key miss 率超过了 50%,新版本为 35% 左右。
注:在发现 CPU 剩余比较充足后,尝试将 Redis 机器换成规格更低的 ecs.c8i.2xlarge, 8 vCPU 16 GiB,
io-threads
配置仍为 6 时,发现性能下降 10% 以上,猜测可能是 vCPU 性能不够的原因。所以推荐大家在使用前,根据自己的机器配置和场景进行压测评估。
总结
在 Redis 8.0 M3 版本中,Async IO Thread 的引入显著提升了 Redis 的性能,为现代应用程序带来了更高的效率和更大的灵活性。关于该功能的详细实现,大家可查看 PR #13665[4]。
ShooterIT: https://github.com/ShooterIT
[2]sundb: https://github.com/sundb
[3]#12540: https://github.com/redis/redis/issues/12540
[4]#13665: https://github.com/redis/redis/pull/13665
[5]memtier_benchmakr: https://github.com/RedisLabs/memtier_benchmark
