




 点击蓝字,关注我们
点击蓝字,关注我们
▍作者:赵尉臣,TuGraph社区开源贡献者
方案背景
随着数据规模的急速扩张和应用场景的多样化,传统关系型数据库在处理特定领域,如社交网络、推荐系统、知识图谱等复杂关联数据时,已逐渐显现出其局限性。这些领域中的数据往往呈现出高度的关联性和复杂性,而传统数据库在处理此类数据时,往往面临着性能瓶颈和扩展性问题。
图数据库作为一种专门用于处理复杂关系网络的数据库类型,在许多场景下展现出显著的优势。然而,面对查询简单且数据量少的查询,语法解析和执行计划生成往往成为查询执行的瓶颈。如下图所示,本项目对TuGraph-DB一些简单查询的执行过程进行性能测量,并构建出了火焰图。火焰图的宽度代表了不同函数执行时间的占用比例。从图中可以看出,语法解析和执行计划生成占据了查询执行时长的70%以上。这些问题难以通过单纯优化语法解析器或执行计划生成器来解决。因此,我们可以考虑采用查询缓存的方式,对结构一致的查询的语法解析结果或执行计划进行缓存,从而显著减少查询执行的时间。
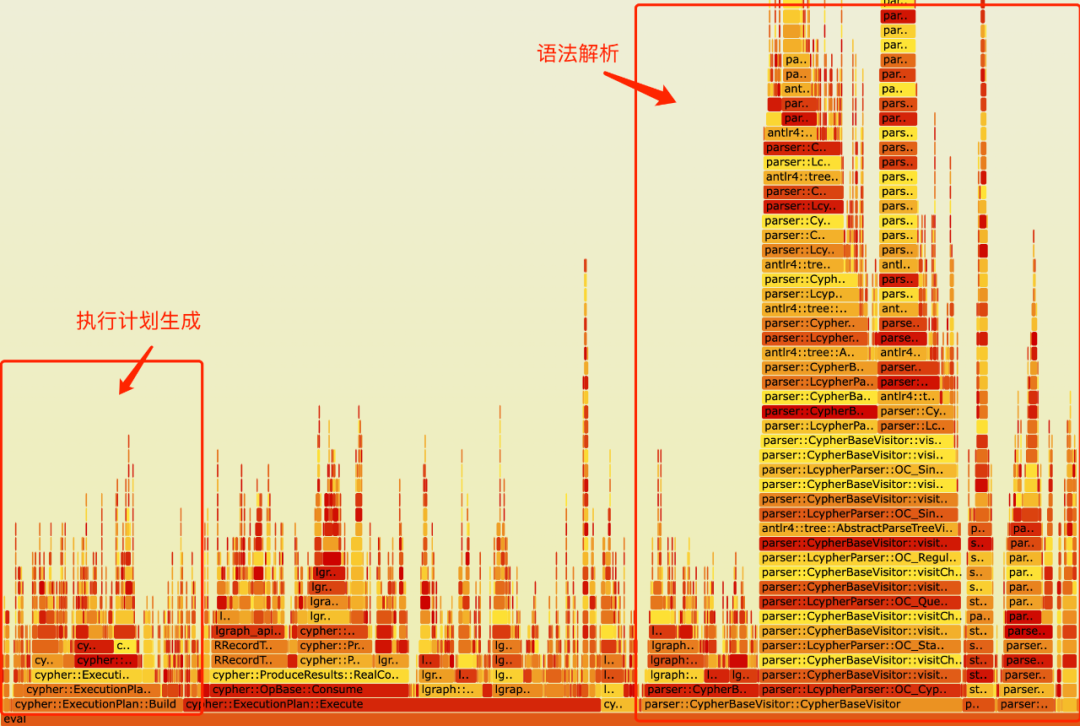
TuGraph-DB查询执行火焰图
除了查询缓存的问题,图数据库普遍采用的传统火山模型(或称为迭代器或流水线模型)在性能上存在一定的问题。与关系型数据库类似,图数据库的查询执行器也通常采用火山模型作为查询处理框架。火山模型将图结构数据的每种执行操作抽象为一种算子,图数据库首先将查询语句(如Cypher查询)解析为算子执行树。每个算子通过以下统一的迭代器接口实现:
open():初始化图操作算子,分配必要的资源。
next():实现图算子的具体执行逻辑,每次调用next()返回一条执行的结果。执行过程中可能包含调用子迭代器的next()方法。
close():关闭和回收分配的资源。
通过这种迭代器接口,图数据库通过不断调用算子执行树根节点的next()方法,从而以迭代、流水线的方式获取全部查询结果。然而,尽管火山模型具有设计简单、灵活性高等优点,TuGraph-DB的查询引擎在处理复杂和大规模数据查询时,暴露出以下性能问题 [1]-[4]:
1、执行效率低: 火山模型在执行过程中会产生大量的中间结果,这些中间结果的频繁生成和传递增加了计算和存储的负担。此外,火山模型难以利用现代CPU乱序执行、SIMD向量化执行的能力,导致查询性能下降。
2、解释性开销大: 一方面,由于算子的next()方法通过虚函数方式实现,每次调用算子的next()时,都需要通过动态分发机制(dynamic dispatching mechanism)从虚函数表中找到对应的执行函数。另一方面,每个算子需要处理多种数据类型的数据,因此对于每一条处理的数据,都需要根据其数据类型判断其对应的执行代码分支。这些问题导致大量计算资源浪费在了解释性执行开销中。
3、缺乏对编译执行的支持: 火山模型缺乏对编译执行的支持,无法针对特定查询生成高效的原生执行代码,限制了进一步提升执行效率的可能性。
这些问题表明,火山模型在处理复杂查询时存在明显的性能瓶颈。为了提升图数据库的查询性能,我们需要探索更高效的查询执行模型,例如向量化执行(vectorized execution[4])或编译执行(query compilation[8])。向量化执行通过每次调用next()返回多条数据,从而减少调用next()次数并且每次解释性操作能处理多条数据,一方面减少了解释性开销对性能的影响,另一方面能够利用现代CPU的乱序执行和SIMD指令集的优势,从而显著提升查询性能。编译执行通过将查询执行计划转换为LLVM IR,交由LLVM即时编译为原生执行代码(native code),其通过编译方式避免了解释性开销,并且能够将多个算子进行融合,生成高效的执行代码。
由于向量化执行通常需要底层存储数据以列存方式进行组织,而TuGraph-DB的存储数据是以行存方式组织的,这使得向量化执行无法直接应用于TuGraph-DB。因此,本项目探索查询编译技术在TuGraph-DB中的实现。
项目方案和初步效果
为了应对这些挑战,本项目旨在从两方面对现有的执行引擎进行优化,以提升TuGraph-DB的查询效率和性能。
实现查询缓存:引入查询参数化与缓存机制,通过缓存已生成的查询计划,避免对完全相同或结构一致的查询请求进行重复的计划生成。对于新的查询请求,TuGraph-DB首先对查询进行参数化(即将查询中的常量替换为参数符$n),然后先优先检查缓存中是否存在匹配的计划,若存在则直接复用,否则再进行新的计划生成。实验表明,在缓存命中的情况下,查询性能最高可提升4倍以上,尤其在高频重复查询场景中效果显著。
探索基于编译执行的查询引擎:引入前沿的数据库编译执行技术[6-8],构建可嵌入至火山模型的编译执行框架。该框架将通过将执行算子转换为LLVM IR进行即时编译(JIT),显著提升TuGraph-DB在处理复杂和大规模数据查询时的性能。实验验证表明,在编译算子缓存命中的情况下,编译执行算子相比传统火山模型迭代器算子,在特定场景中性能提升超过60倍。
任务一:查询缓存在TuGraph-DB中的实现
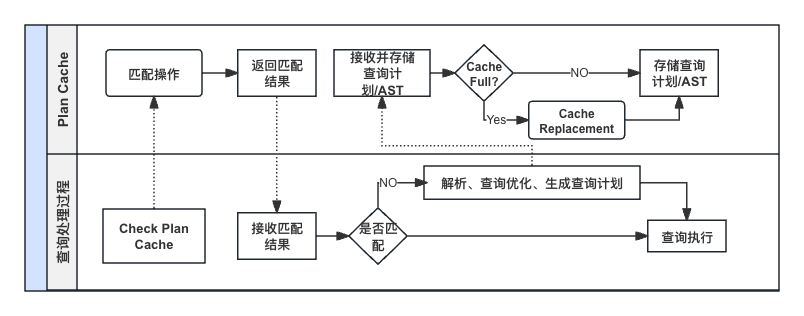
集成查询缓存后的查询处理流程
结合查询缓存后,查询的执行流程如上图所示。在执行查询时,TuGraph-DB首先会对查询进行参数化处理,将参数化的查询在LRU缓存中进行匹配。如果缓存命中,则直接复用缓存中的抽象语法树(AST),并将参数化解析的参数回填到AST中,最终生成查询执行计划再执行;如果缓存未命中,则进行语法解析,查询优化和执行计划生成,再将参数化查询作为键、解析出的AST作为值,将其加入到缓存中。如果缓存满了,则采用LRU机制进行缓存转换。
对查询进行参数化的目的是减少重复的语法解析和执行计划生成,简化缓存管理。例如查询语句
MATCH (p:Person {name:'summer'}) where p.age > 28 RETURN p LIMIT 2
MATCH (p:Person {name: $1}) where p.age > $2 RETURN p LIMIT 2
通过这种方式,结构相近但参数不同的查询语句可以复用参数化后的查询计划缓存。在执行时,只需将参数根据 $n 指示的位置回填到查询计划中即可。
由火焰图的结果可得,语法解析占了查询执行时长的较大部分。所以本项目采用了基于分词器(Lexer)的查询参数化方式,通过缓存语法解析生成的AST的方式来优化执行性能。具体来说,通过分词器对查询语句进行分词处理,将特定类型(包括整数类型、字符串类型和浮点数类型)的Token(即分词后的各个词组)替换为参数占位符(即 $n ,其中n表示其为第几个参数)。同时,并将替换出的数值存储在参数表。最终,该方法返回参数化后的查询字符串与对应的参数表。
在查询执行中,我们复用了Cypher中的参数化查询机制。Cypher参数化查询是一种使用占位符作为参数并在执行时提供参数值的查询方式。例如:
Parameters:{"name": "Johan"}MATCH (n:Person) WHERE n.name = $name RETURN n
通过提前设置"name"参数,在查询时通过$name即可引入对应的参数值。在执行时,Cypher会将$name替换为实际的参数值。TuGraph-DB已经支持了这种参数化查询机制。基于这种机制,我们将查询参数化的结果记录在RTContext结构体中的参数param_tab中。在运行时,当算子执行到参数占位符时,会从该param_tab中查询对应的参数值。
这种查询参数化方法不仅能够避免对相同结构的查询进行重复的语法解析和执行计划生成,减少计算资源的消耗,还能显著提高查询执行效率。此外,参数化查询简化了缓存管理,使得缓存中的查询计划可以被更多不同参数的查询复用,减少了缓存中存储的重复查询计划,提高了缓存的利用率,从而在面对大量相似查询的场景下,显著提升系统的可扩展性和性能。
对于查询计划或AST的缓存置换策略,项目采取了常见的LRU(最近最少使用)策略。即当缓存空间不足时,将最近最少使用的缓存块置换出去。本项目实现了基于读写锁并发控制的LRU缓存模块。
为了验证查询缓存的效果,项目对集成查询缓存后的TuGraph-DB查询执行也构建出火焰图。如下图所示,在整合查询缓存后相比于之前的火焰图,语法解析不再成为性能瓶颈,查询的有效执行时间所占整体时间比例明显增加。这一结果表明,通过查询缓存能够有效解决了对于结构简单且重复执行的查询中,语法解析成为查询执行瓶颈的问题,较为显著地提升了查询性能。
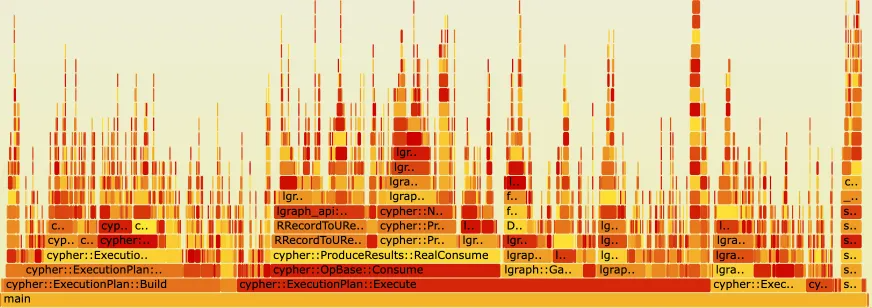
查询缓存命中时的火焰图
任务二:TuGraph-DB查询编译框架的探索
构建高性能查询执行引擎是一项极具挑战性的任务。查询编译虽然提供了卓越的性能,但同时也引入了显著的系统复杂性,使得引擎难以构建、调试和维护。尤其对于开源社区而言,如果采用复杂的查询引擎框架,会增加社区参与项目的门槛。为了克服这一复杂性,项目采用了前沿的编译执行框架[6],该框架结合了查询解释的易用性和查询编译的性能优势。
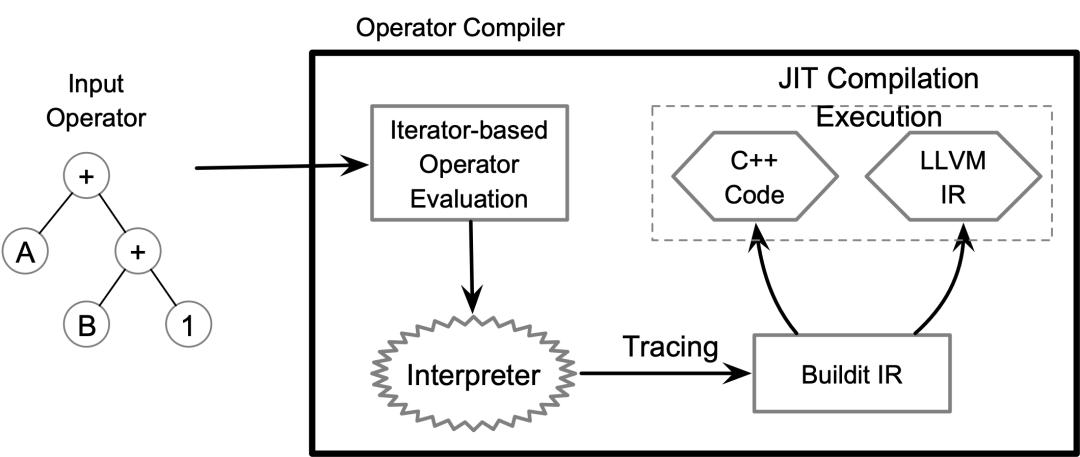
查询编译框架
如上图所示,该框架提供了一个对接火山模型的算子接口,使得开发者能够以实现火山模型算子的方式来实现操作符。不同于传统火山模型的是,该框架引入一种基于Tracing的多后端JIT编译器,缓解了火山模型本身的性能缺陷,该编译器将算子通过即时编译(JIT)的方式转换为native code。

查询编译流程
该编译执行框架的核心思想如上图所示,以执行相加操作的解释型原语为例,该框架会要求开发者用val来对声明的变量、传入的函数参数进行封装。该框架利用C++符号重载机制(Operator Overloading)对val封装的变量的运算符进行重载,从而可以识别出原语中进行了相加操作,将该操作转换为BinaryExpr::Add表达式加入到tracing栈中。最后,通过将表达式转换为后端IR(例如:LLVM IR)的方式,将解释型操作转换为编译执行的方式进行执行。
该方式不仅简化了查询算子的开发和维护难度,还在编译延迟与性能之间取得了很好的平衡。具体来说,算子可以选择火山模型的执行方式零编译时延地进行解释执行。当执行的任务较繁重时会触发编译框架的tracing任务,编译框架会对算子进行编译执行,从而利用编译算子提升后续执行性能。
项目计划构建`IR`的多种执行后端:IR Interpreter, LLVM IR, MLIR, C++等。可根据不同的工作负载特性和性能要求,选取不同的执行后端。此外,结合开发出的查询缓存功能,可以实现出对编译算子的缓存,从而减少编译带来的时间开销。
对于具体实现,本项目对TuGraph-DB的基础数据类进行封装,利用std::variant结构来实现抽象的数据封装类。
struct CScalarData {std::variant<std::monostate, // Represent the null statedyn_var<short>,dyn_var<int>,dyn_var<long>,dyn_var<float>,dyn_var<double>> constant_;lgraph::FieldType type_;}CFieldData operator+(const CFieldData &other) const {if (is_null() || other.is_null()) return CFieldData();CFieldData ret;if (is_integer() && other.is_integer()) {ret.scalar = CScalarData(scalar.Int() + other.scalar.Int());} else {...}return ret;}
以相加操作的解释原语为例,可以看到以上述方式能够非常容易实现编译执行算子,甚至不需要编译相关的前置知识。
为了验证该编译框架的效果,项目对实现好的BinaryExpr(即,进行加减乘除等算数运算的表达式)算子与TuGraph-DB原先的火山模型进行性能对比,编译执行算子的性能能够比解释执行算子提升60多倍。由于图算子的复杂性,项目仅对表达式执行进行了相应的适配,还没有实现更为复杂的聚合算子和图复杂的执行算子。
未来展望
查询是一个CALL语句
limit/skip 关键词后的数值不做参数化。 查询中的范围数值不做参数化: `` ()->[e*..3]->(m)`` 。 返回体中的数值不做参数化: `` return RETURN a,-2,9.78,'im a string'`` 。 查询涉及 MATCH ... CREATE 。例如
·END·

欢迎关注TuGraph代码仓库✨
https://github.com/tugraph-family/tugraph-db
https://github.com/tugraph-family/tugraph-analytics
