接上一篇:PolarDB-X 列存索引 | 分析TPC-H执行计划 (一)
TPC-H优化点
所有的优化点以及对应的查询罗列如下
| 优化点 | 可应用的查询 |
|---|---|
| partition wise | Q2、Q3、Q4、Q9、Q10、Q12、Q13、Q14、Q16、Q18、Q21 |
| 列裁剪 | Q1-Q22 |
| 常量折叠 | Q1、Q4、Q5、Q6、Q14、Q15、Q19、Q20 |
| 两阶段agg | Q1、Q4、Q5、Q6、Q7、Q8、Q9、Q11、Q12、Q13、Q14、Q15、Q16、Q17、Q19、Q21、Q22 |
| 基数估计 | Q9、Q13 |
| Reverse semi hash join | Q4、Q21 |
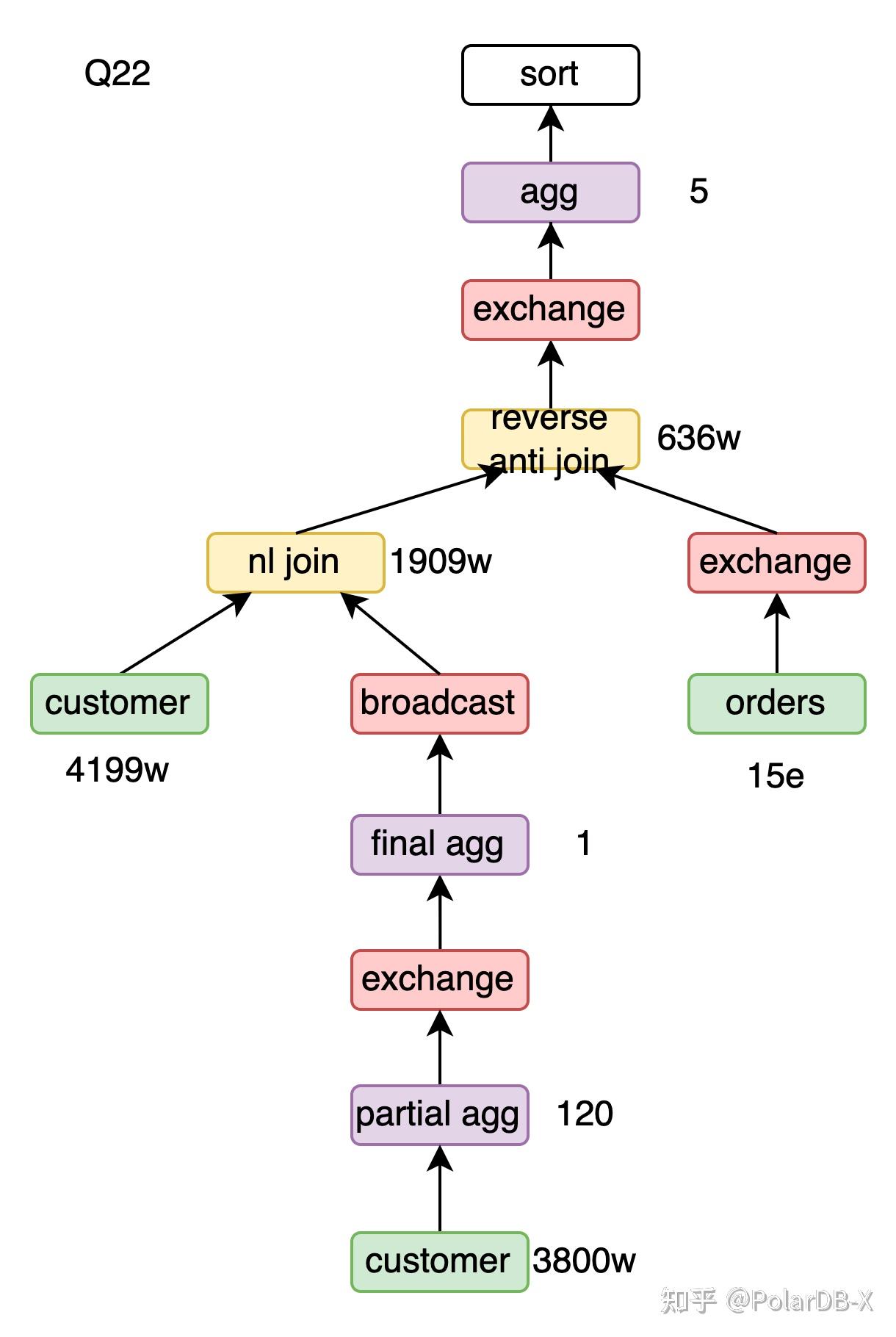
| Reverse anti hash join | Q21、Q22 |
| Join-Agg转Join-Agg-Semijoin | Q20 |
| Group join | Q13 |
| Hash window | Q17 |
partition wise
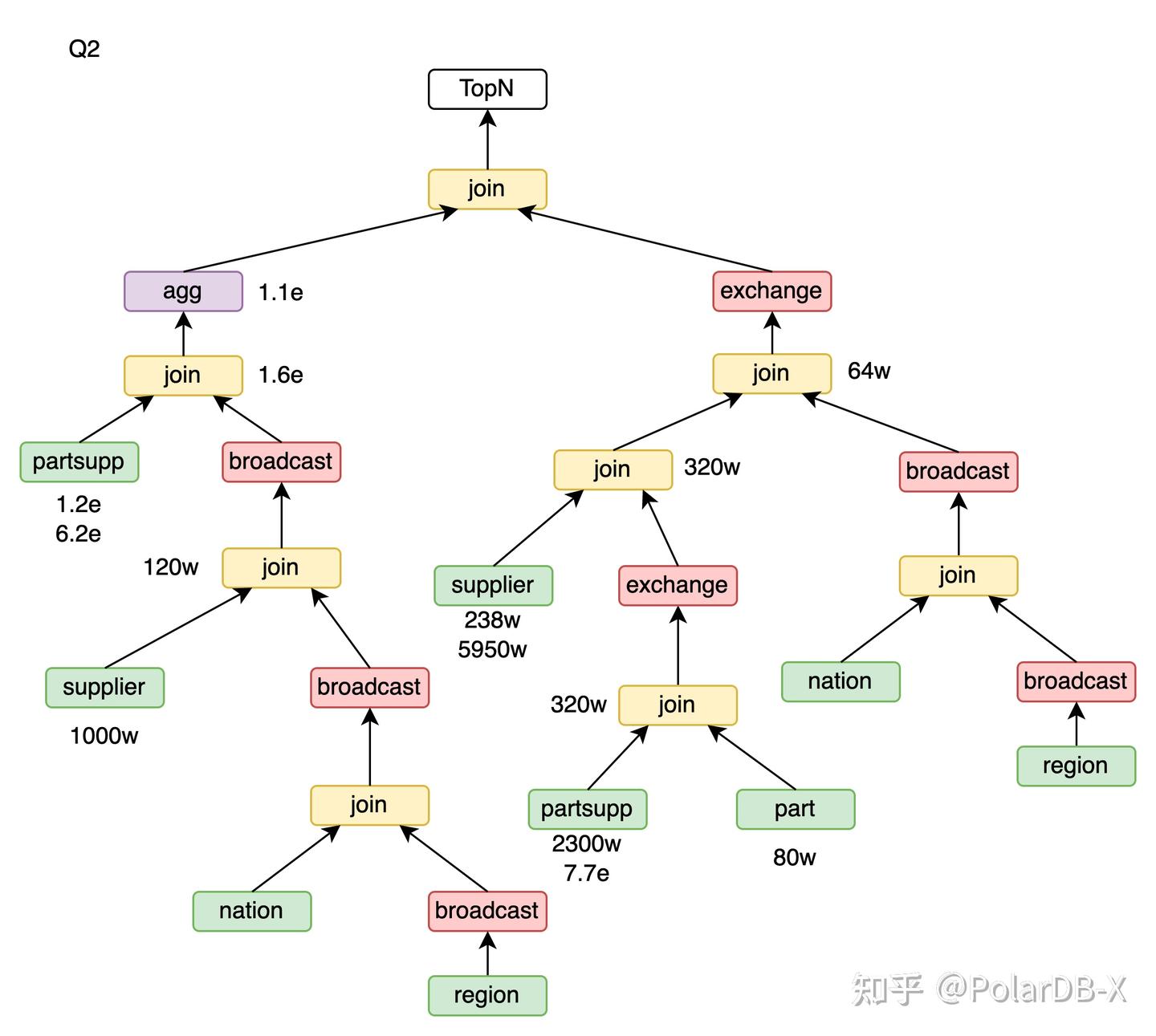
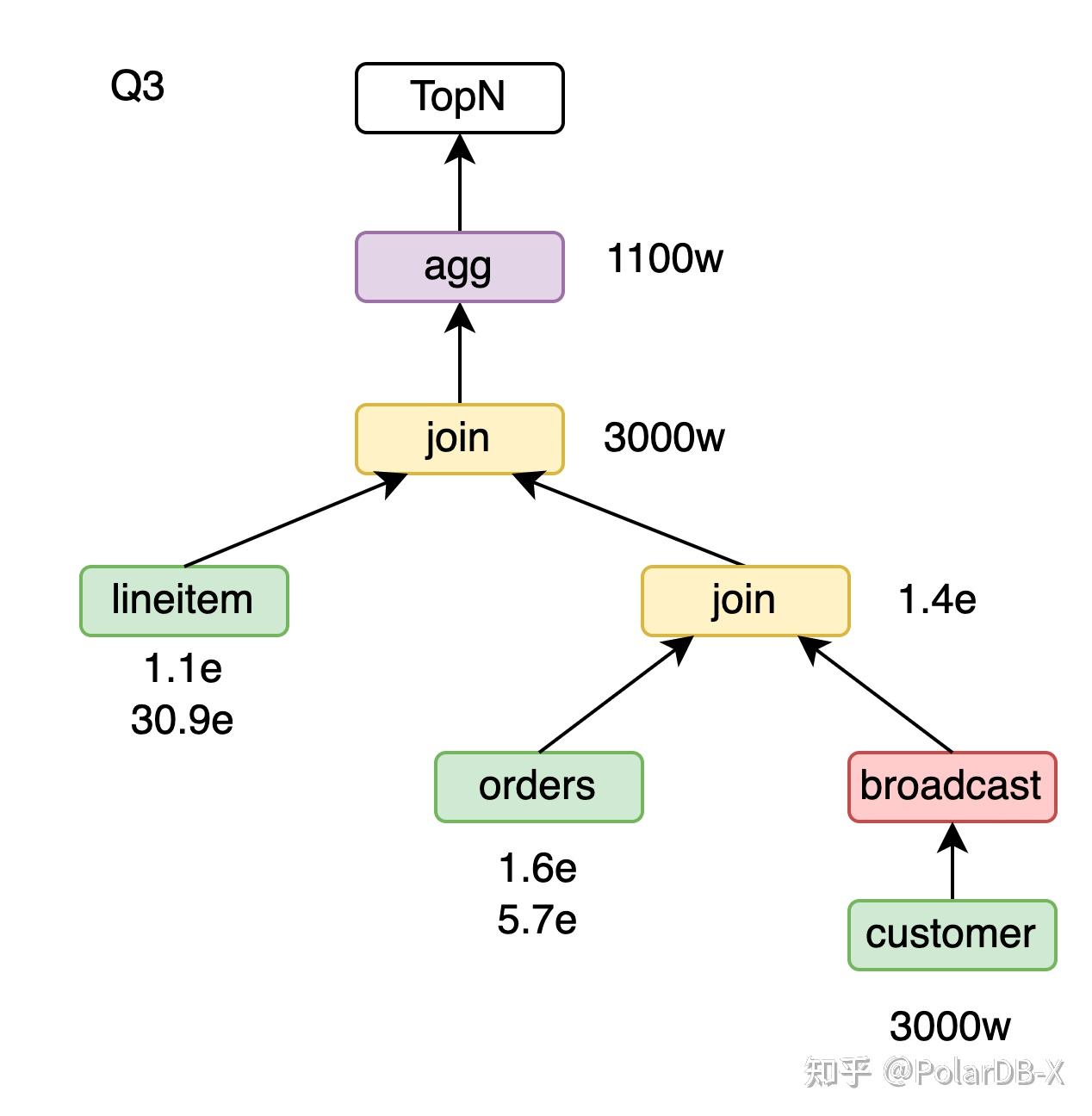
以Q3为例,lineitem按l_orderkey分片,orders按o_orderkey分片,customer按c_custkey分片。
select
1
from
customer,
orders,
lineitem
where
c_custkey = o_custkey
and l_orderkey = o_orderkey
group by
l_orderkey,
o_orderdate,
o_shippriority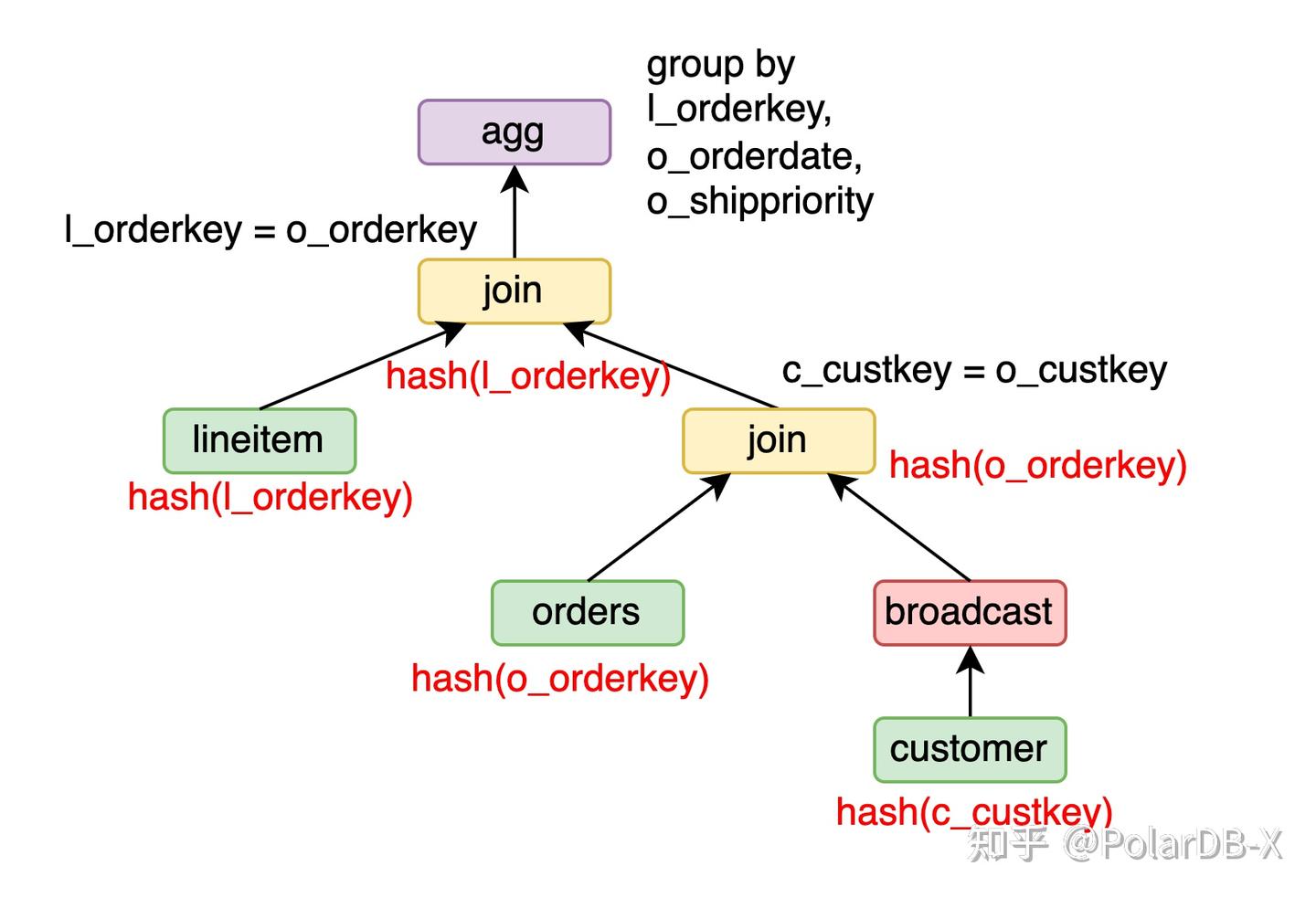
对于orders join customer,将customer做广播,orders join customer可以保持o_orderkey的分片属性。进一步 lineitem join (orders join customer),lineitem有l_orderkey的分片属性,orders join customer有o_orderkey的分片属性,可以做partition wise join,并保持l_orderkey的分片属性。最后的group by l_orderkey, o_orderdate, o_shippriority,由于输入保持l_orderkey的分片属性,可以做partition wise agg。
PolarDB-X的broadcast join
void columnarBroadCastRight(Join join, RelNode leftChild, RelNode rightChild) {
join.Distribution = ANY;
leftChild.Distribution = ANY;
rightChild.Distribution = BROADCAST;
return;
}若右孩子的分布属性为broadcast,passThroughTrait会将需要的join分布属性传递到左孩子,从而一步步向下传递直到列存索引上。
void passThroughTrait(
Distribution required, Join join, RelNode leftChild, RelNode rightChild) {
RelDistribution distribution = required.Distribution;
if (rightChild.Distribution == BROADCAST) {
for (int key : required.getKeys()) {
if (key >= leftInputFieldCount) {
return;
}
}
join.Distribution = required;
leftChild.Distribution = required;
}
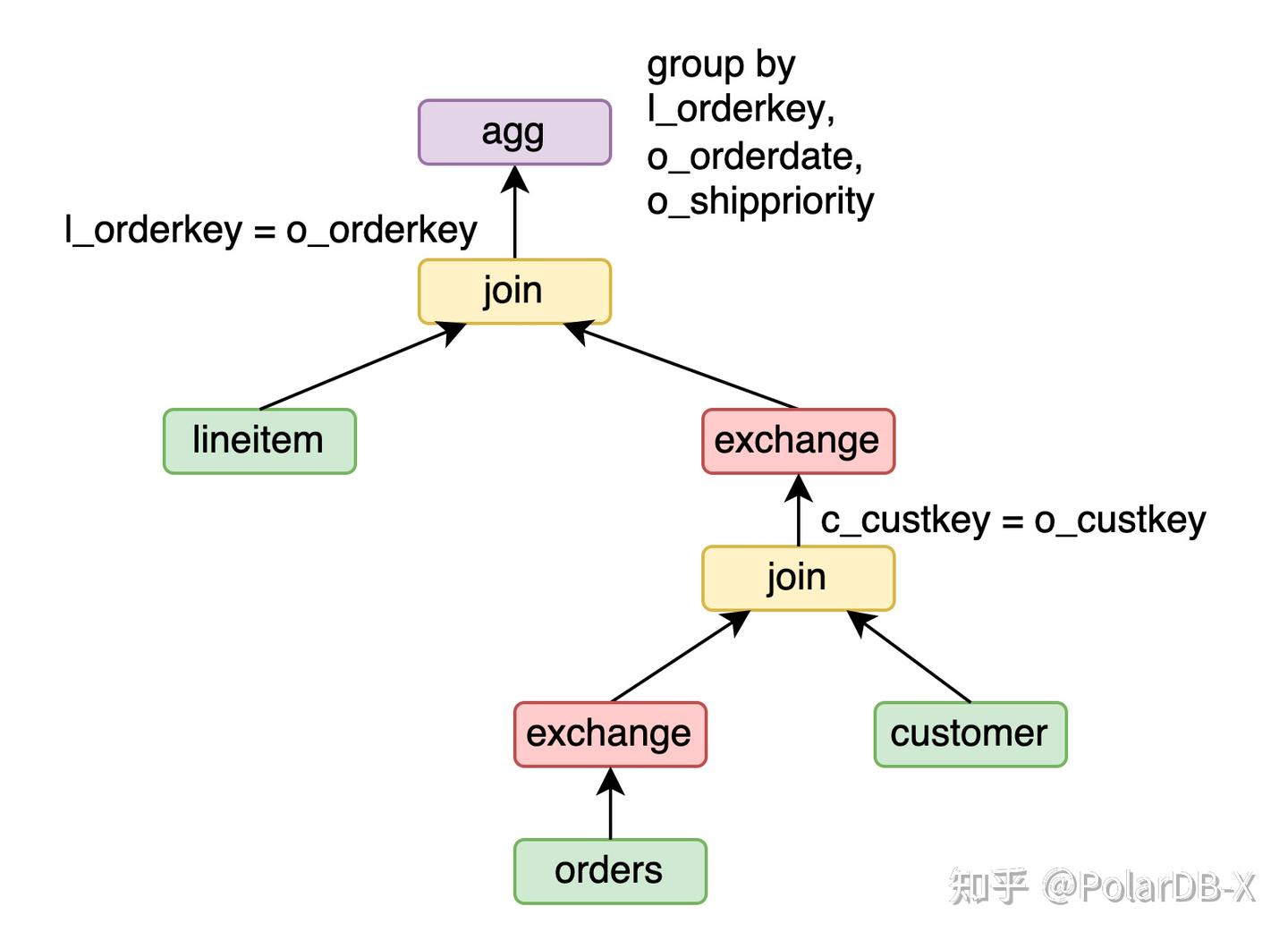
}除了broadcast,也可以用exchange。例如Q3,将orders按o_custkey做exchange来获得o_custkey的分片属性,customer有c_custkey的分片属性,orders join customer可以做partition wise join。接着将orders join customer按o_orderkey做exchange,lineitem join (orders join customer)可以做partition wise join。
由于这个执行计划代价需要exchange两次,代价高于上述broadcast的计划,CBO并没有采用。
columnarBroadCastRight与passThroughTrait共同作用的问题是broadcast join可能PassThrough所有输出的列,导致搜索空间急剧膨胀,所以必须尽早裁剪掉不需要的broadcast join。
裁剪逻辑如下:对于A join B,A join broadcast(B)必然可以表示为shuffle(shuffle(A) join shuffle(B),所以若broadcast(B)的代价大于shuffle(A)+shuffle(B)+shuffle(A join B)的代价,就可以避免优化器产生冗余的A join broadcast(B),因此不再需要PassThrough A的任何一列。
列裁剪
为了降低大规模数据处理任务中的shuffle成本,需要在shuffle操作之前通过project算子对列进行裁剪,以减少冗余列。join操作后通常会引入冗余列,增加shuffle的数据量,从而导致性能下降。shuffle算子的NET成本公式被设计为NET_COST = rowSize * rowCount / NET_BUFFER_SIZE,其中rowSize指的是每行的数据量。显然,较大的rowSize直接增加了shuffle的代价,CBO会自然选择经过列裁剪的执行计划。
public RelOptCost computeSelfCost() {
double rowCount = getRowCount();
long rowSize = estimateRowSize(getInput().getRowType());
if (distribution == BROADCAST) {
rowCount = rowCount * parallelism;
}
cpuCost=...;
netCost = rowSize * rowCount / NET_BUFFER_SIZE);
return costFactory.makeCost(rowCount, cpuCost, 0, 0,
Math.ceil(netCost);
}列裁剪的实现要点有三个:
- 列存RBO将project算子尽量下推。
- 列存CBO进行逻辑算子变换时保留project算子。
- 代价模型考虑shuffle时的列宽。
常量折叠
常量折叠就是优化器阶段将可以直接计算的常量提前计算出来,例如Q1的过滤条件l_shipdate <= '1998-12-01' - interval '118' day会被优化器转成l_shipdate <= '1998-08-05'。
由于常量折叠只会应用一次,对性能没有要求,直接调用标量函数的计算接口即可。 需要注意PolarDB-X的解析器会将常量进行参数化,方便plan cache进行匹配。Q1的过滤条件被参数化成l_shipdate <= ? - interval ? day,常量折叠成l_shipdate <= '1998-08-05'后执行计划无法复用,因此常量折叠与plan cache不兼容。默认情况下列存plan cache关闭,常量折叠打开。若打开了列存plan cache,常量折叠会自动关闭。
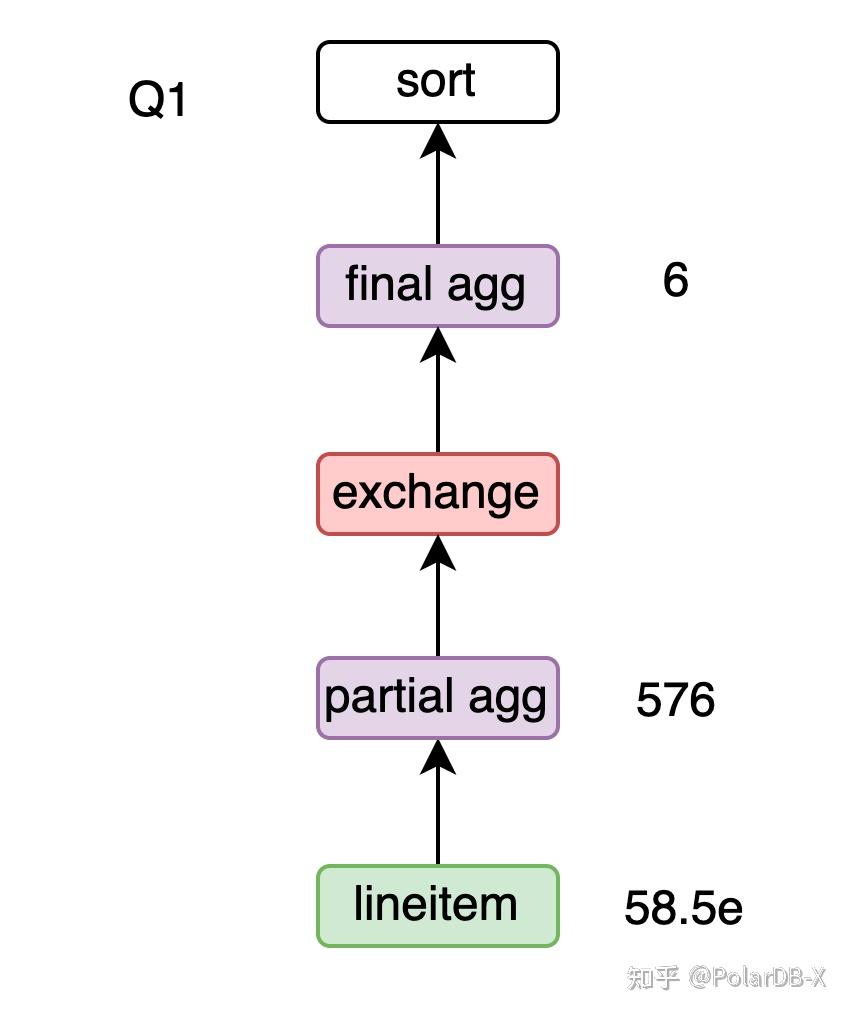
两阶段agg
Q1的group by l_returnflag, l_linestatus需要拆成两阶段,避免大量的数据shuffle。先做分片级的partial agg group by l_returnflag, l_linestatus,再做global agg group by l_returnflag, l_linestatus,shuffle数据量从58.5亿降低到了576行。但如果agg本身产生的结果很多,两阶段agg有可能无法减少数据的shuffle量,反而引入了冗余的agg计算,所以需要通过基数估计确定两阶段agg是否有收益。 由于partial agg是分片级的,会有结果集放大的问题,基数估计的公式需要做下调整:rows为输入的总行数,bins为agg的rowcount估算。考虑每个分片的情况,每个分片上有
行数据,共有bins个不同的分组,这也是Balls into Bins,rowcount估算为
基数估计
对于x join y on x.a = y.b and x.c = y.d,基数估计计算公式为
。Q9中的join条件 ps_suppkey = l_suppkey and ps_partkey = l_partkey涉及到partsupp的复合主键,需要在join的基数估计时改为
。 Q9的过滤条件p_name like '%goldenrod%',目前没有专门的处理,采用heuristic
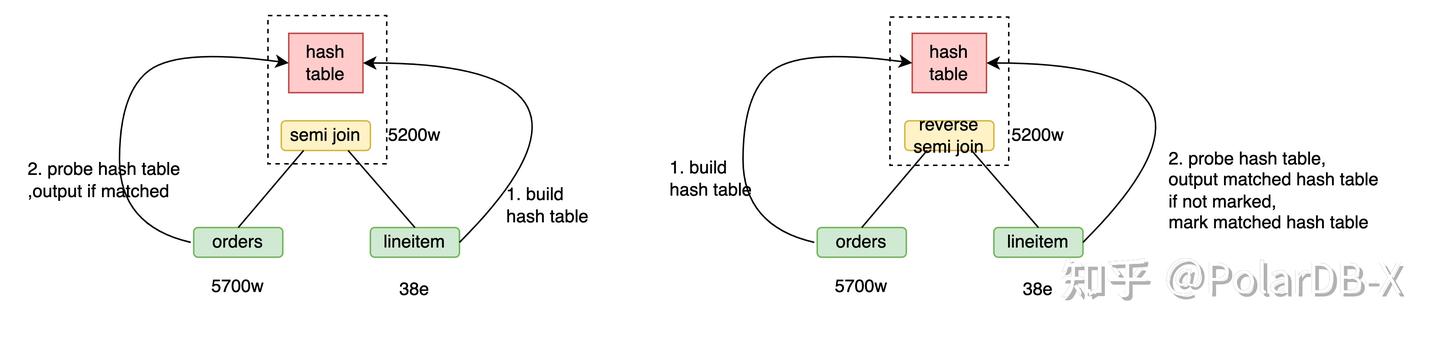
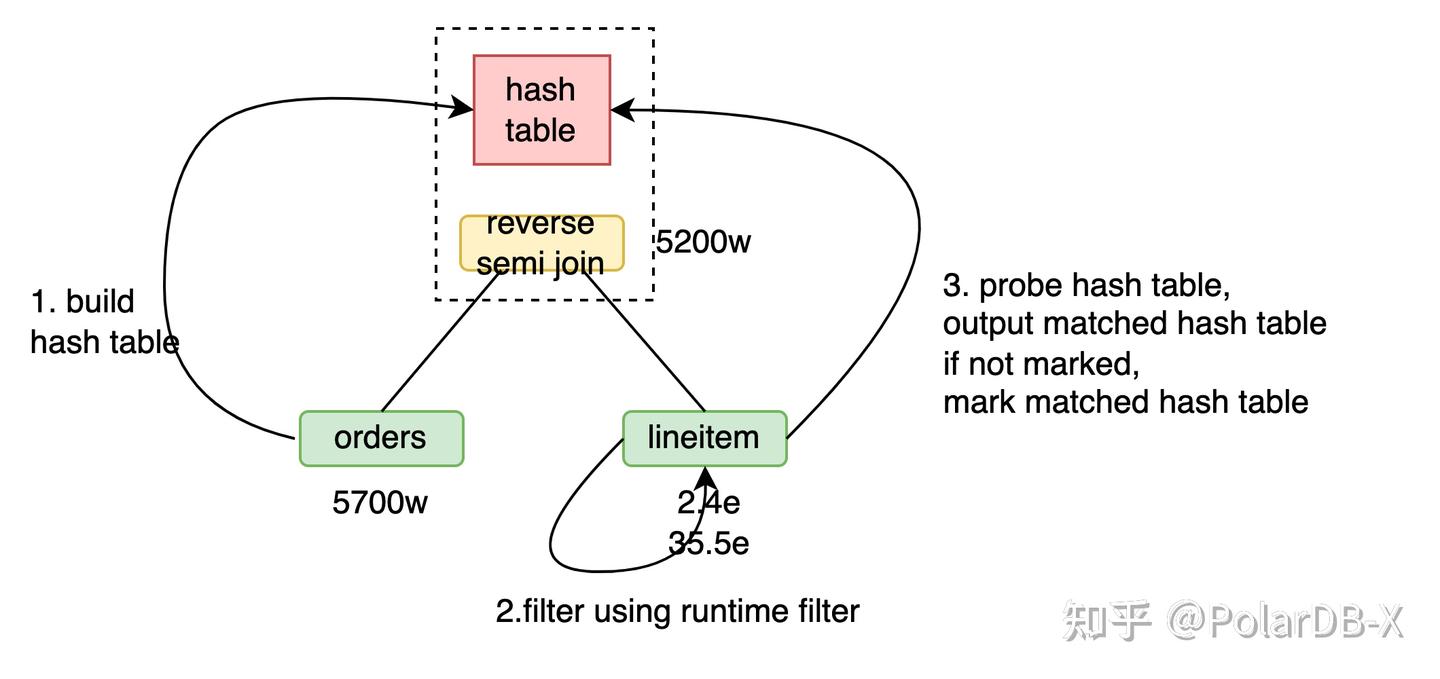
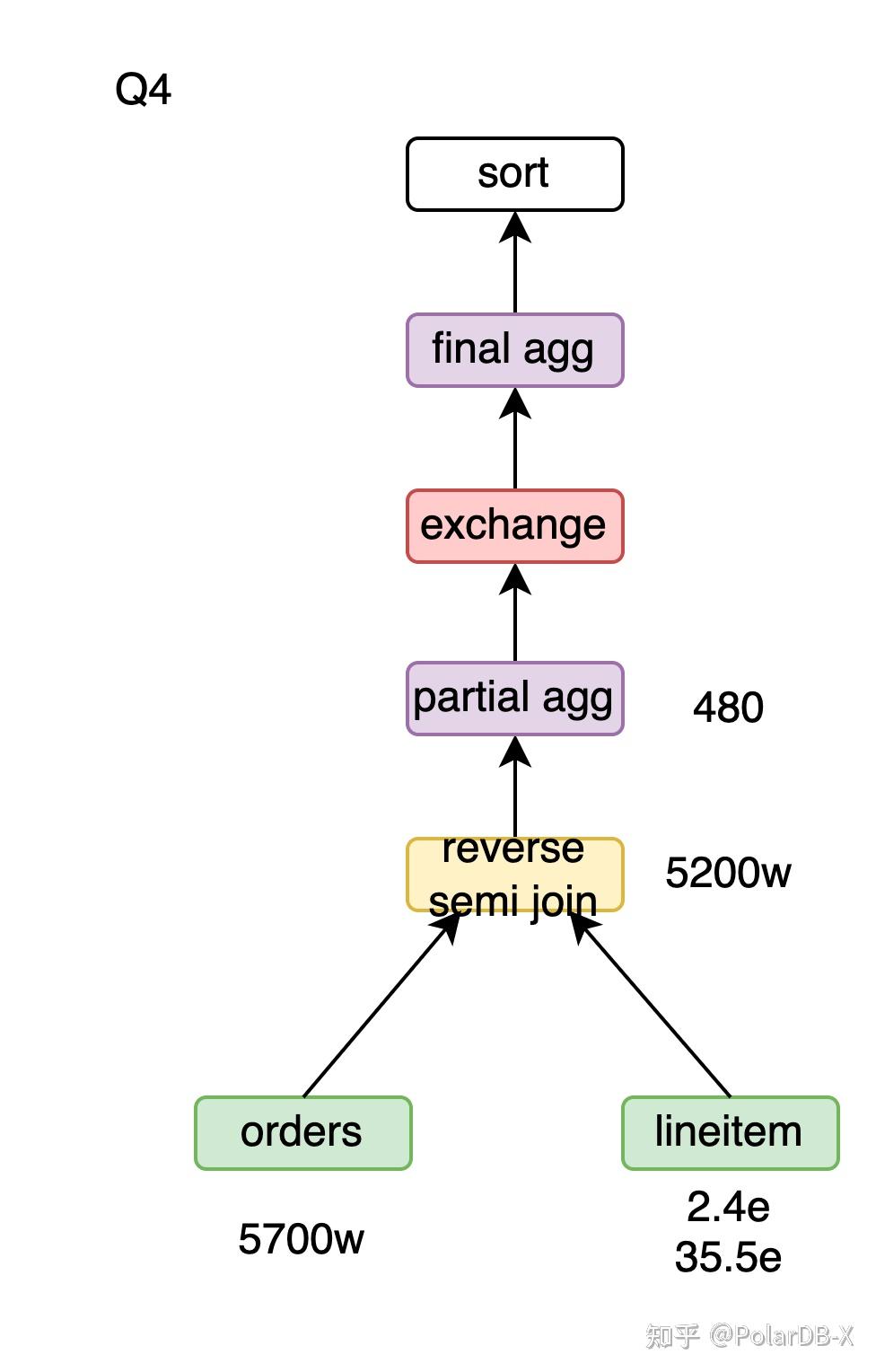
Reverse semi hash join
Q4中exists子查询转成semi join后变成了orders semi join lineitem。 用orders semi hash join lineitem,流程为
- 用lineitem构建38亿行的哈希表。
- orders的5700万数据探查哈希表,输出匹配的行,共5200万。
用orders reverse semi hash join lineitem,流程为
- 用orders构建5700万行哈希表。
- lineitem的38亿行数据探查哈希表,输出未被标记的哈希表记录并标记其已被匹配,共5200万。
由于探查哈希表效率远高于构建哈希表,当前场景下reverse semi hash join效率更高。
对于
对于
对此给出证明。 证明 设A用runtime filter过滤后的结果集为C,要证明
,只需要证明
引入runtime filter的orders reverse semi hash join lineitem的流程为
- 用orders构建5700万行哈希表。
- 用orders的runtime filter过滤lineitem,得到2.4亿行。
- lineitem的2.4亿行数据探查哈希表,输出未被标记的哈希表记录并标记其已被匹配,共输出5200万。
由于runtime filter探查效率远高于探查哈希表,当前场景下引入runtime filter后效率更高。
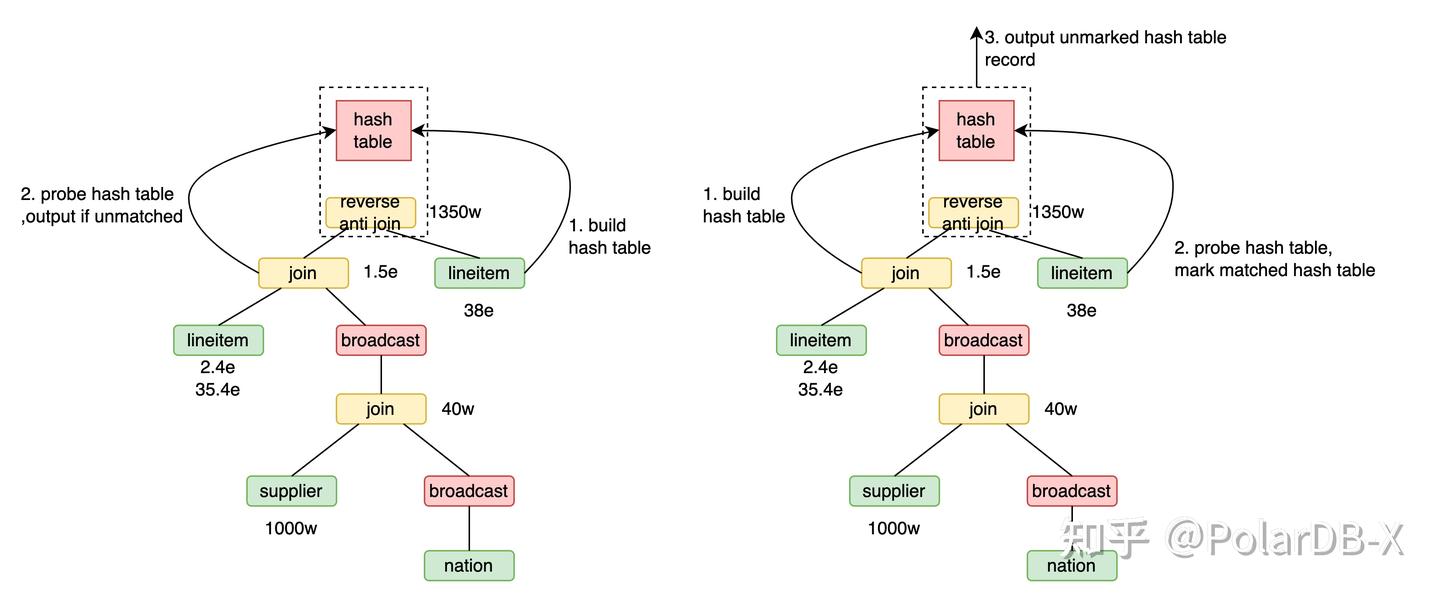
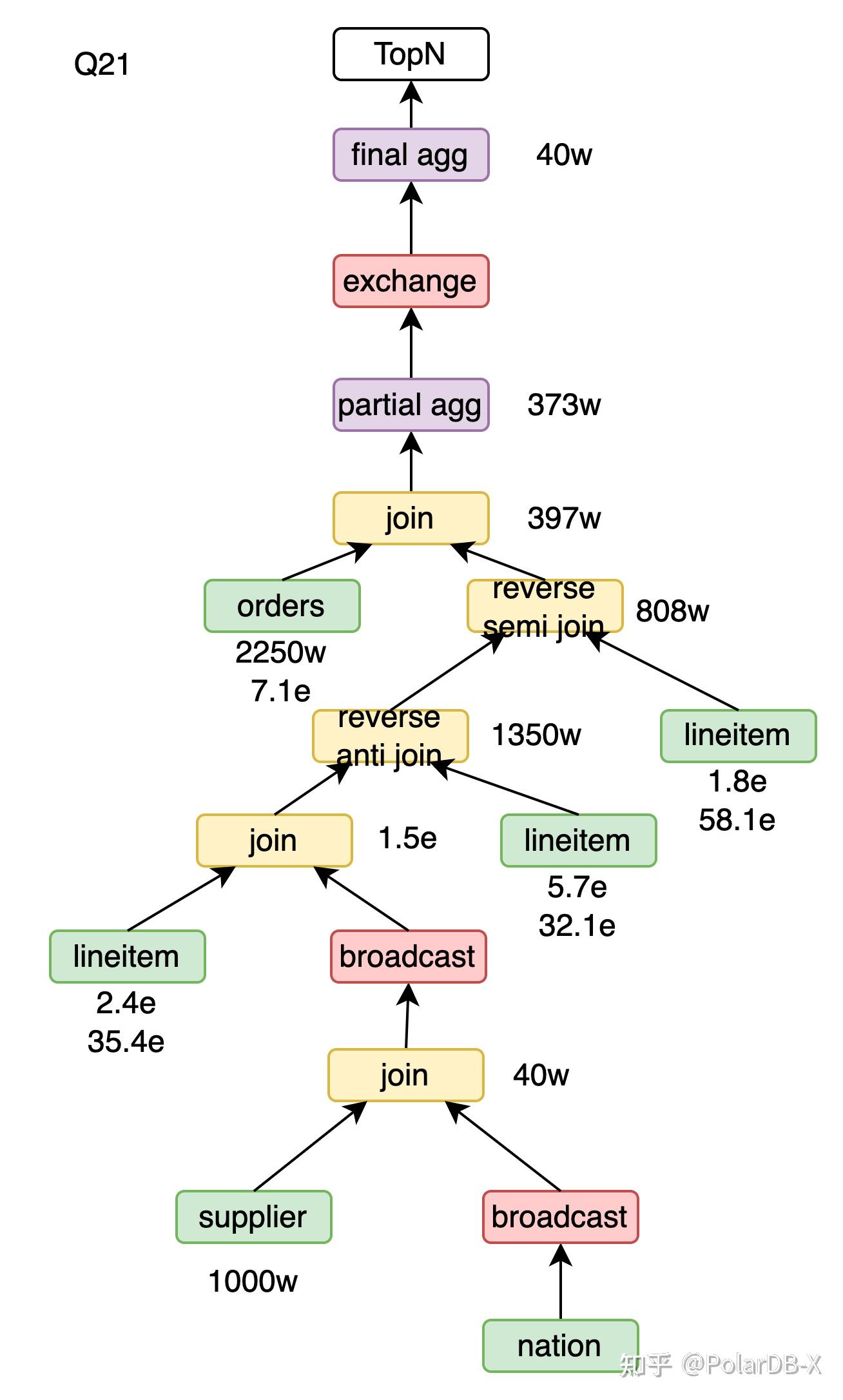
Reverse anti hash join
Q21中not exists子查询转成anti join,变成了xx anti join lineitem,这里的xx为linitem、supplier、nation三表join的结果。 用xx anti hash join lineitem,流程为
- 用lineitem构建38亿行的哈希表。
- xx的1.5亿行数据探查哈希表并输出不匹配的数据,共1350万行。
用xx reverse anti hash join lineitem,流程为
- 用xx构建1.5亿行的哈希表。
- lineitem的38亿数据探查哈希表并标记匹配。
- 遍历哈希表最后输出哈希表中未被标记的数据,共1350万行。
由于探查哈希表效率远高于构建哈希表,当前场景下reverse anti hash join效率更高。
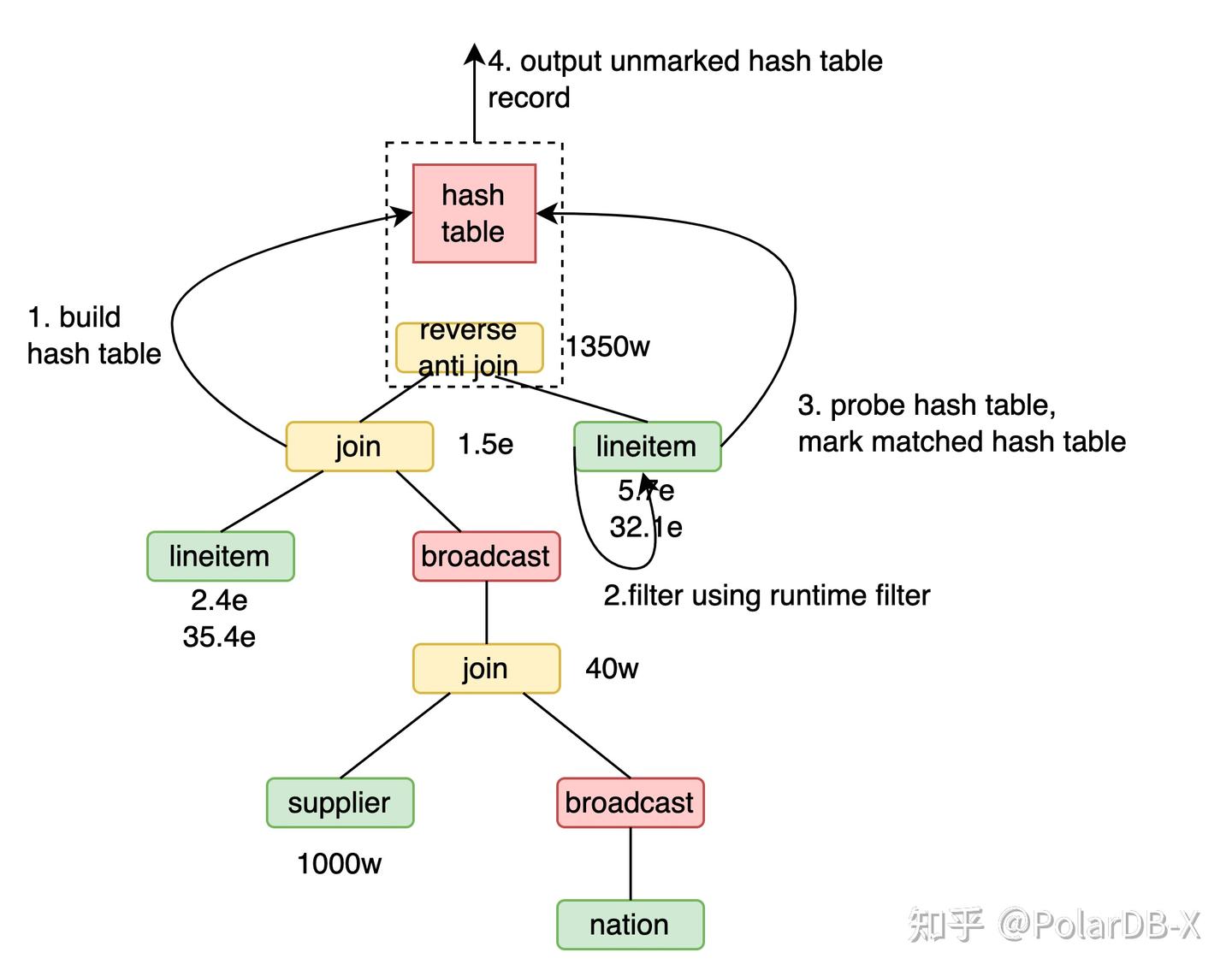
对于
引入runtime filter的xx reverse anti hash join lineitem的流程为
- 用xx构建1.5亿行的哈希表。
- 用xx的runtime filter过滤lineitem,得到5.7亿行。
- lineitem的5.7亿数据探查哈希表并标记匹配。
- 遍历哈希表最后输出哈希表中未被标记的数据,共1350万行。
由于runtime filter探查效率远高于探查哈希表,当前场景下引入runtime filter后效率更高。
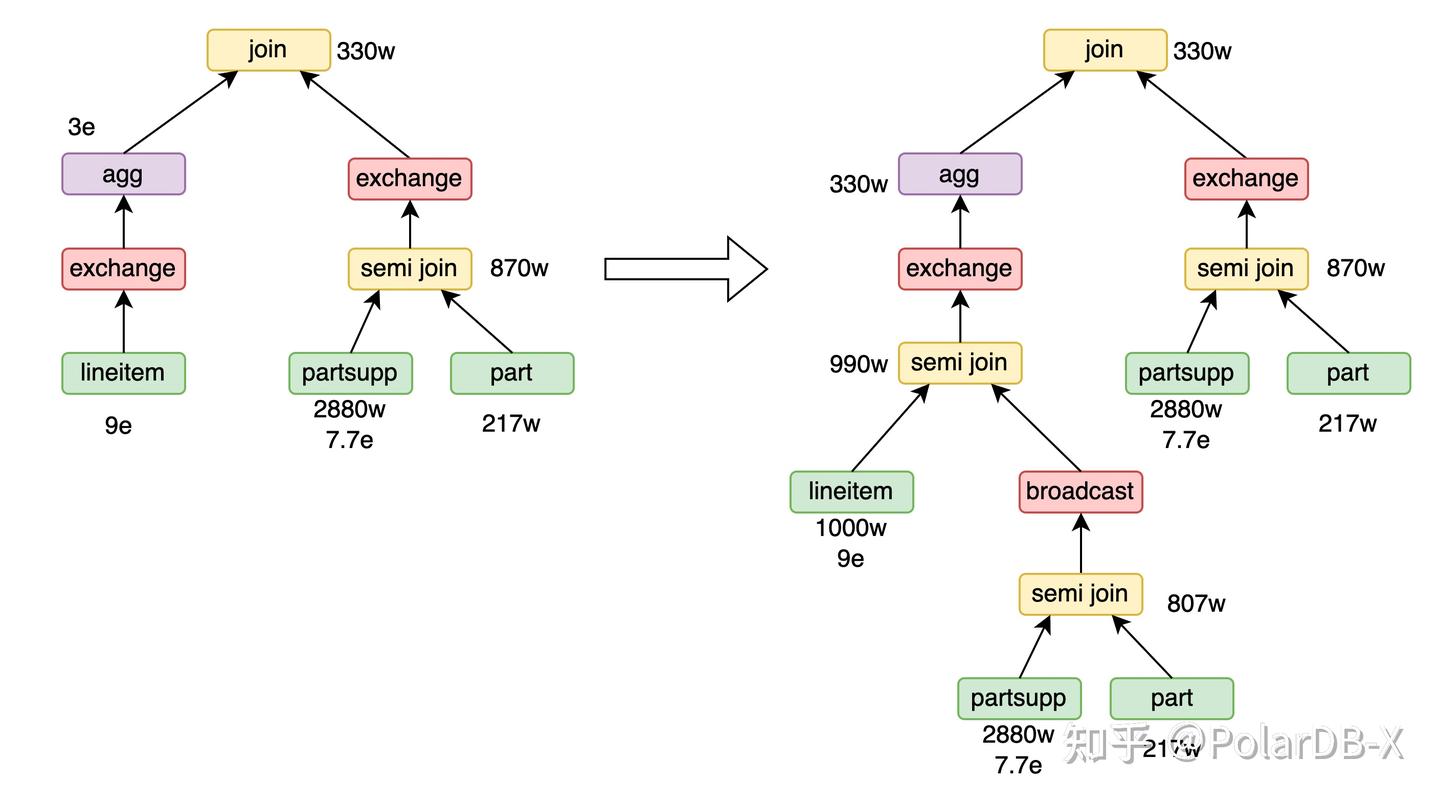
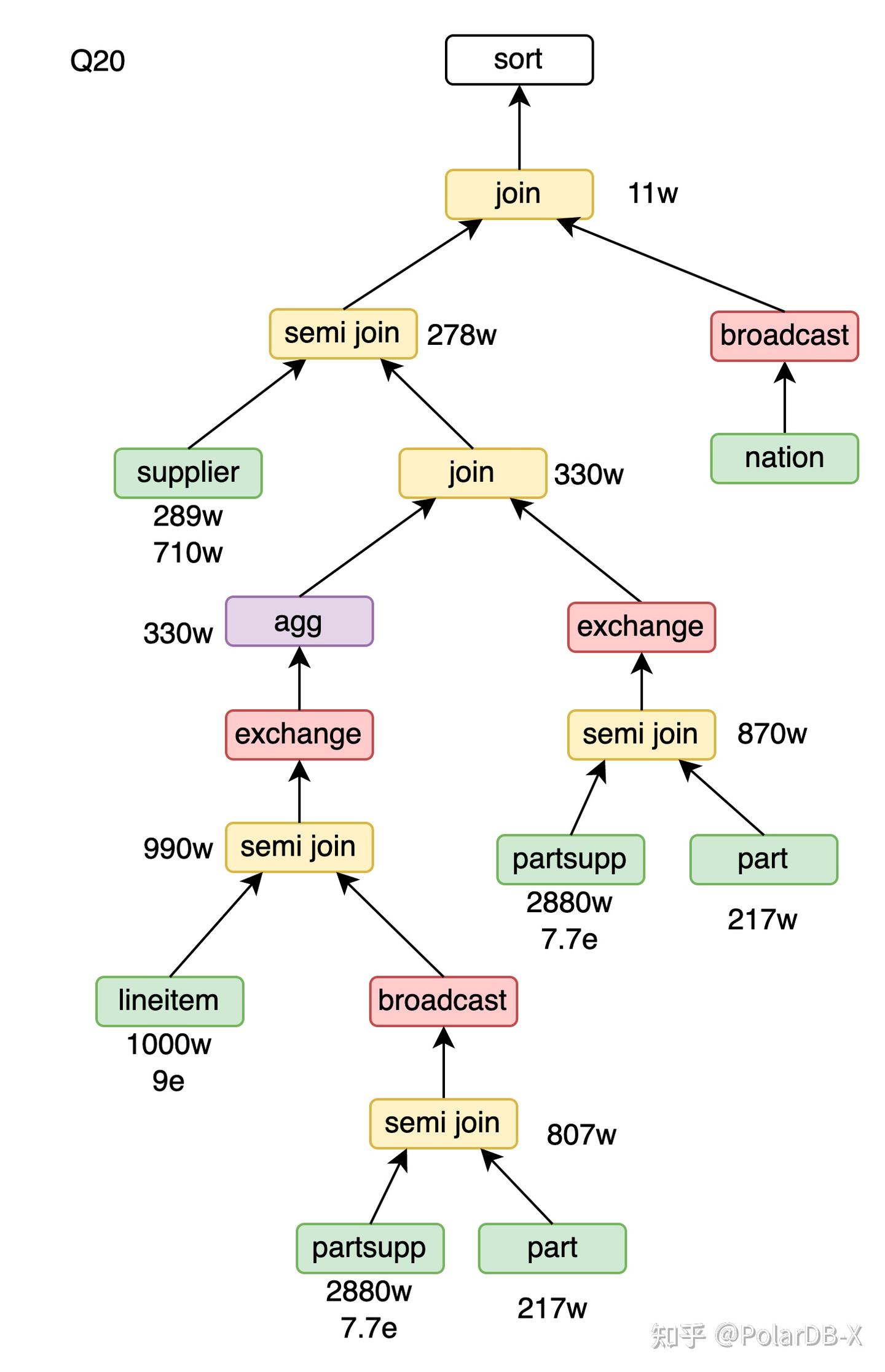
Join-Agg转Join-Agg-SemiJoin
目前,PolarDB-X的runtime filter在join的probe端无法穿透shuffle操作。这一限制对Q20查询的性能带来了负面影响:在lineitem表上的agg计算出大量冗余结果,在agg之前使用runtime filter将其筛选掉可以提升性能。然而,lineitem表和agg操作之间的shuffle阻碍了runtime filter的下推。为了解决此问题,我们引入了一个CBO规则:将join的右孩子节点复制,并与agg的输入进行semi join,从而起到runtime filter的作用。
Group join
group join限制过于严苛,且可能有负面作用,导致实际应用并不多,具体可参考这篇文章[10]。PolarDB-X当前对group join限制为
- 只支持等值join。
- 对于inner join、left join,group by的列完全匹配左孩子的join key,agg运算的列属于右孩子。
- 对于right join,group by的列完全匹配右孩子的join key,agg运算的列属于左孩子。
- group by的列全局唯一。
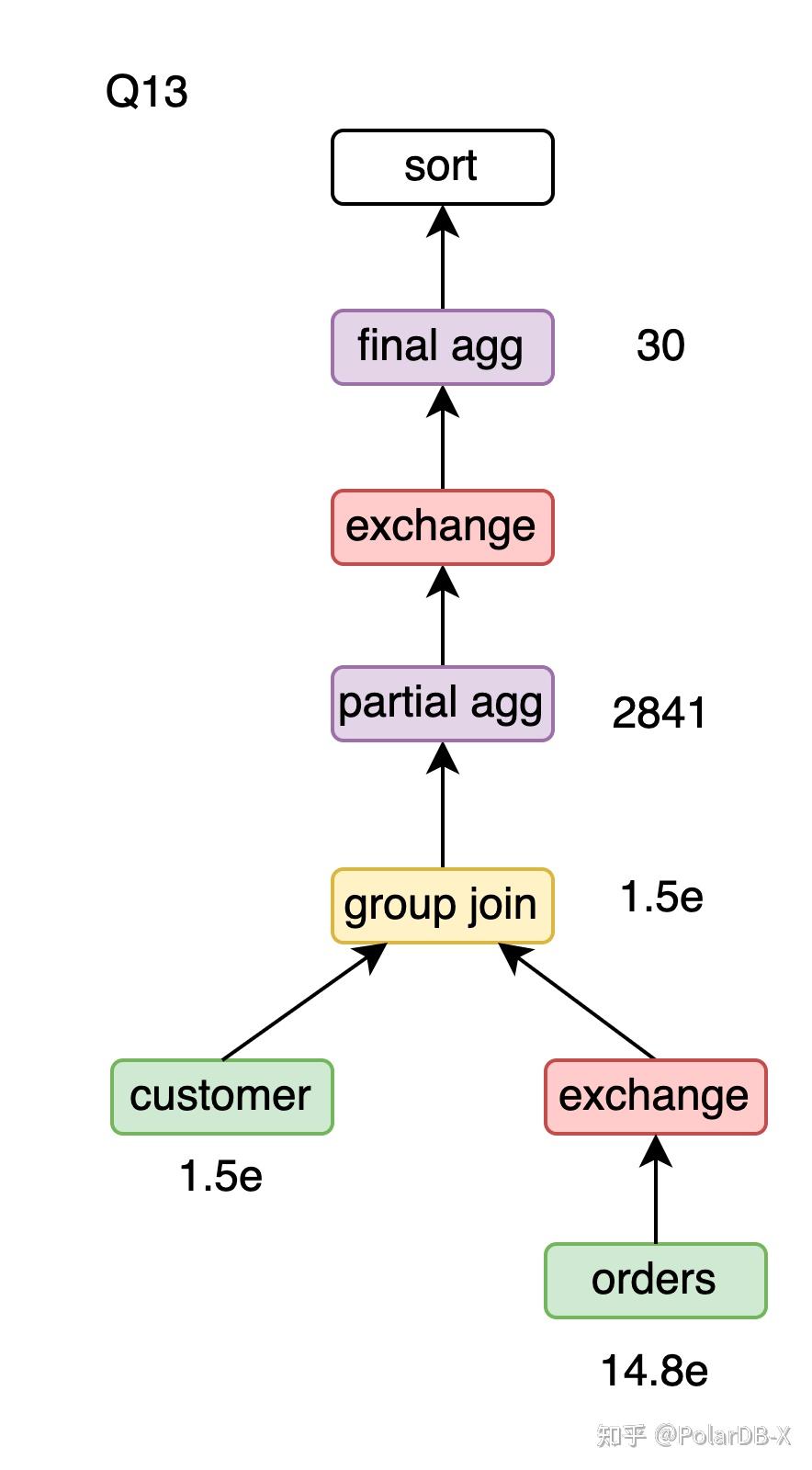
全局唯一的限制主要是为了避免group join导致中间结果集放大的问题。对于Q13,可以应用group join。
select
c_custkey,
count(o_orderkey) as c_count
from
customer
left outer join orders on c_custkey = o_custkey
and o_comment not like '%special%packages%'
group by
c_custkeygroup join的执行流程
- 对customer表用c_custkey建哈希表。
- orders的数据探查哈希表并计算count(o_orderkey)。
- 遍历哈希表,用null填充未匹配记录的agg结果,输出agg结果。
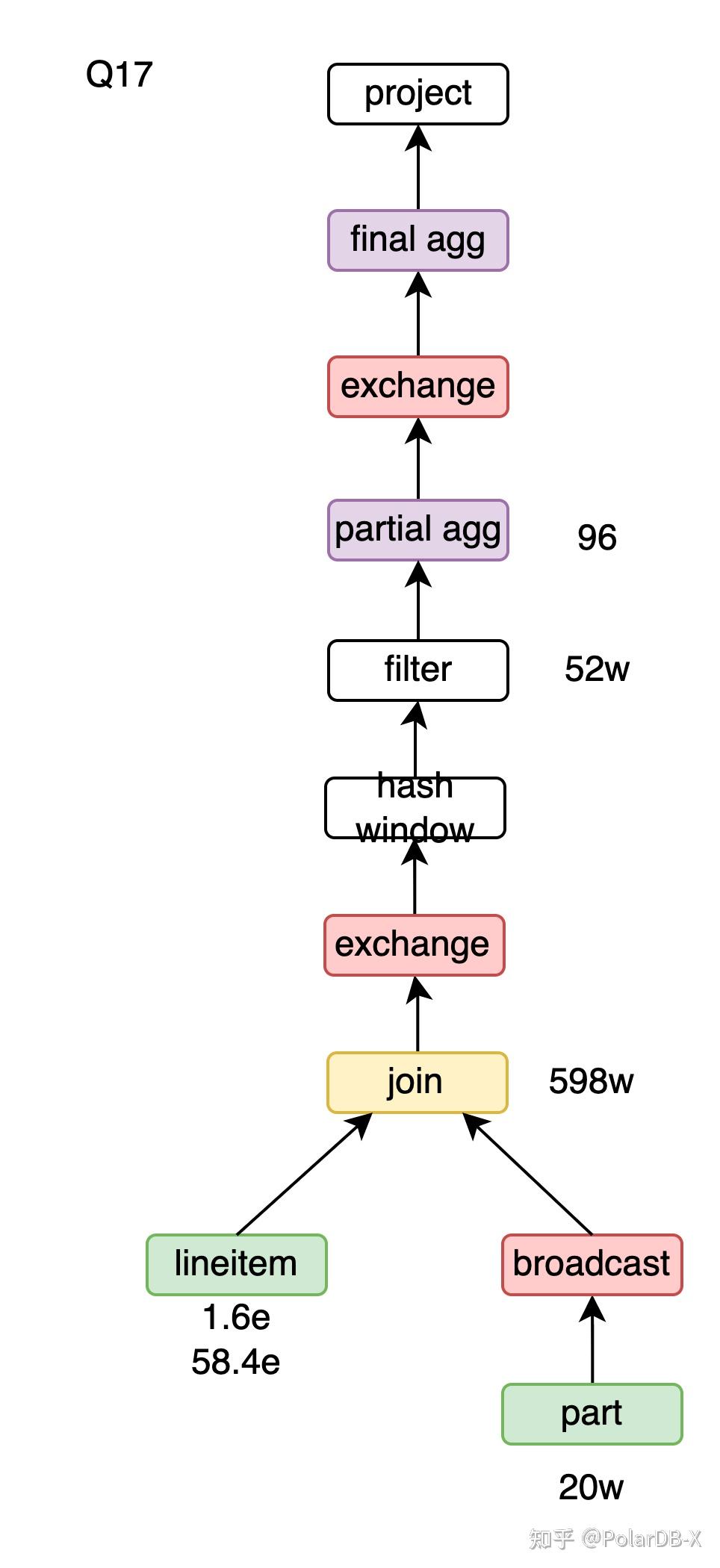
Hash window
将Q17的子查询转window节省一次lineitem的扫描,进一步可以使用hash window。由于并行度的区别,PolarDB-X上的hash window比sort window更高效。window转hash window需要满足的三个条件为
- Unbounded window。
- 没有order by。
- 不包含window agg,如ROW_NUMBER、RANK。
总结
本文从官方的角度逐条解析PolarDB-X在TPC-H列存执行计划的设计要点。这些要点不仅包含了各项优化的原理,还提供了相关的证明与代码实现,希望帮助读者更深入地理解PolarDB-X的列存优化器。 在下一期中,我们将探讨PolarDB-X的行列混合执行计划。
引用
[1] https://www.vldb.org/pvldb/vol13/p1206-dreseler.pdf
[2] https://homepages.cwi.nl/~boncz/snb-challenge/chokepoints-tpctc.pdf
[3] https://zhuanlan.zhihu.com/p/701718682
[4] https://cedardb.com/docs/example_datasets/job/
[6] https://zhuanlan.zhihu.com/p/336084031
[7] https://zhuanlan.zhihu.com/p/580127024
[8] https://www.ic.unicamp.br/~celio/peer2peer/math/mitzenmacher-power-of-two.pdf
[9] https://zhuanlan.zhihu.com/p/470139328
[10] https://vldb.org/pvldb/vol14/p2383-fent.pdf
附录
TPCH执行计划汇总 Q1
Q2
Q3
Q4
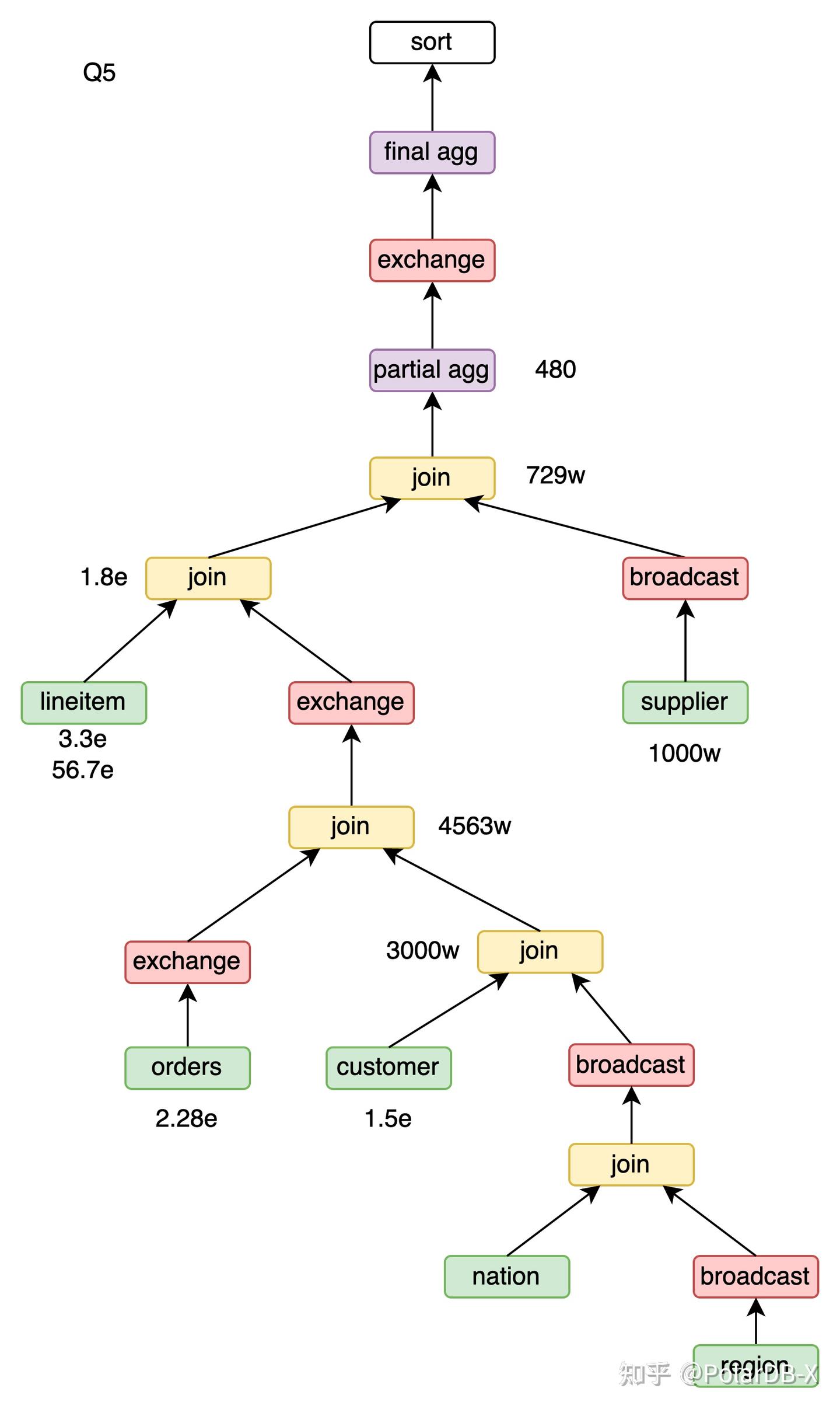
Q5
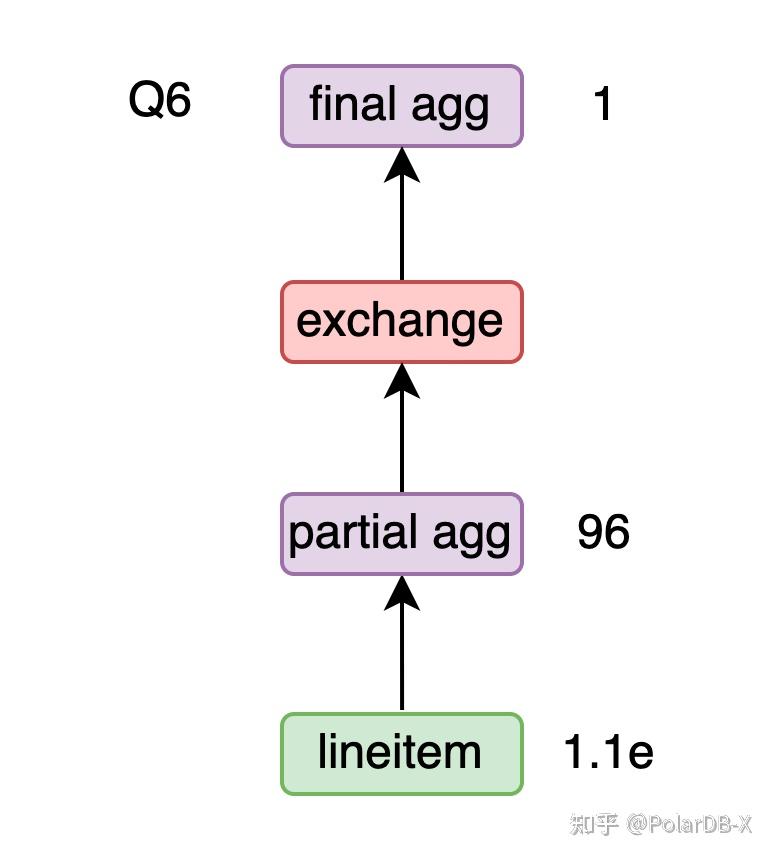
Q6
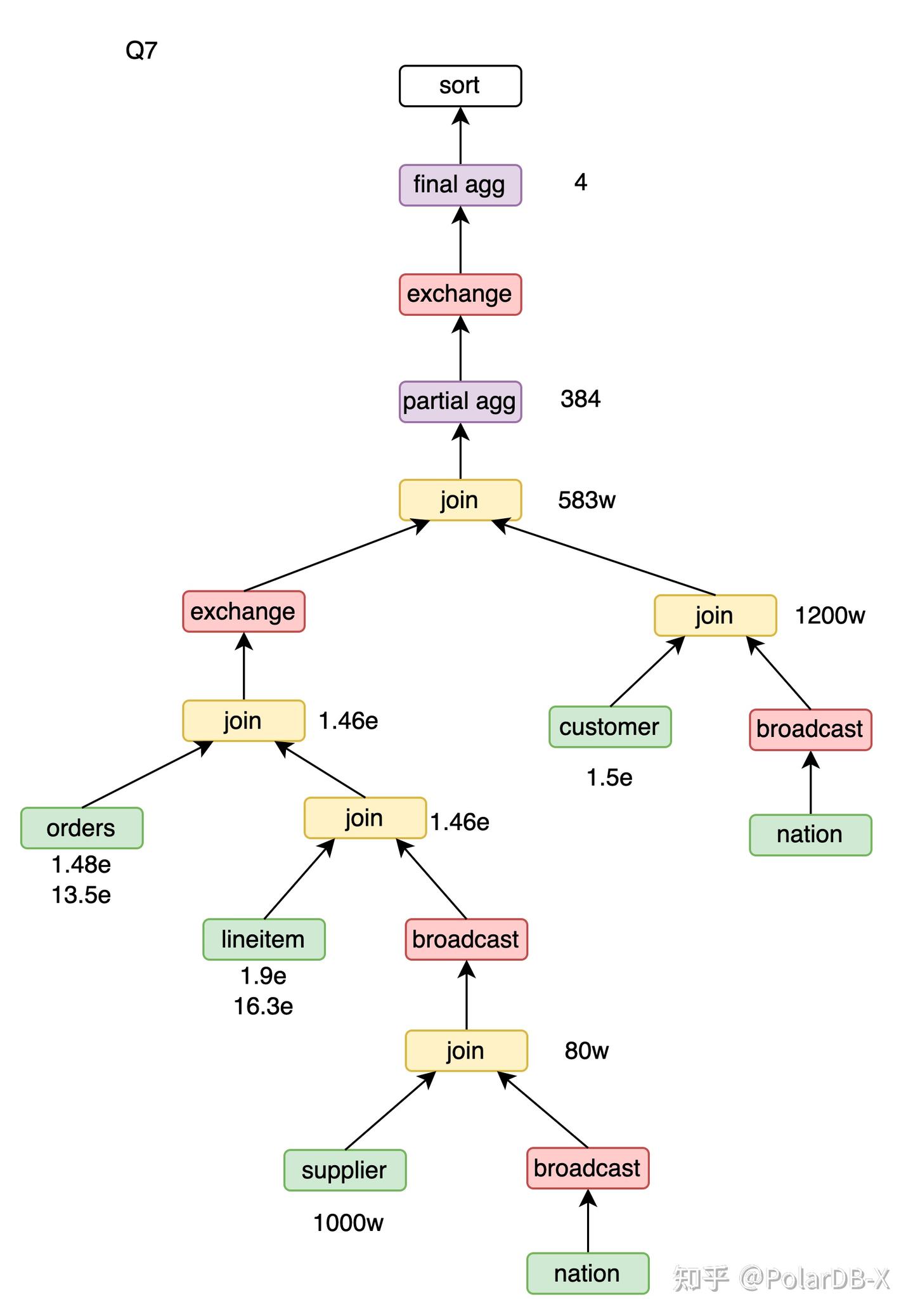
Q7
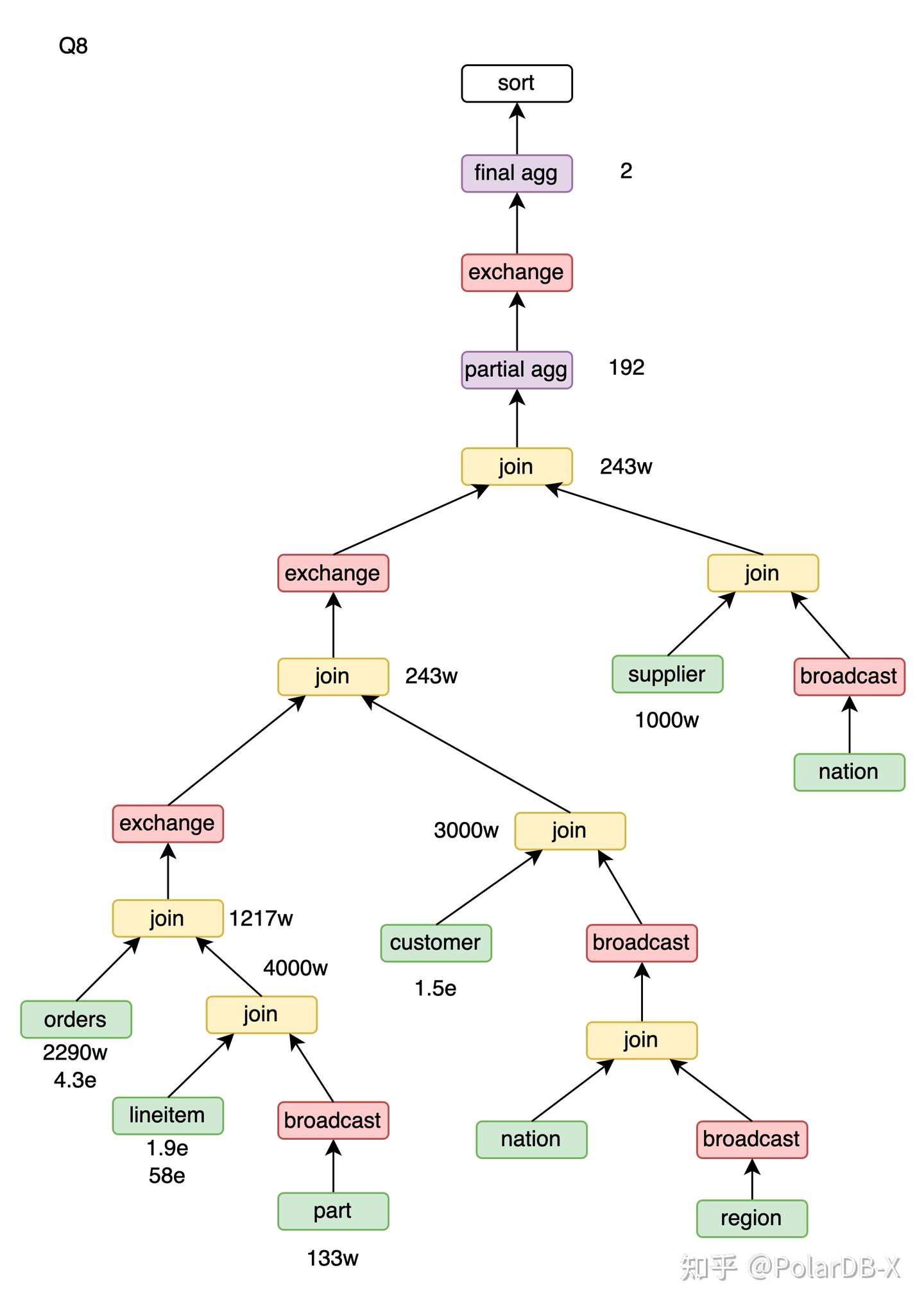
Q8
Q9
Q10
Q11
Q12
Q13
Q14
Q15
Q16
Q17
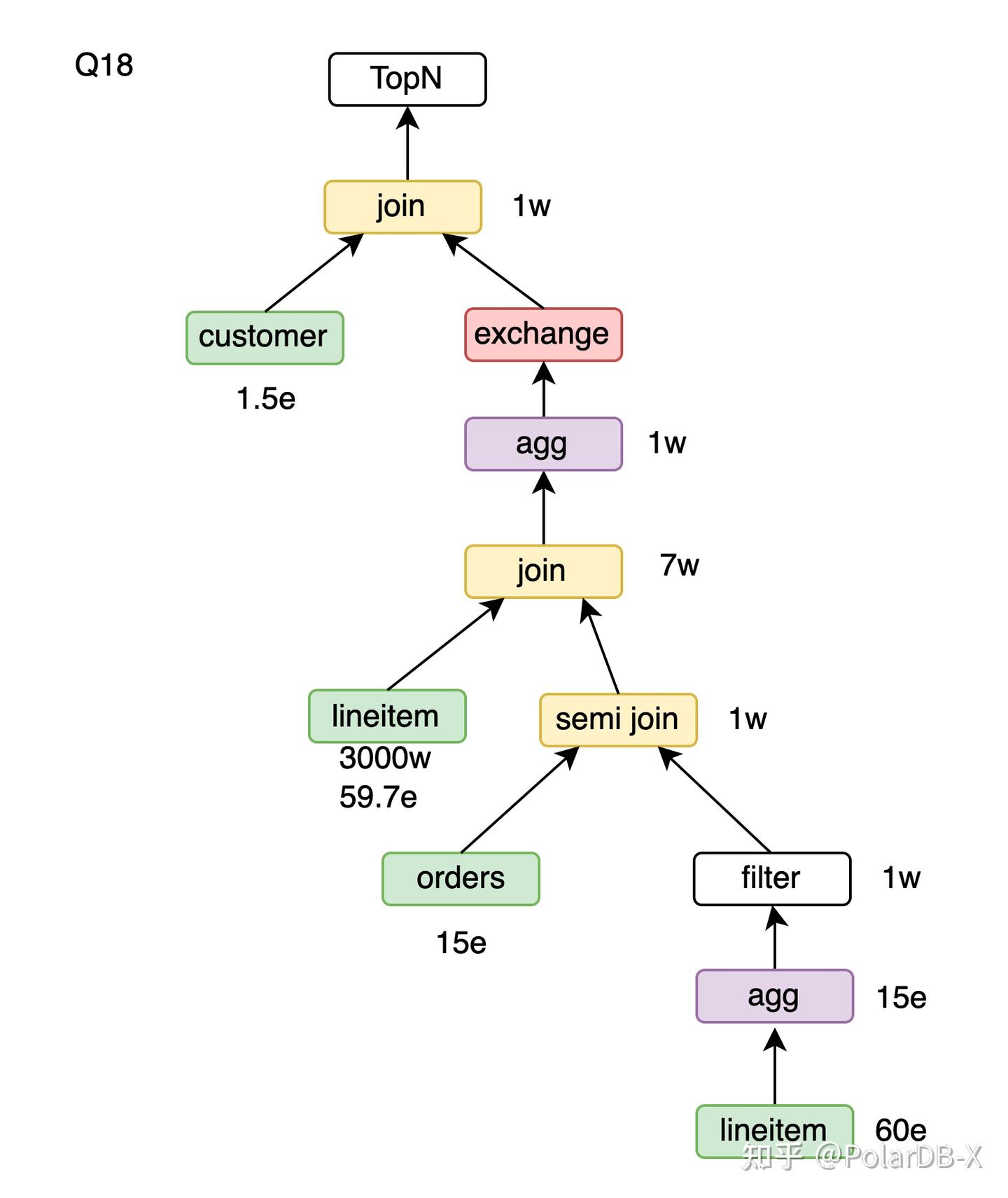
Q18
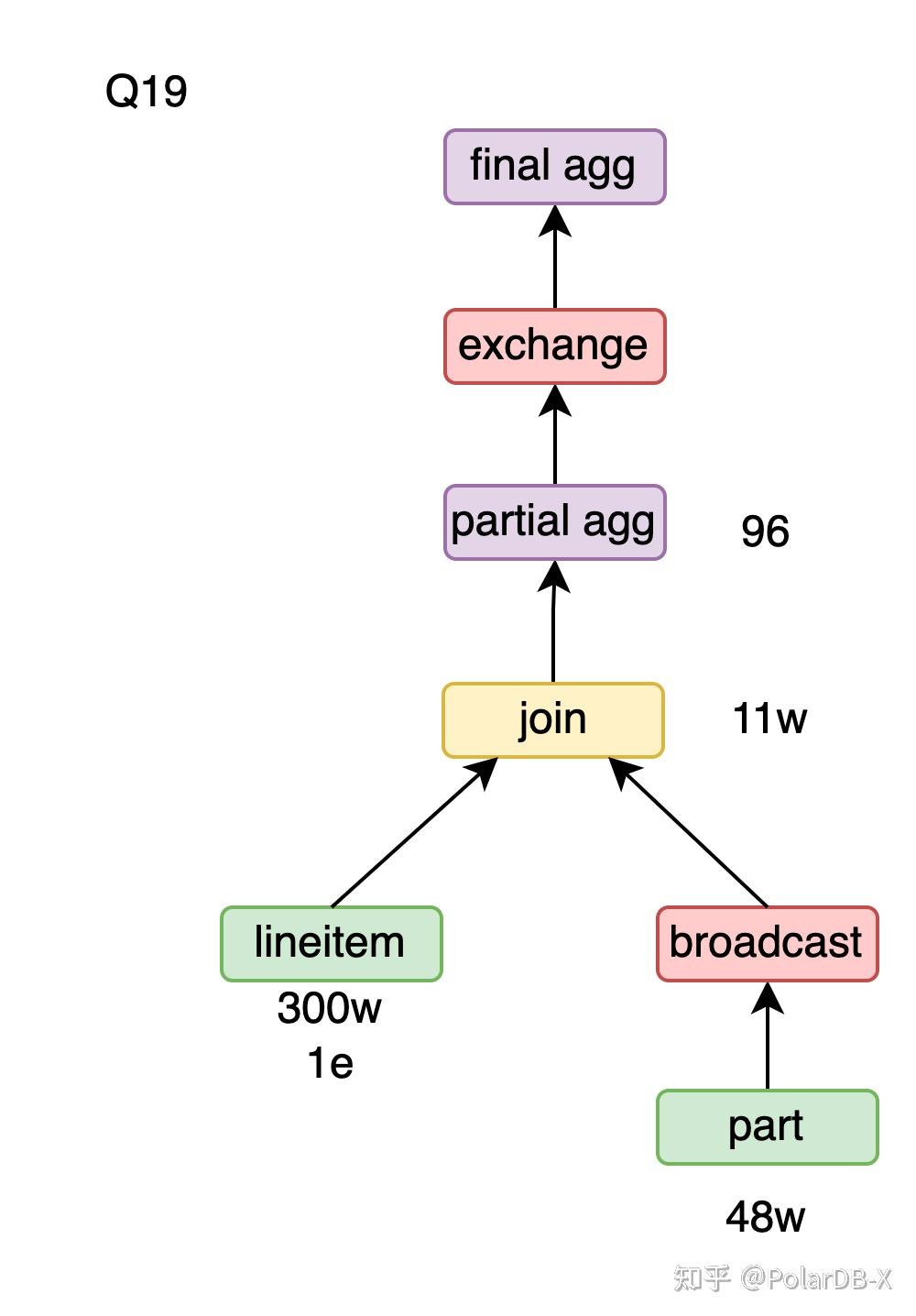
Q19
Q20
Q21
Q22