




在Ai革命的漩涡中,对于那些包括大型语言模型、生成型AI以及语义搜索在内的应用,如何有效处理数据的问题,变得尤为重要。大部分基于大型语言模型的创新应用的基础,都是建立在向量技术之上,向量数据库(Vector Database) 应用而生。其是一种专门用于存储、管理和高效检索向量数据的数据库。它特别适合处理高维向量,常见于机器学习、自然语言处理、推荐系统和语义搜索等领域。
向量数据库的几个核心概念:
什么是向量:
向量是高维度数据(例如 512 维、1024 维),维度可以理解为某些内容的属性和特征,如可以代表文本、图像、音频或用户行为等数据的特征,其用普通数据库存储和检索非常耗时。相似性搜索:
例如:
近似最近邻搜索(Approximate Nearest Neighbor, ANN):在大规模数据中提高搜索速度,牺牲一定精度。
最近邻搜索(Nearest Neighbor Search, NNS):找到与给定向量最近的其他向量。嵌入:
将数据(例如文本、图像)转换成向量表示的过程。
• 例如:使用 OpenAI 的 Text Embedding 模型 将句子转化为 1536 维向量。索引:
向量数据库使用索引结构(如 HNSW, IVF, PQ)来加速搜索过程,如HNSW一种高效的索引算法,广泛用于向量搜索。
向量数据库的工作原理:
在传统数据库中,我们通常查找数据库中与查询完全匹配的行值。而在向量数据库中,我们采用相似性度量来查找与查询最相似的向量。向量数据库结合运用了各种算法来实现近似最近邻(ANN)搜索,包括哈希、量化或基于图的搜索等,以优化搜索过程。
索引:向量数据库利用PQ、LSH或HNSW等算法为向量建立索引。此步骤将向量映射到一种数据结构中,以便加速搜索。
使用场景:
场景 | 描述 | 示例 |
|---|---|---|
语义搜索 | 根据用户输入的含义进行搜索,而非字面匹配。 | 搜索引擎、企业知识库 |
推荐系统 | 基于用户行为特征进行个性化推荐。 | 电商推荐、视频推荐 |
图像识别 | 通过图像特征匹配相似图像。 | 视觉搜索、自动标记 |
自然语言处理 (NLP) | 文本嵌入和语义匹配。 | 聊天机器人、智能客服 |
异常检测 | 识别与正常模式不同的向量。 | 风险监控、金融欺诈检测 |
向量数据库DB-ENGINES流行度:
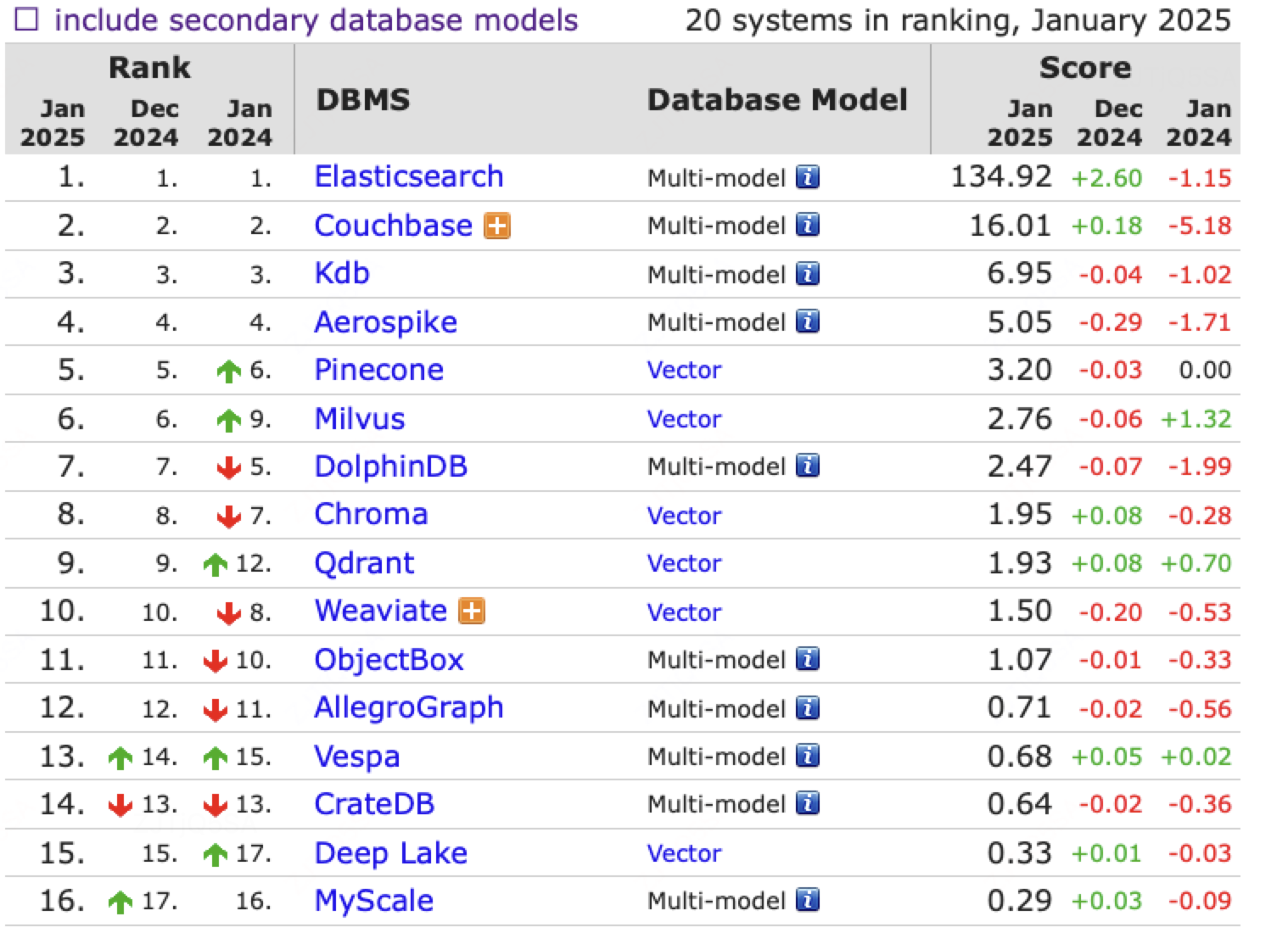
向量数据库分类:
传统的关系型数据库和NoSQL数据库:
其为支持AI功能调整产品形态支持向量数据存储和检索,常见对比
特性 | PostgreSQL (pgvector) | ElasticSearch | Redis (RedisSearch/RedisVector) |
|---|---|---|---|
向量支持 | ✅ 插件支持 (pgvector) | ✅ 原生支持 (kNN, ANN) | ✅ 插件支持 (RedisVector) |
检索算法 | HNSW (ANN) | HNSW (ANN) | FLAT (精确匹配)、HNSW (ANN) |
索引类型 | HNSW | HNSW | HNSW |
性能优化 | ⚠️ 单机限制,性能依赖硬件 | 分布式,高性能 | 内存存储,超快读取性能 |
扩展性 | ⚠️ 受限于单机 | ✅ 极强,分布式架构 | 分布式(Redis Cluster) |
存储类型 | 持久化磁盘存储 | 持久化磁盘存储 | 内存存储 + 持久化支持 |
数据模型 | 关系型数据库 (SQL) | 文档型+搜索引擎 | 键值对存储 |
事务支持 | ✅ 完整 ACID 事务支持 | ⚠️ 较弱,不适合事务场景 | ⚠️ 不支持复杂事务 |
复杂查询 | ✅ 支持 SQL 查询 | ✅ 多模态复合查询 | ⚠️ 查询灵活性较弱 |
实时性 | ⚠️ 中等,依赖存储优化 | ✅ 高,支持实时检索 | ✅ 极高,内存级实时性能 |
存储规模 | ⚠️ 受限于单机 | ✅ 支持海量数据 | ⚠️ 内存受限,需分布式方案支持 |
优势 |
|
|
|
劣势 |
|
|
|
适用场景 |
|
|
|
存储数据举例 | 小规模向量检索 + SQL 分析: 企业内部知识库 文档嵌入向量、元数据 推荐系统(中小规模):小型电商平台推荐 用户偏好向量、产品特征向量 复杂 SQL + 向量查询:金融风控系统 用户行为向量、交易特征向量 科研分析系统:基因数据分析 基因序列向量、特征值向量 | 多模态搜索(文本+向量):搜索引擎 文档全文索引、向量嵌入 大规模向量检索:电商搜索推荐产品描述向量、用户行为向量 日志分析 + 向量搜索:安全日志系统 用户访问向量、异常行为向量 内容推荐系统:媒体内容推荐 用户兴趣向量、内容特征向量 |
|
专用向量数据库:
数据库 | 开发国家 | 开发语言 | 索引算法 | 存储引擎 | 扩展性 | 事务支持 | 实时性 | 典型场景 |
Milvus | 中国 | Go、C++ | HNSW、IVF、PQ、DISKANN | RocksDB | ✅ 分布式 | ⚠️ 不完全支持 | ✅ 高实时性 | 推荐系统、图像检索 |
Pinecone | 美国 | Python | HNSW、IVF | 云存储 | ✅ 云原生分布式 | ⚠️ 不支持 | ✅ 高实时性 | NLP、搜索引擎 |
Qdrant | 德国 | Rust | HNSW | RocksDB | ✅ 分布式 | ⚠️ 基本支持 | ✅ 高实时性 | 文本搜索、AI应用 |
Weaviate | 荷兰 | Go | HNSW、IVF、FLAT | RocksDB、云存储 | ✅ 分布式 | ⚠️ 基本支持 | ✅ 高实时性 | 多模态搜索、AI |
Vespa | 挪威 | Java、C++ | HNSW、ANN | 内存+磁盘 | ✅ 分布式 | ✅ 完整事务 | ✅ 高实时性 | 企业搜索、推荐系统 |
FAISS | 美国 | C++、Python | HNSW、IVF、PQ、OPQ | 内存 | ⚠️ 单机 | ⚠️ 不支持 | ✅ 高实时性 | 离线搜索、批量查询 |
Elasticsearch8的向量存储和mivus纵向对比:
对比维度 | Milvus | Elasticsearch | PostgreSQL |
|---|---|---|---|
设计目的 | 专用向量数据库,专为大规模向量数据存储和高效检索设计 | 面向文档存储和搜索,向量检索作为附加功能 | 关系型数据库,通过扩展(如 pgvector)支持向量存储 |
存储引擎 | RocksDB(支持内存+磁盘存储) | Lucene(面向文档存储) | 多种存储引擎,常见为 pgvector 扩展 |
索引算法 | HNSW、IVF、PQ、DISKANN | HNSW(仅限 dense_vector 字段) | HNSW(通过 pgvector 提供) |
向量检索性能 | ✅ 高性能,专为向量检索优化,支持 PB 级数据 | ⚠️ 中等性能,适合小规模场景 | ⚠️ 较慢,适合中小规模场景 |
扩展性 | 分布式存储,水平扩展能力强 | 分布式架构,支持横向扩展 | 单机为主,分布式需要第三方工具 |
实时性 | 高实时性 | 较弱的实时性(受 Lucene 索引影响) | 延迟较高(事务和一致性开销大) |
数据类型 | 向量、嵌入数据 | ✅文档、JSON、向量 | 结构化数据、向量 |
复杂查询 | ⚠️ 基础支持,偏向向量检索 | ✅ 支持复杂的多字段查询 | ✅ 支持复杂 SQL 查询 |
建议存储容量 | 亿级以上 | 百万到千万级 | 十万到百万级 |
使用场景 | 大规模向量搜索、推荐系统、AI 检索 | 混合搜索(文本 + 向量)、企业搜索引擎 | 结构化数据与向量检索结合 |
