




Apache HugeGraph (incubating) 第四个 Apache Release 版本 1.5.0 已正式发布,欢迎大家下载使用(可点击文末“阅读原文”跳转官网下载),也提前祝大家新年快乐🎇
这是 HugeGraph 加入 Apache 基金会进行孵化以来发布的第四个正式版本。本版本新增了大量功能并进行了多项优化,尤其是针对自控分布式版本新后端 HStore (Raft + RocksDB) 的实现支持。1.5.0 版本相较于 1.3.0 版本,在主仓库新增了 300+ 个 commits,包含 1500+ 个文件约 20w 行的代码变更提交。
自 HugeGraph 1.5.0 版本开始,HugeGraph 相关组件仅支持在 Java 11 环境下编译与运行,并计划在后续版本逐步升级至 Java 17 和 Java 21,从而充分利用更高版本 Java 的性能和新特性。

01
核心功能 & 变动
NEW FEATURES
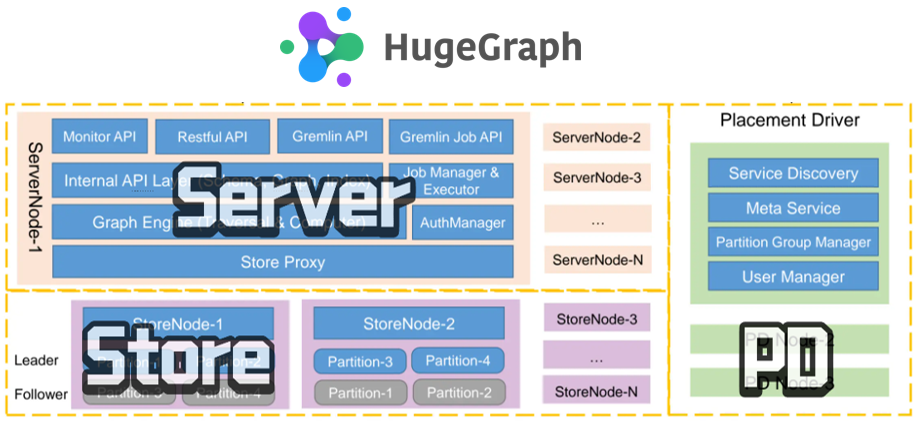
Server 自控分布式版本 (PD, Store)
HugeGraph 1.5.0 版本在原有架构基础上新增了自控分布式后端 HStore,采用 Raft + RocksDB 的方案实现多副本存储与一致性管理。通过划分数据分区、自动平衡副本与 Leader 分配等机制,自控分布式版本能够在海量数据场景下实现更高的可扩展性与高可用性。
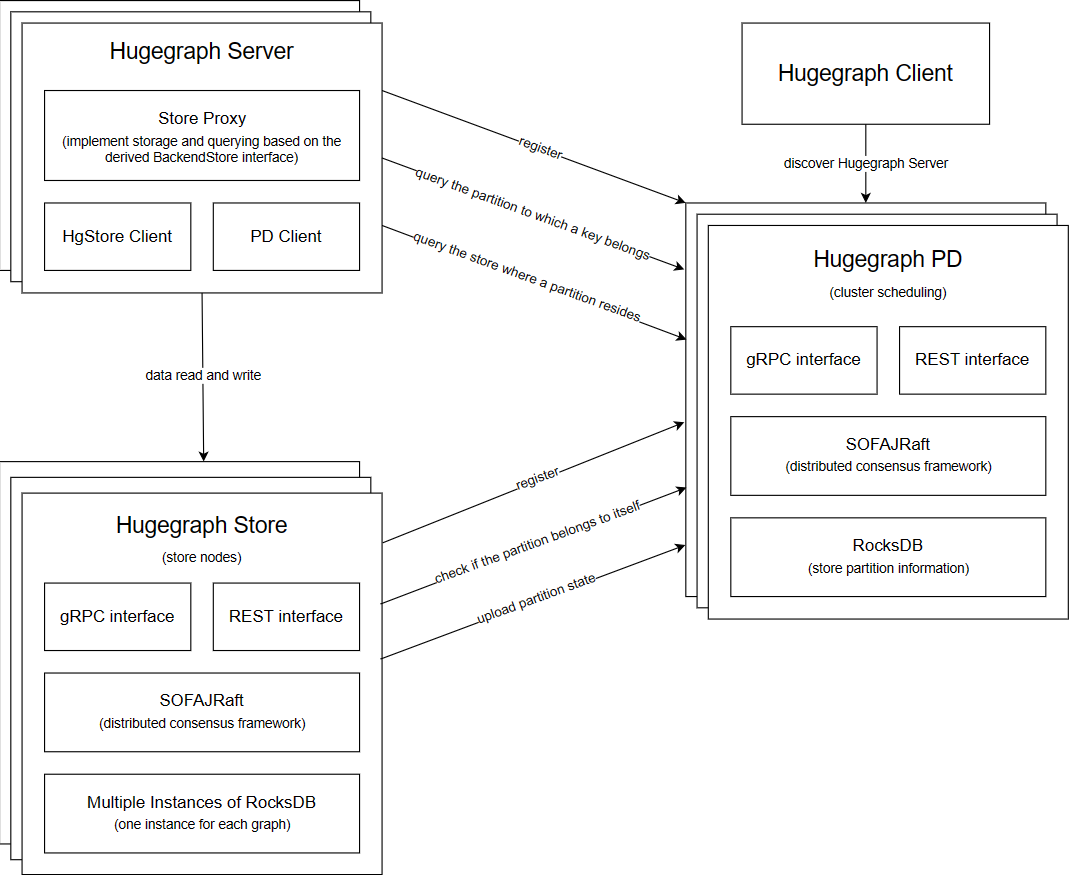
自控分布式后端 HStore 依赖新增的两个组件 PD 和 Store:
PD (Placement Driver) 负责管理集群的核心元数据信息,包括分区与副本的调度、Leader 分配、节点注册与发现等。
Store (Store Node) 是新的内置存储节点,用于实际存储点、边和索引数据。
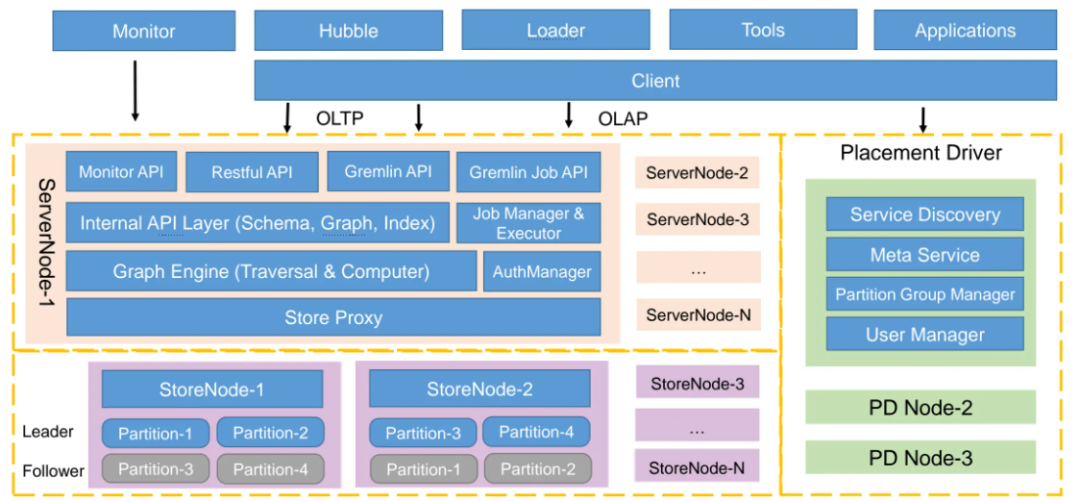
在分布式版本下,Graph 被切分成多个 Partition,以实现水平扩展;每个 Partition 通过多个副本(Shard)来确保高可用,这些副本分别保存在不同的 Store 节点上,并使用 Raft 进行一致性管理;与此同时,Store 节点承担存储和部分计算的职责,每个图对应一个单独的 RocksDB 实例,用于存储点、边和索引数据;PD 作为元数据中心,负责追踪所有 Partition 和 Shard 的分配与迁移,并根据负载状况或故障情况执行自动调度,从而实现更优的资源利用率与高可用性。完整的 HugeGraph 分布式架构如下图所示:
此外,HugeGraph 在分布式场景中为了提升查询效率与可扩展性,引入了计算下推这一机制:在 Store 节点上直接执行部分计算 (如 Aggregate/LimitAndOffset 等) 后,再将精简后的结果返回给 Server,使得 Server 无需处理过多的原始数据加载与过滤;这样的架构不仅充分利用了 Store 节点的存储与处理能力,还能够减少网络传输开销,从而在大规模图数据场景下实现更高效的计算与查询。
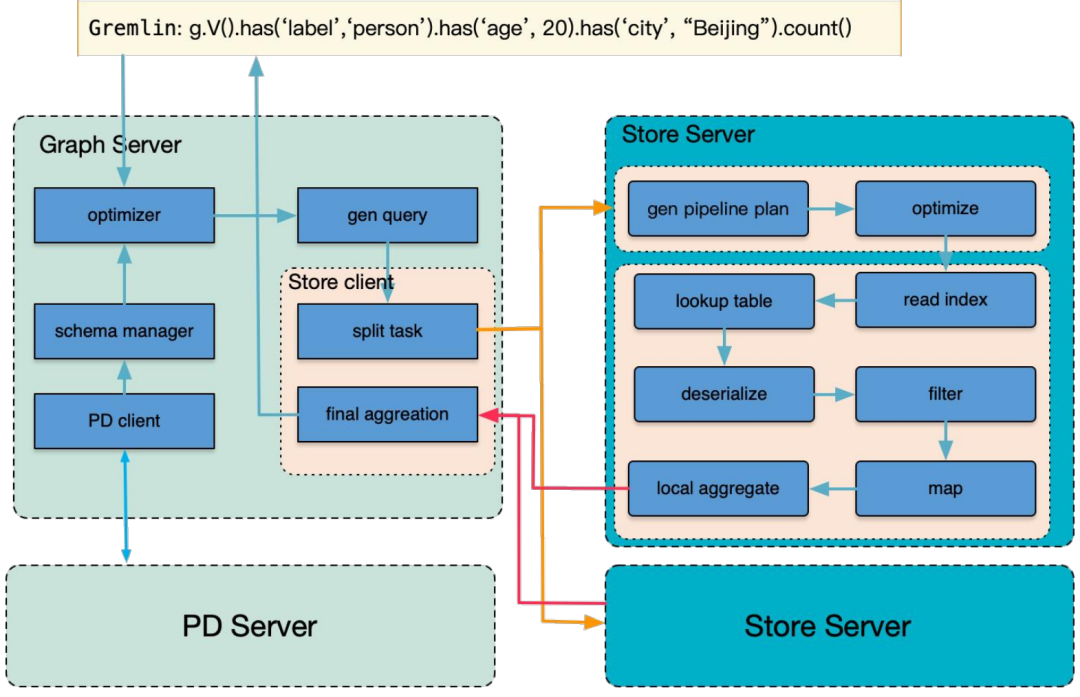
至此,HugeGraph 自控分布式版本的整体框架及其关键组件已经介绍完毕。借助这种自控分布式方案,HugeGraph 在千亿级别的数据场景下,依然能保持高效的读写性能和灵活的运维能力。
Server 父子边功能 (BREAKING CHANGE)
HugeGraph 1.5.0 版本中新增并完善了父子边(parent-child edge)的功能,用于给 EdgeLabel 设置从属类型。以银行转账场景为例,转账操作可以有“人-人转账”、“人-公司转账”等多个子类型,并统一归到同一个父类型“转账”下,这样既能满足区分多种转账场景的需求,也能通过一次查询获取所有转账相关的边。
在底层边数据结构方面,HugeGraph 引入了父类型 EdgeLabel 字段,用于标记边所从属的父类型,使其在检索时能够更有效地利用前缀扫描来定位不同类型的子边。
这是一次涉及底层存储格式改变的重大 BREAKING CHANGE,除了支持父子边的功能外,在编码层面也进一步放宽了相关实体的长度限制,以满足更大规模和更复杂场景下的存储需求。这些修改具体包括:将 Vertex ID 的长度上限扩展到 16KB、Edge ID 的长度上限扩展到 64KB,以及 property 属性的长度上限扩展到 10MB,在使用和升级时需要格外关注并做好兼容性评估和数据迁移准备。
Server 集成测试框架 (Mini Cluster)
HugeGraph 1.5.0 版本在测试方面引入了新的 Server 集成测试框架,旨在搭建一个可模拟真实环境的微集群进行整体稳定性测试。过去的测试主要聚焦于独立功能的单元测试,缺乏对系统整体性和高负载下表现的验证,因此通过借鉴 MiniCluster 等方案,可以在同一台机器上运行多个服务节点,从而更接近生产环境并支持后续的压力及混沌测试需求。
该集成测试框架的核心思路是先通过 Env 和 Config 等组件来封装 PD、Store 与 Server 的基础运行环境,并根据需要搭建单节点或多节点集群;随后在此环境中使用 restful 接口进行交互和测试。该框架不仅可以灵活地配置节点和集群参数,还能在相对有限的硬件资源条件下模拟真实场景,从而大幅提升 HugeGraph 在稳定性和兼容性方面的验证效率。
Server 其余功能和性能优化
Commons 模块合并到 Server 主仓库,简化了依赖管理。
初步兼容 GraphSpace API,以支持未来图空间多租户。
默认使用 G1 垃圾回收器。
增加 JVM 堆内存监控机制,避免高深度查询导致 Server 出现 OOM 的情况。
修复并处理了一系列安全性(SEC)问题,提升了系统稳定性。
图计算
新增单源最短路径算法 (Single Source Shortest Path),方便在大规模图数据中获取最短路径。
支持对输出结果进行过滤 (output filter),可按需筛选计算结果,提升使用灵活度。
优化随机游走 (random walk) 机制,可更好地控制顶点的活跃状态。
PS: 下一个版本我们将发布全新/独立的 Go 内存图计算架构, 功能已经就绪 (欢迎提前在最新 PR/代码试用)
图工具链
适配对父子边的支持,便于在更复杂的层次化关系中进行数据建模。
Hubble(前端界面)支持英文界面及编译脚本,方便多语言环境下的可视化操作。
优化依赖管理和代码风格验证。
PS: 下一个版本我们将发布全新的 Hubble V2.0, 欢迎提前在最新 PR/代码试用
HugeGraph with AI
新增图学习(Graph Learning)的常见支持,包含基于 DGL 的节点 Embedding、节点分类及多种图分类等 20+ 算法实现。
Python-Client 大幅更新同步, 到达生产可用, 并可无缝兼容新旧图空间版本
新增多源 LLM API,支持 OpenAI 兼容的各类国产 LLM,支持 Ollama/Xinference 等本地模型服务灵活接入
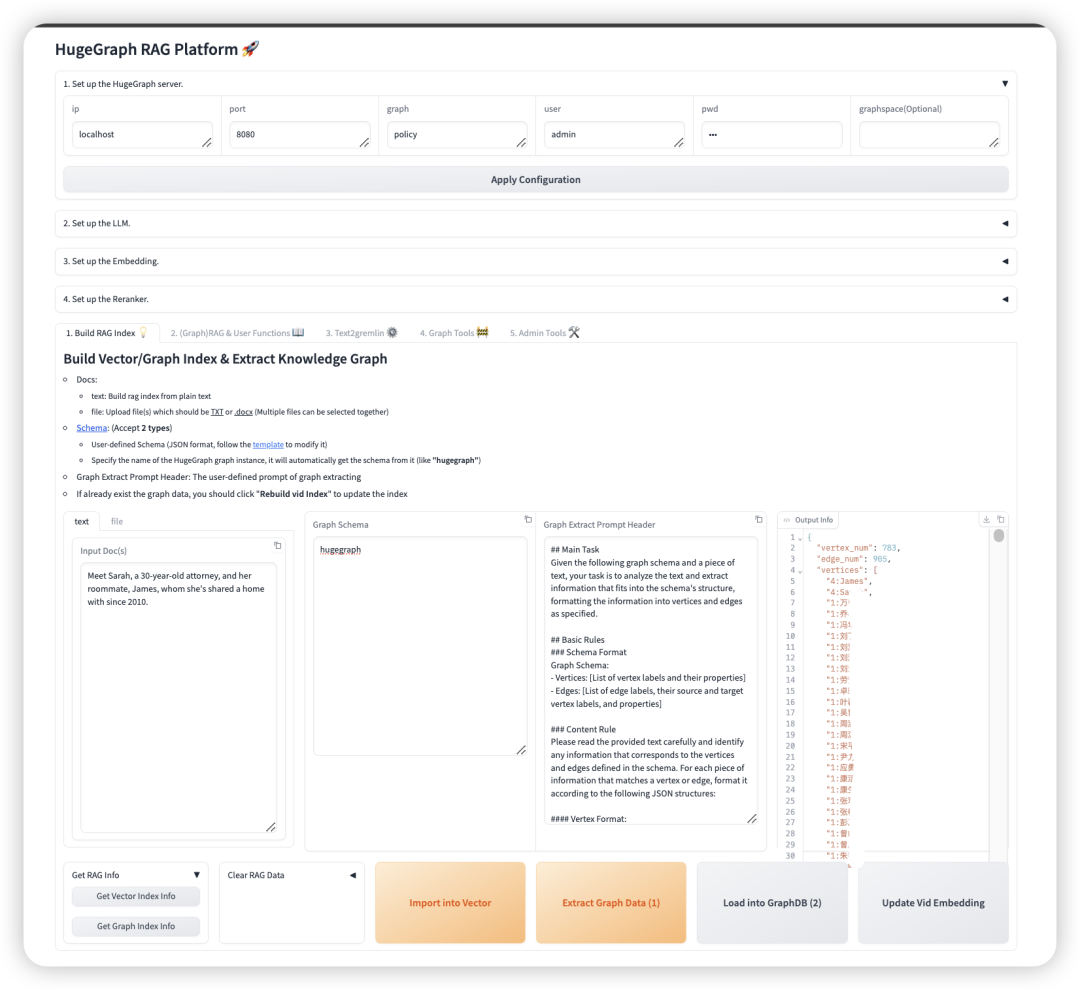
新增 Graph RAG 中多任务模型拆分, 大 + 小 (本地 + 在线) 模型自由组合
新增 RESTfu-API 接口, 可提供精准的 graph 召回信息, 在已有 vector 的业务场景结合更方便
新增 Text2GQL 模块, 可独立测试, 也默认整合在查询流程可选开启, 并且支持模板库优化生成效果
新增 Rerank 模块, 并支持近邻优先/自定义优先等多种排序策略
提供 RAG 回测和批量测试功能 + 数据自动备份/等用户实用功能
.....大量细节优化等, 欢迎试用反馈 一同参与共建
02
感谢每位贡献者
THANK YOU ALL
社区的发展源自于诸多用户的积极反馈,以及仰赖于每一位开发者的无私贡献,感谢以下 Contributors 对此版本做出的巨大贡献(字母序):AnkiPu, ChenZiHong-Gavin, FrostyHec, HJ-Young, JackyYangPassion, MingzhenHan, MrJs133, Pengzna, Thespica, VGalaxies, ZeeJJ123, afterimagex, coderzc, dependabot, diaohancai, diya-he, edw4rdyao, emmanuel-ferdman, haohao0103, imbajin, jasinliu, liuxiaocs7, msgui, returnToInnocence, rubia0022, sheli00, shirleyStorage, simon824, vichayturen, zyxxoo
03
版本变更详情
RELEASE NOTE
版本的更多详细变更内容见:
https://hugegraph.apache.org/docs/changelog/hugegraph-1.5.0-release-notes/
04
关于HugeGraph
ABOUT HUGEGRAPH
Apache HugeGraph (Incubating) 是国内首个开源的图数据库,提供了一站式的千亿级大规模图数据的存储、在线查询、离线分析平台。HugeGraph 于 2016 年项目启动,并于 2018 年开源,2022 年 1 月正式通过世界顶级开源组织 Apache 软件基金会的投票决议,HugeGraph 以全票通过的优秀表现正式成为全球首个加入 Apache 孵化的图数据库项目,同年 5 月正式入驻 Apache 开启孵化,促使国产图数据库走向世界,在提升图数据库产品开发效率、降低产业应用成本的同时,在人才、生态建设产生深远的影响,让更多开发者因此受益。
HugeGraph 不仅是国内第一个开源的图数据库产品,也是唯一捐赠给 ASF (Apache 基金会) 的图系统。它实现了 Apache TinkerPop3 框架兼容 "Gremlin + Cypher" 查询语言, 具备完善的工具链组件,助力用户轻松构建基于图数据库之上的应用和产品。HugeGraph 支持百亿以上的顶点和边快速导入,并提供毫秒级的关联关系查询能力(OLTP), 并可与 Hadoop、Spark 等大数据平台集成以进行数据集成,提供自研的图计算系统,形成整合的一站式图服务。此外,HugeGraph 也正探索与 AI 技术融合的路径,例如在图数据库中引入大语言模型与机器学习算法,以进一步增强知识推理与分析能力,解决图数据库应用场景中关于知识图谱构建、知识问答、知识管理等方面的难题。图数据库能够支撑新型应用场景的关联分析业务,根据 Gartner 预测,到 2025 年图技术将应用于 80% 的数据和分析创新,而图技术是图数据库的核心技术,我们将携手更多 fellows 不断推动图数据库的规模持续增长。
05
加入我们
WE NEED YOU
📔项目地址:
https://github.com/apache/incubator-hugegraph
📬提交问题和建议:
https://github.com/apache/incubator-hugegraph/issues
🍀贡献代码:
https://github.com/apache/incubator-hugegraph/pulls
📧订阅社区开发邮件列表:dev@hugegraph.apache.org
请点击文末“阅读原文”访问下载页面,扫描图中二维码可关注公众号
Apache HugeGraph
长按识别二维码关注我们
易用、高效、通用的
国产开源图数据库

Apache HugeGraph 官方公众号
