




数据库管理288期 2025-01-28
数据库管理-第288期 杀!会话(20250128)
作者:胖头鱼的鱼缸(尹海文) Oracle ACE Pro: Database PostgreSQL ACE Partner 10年数据库行业经验 拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证 墨天轮MVP,ITPUB认证专家 圈内拥有“总监”称号,非著名社恐(社交恐怖分子) 公众号:胖头鱼的鱼缸 CSDN:胖头鱼的鱼缸(尹海文) 墨天轮:胖头鱼的鱼缸 ITPUB:yhw1809。 除授权转载并标明出处外,均为“非法”抄袭

在开篇祝大家新春快乐,蛇年大吉。
总监还在客户现场苦逼的值班,按照惯例会到半夜,回家都是蛇年了。在现场闲来无事,复盘一下前两天处理的一个和会话相关的故障,也顺便回顾一下处理异常会话的一些方法。
1 故障背景
中午开始,某个PDB对应的业务反馈一直在报错ORA-04036: PGA memory used by the instance exceeds PGA_AGGREGATE_LIMIT,当时业务方说是有一些计算,需要增大PGA,检查PDB配置,PGA_AGGREGATE_LIMIT为8G,随即扩大PGA上限值至16G:
alter system set pga_aggregate_limit=16g;
这时两个实例的PGA总限制就从8G×2来到了16G×2,暂时相安无事。但是下午快下班那会儿,业务方反馈又开始持续报错ORA-04036且影响部分业务了,随即继续扩大PGA上线至24G,因为涉及大量计算操作,还给临时表空间扩展了3个数据文件:
alter system set pga_aggregate_limit=24g;
alter tablespace temp add tempfile size 500m autoextend on next 500m maxsize unlimited;
alter tablespace temp add tempfile size 500m autoextend on next 500m maxsize unlimited;
alter tablespace temp add tempfile size 500m autoextend on next 500m maxsize unlimited;
但是问题依然没有解决。
2 故障排查
首先检查PDB的PGA与SGA使用情况:
SELECT r.inst_id,r.CON_ID, p.NAME, r.SGA_BYTES/1024/1024/1024 SGA, r.PGA_BYTES/1024/1024/1024 PGA, r.BUFFER_CACHE_BYTES/1024/1024/1024 CACHE,r.SHARED_POOL_BYTES/1024/1024/1024 SHARED_POOL FROM GV$RSRCPDBMETRIC r, GV$CONTAINERS p WHERE r.CON_ID = p.CON_ID and r.INST_ID=p.INST_ID order by inst_id;

发现该PDB的PGA使用已接近上限。接下来检查数据库会话情况:
select machine,status,count(*) from gv$session group by machine,status order by 1;
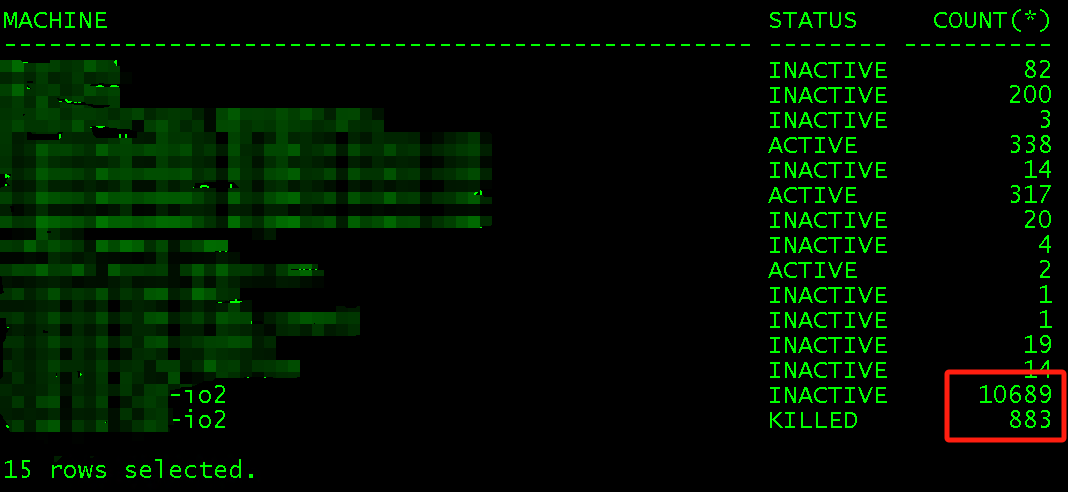
这时发现来自于某台服务器有大量状态为INACTIVE的会话,部分会话在DBA处理过程中成为了KILLED状态并处于不断减少中,但是INACTIVE的会话数量没有下降还在增加。
数据库配置的processes为9000,session为13536,虽未超过两个实例的上限,但是其占用PGA总量超过了PGA的上限值。
3 解决问题
经过业务方排查,是一个新上线的监控脚本的会话退出机制有问题,导致session没有正常中断,保留在了数据库中,这种情况需要通过数据库方面处理,于是写了条SQL来批量输出kill session的语句:
--目标:alter system kill session 'sid,serial#[,@inst_id]'; select 'alter system kill session '''||sid||','||serial#||',@'||inst_id||''';' from gv$session where machine='xxxxxx-io2' and status='INACTIVE';
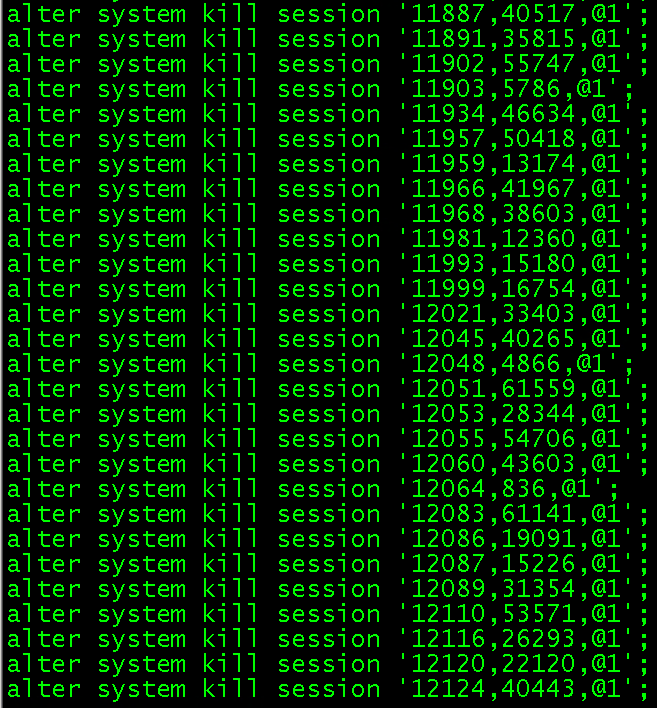
这时可以手动复制执行,也可以通过spool到sql脚本中执行,但是不建议一次性执行太多,会出现执行效率慢的现象。
通过一段时间的kill session操作后,相关会话都进入了KILLED状态,并逐渐消除。
4 万一
首先回顾下一个概念,会话连接到数据库后会创建server process,kill session的操作除了清理数据库内的相关内容外,就是干掉这些server process。大批量kill session后,对应的server process可能出现延迟清理的情况,也就是会在数据库内呈现KILLED的状态,在一些情况下,这些进程会一直处于KILLED的状态,操作系统的相关占用也不会释放,这时候就需要在操作系统中kill相关的进程了:
select 'kill -9 '||p.spid as kill_command from v$process p,v$session s where p.addr=s.paddr and machine='xxxxxx' and status='KILLED';

在对应实例执行并在对应服务器操作系统侧执行输出的kill命令即可。一般来说,不建议直接通过操作系统层面kill进程的方式kill会话,特别是注意一些重要的进程,比如PMON、SMON等,会导致实例异常,一般建议是在session的匹配条件中过滤相关内容,并现在数据库中kill session后,确定异常再去尝试操作系统重kill进程。
当然在一些极端情况下,操作系统侧也无法kill掉对应进程,这种情况下就需要进一步处理或者使用重启大法了。
总结
蛇年前最后一卷,杀会话!
老规矩,新春快乐,蛇年大吉。
