




“ 向量数据库是RAG技术的重要底座之一 ”
关于RAG和向量数据库的基础知识这里就不再做介绍了,不懂的可以翻看之前的文章。
今天的主要目的是使用milvus向量数据库来实现RAG检索增强,后面会附上代码。
使用milvus实现RAG
RAG的核心在于检索,而与传统字符匹配和分词检索方式不同的是RAG主要是基于语义检索的方式,也就是向量检索。而一个好的向量数据库就成为RAG技术环节中必不可少的一环。
备注:RAG并不是只支持向量检索,也可以使用传统的检索方式,主要根据不同的应用场景选择最合适的方式;RAG的核心是准确,高效的检索到有效数据,也就是说RAG重视的是结果,而不是过程。 DFires,公众号:AI探索时代RAG与本地知识库,向量数据库,以及知识图谱的联系与区别
milvus是我国企业自主开发的一款向量数据库,根据其官方介绍,milvus既可以方便本地开发测试,也可以大规模集群部署支持上百亿的向量检索需求。
而且,milvus同时还支持多种检索方式和算法:

并且集成多种语言的SDK:

当然,今天的主要目的不是为了给milvus产品打广告,而是使用milvus实现RAG——检索增强问答系统。
https://milvus.io/docs/zh
milvus官方文档
安装milvus
milvus有多种版本,每种版本支持的场景不太一样,但安装方式都非常简单。
轻量级可以直接通过pip进行安装,并直接嵌入到python代码中:
# 本地python sdk 使用pip install mivlus
而单机版和集群版都是通过docker 进行安装,官方提供了详细的安装命令:
# 单机安装 linux系统 需要梯子curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.shbash standalone_embed.sh start
| 版本 | 说明 | 使用场景 | 数据量 |
| milvus Lite | 轻量级版本 | 常用于本地开发使用 | 百万到千万级向量数据 |
| milvus Standalone | 单机版 | 常用于小规模用户使用 | 上亿级向量数据 |
| milvus Distributed | 集群版 | 常用于大规模业务场景 | 百亿级向量数据 |
为了方便管理,milvus提供了一个可视化的客户端工具——attu,只需要一个命令就可以安装:
# attu 安装命令 这个{milvus server IP} 要换成你自己的服务器地址或本地地址docker run -p 8000:3000 -e MILVUS_URL={milvus server IP}:19530 zilliz/attu:v2.4项目地址: https://github.com/zilliztech/attu
这里有一个坑, zilliz/attu:v2.4 attu的镜像有些平台会拉不下来,大家可以换个思路使用自己的电脑或者能够拉下attu镜像的服务器,拉取之后把使用 save命令把镜像保存下来,然后再部署到你的电脑或服务器上。
当然,attu客户端工具并不是必须的,只是方便管理milvus ,也可以不使用。
如下是attu的管理页面:
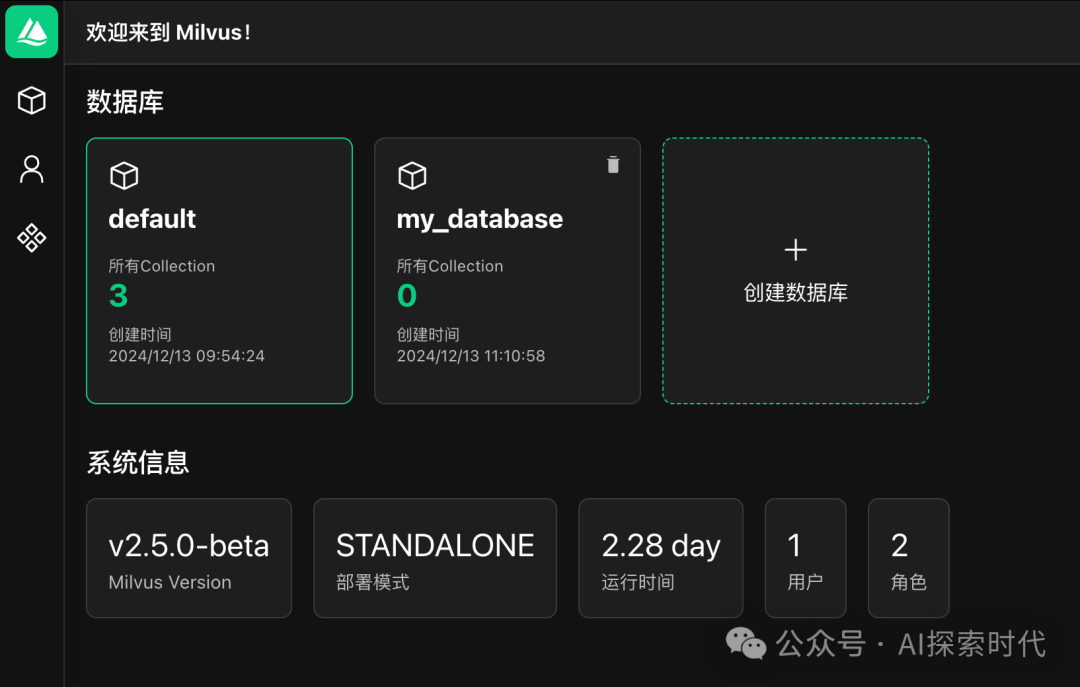
用户本地或在服务上安装好milvus向量数据库之后,就可以直接使用了。
在python 中连接milvus数据库的方式有两种,然后用户所有与milvus数据库的操作都可以基于milvus_client客户端对象实现。
# milvus 客户端有两种连接方式 一种是本地开发测试使用 一种是独立部署# 独立部署方式# milvus_client = MilvusClient(# uri="你的milvus ip:19530",# token="root:milvus" # 默认用户名和密码# )# 本地方式 会在本地创建一个milvus 数据库milvus_client = MilvusClient("milvus_demo.db")
其次,milvus也像传统的关系型数据库一样,拥有数据库的概念;不同的数据可以放到不同的数据库中,默认数据库就是default,如果你没有声明或创建数据库,那么你的数据默认都在default数据库中。
但milvus的主要操作是通过Collections来实现的;Collections就类似于传统数据库中的表结构。
如下图所示:
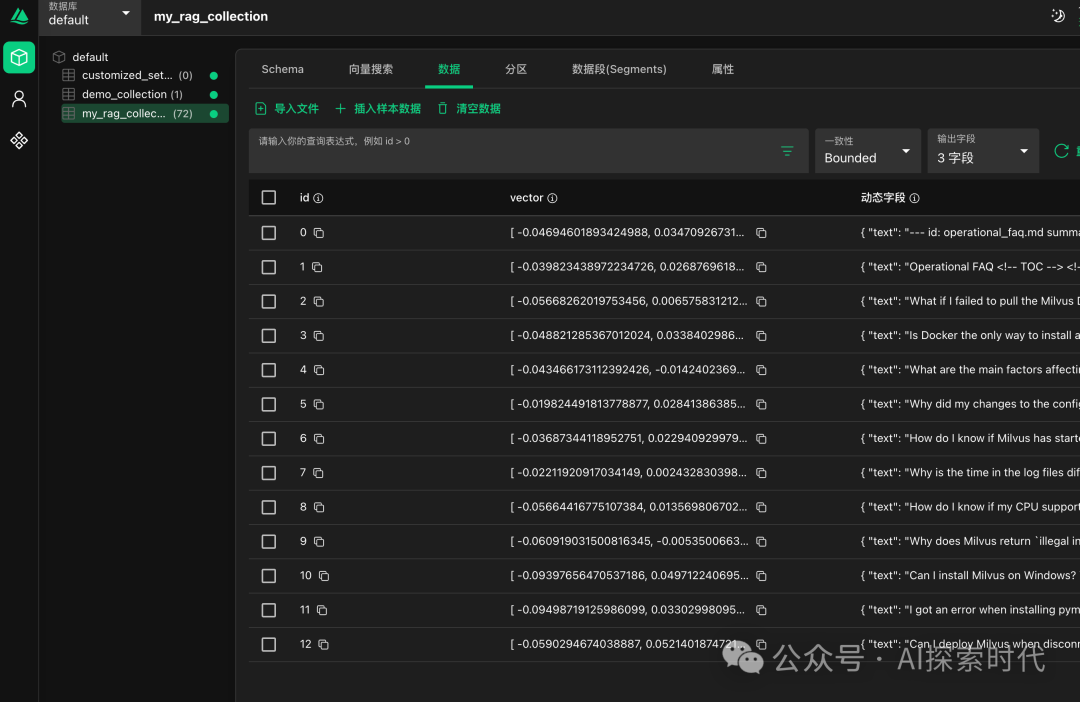
在学会milvus数据库的基本使用之后,就可以通过嵌入模型把数据导入到milvus数据库的collection中;然后通过调用大模型实现RAG问答。
详细实现可以查看官方文档:
https://milvus.io/docs/zh/build-rag-with-milvus.md
完整代码如下所示,这里使用的是阿里云的通义千问模型,嵌入模型使用的也是阿里云的嵌入模型;当然milvus官方也提供了一些嵌入模型,用户也可以根据自己的喜好选择一些第三方的模型。
需要安装的python 包,当然作者这里只是记录了一部分包,如果代码执行出错提示缺包,用户自行下载即可。
!pip install jq!pip install pymilvus[model]!pip install pymilvus!pip install tqdm!pip install openai# python 环境是3.9
这里的代码是完整的可执行代码,只需要把文件路径换成你本地下载的文件即可;还有就是大模型客户端可以选择你自己的模型和key。
这里的测试文件使用的是milvus官方提供的问题文档,下载地址:
https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
from glob import globfrom openai import OpenAIfrom pymilvus import MilvusClientfrom tqdm import tqdmimport jsontext_lines = []# 路径 milvus_docs/en/faq/*.mdfor file_path in glob("换成你的文件路径", recursive=True):with open(file_path, "r") as file:file_text = file.read()text_lines += file_text.split("# ")print("text_lines: ", text_lines)# 这里使用的是openai的工具包 可以连接openai, 通义千问, 等多种兼容openai格式的大模型服务商 这里使用的是阿里的通义千问模型openai_client = OpenAI(api_key="换成你的key",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")# 嵌入模型def emb_text(text):return (openai_client.embeddings.create(input=text, model="text-embedding-v3").data[0].embedding)test_embedding = emb_text("This is a test")embedding_dim = len(test_embedding)print(embedding_dim)print(test_embedding[:10])# milvus 客户端有两种连接方式 一种是本地开发测试使用 一种是独立部署# 独立部署方式# milvus_client = MilvusClient(# uri="你的milvus ip:19530",# token="root:milvus"# )# 本地方式 会在本地创建一个milvus 数据库milvus_client = MilvusClient("milvus_demo.db")collection_name = "my_rag_collection"if milvus_client.has_collection(collection_name):milvus_client.drop_collection(collection_name)milvus_client.create_collection(collection_name=collection_name,dimension=embedding_dim,metric_type="IP",consistency_level="Strong")data = []for i, line in enumerate(tqdm(text_lines, desc="Creating embeddings")):data.append({"id": i, "vector": emb_text(line), "text": line})print("data: ", len(data))milvus_client.insert(collection_name=collection_name, data=data)question = "How is data stored in milvus?"search_res = milvus_client.search(collection_name=collection_name,data=[emb_text(question)],limit=3,search_params={"metric_type": "IP", "params": {}},output_fields=["text"])retrieved_lines_with_distances = [(res["entity"]["text"], res["distance"]) for res in search_res[0]]print("retrieved: ", retrieved_lines_with_distances)print(json.dumps(retrieved_lines_with_distances, indent=4))context = "\n".join([line_with_distance[0] for line_with_distance in retrieved_lines_with_distances])SYSTEM_PROMPT = """Human: You are an AI assistant. You are able to find answers to the questions from the contextual passage snippets provided."""USER_PROMPT = f"""Use the following pieces of information enclosed in <context> tags to provide an answer to the question enclosed in <question> tags.<context>{context}</context><question>{question}</question>"""response = openai_client.chat.completions.create(model="qwen-plus", # 可以换成你自己喜欢的模型messages=[{"role": "system", "content": SYSTEM_PROMPT},{"role": "user", "content": USER_PROMPT},],)print(response.choices[0].message.content)
当然,上面文章写的不明白的地方,用户可以自己看milvus的官方文档,操作起来真的特别简单,这个案例就是作者自己根据milvus的官方文档实现的。
文档地址:https://milvus.io/docs/zh/build-rag-with-milvus.md
