




今年1月份,AI 方面最火爆的议题莫过于针对杭州的 DeepSeek 公司(深度求索)的AI技术、产品的讨论热度,急剧上升,连续霸榜中国以及西方的科技头条。
尤其是在美国 X社交平台(推特)上的一些科技大佬名人,夸赞了DeepSeek坚持开源、某些性能不弱于美国顶尖AI产品后,这些言论被转回国内社交平台上,掀起了一浪高过一浪拆解、分析、盛赞DeepSeek的舆论。
为什么DeepSeek 的大模型这么火爆,让西方科技巨头如临大敌呢
背景
现在训练顶级 AI 模型贵得离谱!OpenAI、Anthropic,Meta 这些科技巨头公司动不动烧 1 亿美金起步进行训练。他们需要塞满几万台 GPU 的数据中心,相当于为了开个工厂先得建发电站。
结果
DeepSeek用实力打脸: 我们花 550 万美金就能搞定,而且模型实测性能已经赶超 GPT-4 和 Claude,典型的 "加量不加价"。于是乎,整个 AI 圈为之震惊。一位 Meta 员工在匿名的帖子中写道:“工程师们正在疯狂地分析 DeepSeek,试图从中复制任何可能的东西。这一点都不夸张。”更令他们担忧的是,“当生成式 AI 组织中的每个‘领导’的薪资都比训练整个 DeepSeek-V3 的成本还要高,而我们有好几十个这样的‘领导’时,他们要如何面对高层?”
DeepSeek如何做
他们的操作分三步走:
第一步,精准瘦身:传统 AI 就像用 32 位小数记账,DeepSeek 直接改用 8 位:“反正够用就行!” 内存需求立减 75%。就像把 100 斤的胖子直接减到 25 斤,还能跑马拉松。
第二步,打包处理:普通 AI 看文字像小学生指读:“小…… 明…… 吃…… 饭……”,他们直接整句扫读。速度翻倍,准确率还能保持在 90%。当处理几十亿词汇时,这就非常重要了。
第三步,专家会诊:传统模型是逼着 1 个学霸同时精通医学法律编程,DeepSeek 搞了个专家联盟(MOE):平时谁也不理谁的,需要时才摇人。18,000 亿参数的传统模型?人家总共 6710 亿参数,但每次只用 370 亿。相当于去医院看病,直接给你匹配知名专家。 用专业一点的术语解释
在MOE架构中,引入了路由专家 (Routed Experts) 和共享专家 (Shared Experts) 。主要是用来激活那些参数需要被更新。路由专家中主要是用来选择参数进行激活。对于每个输入的token,只有一部分路由专家会被选中来参与计算。这个选择过程是由一个门控机制决定的,比如DeepSeek MoE中用的那种根据亲和度分数来选的Top-K方式。而共享专家始终参与所有输入的处理。无论输入是什么,所有共享专家都会贡献它们的力量。
效果有多离谱呢?
训练成本:1 亿刀→550 万刀(直接打骨折) GPU 需求:10 万台→2000 台(网吧配置就能玩) API 价格:直接砍到脚踝价(便宜 95%) 用游戏显卡就能跑(英伟达数据中心卡滞销警告, 1.28的交易日创下历史最大跌幅 跌了3w亿软妹币)
对股市的影响

DeepSeek的低成本训练方法依赖于更高效的算法或新型硬件,可能减少对传统高性能GPU的依赖,从而影响NVIDIA的某些产品线需求。目前市场已经用脚投票,英伟达,博通,台积电 等公司大跌10% 以上,美国纳斯达克指数暴跌3%
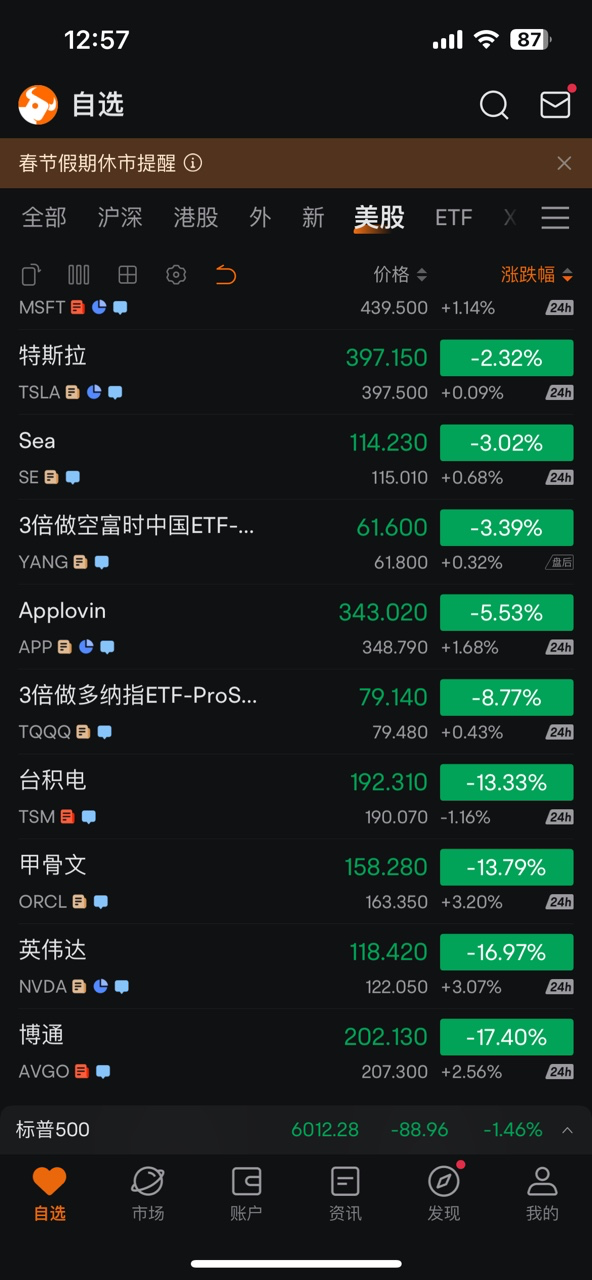
但是 高性能的大模型会刺激 模型应用的进一步普及,长期会进一步刺激AI 应用对 硬件的需求。这里有个疑问,对显卡的需求 不一定是 英伟达一直收益,可能是其他公司的 GPU 产品。
