




使用Timescale压缩和分块跳过索引,实现PostgreSQL处理数十亿行数据的方法。
译自Handling Billions of Rows in PostgreSQL,作者 Semab Tariq。
在PostgreSQL(或任何关系数据库)中处理数十亿行的表可能具有挑战性,因为数据复杂性高、存储空间占用量大以及更复杂或分析查询的性能问题。
通过在Timescale中启用列存储(压缩数据)并使用Timescale的块跳过索引,可以解决所有这些挑战。Timescale构建在PostgreSQL之上,旨在简化PostgreSQL的扩展。这篇文章展示了如何使用Timescale的列存储和块跳过索引功能来减小表大小并加快搜索速度。
以下是我们将遵循的方法。首先,我们将数据插入到未压缩表中以获取初始大小和查询速度。然后,我们将这些结果与压缩表进行比较。让我们开始吧。
我们将在Timescale Cloud上使用PostgreSQL——这是一种完全托管的数据库服务,旨在高效处理时间序列数据。它提供PostgreSQL的熟悉功能,同时添加强大的时间序列功能。
功能包括自动缩放、高可用性和各种性能优化,使开发人员更容易存储、管理和查询大量时间序列数据,而无需担心基础设施管理。
以下是这些测试中使用的实例详细信息:
实例类型:时间序列
CPU:4核
RAM:16 GB
未压缩表基准测试
首先,我们在时间序列数据库中创建一个名为sensor_uncompressed
的PostgreSQL堆表,并将十亿行数据导入其中。之后,我们检查其统计信息,包括表大小和SELECT
查询性能。
步骤1:创建一个表格
CREATE TABLE sensors_uncompressed ( sensor_id INTEGER, ts TIMESTAMPTZ NOT NULL, value REAL );步骤2:创建索引
CREATE INDEX sensors_ts_idx_uncompressed ON sensors_uncompressed (sensor_id, ts DESC);步骤3:摄取数据
数据集被放置在AWS S3存储桶中,因此我们使用了timescaledb-parallel-copy工具将数据导入表中。timescaledb-parallel-copy是一个用于并行化PostgreSQL内置COPY功能的命令行程序,用于批量插入数据到TimescaleDB。
curl https://ts-devrel.s3.amazonaws.com/sensors.csv.gz | gunzip | timescaledb-parallel-copy -batch-size 5000 -connection $DATABASE_URI -table sensors_uncompressed -workers 4 -split '\t'
以下是成功将十亿行数据导入PostgreSQL堆表后的部分统计信息。
数据导入时间:49分钟12秒
包括索引和数据的总表大小:101 GB
步骤4:运行聚合查询
目标是通过对压缩表和未压缩表运行各种缩放聚合查询来比较查询执行时间,观察压缩表相对于未压缩表的性能。
Query 1
SELECT * FROM sensors_uncompressed WHERE sensor_id = 0 AND ts >= '2023-12-21 07:15:00'::timestamp AND ts <= '2023-12-21 07:16:00'::timestamp; -- Execution Time: 38 msQuery 2
SELECT sensor_id, DATE_TRUNC('day', ts) AS day, MAX(value) AS max_value, MIN(value) AS min_value FROM sensors_uncompressed WHERE ts >= DATE '2023-12-21' AND ts < DATE '2023-12-22' GROUP BY sensor_id, DATE_TRUNC('day', ts) ORDER BY sensor_id, day; -- Execution Time: 6 min 31 secQuery 3
SELECT sensor_id, ts, value FROM sensors_uncompressed WHERE ts >= '2023-12-21 07:15:00' AND ts < '2023-12-21 07:20:00' ORDER BY value DESC LIMIT 5; -- Execution Time: 6 min 24 sec压缩超表基准测试
现在是时候收集使用Timescale的列存储方法的压缩超表(按时间自动分区PostgreSQL表)的统计信息了。
步骤1:创建一个表
CREATE TABLE sensors_compressed ( sensor_id INTEGER, ts TIMESTAMPTZ NOT NULL, value REAL );步骤2:创建索引
CREATE INDEX sensors_ts_idx_compressed ON sensors_compressed (sensor_id, ts DESC);步骤3:转换为超表
SELECT create_hypertable('sensors_compressed', by_range('ts', INTERVAL '1 hour'));步骤4:启用列存储/压缩
ALTER TABLE sensors_compressed SET (timescaledb.compress, timescaledb.compress_segmentby = 'sensor_id');步骤5:添加压缩策略
SELECT add_compression_policy('sensors_compressed', INTERVAL '24 hour');步骤6:摄取数据
curl https://ts-devrel.s3.amazonaws.com/sensors.csv.gz | gunzip | timescaledb-parallel-copy -batch-size 5000 -connection $CONNECTION_STRING -table sensors_compressed -workers 4 -split '\t'以下是成功将十亿行数据导入启用压缩的超表后的统计信息。
数据导入时间:1小时3分21秒
包括索引和数据的总表大小:5.5 GB
步骤7:运行聚合查询
Query 1
SELECT * FROM sensors_compressed WHERE sensor_id = 0 AND ts >= '2023-12-21 07:15:00'::timestamp AND ts <= '2023-12-21 07:16:00'::timestamp; -- Execution Time: 20 msQuery 2
SELECT sensor_id, DATE_TRUNC('day', ts) AS day, MAX(value) AS max_value, MIN(value) AS min_value FROM sensors_compressed WHERE ts >= DATE '2023-12-21' AND ts < DATE '2023-12-22' GROUP BY sensor_id, DATE_TRUNC('day', ts) ORDER BY sensor_id, day; -- Execution Time: 5 minQuery 3
SELECT sensor_id, ts, value FROM sensors_compressed WHERE ts >= '2023-12-21 07:15:00' AND ts < '2023-12-21 07:20:00' ORDER BY value DESC LIMIT 5; Execution Time: 4.4 sec关键要点
存储效率: 启用压缩后,表大小减少了约 95%。
聚合查询 1 在压缩表上快了 47.37%。
聚合查询 2 在压缩表上快了 23%。
聚合查询 3 在压缩表上快了 98.83%。
这些结果证明了使用 TimescaleDB 的压缩功能的显著优势,无论是在存储节省方面还是在查询性能改进方面。使用分块跳过索引增强 PostgreSQL 性能
在时间尺度中的块跳过
进一步加快 PostgreSQL 性能并减少存储空间占用的是Timescale 的分块跳过索引(从 TimescaleDB 2.16.0 开始可用)。此功能使开发人员能够使用元数据在规划或执行期间动态修剪和排除分区(称为块),因为并非所有查询都非常适合分区。如果无法按分区列进行筛选,则会导致查询缓慢,因为 PostgreSQL 无法在没有非分区列的元数据的情况下排除任何分区。
分块跳过索引通过允许我们在搜索大型数据集时绕过不相关的块来优化查询性能。
在 TimescaleDB 中,数据被组织成基于时间的块,每个块代表超表的整体的一个子集。当查询指定时间范围或其他可以筛选数据的条件时,分块跳过索引使用元数据来识别和访问仅相关的块,而不是顺序扫描每个块。
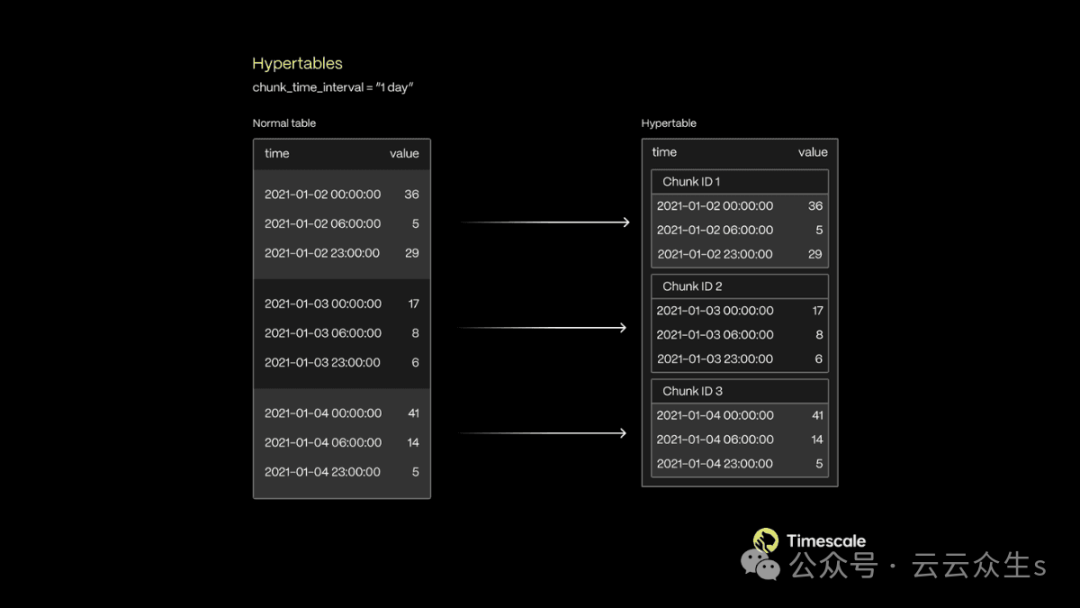

这种有针对性的访问最大限度地减少了磁盘 I/O 和计算开销,使查询更快、更高效,尤其是在拥有数十亿行的超表中。
让我们创建一个名为product_orders
的表,其中包含订单详细信息的列,例如 ID、时间戳、数量、总计、地址和状态。
CREATE TABLE product_orders ( order_id serial, order_date timestamptz, customer_id int, product_id int, quantity int, order_total float, shipping_address text, payment_status text, order_status text );转换为超表
将product_orders
表转换为 TimescaleDB 超表,按order_date
分区,间隔为四天。
SELECT create_hypertable('product_orders', 'order_date', chunk_time_interval=>'4 day'::interval);摄取数据
为了导入数据,我们将使用一个查询来生成 5000 万行虚拟订单数据,模拟从 2023 年 1 月 1 日开始每分钟一个订单。该查询为客户和产品 ID、数量、总计和状态字段分配随机值,以创建真实的订单记录。
WITH time_series AS ( SELECT generate_series( '2023-01-01 00:00:00'::timestamptz, '2023-01-01 00:00:00'::timestamptz + interval '50000000 minutes', '1 minute'::interval ) AS order_date ) INSERT INTO product_orders ( order_date, customer_id, product_id, quantity, order_total, shipping_address, payment_status, order_status ) SELECT order_date, (random() * 1000)::int + 1 AS customer_id, (random() * 100)::int + 1 AS product_id, (random() * 10 + 1)::int AS quantity, (random() * 500 + 10)::float AS order_total, '123 Example St, Example City' AS shipping_address, CASE WHEN random() > 0.1 THEN 'Completed' ELSE 'Pending' END AS payment_status, CASE WHEN random() > 0.2 THEN 'Shipped' ELSE 'Pending' END AS order_status FROM time_series;数据导入完成后,让我们执行一个简单的SELECT
语句来测量查询执行所需的时间。
tsbd=> select * from product_orders where order_id = 50000000; order_id | order_date | customer_id | product_id | quantity | order_total | shipping_address | payment_status | order_status ----------+-----------------------+-------------+------------+----------+-------------------+------------------------------+----------------+-------------- 50000000 | 2117-01-24 12:33:00+00 | 515 | 14 | 9 | 61.00540537187403 | 123 Example St, Example City | Completed | Shipped (1 row) Time: 42049.154 ms (00:42.049)目前,order_id
列上没有索引,这就是为什么查询花费近 42 秒才能执行的原因。
添加索引
让我们看看是否可以通过在order_id
列上创建B 树索引来减少这 42 秒。
CREATE INDEX order_id ON product_orders (order_id);创建索引后,让我们重新运行SELECT
查询并检查执行时间是否从 42 秒减少。
tsdb=> select * from product_orders where order_id = 50000000; order_id | order_date | customer_id | product_id | quantity | order_total | shipping_address | payment_status | order_status ----------+------------------------+-------------+------------+----------+-------------------+------------------------------+----------------+-------------- 50000000 | 2117-01-24 12:33:00+00 | 515 | 14 | 9 | 61.00540537187403 | 123 Example St, Example City | Completed | Shipped (1 row) Time: 9684.318 ms (00:09.684)太好了!创建索引后,执行时间缩短到了不到9秒,这是一个显著的改进。现在,让我们进一步优化,探索块跳过如何能进一步提升性能。
启用分块跳过索引
要利用块跳过索引,我们首先需要在表上启用块跳过,然后对其进行压缩。这样可以让 TimescaleDB 为每个块生成必要的元数据。
ALTER TABLE product_orders SET (timescaledb.compress); SELECT compress_chunk(show_chunks('product_orders')); SELECT enable_chunk_skipping('product_orders', 'order_id');启用分块跳过和列存储(压缩数据)后,让我们重新运行相同的SELECT
查询以观察性能改进。
select * from product_orders where order_id = 50000000; order_id | order_date | customer_id | product_id | quantity | order_total | shipping_address | payment_status | order_status ----------+------------------------+-------------+------------+----------+-------------------+------------------------------+----------------+-------------- 50000000 | 2117-01-24 12:33:00+00 | 515 | 14 | 9 | 61.00540537187403 | 123 Example St, Example City | Completed | Shipped (1 row) Time: 304.133 ms哇!查询现在只需 304 毫秒即可执行,与没有索引的初始执行时间相比,性能提高了99.28%,与 PostgreSQL 索引相比,性能提高了96.86%。这是一个显著的差异!
总之,使用 TimescaleDB 的关键特性——例如超表、列存储和分块跳过索引——可以极大地提高 PostgreSQL 的性能:
超表帮助您更轻松地管理大量数据,同时保持一切井然有序。
列存储减少存储空间并通过减少需要读取的数据量来加快查询速度。
分块跳过索引还可以通过忽略不必要的数据来加快查询性能。
这些特性共同简化了时间序列数据、事件和实时分析的工作。通过选择 TimescaleDB,您正在投资一个更高效、更强大的数据系统,该系统可以处理大型工作负载并轻松扩展 PostgreSQL。
