





我们非常高兴的宣布,在海外版 Azure Database for PostgreSQL——灵活服务器上推出 DiskANN 预览版!作为一种领先的矢量索引算法,DiskANN 由微软研究院开发,并已广泛应用于 Bing、Microsoft 365 等全球服务。DiskANN 帮助开发人员构建高精度、高性能且具备良好扩展性的生成式 AI 应用,超越了 pgvector 的 HNSW 和 IVFFlat,在延迟和准确性方面表现更出色。同时,DiskANN 还克服了 pgvector 在过滤矢量搜索中偶尔返回错误结果的局限性,为开发者提供更稳定可靠的搜索体验。
什么是 DiskANN?
DiskANN 是一种可扩展的最近的邻域搜索算法,可给出近似的结果,适用于任意规模的高效矢量搜索。 这一算法能够做到高召回率、每秒高查询 (QPS) 和低查询延迟,甚至适用于包含数十亿项目的数据集。 这使得它成为处理大量数据的强大工具。

DiskANN 在 Azure PostgreSQL- 灵活服务器上优化布局
DiskANN 的强大技术特点包括:
优化存储:即使超出 RAM 限制,也能保持快速的搜索速度。
向量量化:将量化后的向量保存在内存中,我们在 PostgreSQL 上的 DiskANN 实现,巧妙平衡了量化与未量化向量的交互,实现低延迟和高精度。
迭代后过滤:在不牺牲速度或精度的前提下,进一步提升了过滤搜索结果的准确性。
稳健的 Vamana 图结构:Vamana 图结构在频繁插入、修改和删除操作下依然能保持高准确性,避免了昂贵的索引重建,与传统图索引相比更具韧性。
过滤矢量搜索问题
矢量相似性搜索是将数据(如图像或文本)转化为矢量表示,存储到索引中,并通过查询矢量在索引中找到匹配的结果。在进行矢量搜索时,用户往往会应用一些非矢量化数据的筛选条件以提升搜索的精准度,比如按日期或价格筛选。然而,pgvector 对过滤矢量搜索的支持相对有限。比如,假设您想在特定日期以低于 30 美元的价格查找排名前 3 的出租房源,可以尝试如下查询:
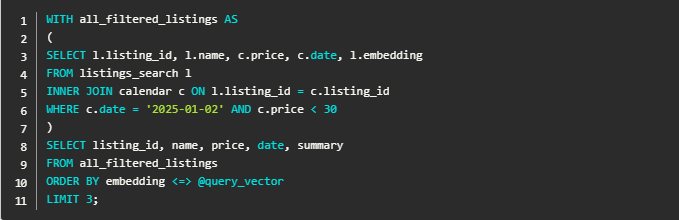
在 pgvector 中,如果我们需要在庞大的数据库中进行矢量相似性搜索,获取最相关的前 3 行结果,查询规划器会将该请求拆分成两个步骤:
排序:首先,根据数据集中与查询最相关的前几行(默认 40 行)进行排序。这里的相似行数量由参数 ef_search 决定,它控制搜索过程中的动态列表大小。
应用过滤:接着,进行后续的条件筛选(如价格低于 30 美元,日期为 2025 年 1 月 2 日),以排除不满足条件的行,最终返回符合条件的 3 行结果(LIMIT 3)。
值得注意的是,pgvector 的实现有时无法保证在后过滤时总能返回 3 行结果。尤其是在过滤条件较宽松的情况下,后过滤步骤可能在最相关的前 40 行中找不到匹配项。这种情况下,即便数据库中存在符合条件的行,pgvector 也可能不返回任何结果。
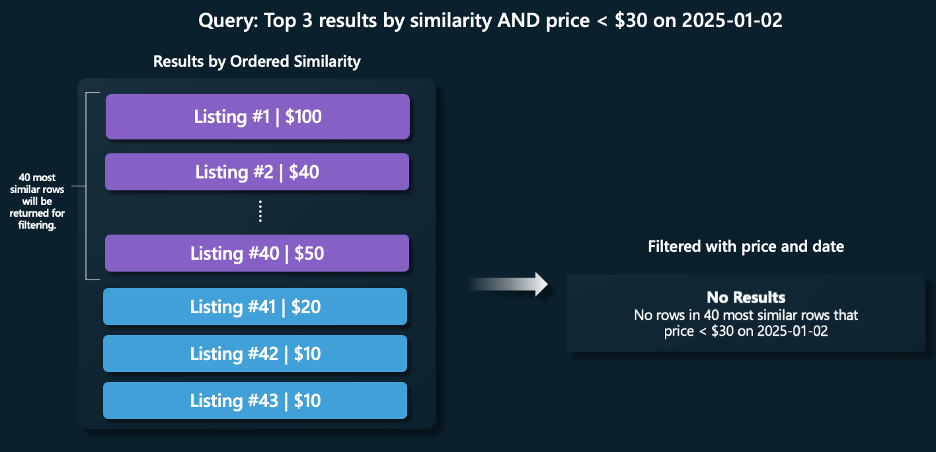
使用 HNSW。想象一个场景,用户在房地产列表数据库中搜索与给定查询类似的房源,并且只想要特定日期下价格低于 30 美元的房源。
在 pgvector 的 HNSW 模式下,虽然增加返回的相关行数量可以缓解部分问题,但其最大返回上限为 1000 行。如果查询的条件选择性要求扫描超过 1000 行的结果,那么 HNSW 就难以满足这一需求。这在搜索大型数据集时尤其常见,导致过滤查询的召回率偏低。
DiskANN 迭代后
过滤带来高效精确的搜索体验
为解决这一痛点,我们在 Postgres 上引入了 DiskANN 及其迭代后过滤功能,特别适用于过滤查询场景。DiskANN 通过迭代方式获取最接近的条目,不断优化搜索精度,直至满足预期结果数量,且全程保持快速响应与高精度。此创新技术专为过滤查询设计,确保搜索结果的高度相关性和低延迟,带来卓越的用户体验。
使用 DiskANN 进行过滤向量相似性搜索时,查询规划器会执行以下 3 个步骤,帮助您在大量数据中找到最相关的前 3 条记录:
排序相关行:首先按数据集中最相关的行进行排序。返回的相似行数量由 DiskANN 中的 l_value_is 参数控制。
应用后置过滤:添加筛选条件(如价格低于 30 美元且日期为 2025 年 1 月 2 日),移除不符合条件的记录。
迭代获取符合筛选条件的结果:按相似度顺序遍历所有记录,直至找到符合条件的 3 条记录(在查询中通过 LIMIT 3 定义)。
这种 3 步查询计划能确保快速且精准地找到符合条件的最佳结果,为您的数据筛选带来更高效率!
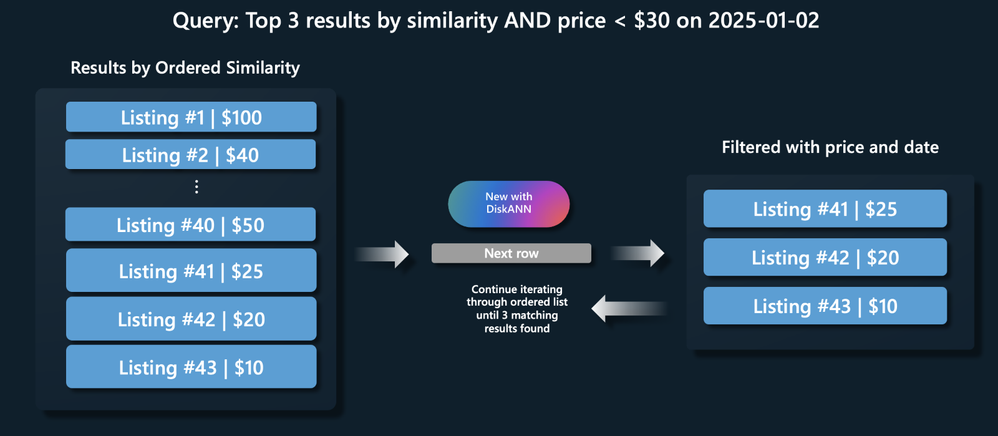
使用 HNSW。想象一个场景,用户在房地产列表数据库中搜索与给定查询类似的房源,并且只想要特定日期下价格低于 30 美元的房源。
面向未来的可扩展性
DiskANN 不仅提升了召回率,还支持高效地存储和搜索海量向量数据!通过利用固态硬盘(SSD)来减少内存占用,DiskANN 实现了极致的可扩展性和高效性。它通过量化技术将压缩后的矢量存储在内存中,并在需要时从 SSD 中调用完整矢量进行最终比对,确保精准度。这项技术让系统即使在处理超大规模数据集时,也能保持响应快速、成本低廉。

DiskANN 如何优化存储
稳定应对插入、
删除和更新操作
DiskANN 的图索引设计非常稳健,即便在大量数据插入、更新或删除的情况下也不会随时间衰减。而市场上大多数基于 HNSW 等技术的向量数据库在面对这种情况时,往往需要高昂的重建成本来维持准确性。DiskANN 专注于减少维护工作,同时确保搜索结果的高精准度,是对精度有极高要求的生产环境的理想之选!
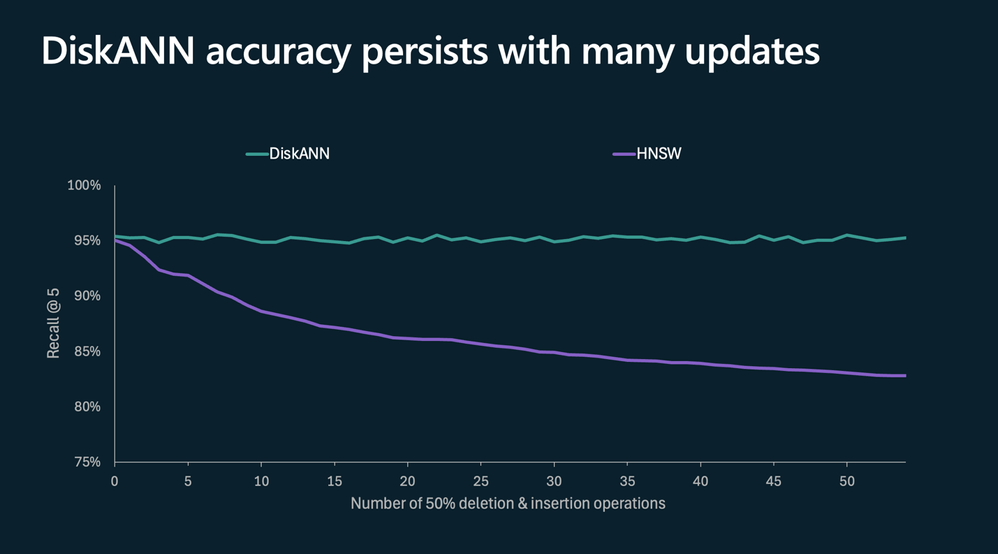
DiskANN 与 HNSW 的稳定性
拥抱 Azure Database
for PostgreSQL 的新未来
将迄今为止最先进的向量搜索技术引入 Azure Database for PostgreSQL,为 AI 应用带来全新可能。DiskANN 向量索引突破传统,使 Azure Database for PostgreSQL 拥有无与伦比的精度和高效性能。通过 DiskANN 的强大功能,您将获得:
简化运营、降低成本:DiskANN 的高效算法和精心设计的索引访问方式,有效利用 Postgres 存储,大幅节省成本。
释放无限扩展潜力:Azure PostgreSQL 数据库能够利用 SSD,减少内存占用,为您的 AI 应用提供无与伦比的扩展能力!
在 Azure Database
for PostgreSQL
上轻松使用 DiskANN
在 Azure Database for PostgreSQL 上使用 DiskANN 非常简便,您只需按照以下步骤操作:
启用 pgvector 和 DiskANN 扩展:在服务器配置中启用 pgvector 和 DiskANN 扩展,以便充分利用其功能。
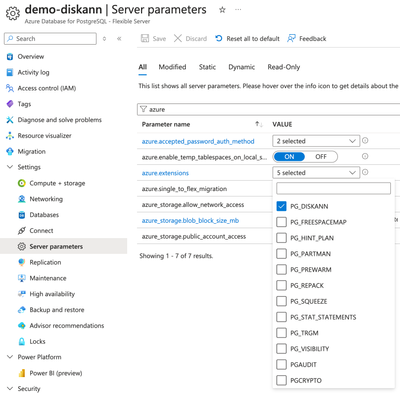
激活DiskANN
创建向量列:定义一个表来存储向量数据,确保包含一个类型为“向量”的列,用于保存向量嵌入。
索引向量列:在向量列上创建索引,以提升搜索性能。DiskANN PostgreSQL 扩展与 pgvector 兼容,支持相同的数据类型、距离函数和语法风格。

执行向量搜索:通过 SQL 查询,基于多种距离度量来查找相似向量(例如,下面的示例使用了余弦相似度)。
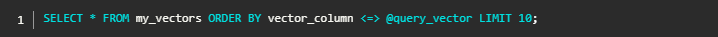
立即体验 DiskANN 预览版
利用 Azure Database for PostgreSQL 的强大功能,探索人工智能驱动应用程序的未来!
1. 请与您的微软客户代表联系,填写申请表单,注册 DiskANN 早期预览版。
2. 获得批准后,运行端到端示例,在指定的示例数据库上测试 DiskANN 与 HNSW 的性能对比。


