




今天趁着工作的间隙,体验了一把本地 Deep Seek 的功能。
DeepSeek 本地部署体验
关于 DeepSeek 本地部署的方法,网上很多相关的教程,使用 Ollama 来部署 DeepSeek 一条命令就能搞定,非常简单这里不再赘述,重点说说使用体验。
在 Ollama 网站上提供了 DeepSeek-R1 和6个不同密度的蒸馏模型,大家可以根据自己的需要和本地资源情况选择不同的模型来进行体验。
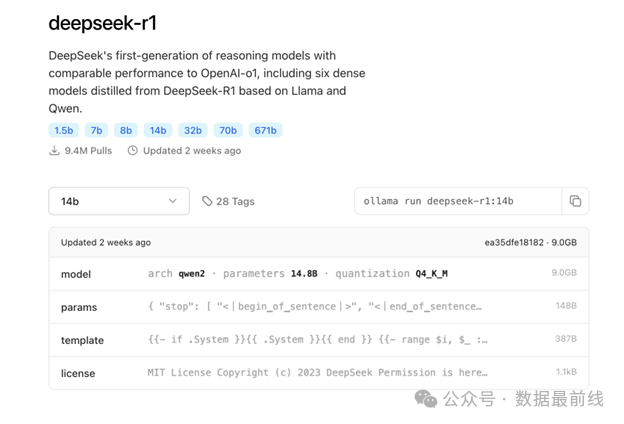
因为笔者的体验环境只是一台平时工作的笔记本,最开始下载的是 deepseek-r1:7b 模型,这个模型大小4.7GB。可是当我询问“如何使用sqlplus关闭数据库”时,模型给出了如下的回答。

前面的废话就不多评价了,关键的操作命令给出的是“drop database ……”,这不是要关闭数据库,而是关闭公司呀。真要照这个命令关闭数据库,不赔的倾家荡产才怪!
后来有朋友建议使用14b的模型,这次给出的建议就靠谱多了。不仅列出了3种关闭模式,还给出了实例状态检查命令,比较符合DBA的思维模式。

接下来试着让 DeepSeek 帮忙写一个ADG的监控脚本,生成的脚本可以用非常专业来评价。这个脚本实现了两个参数分别用于获取延时信息和发送告警,同时还给出了脚本使用说明和相应的配置步骤,只需要少量的修改就可以使用。


写在最后
虽然只是一个简单的体验,带给我的感觉仍然是震撼的!
首先,大模型的使用成本越来越低,蒸馏后的14b模型仅9GB,中等性能的笔记本运行起来毫无压力,使用成本的降低必将快速推动大模型的快速普及。因此可以预见的是,未来几年大模型将会渗透到我们生活的各个可能的角落;
其次,大模型既能够提升我们的工作效率,也会加速低技术含量工作的替代。就像前面ADG延时监控的脚本,如果人工来写可能需要2个小时,大模型几分钟就生成好了,加上测试和调整,大概1小时就能够完成,工作效率提升1倍。但如此一来,对岗位的数量需求也就下降了,因此大模型给我们的生活带来便利的同时,也可能会冲击到我们的工作;
再次,大模型仍然只是一种辅助,并不能完全取代人工。尤其是模型规模没有达到一定程度时,容易出现一些似是而非的答案,也就是我们常说的“一本正经胡说八道“。如同关闭数据库例子,如果没有专业技能的辅助盲目轻信大模型,轻则闹笑话、重则闯大货,并不是危言耸听;
最后,虽然大模型会对部分工作带来冲击,但最终会成为人类的帮手,最终得利的是善用大模型的那部分人。所以每个人都不应该忽视大模型对我们的影响,都应该要学会使用大模型优化工作效率,同时发展创造性思维和复杂问题的解决能力,这些是AI大模型不能替代的。
