





早就听说过Pinecone,但一直没接触过。
上期文章分享的Alluxio算是跟AI沾点儿边,借着这股子热情,潭主顺势把注意力转向了AI。
这两天花时间研习了一下Pinecone,有些收获。
本期,潭主分享一下向量数据库的学习心得。
什么是向量数据库
简单说,向量数据库是一种面向向量数据的数据库,它以向量作为基本数据类型,支持向量的存储、索引、查询和计算。
市面上产品很多,有的支持插件,有的支持字段,反正又是一堆厂商。
之所以选Pinecone,主要是因为其跟OpenAI结合比较紧密,相对主流的缘故吧。
向量数据库的应用场景很多,除了推荐系统、情感分析外,还支持RAG,后者可是当下企业追逐AI的热点。
接下来,就一起开始体验之旅吧。
Starter新手体验
登录官网:https://www.pinecone.io/,点击Sign Up,通过邮件的Verification Code完成注册。
目前,官网支持三个版本(Plan),潭主测试用的是Starter免费版,但免费版只能创建一个项目。
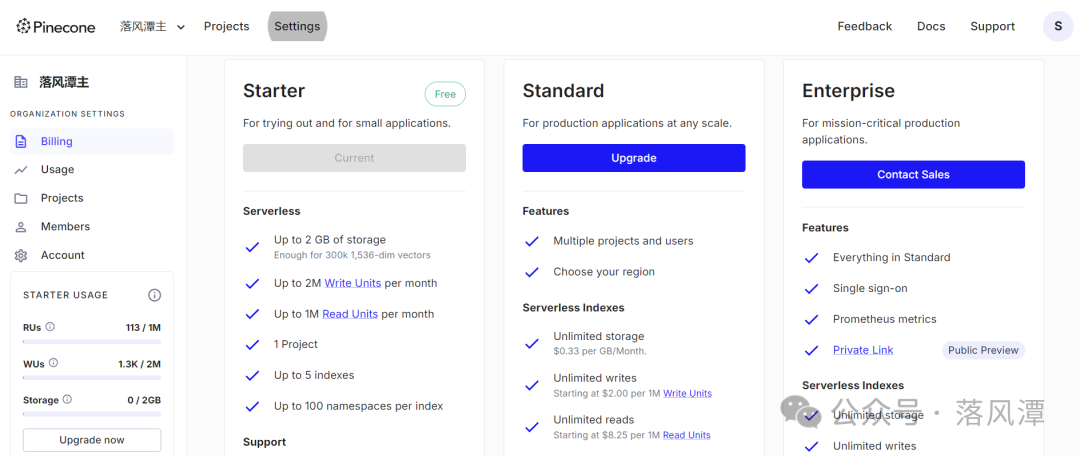
界面布局上,PineCone和MongoDB的Atlas风格类似,产品很容易上手。
不过,对比其他资料,能明显感受到产品端的变化还是很大的,应该跟Pinecone推出Serverless版本有关。
潭主自己创建了一个TK-Vector项目用于测试。
Pinecone的产品术语
Organization(组织)和Project(项目)都是现代化应用的标准化产品架构。
Pinecone也有Namespace的概念,感觉一切都是为了和K8S对齐颗粒度。
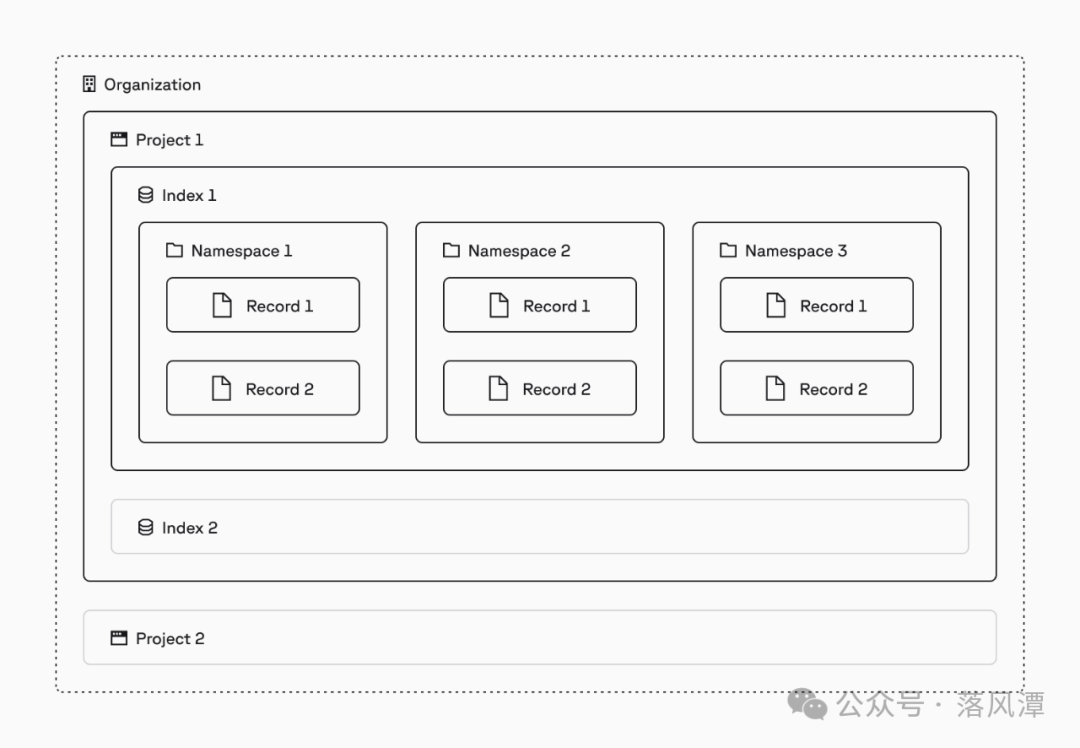
如图所示,Pinecone核心概念关系如下:
一个Project可以包含多个向量Index
一个Index又可以包含多个Namespace
一个Namespace是多条向量数据的集合
学习向量数据库,关键就是要搞懂向量自身的特征:
Index:索引是向量数据的最高级别组织单位,可以在其中定义要存储的向量的维度(Dimension)以及查询这些向量时要使用的相似度度量(Metric)
Collection:索引快照(Snapshot),也可以理解成Index的备份。
API key:访问数据的密钥,用于通过API-key完成API调用时的身份验证
创建Project时会默认创建一个“default”的API-key,也可以在项目中创建多个key。
此外,Pinecone还支持Rotate功能,更换密钥。
Namespace从属于Index,每个索引默认有一个名为(Default)的命名空间。
在实际应用中,可以将不同文档对应的向量数据存储在不同的Namespace,有助于规划管理,如在delete向量数据时,可以以Namespace为粒度执行批量删除。
Pinecone,从Pod到Serverless
Pinecone是一个托管式的云原生向量数据库,其核心是Vector Index。
现在的云原生到了高阶都是Serverless架构,Pinecone也不能免俗,毕竟Serverless有助于降低客户的用云成本支出。
Pinecone支持两种结构的索引:
Pod-based Indexes:可选择一个或多个预配置的硬件单元(Pod),根据Pod的类型、大小和数量,获得不同存储容量和性能
Serverless Indexes:无需配置或管理任何计算或存储资源,根据使用量自动扩展,只需为存储数据量和执行操作付费
Pod模式不同定价不同,跟MongoDB Atlas的M0、M10规格类似。
S系列(Storage):容量型,适合大容量,但延迟要求不高的大型索引。每个s1 Pod可存储大约500万个768维向量。
P系列(Performance):性能型,适用低延迟场景,p1 Pod延迟小于<100ms,可存储大约100万个768维向量;p2的性能更强,但不支持稀疏向量。
Pod类型的索引,创建后无法改变Pod类型,但可通过集合(Collection)进行中转,恢复成不同Pod类型的新索引,相当于索引的备份和重定向恢复。
每种Pod类型都支持四种Pod大小:x1、x2、x4和x8,对应索引的存储和计算能力都会翻倍,默认Pod大小为x1,可以在索引创建后增加Pod的大小。
Pod的环境对应的就是云服务商的可用区域,在索引创建时通过environment参数设置。
Pinecone的Serverless是实现了读写路径分离,计算资源根据需求独立自动扩展,该模式保证了查询不会影响写入吞吐量,而写入也不会影响查询延迟。
不过,Serverless模式的索引不支持Collection。
Pinecone的体系架构
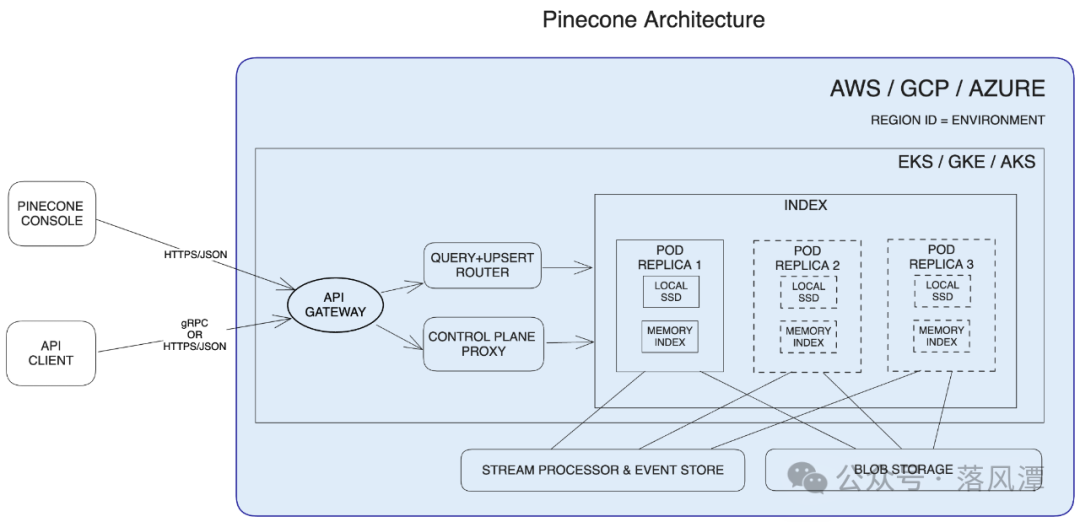
从Pod-based的架构图可以看到一些Pinecone的技术细节。
比如,前端通过API Gateway接入,有标准的Control Plane和Data Plane。
在向量索引部分,包括本地的SSD盘,内存中的索引、以及多副本的Pod Replica。
与Pod架构显示Blob存储不同,在Serverless架构中,可以看到Pinecone数据平面的后端是对象存储。
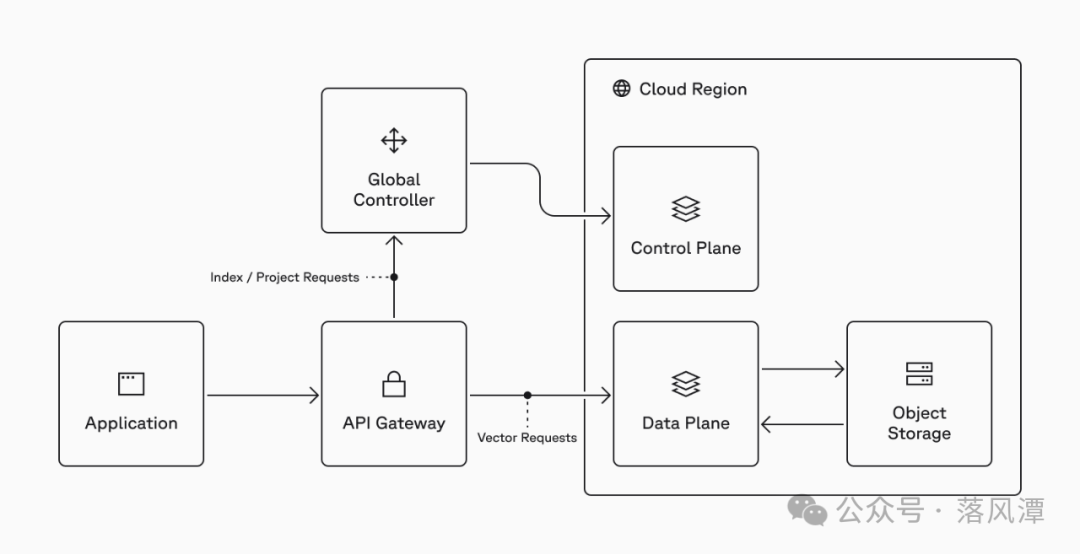
这让潭主不由想到了Oracle和MongoDB的Vector实现。
Oracle 23ai中对向量的支持是在数据表上支持Vector字段类型,存储底层是Blob类型。
MongoDB自身就是基于BSON格式设计的,其支持Vector属于水到渠成。
如何配置自己的Pinecone
如图所示,Serverless版的Pinecone项目跟Index、API key、User和Collection都是有关联的,如果是Pod架构还会涉及PodType:如p1.x1。
创建索引时需设置向量维度和度量标准两个参数,也可以通过选Model的方式设置。
Metric用于定义向量之间相似度的计算方法或距离度量方式,会直接影响向量检索的准确性和效率。
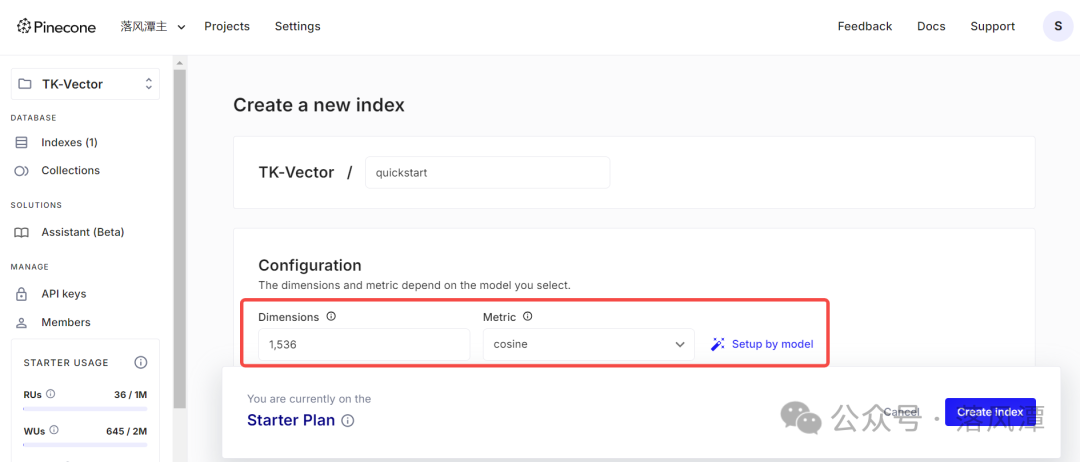
Pinecone提供了三种Metric:(默认为cosine)
euclidean(欧几里得):查询索引会返回一个相似度分数,该分数等于结果向量和查询向量之间的平方欧几里得距离(Euclidean Distance),用于衡量欧几里得空间中两点间的直线距离
cosine(余弦):常用于查找不同文档之间的相似性,其优势在于分数被归一化到[-1,1]范围内。余弦相似度(Cosine Similarity)衡量两个向量在方向上的相似度,而不考虑它们的大小。
dotproduct(点积):用于将两个向量相乘,用来判断这两个向量有多相似,结果越正,这两个向量在方向上的距离就越近。数学上,点积常用于计算两个向量之间的夹角或其中一个向量在另一个向量上的投影长度。
对于新手,Pinecone提供了“Load sample data”功能,可创建一个名为“sample-movies”的索引,对了解向量数据库很有帮助。
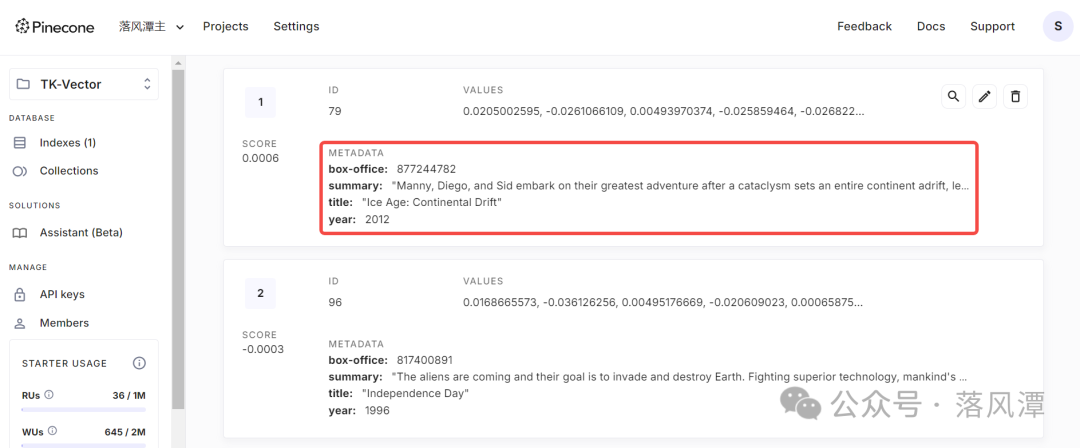
从使用感受上,潭主觉得Pinecone跟MongoDB很像,向量数据的ID类似MongoDB的ObjectID,除此之外,Pinecone还支持metadatah和sparse_values。
如图所示,Metadata其实一组Key-Value,可以通过图形界面测试Top_K和Metadata filter功能,也可以看成是字段型向量数据库。
Pinecone支持包含稀疏和密集值的向量,允许在一个查询中执行混合搜索(即语义搜索和关键字搜索),并将结果合并以获得更相关的结果。
Pinecone将稀疏值表示为两个数组组成的字典,索引(indices)数组的元素类型为uint32,而值(values)数组的元素类型为float32。
不过,只有使用点积距离度量的索引才支持稀疏密集向量。
伪程序猿的Python修养
Python跟AI贴合很紧密,所以潭主在笔记本上装了一个Anaconda,便于代码编写和测试。
实验过程中,潭主发现Pinecone更新变化很快,不同版本的API语法差异还是挺大的,无形中增加了学习的复杂度。
目前,AI涉及的学习范围很广,潭主先从Pinecone开个头,后面还有RAG、LongChain、LlamaIndex等。
希望,能早日搭建起属于潭主的AI框架。
- END -
感谢阅读。如果觉得写得还不错,就请点个赞或“在看”吧。
公众号所有文章仅代表个人观点,与供职单位无关。
推荐阅读

