





“采菊东篱下,
悠然现南山”。
晋·陶渊明


"作者: 悠然 | 首发公众号: dba悠然"
<温馨提示:以下内容仅代表个人观点>


近些年,国产化信创热火朝天,而数据库信创之路却显得似乎有些任重道远。刚好最近遇到一个与信创数据库相关的故事,与大家分享一下。

周一上午接到电话,某客户数据库卡顿,相关业务都无法使用,于是乎笔者又再一次化身为“老司机",当起了“救火队员”:
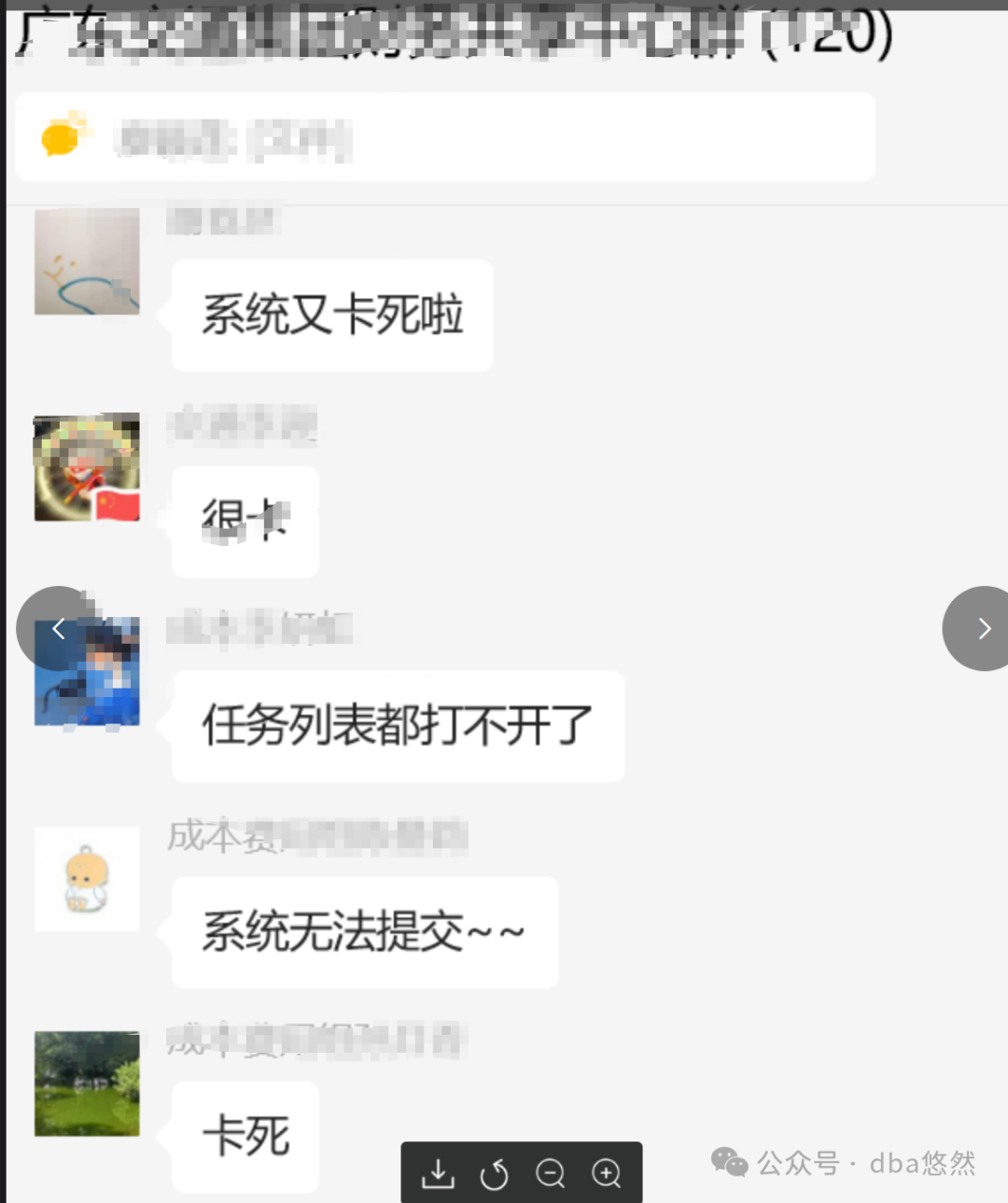
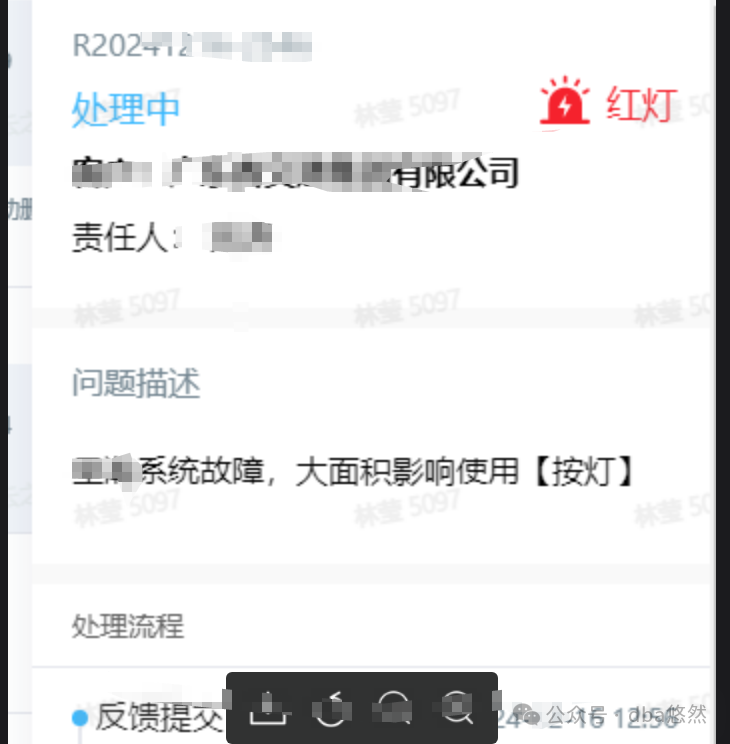
PART2:“老司机”登场

“首先了解下数据库老司机信条之一:如果不想背上一口大锅,故障第一时间保留现场,收集证据(养成截图习惯)。”
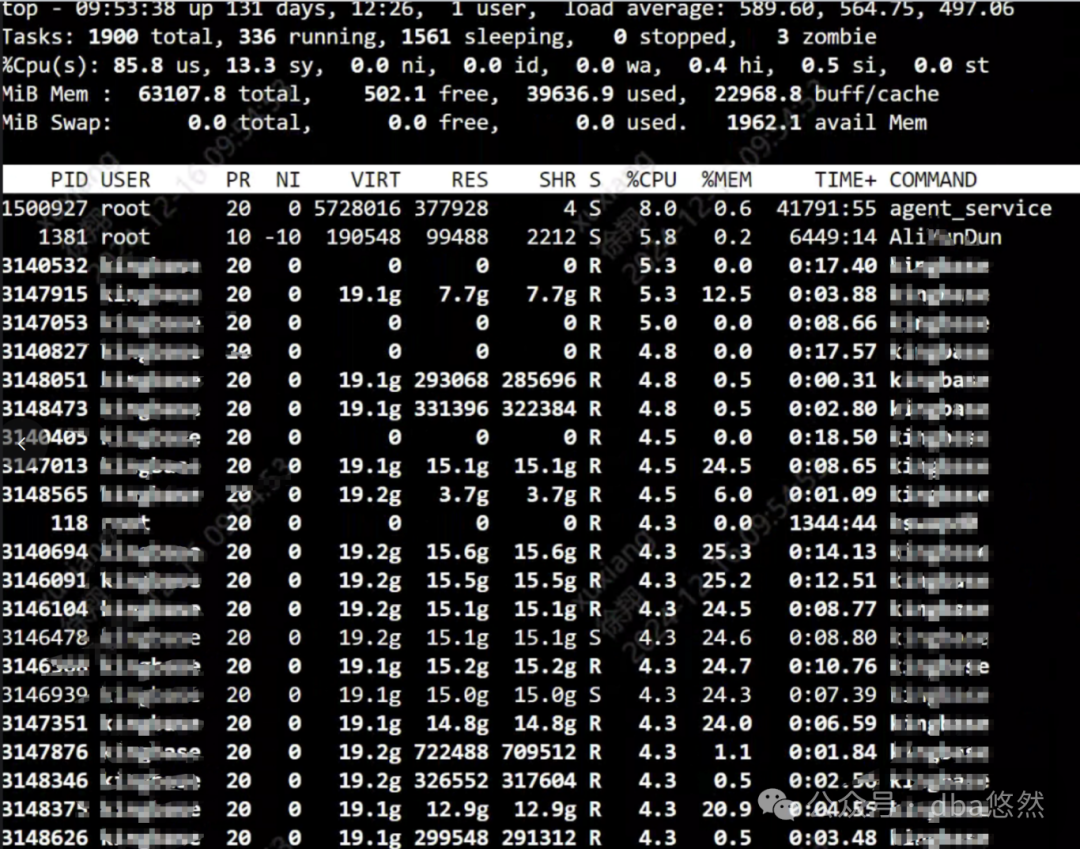
1)TOP显示Load已经到了近600,内存近乎耗尽:
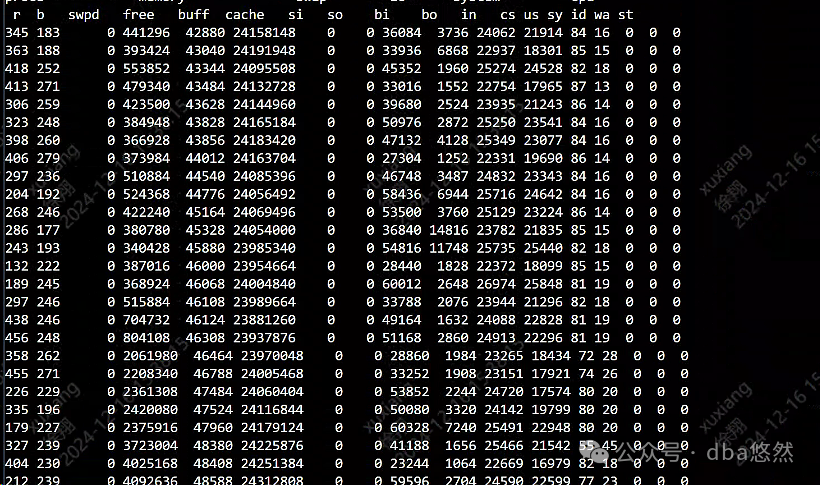
2)vmstat显示runing峰值接近450(cpu16c),而blocking接近300,cpu100%耗尽,cs/in很高:
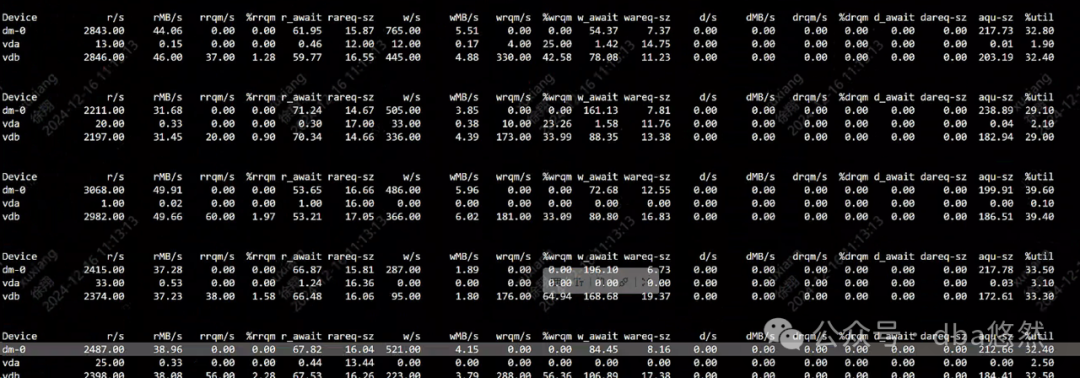
3)iostat显示读写iops不到4000,吞吐量不到50MB/s,io使用率正常:
2.数据库信息:
从收集到的信息来看数据库服务器几乎已经hang死了,接来看一下数据库的情况:
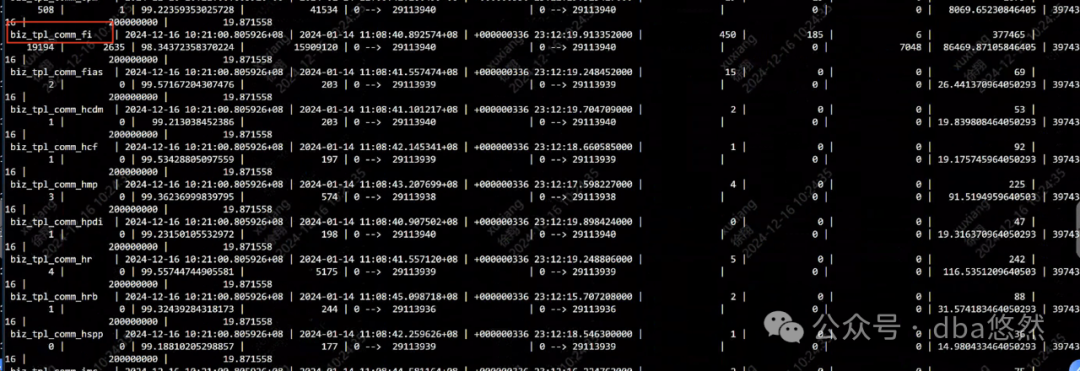
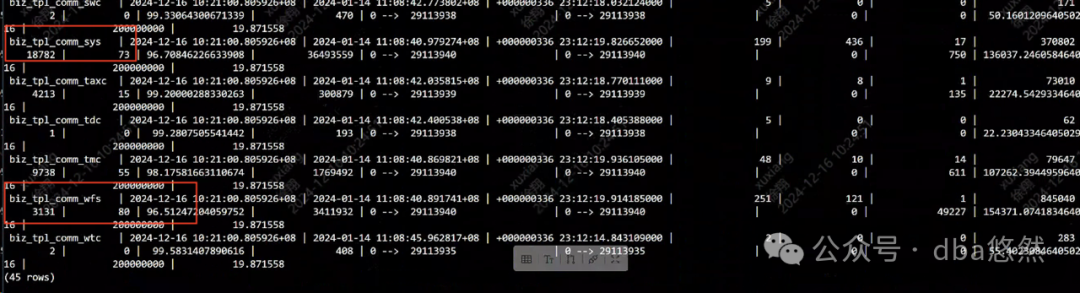
1)数据库负载运行一览:数据库负载主要集中sys/fi/wfs这几个库,平均dml相对比较高,部分db有轻微的tmp生成;数据库缓存命中率略有高地,age年龄正常:
2)数据库TOP会话:主要中在一个copy(备份),以及一些慢查询,TOP慢查询会话执行几个小时甚至几十个小时:
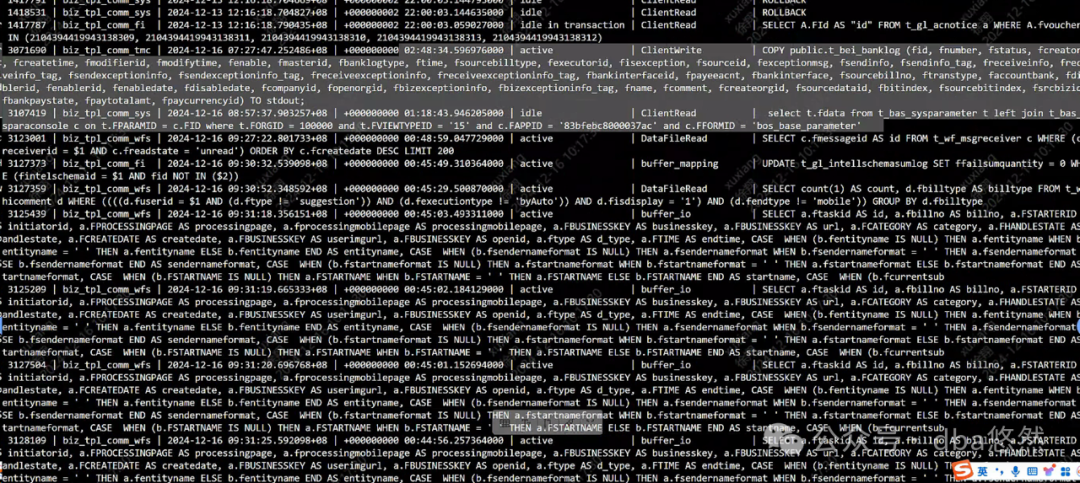
3)数据库Server慢查询输出较频繁:
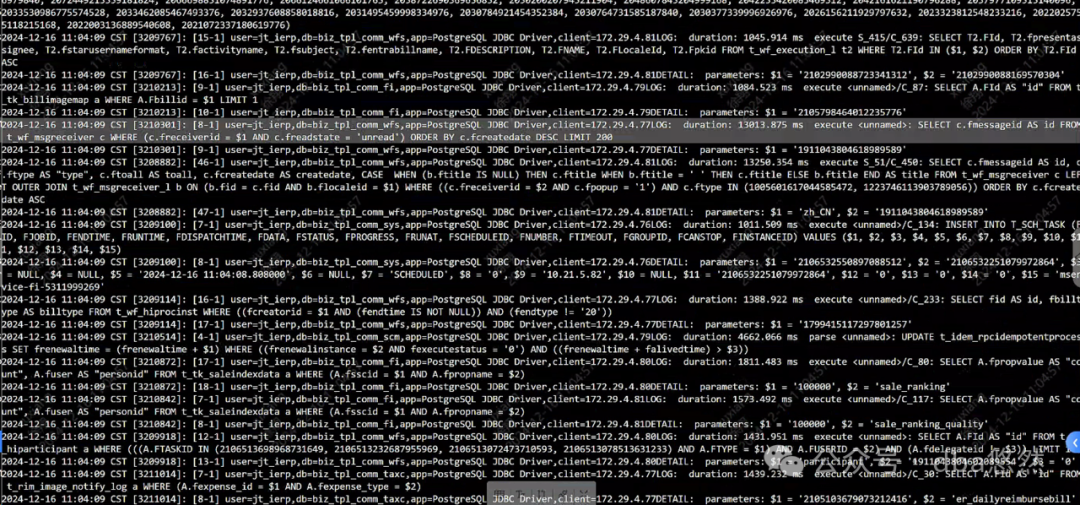
4)表对象相关信息:部分TOP大表几乎是全表扫描,未使用索引,同时统计信息有部分滞后:
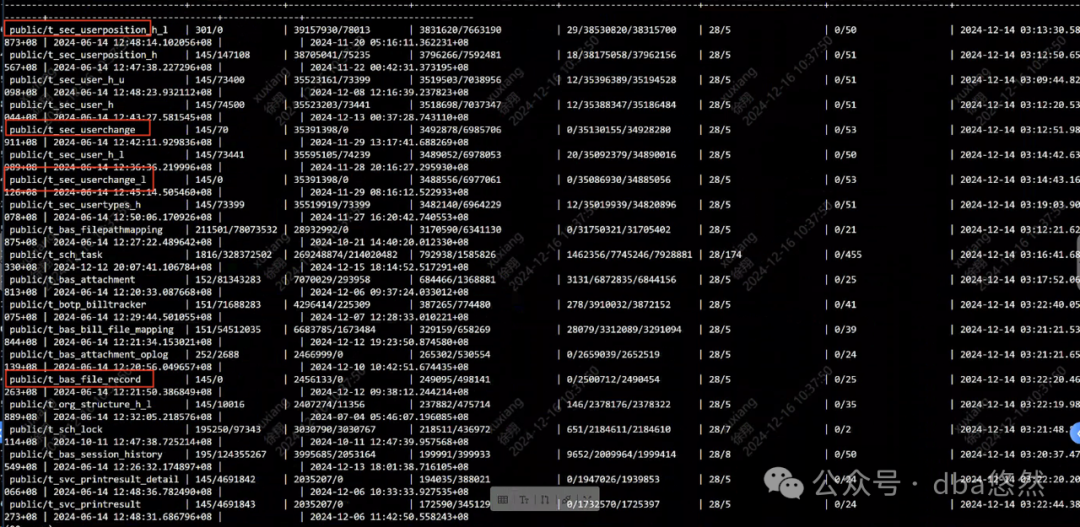
5)部分库表存在普遍性autovacuum/autoanalyze缺失问题:
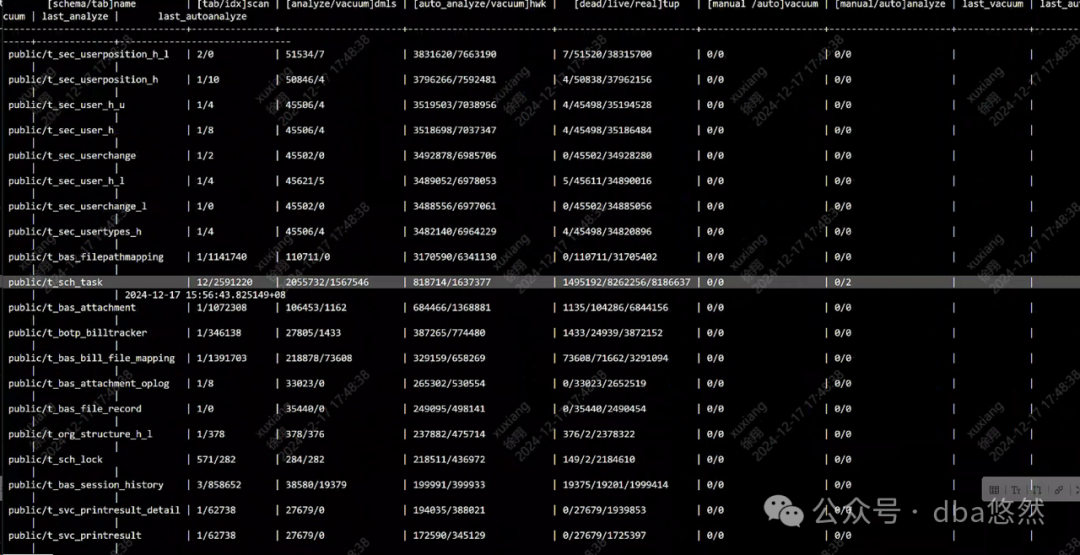
6)TOP 负载进程集中在单热点表业务(查询/DML),热点表dml过于频繁:
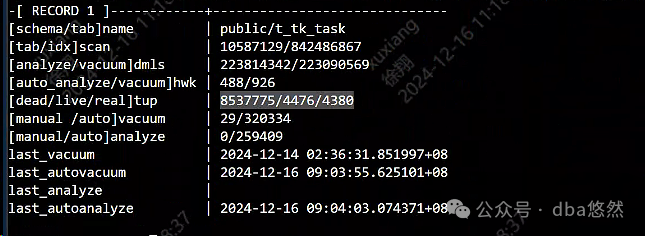
7)Autovacuum进程(3个)一直处于满负荷运行状态:

8)checkpoint刷脏页轻微频繁:
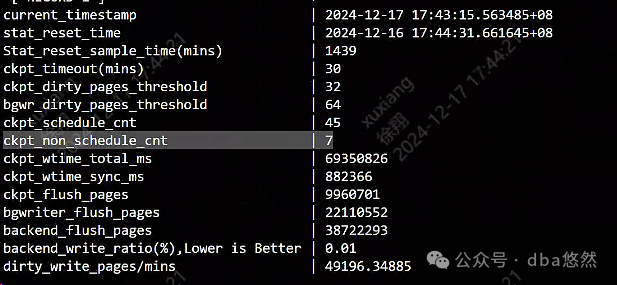
根据前面获取的信息分析,数据库问题主要集中在:
1.cpu/mem超负荷运转:
数据库全局缓慢,慢查询只是数据库慢的一个因素;
2.内存泄漏:
通过TOP进程跟踪,OS中部分TOP进程(cpu/mem)进程一直处于运行状态,而数据库中已无相关会话(截图未保存),是为僵尸进程;僵尸进程较多(700个多长dile进程),可以看到有内存泄漏,资源无法回收(操作系统hang)
3.业务运行期的备份操作:
copy会话备份:数据库繁忙导致备份时间拉长,备份操作从凌晨2点开始一直持续到第二天中午业务峰值,备份、业务互相抢占资源阻塞;
4.热点表(部分库表)膨胀非常严重:
热点表dml过于频繁,自上一次Autovacuum的2小时内生成800w死元组,而表本身只有几千条数据,过于频繁表DML膨胀带来诸多性能问题;
5.缺乏日常性维护:
数据库运行1年多,期间无例行巡检调优,导致部分库死元组过于膨胀积压、优化器性能低下
6.长连接/长事务:
7.参数配置不合理:
8.慢SQL全表扫描:
PART4:问题解决
参数调优
//服务器:16C64GB
shared_buffers 16GB
effective_cache_size 48GB->32GB
Checkpoint_timeout 20min->30min
autovacuum_max_workers 3->4
idle_in_transaction_session_timeout=600000
statement_timeout=9000000
synchronous_commit remote_apply->remote_write
max_parallel_workers_per_gather 0->2
2.全库级手动vacuum full维护:
业务低峰期vacuum full database,如果是pg系数据库,可使用pg_repack插件Online操作。
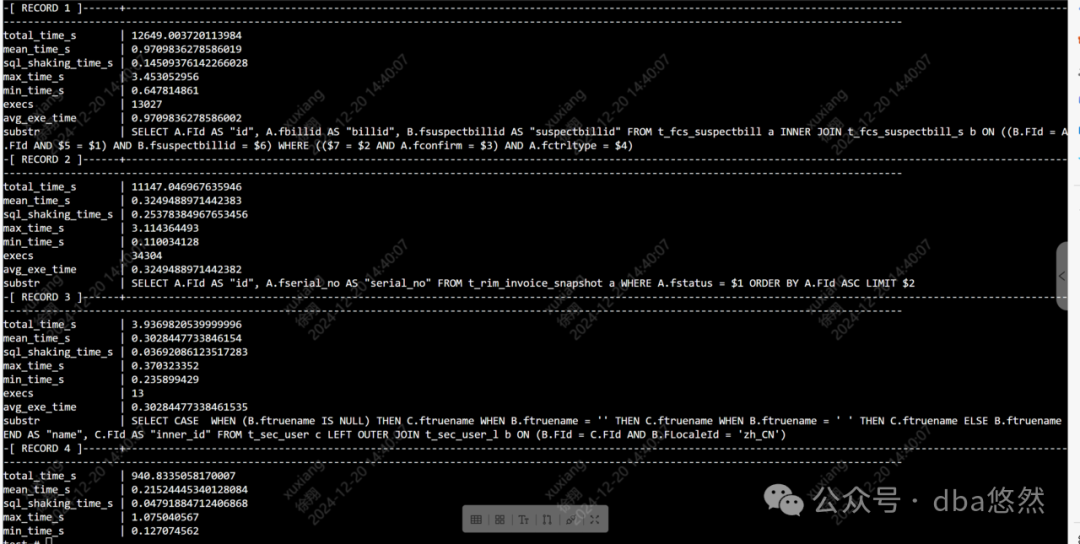
3.调整优化后效果:
1)数据库慢SQL在可控范围,TOP SQL执行平均1s内:
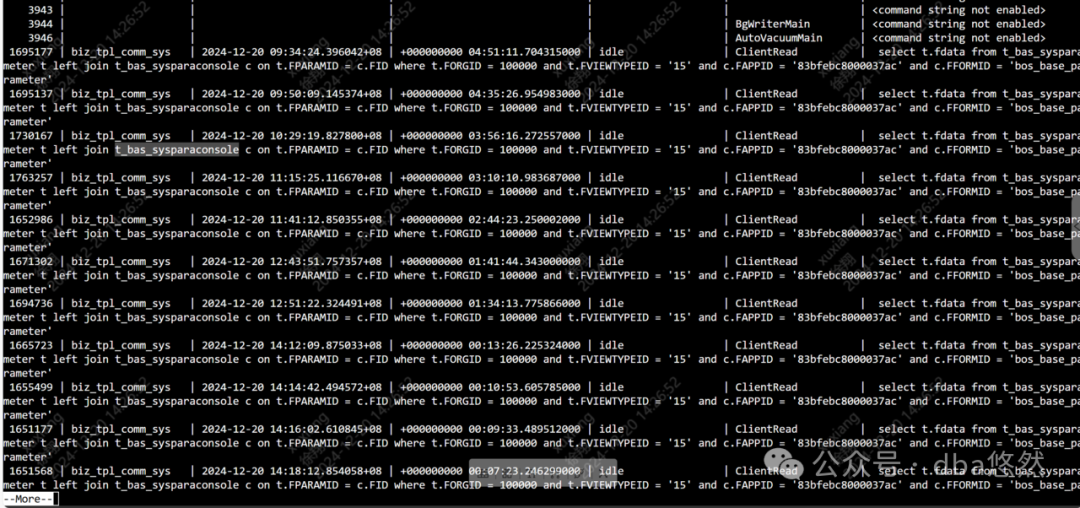
2)TOP会话基本正常:
4.下一步计划:
1)数据库进行适当扩容(16C64G->32C128GB);
2)巡检运维机制建设,确保业务稳定运行;
3)慢SQL治理,大表全表扫描调优。
PART5:故事结尾
通过这个故事,可以有哪些启发:
1)数据库/业务设计必须考虑过载保护:
对于一些较为成熟业的务系统,在上线前会进行全方位压测,甚至极限混沌测试,但是仍然不能cover所有场景:例如上线前预估1000并发,而实际上可能在某个突发场景(例如月结/年结等)并发直接暴涨到6000;这种突然性负载暴涨对于数据库/业务而言都是一场灾难;解决方案就是:在数据库侧小范围配置限流,而更多的工作则是考验业务系统的健壮性、韧性以及强壮性(过载保护、容错机制等)技术实现。
2)数据库投入要具有前瞻性:
例如预估需要16C64GB资源,可以适当预留(长远准备)资源,因为除了要考虑3~5年内业务负载增长以外,还需要考虑突发性负载暴增对于数据库的冲击,以及如何应对在负载暴增后的平滑扩容,从而保证业务连续性SLA。
如果觉得本文有所帮助或者启发,欢迎关注点赞收藏!!!。




oracle直方图了解多少?
