“采菊东篱下,
悠然现南山”。
晋·陶渊明


"作者: 悠然 | 首发公众号: dba悠然"
<温馨提示:以下内容仅代表个人观点>


最近有一段时间未更新公众号了,确实有点小忙(停更一段时间,“闭关了”);刚好遇到一个case,与大家一起分享下。

1.小楷

2.行书
欢迎对书法感觉兴趣的同学一起交流。
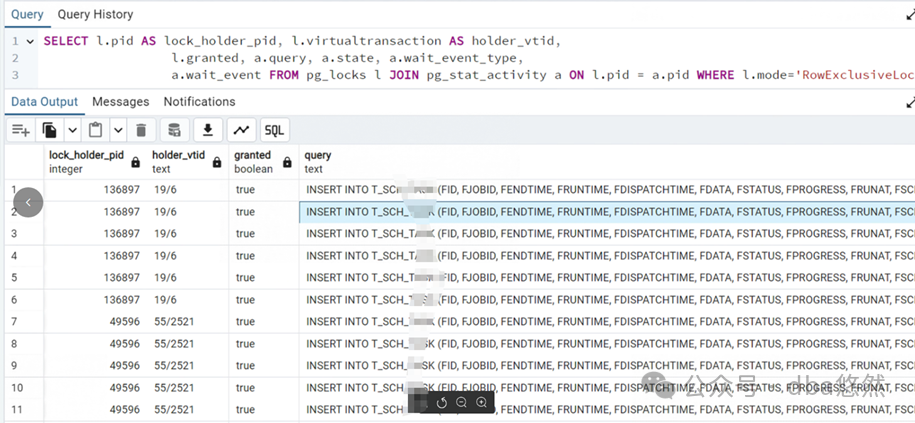
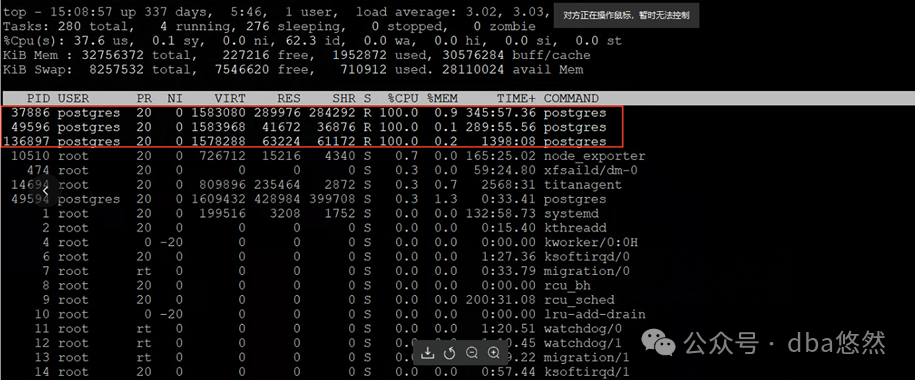
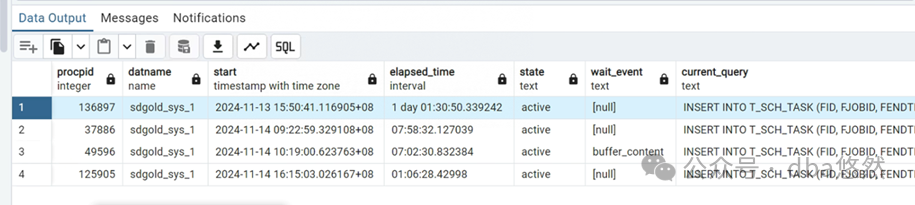
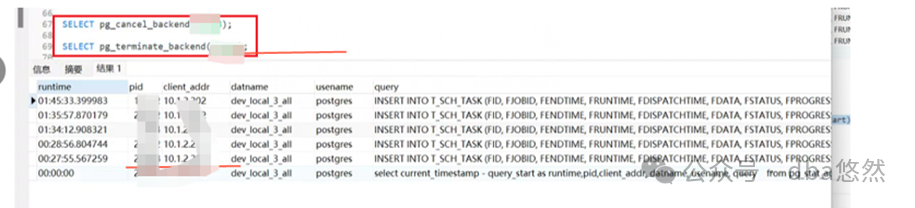
某客户PG环境Insert单表阻塞卡顿,整体负载较低,PG insert进程CPU使用爆满,重启问题依旧:

PART3:问题分析
(一) 环境(测试复现)
1.Insert进程足持续时间7小时~1days不等,状态”active”,其中某个进程等待事件为”buffer_content”:
2.等待”lock on a relation”
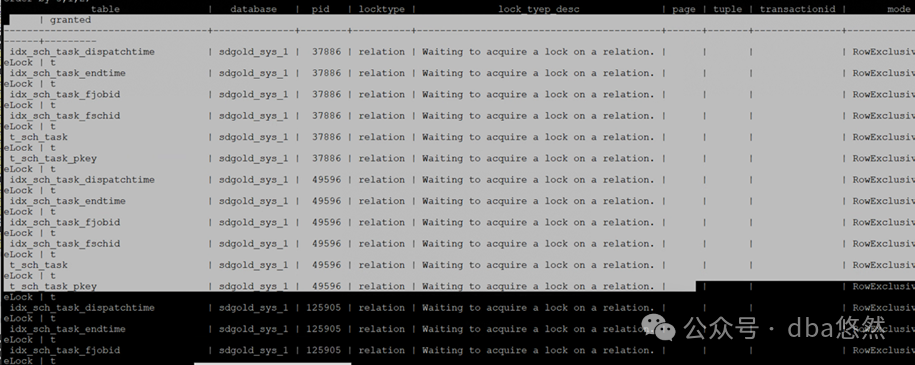
--查询锁blocking无阻塞(链、源),查询过程略
(二) 环境(测试复现)
表结构信息:
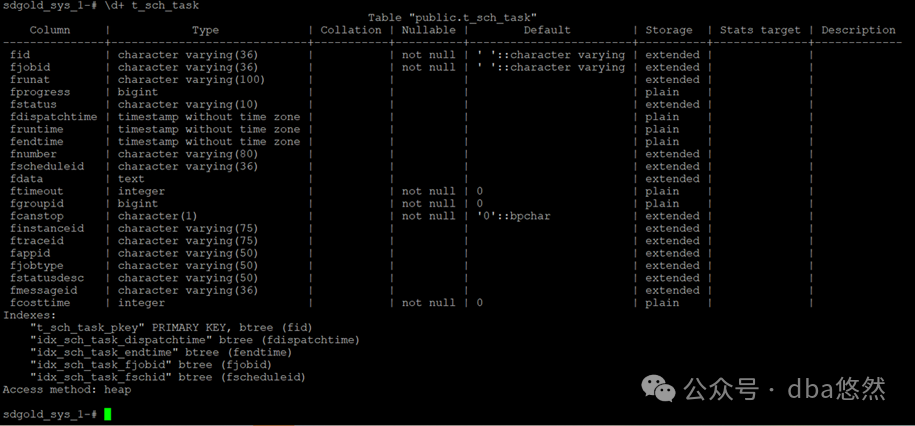
表包含一个主键及多个索引
2.数据库配置
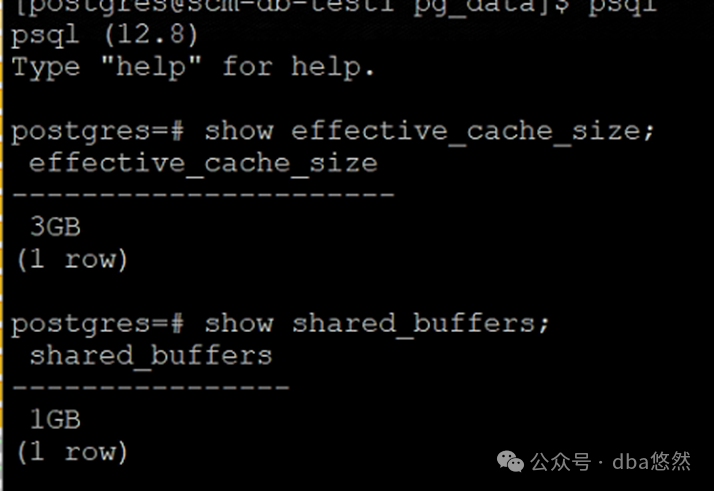
--其余配置略
3.表统计信息缺失(未截图)
(三) 问题定位
1. 尝试停pg_backend_pid终止Insert进程,进程无法终止(重启后仍然问题依旧)
2.Gstack&gdb打印堆栈
1) gastack打印堆栈等待”pg_statement.so”,无参考意义(无截图)
2)gdb调试出现”_bt”相关函数:_bt_relandgetbuf_bt_moveright()
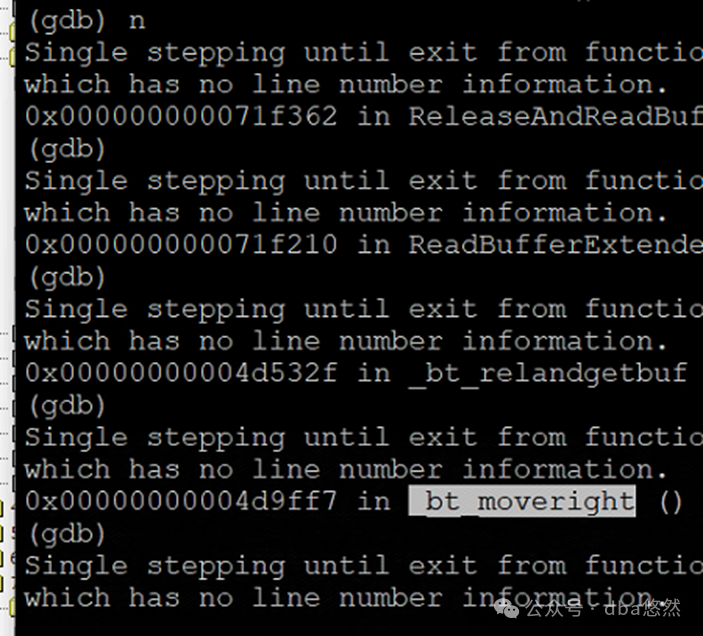
3)_split等待未保存截图
通过前面初步分析,可以初步定位问题聚焦在资源配置不足、autovacuum统计信息缺失以及Index索引问题
(一) 参数调优
//OS:8C32G
1.调节内存参数
Shared_buffers: 1GB->8GB
Effectibe_cache_size :4GB->16GB
2.调节超时限制
#设置idle事务超时10mins
idle_in_transaction_session_timeout=600000
#设置长连接超时2h
statement_timeout=7200000
3.停业务,重启pg
(二) Vacuumdb
考虑到资源配置严重不足,全局autovacuum无法完全完成,导致vacuum/analyze缺失,尝试vacuudb修复
1)Vacuumdb
-e :回显vacuum过程
-f :vacuum full
-j :jobs并行度
-v :verbose
-z :收集统计信息
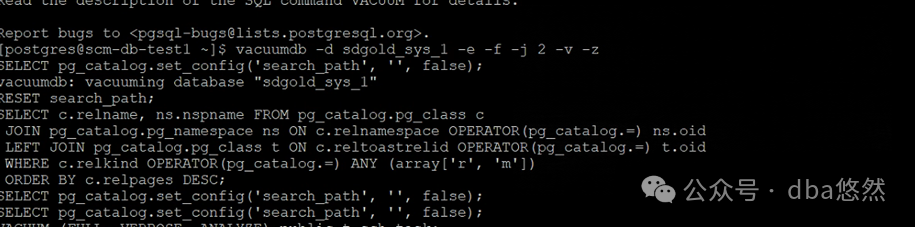
2)vacuumdb 锁定异常,长时间无法应
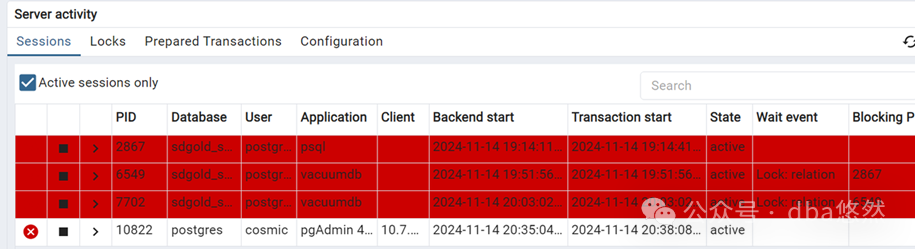
3)Vacuumdb死锁日志:
vacuumdb: error: vacuuming of database "sdgold_xx_1" failed: ERROR: deadlock detected DETAIL: Process 14887 waits for AccessShareLock on relation 1249 of database 592878; blocked by process 14888. Process 14888 waits for ShareLock on transaction 24162689; blocked by process 14887. HINT: See server log for query details.
4)尝试重建索引,再vacuumdb,问题解决:
reindex table txxx concurrently;
vacuumdb -d xx -e -f -j 2 -v -z ;
PART5:故障复盘分析
1.由于时间紧迫,问题分析(根据经验推断):
1)资源配置不足,shared_buffers/effective_cache_size过小,缓存写入机制index buffer不一致性(类似”坏块”, 等待buffer_content),导致索引插入分裂异常;
2)索引异常,插入数据索引分裂失败,”_bt_moveright”,Insert 进程hang(重启后insert仍然卡顿、无法terminate insert进程);
3)autovacuum/analzye触发却并未激活,资源配置不足的负面影响案例;
2.关于Autovacuum,有哪些启发:
2.1Autovacuum运行机制
/* autovacuum.c*/
Autovacuum Daemon主要包括2类进程:
-autovacuum launcher,由Postmaster进程启动,负责周期性(autovacuum_naptime)fork autovacuum worker进程完成vacuum
-autovacuum launcher维护autovacuum shared memory area全局数据库信息(need vacuum dbs/relations)
-autovacuum worker,autovacuum实际实行进程,数量由参数autovacuum_max_works控制
1)autovacuum launcher& autovacuum workers
-autovacuum launcher无法直接启动/控制worker进程,由Postmaster进程完成(参考附录postmaster.c):
-autovacuum launcher连接到shared memory,维护全局数据字典信息(记录哪些db,relation需要vacuum)
-worker进程只负责单个局部db vacuum,autovacuum launcher启动容易出现异常
2)autovacuum launcher& workers &shared memory area
-autovacuum launcher在autovacuum shared memory area记录了需要vacuum的db/relation信息
-当满足autovacuum条件时,autovacuum launcher通知postmaster进程fork worker进程进行vacuum
-新fork workers连接到autovacuum shared memory area,读取autovacuum launcher维护信息后,到指定db进行vacuum
-如果postmaster fork worker失败,则会在shared memory area记录flag;launcher周期性(scheduler)识别后,重新通知postmaster尝试fork woker
-当worker进程完成vacuum后,发送SIGUSR2到autovacuum launcher,autovacuum launcher根据vacuum_cost评估/负载均衡当前worker与正在运行的woker的负载,进行合理调度(延迟,削峰填谷等),参考附录rebalance()函数;
3)multi workers in one database
-当单个db需要vacuum负载较多时,该db可以同时并发运行多个worker进程均衡负载,vacuum
-并发workers冲突检测:wokers将自己当前vacuum对象写入shared memory area(hash 表),这样并行vacuum将不会出现互相阻塞
-每个workers读取pgstats统计的最后一次vacuum时间以及标记为vaccummed对象,从而跳过已经被vaccumed对象,避免重复vacuumed冲突
-BUG:并发worker重复vacuum:多workers并发vacuum场景未获取relation lock导致pgstat统计信息更新延迟,worker重复vacuum并行worker以及vacuumed的对象,Is bug.
/*
However, there is a small window (due to not yet
* holding the relation lock) during which a worker may choose a table that was
* already vacuumed; this is a bug in the current design.
*/
4)postmaster调用fork()失败原因(Autovacuum未触发原因)
-暂时性:high load, memory pressure, too many processes, etc
-持久性:数据库异常/数据量连接失败等
5)shared memory area
autovacuum launcher维护共享内存信息:
//涉及源码函数
relation_needs_vacanalyze()
autovacuum_do_vac_analyze()
.....
7)Autovacuum参数
postgres=# select name,setting,unit from pg_settings where name ~ 'autovacuum';
name | setting | unit
-----------------------------------------------+-----------+------
autovacuum | on | #开启autovacuum
autovacuum_freeze_max_age | 200000000 |
autovacuum_multixact_freeze_max_age | 400000000 |
autovacuum_max_workers | 3 | #launcher最多并发fork 3个workers,上线受制于(max_worker_processes)
autovacuum_work_mem | -1 | kB #-1表示等于maintenance_work_mem
autovacuum_naptime | 60 | s #demon休眠周期,默认值60s
log_autovacuum_min_duration | 600000 | ms #autovacuum日志记录阈值
.....
-autovacuum launcher进程周期性(autovacuum_naptime)启动autovacuum_worker
-默认周期60s(autovacuum_naptime)
-周期性启动3个workers(autovacuum_max_works)
-3个worker在不同db并发vacuum,如果db较多,则autovaccum workers忙不过来
2.2Autovacuum触发条件
1)当前txid_current到达阈冻结阈值(vacuum freeze,xid消耗过快)
txid_current >= {relfrozenxid + autovacuum_freeze_max_age}
-txid_current #当前事务transaction xid
-relfrozenxid #pg_class.relfrozenxid(relation表)
-autovacuum_freeze_max_age #autovacuum最大冻结年龄:默认20E(200000000)
2)死元组数量(n_dead_tup)到达阈值
n_dead_tup > = {autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor *reltuples }
-n_dead_tup #死元组tuples估算总量, pg_stat_all_tables.n_dead_tup
-autovacuum_vacuum_threshold #autovacuum死元组基础阈值,默认值50
-autovacuum_vacuum_scale_factor #autovacuum死元组可变因子0.2
-reltuples #元组总量,pg_class.reltuples
3)插入元组数量(n_tup_ins)到达阈值
n_tup_ins >= {autovacuum_vacuum_insert_threshold + autovacuum_vacuum_insert_scale_factor*reltuples
-n_tup_ins #插入元组tuples估算总量, pg_stat_all_tables.n_tup_ins
-autovacuum_vacuum_insert_threshold #autovacuum插入元组基础阈值,默认值1000
-autovacuum_vacuum_insert_scale_factor #autovacuum插入元组可变因子,默认值0.2
-reltuples #元组总量,pg_class.reltuples
4)统计更新元组达到阈值(PG13+)
n_mod_since_analyze >= {autovacuum_analyze_threshold + autovacuum_analyze_scale_factor*relputples}
-n_mod_since_analyze #最近一次Analyze更改(INSERT/DELETE/UPDATE)tuples,pg_stat_all_tables.n_mod_since_analyze
-autovacuum_analyze_threshold #autovacuum统计信息基础阈值,50
-autovacuum_vacuum_insert_scale_factor #autovacuum统计信息可变因子,默认值0.1
-reltuples #元组总量,pg_class.reltuples
//附录源码
src/backend/postmaster/launch_backend.c
child_process_kind child_process_kinds[] = {
[B_INVALID] = {"invalid", NULL, false},
[B_BACKEND] = {"backend", BackendMain, true},
[B_AUTOVAC_LAUNCHER] = {"autovacuum launcher", AutoVacLauncherMain, true},
[B_AUTOVAC_WORKER] = {"autovacuum worker", AutoVacWorkerMain, true},
[B_BG_WORKER] = {"bgworker", BackgroundWorkerMain, true},
*
* WAL senders start their life as regular backend processes, and change
* their type after authenticating the client for replication. We list it
* here for PostmasterChildName() but cannot launch them directly.
*/
[B_WAL_SENDER] = {"wal sender", NULL, true},
[B_SLOTSYNC_WORKER] = {"slot sync worker", ReplSlotSyncWorkerMain, true},
[B_STANDALONE_BACKEND] = {"standalone backend", NULL, false},
[B_ARCHIVER] = {"archiver", PgArchiverMain, true},
[B_BG_WRITER] = {"bgwriter", BackgroundWriterMain, true},
[B_CHECKPOINTER] = {"checkpointer", CheckpointerMain, true},
[B_STARTUP] = {"startup", StartupProcessMain, true},
[B_WAL_RECEIVER] = {"wal_receiver", WalReceiverMain, true},
[B_WAL_SUMMARIZER] = {"wal_summarizer", WalSummarizerMain, true},
[B_WAL_WRITER] = {"wal_writer", WalWriterMain, true},
[B_LOGGER] = {"syslogger", SysLoggerMain, false},
};
*/
//autovacuum launcher Fork启动AutoVacLauncherMain进程
//AutoVacWorkerMain()函数
AutoVacWorkerMain()
pgstat_report_autovac(dbid);
*
* Connect to the selected database, specifying no particular user
*
* Note: if we have selected a just-deleted database (due to using
* stale stats info), we'll fail and exit here.
*/
InitPostgres(NULL, dbid, NULL, InvalidOid, 0, dbname);
SetProcessingMode(NormalProcessing);
set_ps_display(dbname);
ereport(DEBUG1,
(errmsg_internal("autovacuum: processing database \"%s\"", dbname)));
if (PostAuthDelay)
pg_usleep(PostAuthDelay * 1000000L);
* And do an appropriate amount of work */
recentXid = ReadNextTransactionId();
recentMulti = ReadNextMultiXactId();
*启动autovacuum*/
//do_autovacuum
do_autovacuum();
}
*
* The launcher will be notified of my death in ProcKill, *if* we managed
* to get a worker slot at all
*/
* All done, go away */
proc_exit(0);
}
//workers rebanlance 负载
autovac_recalculate_workers_for_balance
*
* a worker finished, or postmaster signaled failure to start a worker
*/
if (got_SIGUSR2)
{
got_SIGUSR2 = false;
* rebalance cost limits, if needed */
if (AutoVacuumShmem->av_signal[AutoVacRebalance])
{
LWLockAcquire(AutovacuumLock, LW_EXCLUSIVE);
AutoVacuumShmem->av_signal[AutoVacRebalance] = false;
autovac_recalculate_workers_for_balance();
LWLockRelease(AutovacuumLock);
}
if (AutoVacuumShmem->av_signal[AutoVacForkFailed])
{
*
* If the postmaster failed to start a new worker, we sleep
* for a little while and resend the signal. The new worker's
* state is still in memory, so this is sufficient. After
* that, we restart the main loop.
*
* XXX should we put a limit to the number of times we retry?
* I don't think it makes much sense, because a future start
* of a worker will continue to fail in the same way.
*/
AutoVacuumShmem->av_signal[AutoVacForkFailed] = false;
pg_usleep(1000000L); * 1s */
SendPostmasterSignal(PMSIGNAL_START_AUTOVAC_WORKER);
continue;
}
}
PART6:结束语
如果觉得本文有所帮助或者启发,欢迎添加好友交流收藏,2024年我们一路同行!!!。
select 1 from dual;