“采菊东篱下,
悠然现南山”。
晋·陶渊明


"作者: 悠然 | 首发公众号: dba悠然"
<温馨提示:以下内容仅代表个人观点>


最近一年主要在做信创适配的事情,经POC测试发现,大多数数据库性能还是很是拉胯,尤其是在业务相对比较复杂的HTAP混合场景下,传统OLTP数据库在OLAP还需要发力。上个月最终完成了OceanBase发版,适配期间槽点太多,优化了一大堆慢SQL,借此机会吐槽一下。

//OB:4.2.3企业版本,Oracle租户模式
慢SQL
慢SQL由2张大表组成,数据量分别为5kw和3kw,使用in..list(900个)对5kw大表过滤,最后再join,如下(仅保留关键部分):
SELECTA.FId "VOUCHERID",B.FEntryId "FENTRYID",A.Fbookeddate "DATEFIELD",A.FPERIODID "PERIOD",....FROMT_GL_VOUCHER AINNER JOIN T_GL_VOUCHERENTRY B ON (((B.FId = A.FIdAND 1 = 1)AND B.forgid = 100000007611)AND B.fperiodid = 120210070)INNER JOIN T_TRMP_VOUCHERID C ON C.fid = B.fassgrpidWHERE((((A.fbillstatus IN ('A', 'C'))AND A.forgid = 100000007611)AND A.fbooktypeid = 237528347981256704)AND (((((B.faccountid IN (1038187913998789632,1038187919770151936,--900in...1038188112490032128,1038188118731155456))AND 1 = 1)AND A.FPERIODID = 120210070)AND 1 = 1)AND 1 = 1))AND ROWNUM <= 100001
2.大表数据量分别为2497w和4994w

3.表列及join key数据分布
表A--ndv--T_GL_VOUCHER "PK_GL_VOU_AC27C87E" PRIMARY KEY ("FID"):2496wA.FId --pk:2496wA.forgid = ? --20A.fbooktypeid = ? --20A.FPERIODID = 120210070 --24A.fbillstatus IN (?, ?) --3表B-- T_GL_VOUCHERENTRY "PK_GL_VOU_70484440" PRIMARY KEY ("FENTRYID") :4900w--ndvB.FId --24914371B.forgid = ? --20B.fperiodid = 120210070 --24B.fassgrpid = --37414B.faccountid --481JOIN KEY:B.FId = A.FId
4.表列索引信息,2张大表均有索引:
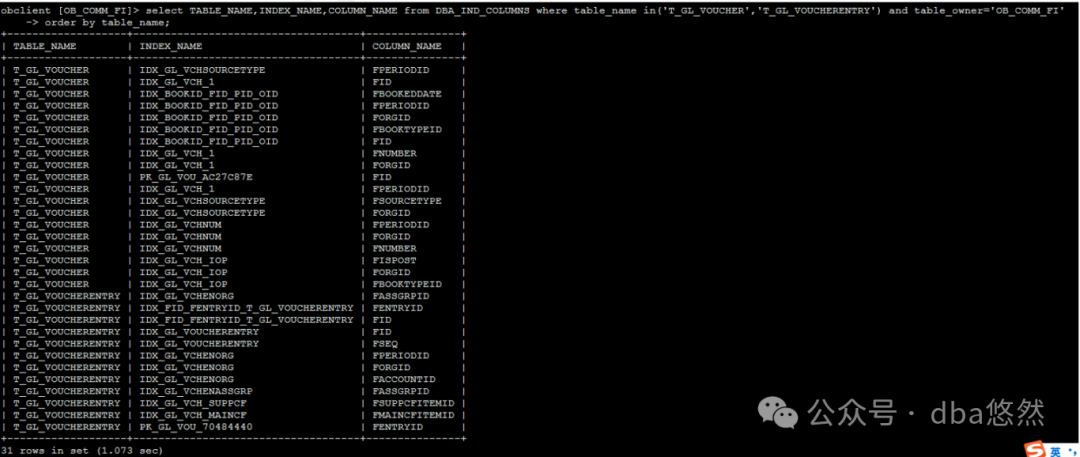
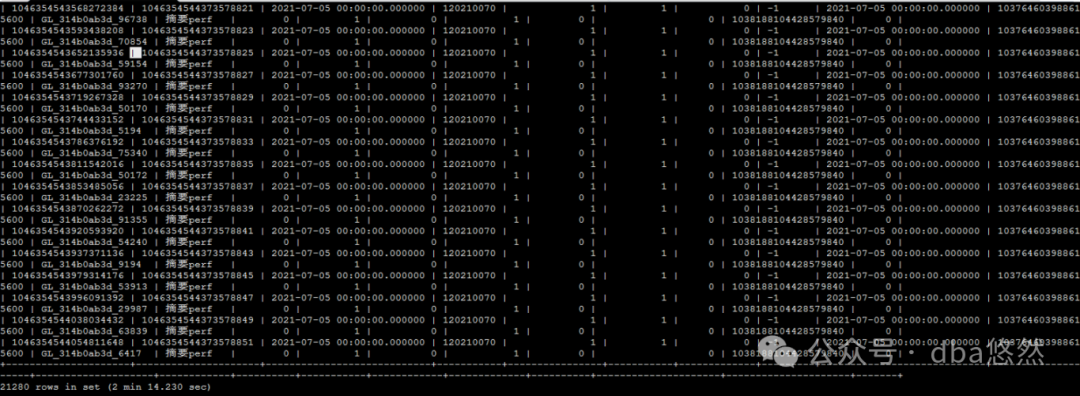
5.SQL执行(2min14s),执行计划:
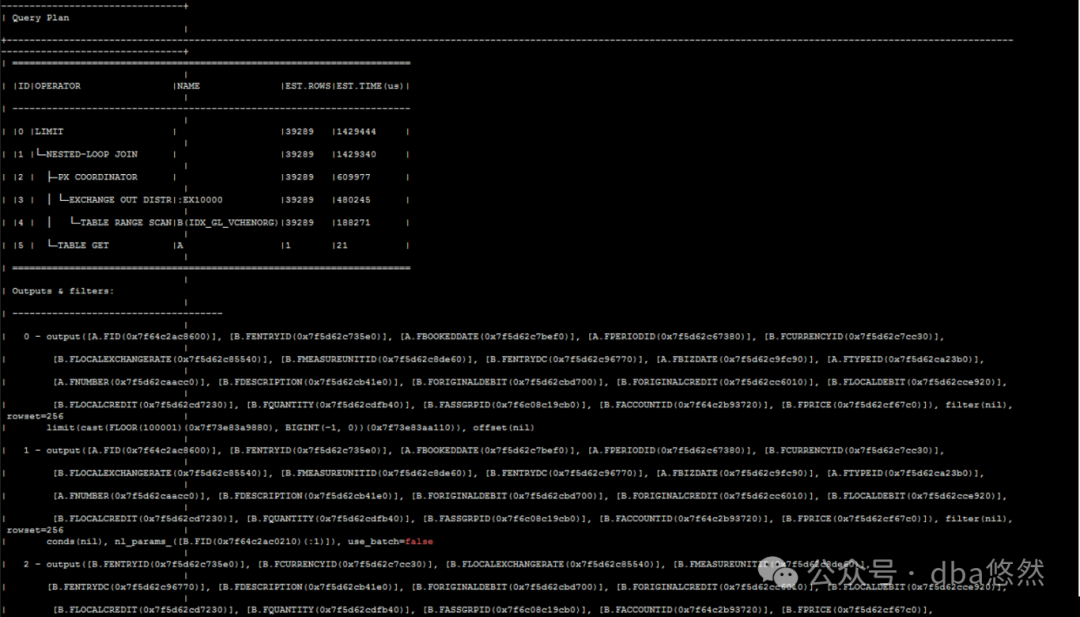
说明:B表(4900w)过滤列选择性较低,使用全表驱动A表进行NL JOIN,性能慢的离谱:
2:调优
1.性能分析
有经验的同学基本可以看到慢SQL存在以下问题:
1)大表驱动小表
2)大表关联使用NL JOIN
3)Filter列选择性低
4)索引全覆盖优化空间有限
5)全表扫描IO吞吐量大
6)回表字段多
7)大表in..list性能消耗
8)Auto DOP带来额外影响
9)索引多,存在干扰影响优化器判断
2.优化思路:使用hint控制优化器行为,SQL如下:
SELECT /*+LEADING(C,B) USE_HASH(B,A) PARALLEL(16)*/A.FId "VOUCHERID",B.FEntryId "FENTRYID",A.Fbookeddate "DATEFIELD",A.FPERIODID "PERIOD",....FROMT_GL_VOUCHER AINNER JOIN T_GL_VOUCHERENTRY B ON (((B.FId = A.FIdAND 1 = 1)AND B.forgid = 100000007611)AND B.fperiodid = 120210070)INNER JOIN T_TRMP_VOUCHERID C ON C.fid = B.fassgrpidWHERE((((A.fbillstatus IN ('A', 'C'))AND A.forgid = 100000007611)AND A.fbooktypeid = 237528347981256704)AND (((((B.faccountid IN (1038187913998789632,1038187919770151936,--900in...1038188112490032128,1038188118731155456))AND 1 = 1)AND A.FPERIODID = 120210070)AND 1 = 1)AND 1 = 1))AND ROWNUM <= 100001
3.执行计划
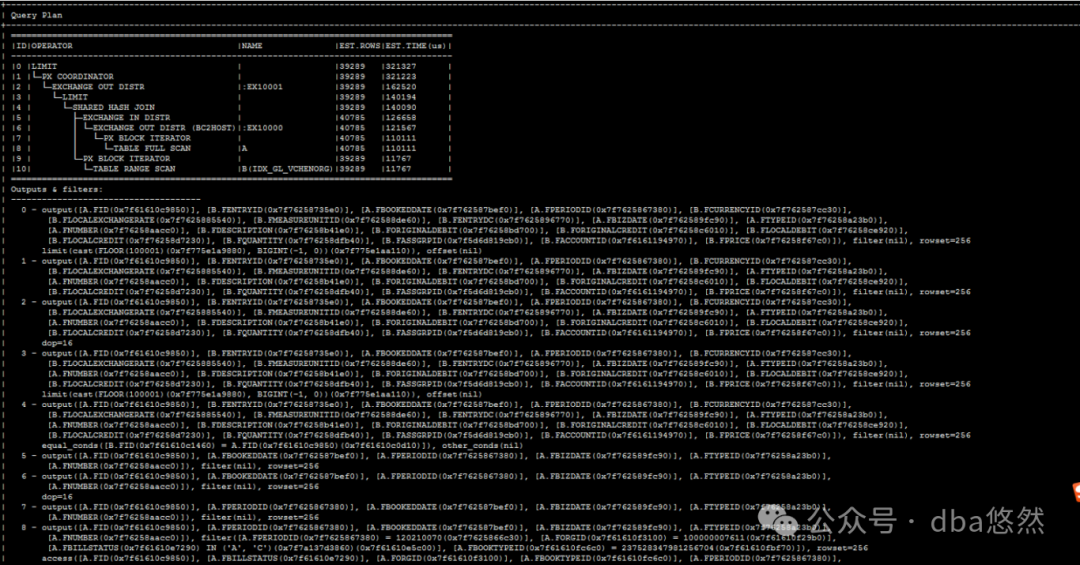
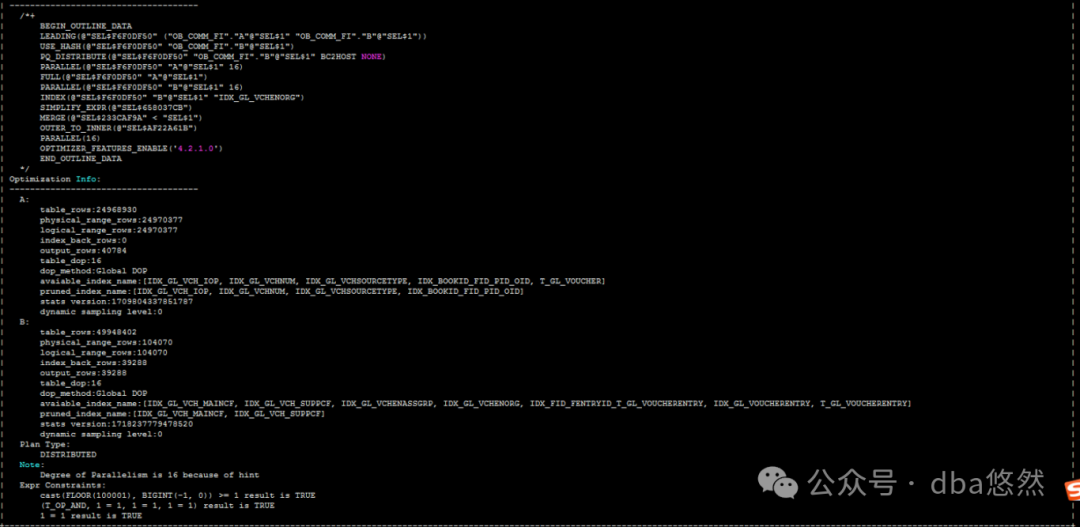
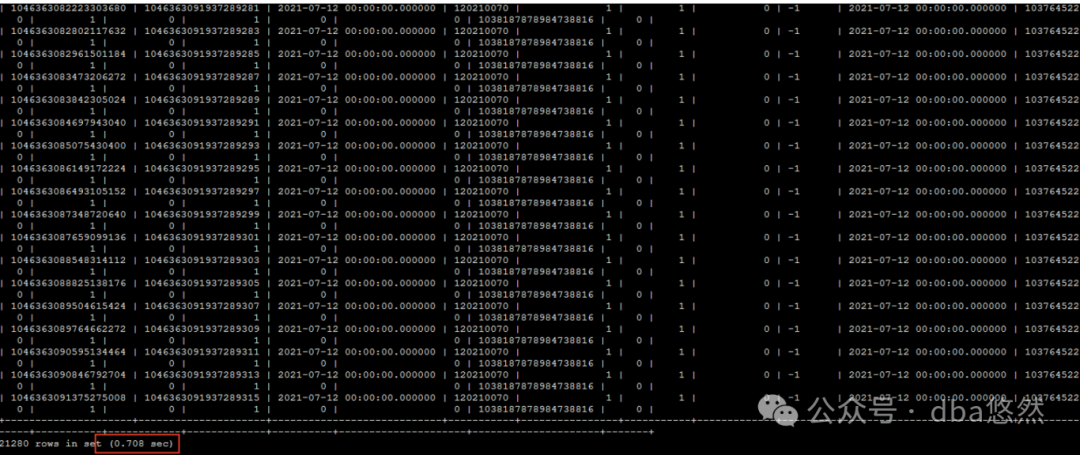
可以看到:SQL执行缩短到0.708s,性能提升130倍,直接起飞。
3:调优完成了?
SQL性能起飞了,此时也许很多同学会觉得优化已经完成了,而我想告诉大家的是,实际问题远远没有这么简单!!!
还原真实的业务场景:大表B.faccountid in..list传参值是不定的,表现在:
1)传参in值是变化的
2)传参in..list数量也是不定的,少则几百个,多则近万个
带来的问题:in的不确定性导致优化器认为每一个SQL都不是唯一的,无法共享plan cache。如果要保持高性能,比较极端的办法就是对每个SQL加hint,怎么在程序端加(估计研发人员会找你拼命),如何加?
也许有的同学可能想到使用outline,确实outline可以固化执行计划,但是由于in..list不确定性,会生成无数个sql_id,使用outline如何根据sql_id去绑定,穷举也穷举不完。
4:“柳暗花明”
前面我们提到,可以使用outline绑定,但前提是得让优化器认为传入的in..list是一个固定长度的字符串(带有?占位符)的格式(类似Oralce绑定变量),这样md5生成的sql_id就唯一了,outline可以绑定。如何实现,且看下面的“骚”操作(重构):
使用table()函数替换in..list,table()函数中传入的函数可以传参控制in..list长度及变量;
创建table()函数的传参函数:f_get_VOUCHER
--表变量替换in--使用outline--创建传参函数f_get_VOUCHER--T_TRMP_VOUCHERID(id number(19));create or replace type type_VOUCHERID as object(fid number(19));create or replace type t_VOUCHERID as table of type_VOUCHERID;create or replace function f_get_VOUCHER(n in number default 0)return T_VOUCHERIDiscursor c is select * from T_TRMP_VOUCHERID where rownum<=n;v_VOUCHERID T_VOUCHERID;beginv_VOUCHERID:=T_VOUCHERID();for i in c loopDBMS_OUTPUT.PUT_LINE(c%ROWCOUNT);--DBMS_OUTPUT.PUT_LINE(i.fid||':'||c%ROWCOUNT);--v_1:= v_VOUCHERID(c%ROWCOUNT).fid;--select i.fid into v1 from dual;v_VOUCHERID.extend;v_VOUCHERID(c%ROWCOUNT).fid := i.fid;end loop;return v_VOUCHERID;end f_get_VOUCHER;/
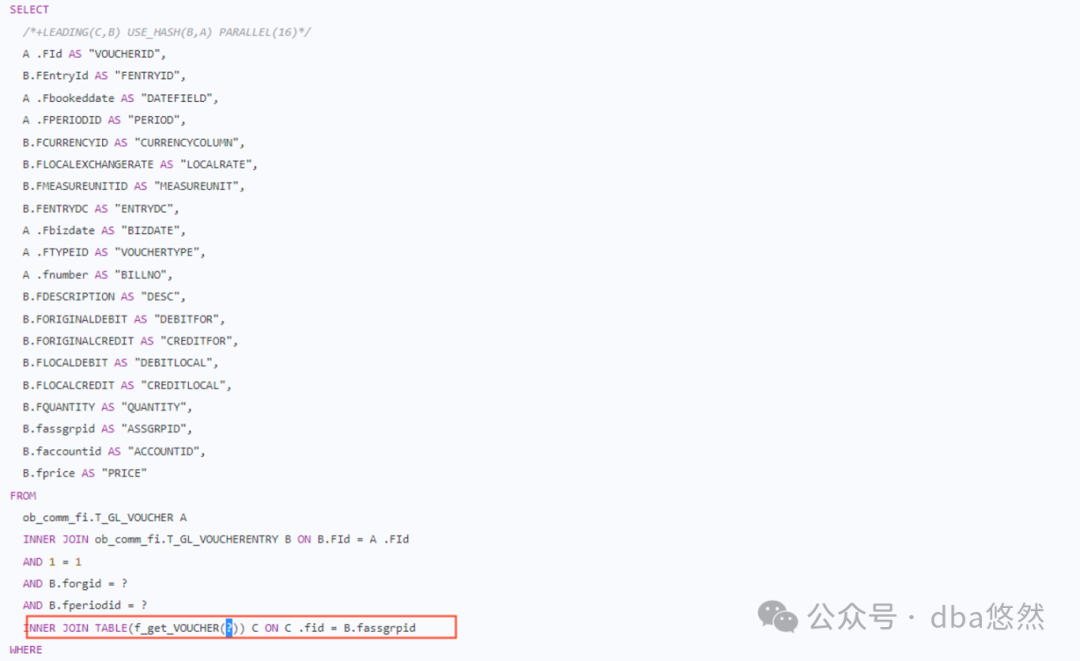
3.使用table()函数替换in,将原SQL in..list转换为JOIN:
SELECT /*+LEADING(C,B) USE_HASH(B,A) PARALLEL(16)*/A.FId "VOUCHERID",B.FEntryId "FENTRYID",A.Fbookeddate "DATEFIELD",A.FPERIODID "PERIOD",....FROMT_GL_VOUCHER AINNER JOIN T_GL_VOUCHERENTRY B ON (((B.FId = A.FIdAND 1 = 1)AND B.forgid = 100000007611)AND B.fperiodid = 120210070)INNER JOIN table(f_get_VOUCHER(3000)) C ON C.fid = B.fassgrpidWHERE((((A.fbillstatus IN ('A', 'C'))AND A.forgid = 100000007611)AND A.fbooktypeid = 237528347981256704)AND (((((B.faccountid IN (select fid from table(f_get_VOUCHER(2000))))AND 1 = 1)AND A.FPERIODID = 120210070)AND 1 = 1)AND 1 = 1))AND ROWNUM <= 100001
4.查看table()函数执行效果:
可以看到,TABLE函数(f_get_VOUCHER(?))函数将通过n控制传参,n被优化器使用?占位,优化器生成的sql_id可以唯一化进行outline绑定。
5.绑定唯一化sql_id后outline
select sql_id ,query_sql from gv$ob_sql_audit where trace_id='YB42AC11E60E-00061425FBAED0BC-0-0' and sql_id='79B1A019A1384DFEF7468AADD43AA000’SELECT sql_id, plan_id, outline_id,statement, outline_data FROM gv$ob_plan_cache_plan_stat where sql_id='79B1A019A1384DFEF7468AADD43AA000’CREATE OUTLINE outline_GL_VOUCHER_JOIN ON '79B1A019A1384DFEF7468AADD43AA000' USING HINT /*+LEADING(C,B) USE_HASH(B,A) PARALLEL(16)*/ ;
6.查看outline绑定

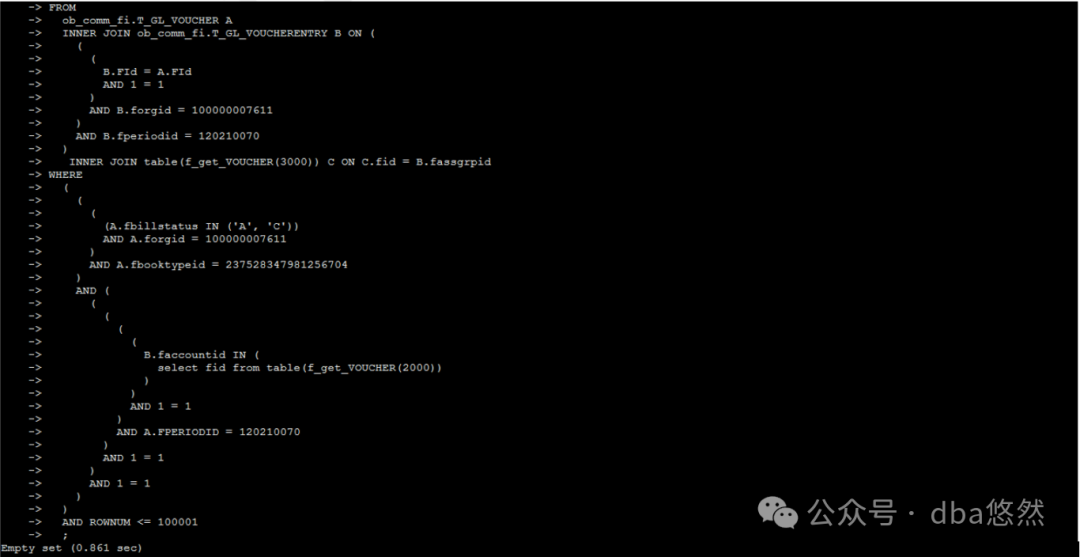
7.查看最终SQL执行效果:0.861s,且不受in传参变化长度影响,提升最终优化完成。
5:吐槽一下
至此,优化终于告一段落,但是有些槽不吐不快:
1.OB内核基于MySQL,NL JOIN(B+树)存在硬伤(躺枪者不关我事,可以参考本文“骚”操作优化);
2.从OB优化器的表现来看,优化器在自动最优选择最优执行计划时候还不是那么智能,国产化信创还需要努力;
3.OB服务确实很一般,遇到性能问题几乎就只会让增加硬件资源(可能是客服是外包),业务上的性能瓶颈完全得靠自己搞定,难道要加钱才能提供高端服务?听说原厂工时费用较高,如果是这样就可不难理解,但是我个人不太喜。

4.值得夸赞的是,某厂商全程现场POC调试支持,甚至直接现场修改优化器调试,服务不可谓不好。真心希望其同行们认真学习一下,真正理解客户是“衣食父母”。
6:文章末尾
如果有需要OB参数调优或行业实践资料的同学,可以关注公众号加好友获取(见后续连接)。
温馨提示:如果觉得本文有所帮助或者启发,欢迎添加好友交流收藏,2024年我们一路同行!!!

 。
。