“采菊东篱下,
悠然现南山”。
晋·陶渊明



"作者: 悠然 | 首发公众号: dba悠然(orasky666)"
<温馨提示:以下内容仅代表个人观点>




您在数据迁移时是否遇到这样痛点?:
1)手头没有好用的迁移工具(白嫖)
2)厂商暂不支持相关数据库类型迁移
3)厂商护城河不支持别家厂商数据库迁移
4)数据量太大干不动,迁移一点数据就噶了
5)迁移效率太低,一丁点数据要迁移半天
6)迁移工具无自动断点续传,网络一抖动就回到解放前
带着这些问题,今天为大家分享一款数据迁移神器DataX,希望在数据迁移时能帮得上忙,同时也是为上一篇文章补坑。

PART1:引言
笔者最近一段时间接触了较多的信创项目,在研究Datax工具前,异构数据库迁移是令人头疼甚至抓狂的事情。虽然有自研迁移工具,但是坑特别多,除了前面列举的痛点以外,还有其一些印象特别深场景:例如好不容易花了几十个小时迁移了几万张表的一部分,突然迁移工具OOM死机了,活白干了;这个时候选择继续肝重试,然而又出现其他问题导致迁移任务异常终止,这时您是否有口吐芬芳的冲动?
“为伊消得人憔悴”。此时此景,如果您的心情和我一样糟糕,这时请别慌,DataX它来了。
PART2:关于DataX
简单介绍一下今天主角Datax,DataX是一款强大的开源离线数据同步工具(https://github.com/alibaba/DataX),支持几乎所有的数据库类型以及异构数据库之间的迁移同步。
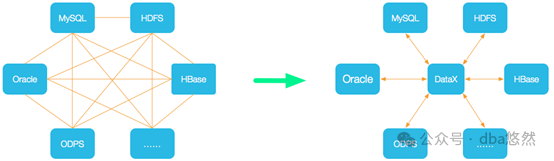
从源码来看,Datax主要包括reader方法从源端读取数据,writer方法写入数据到目标端,每个reader/writer方法支持一个类型的数据库,可以根据需要更换驱动支持不同的数据库类型,如下所示:
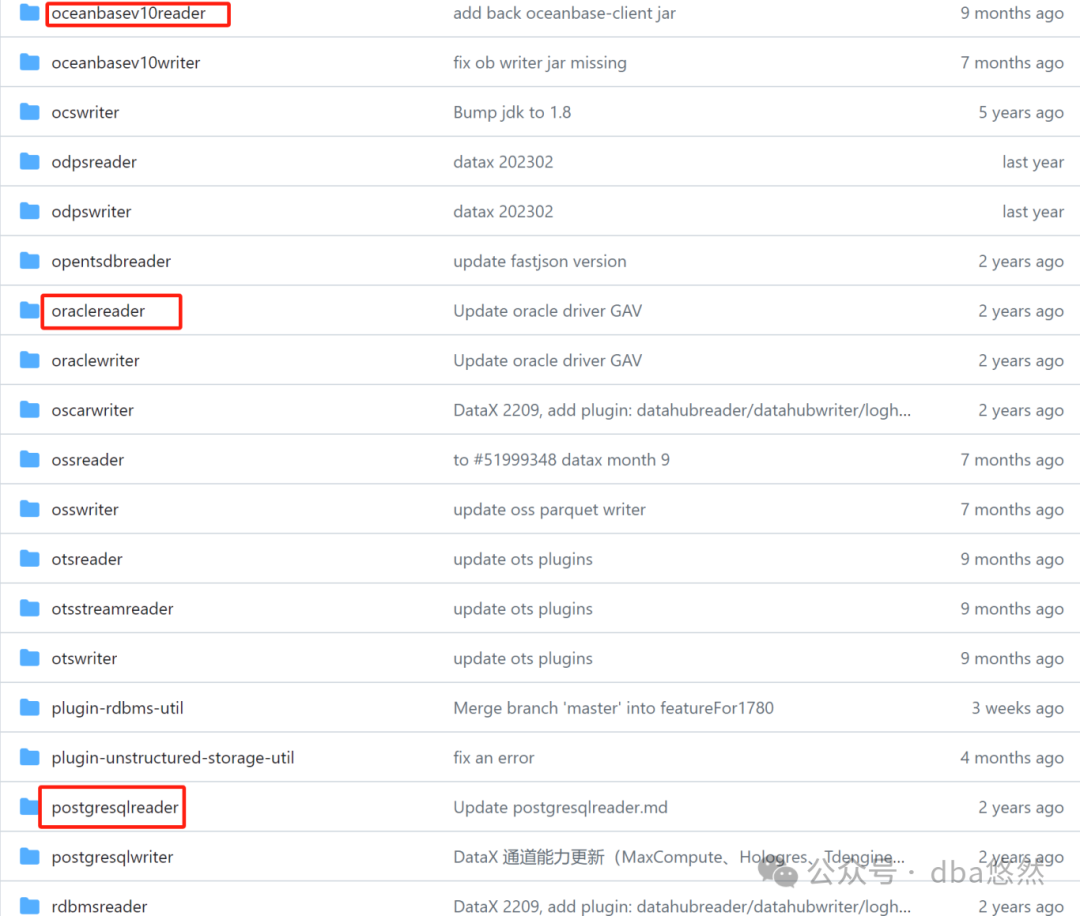
PART3:DataX使用指南
DataX环境准备(安装部署略):
--JDK1.8+
--Python2.7
避坑指南(附最佳实践):
--DataX目前只支持单表同步
--源目标端jdbc URL需要调优,否则容易连接超时终止任务
--DataX迁移大数据容易OOM,JVM启动参数需要调优
--DataX配置文件调优(由于篇幅原因,部分参数仅有注释)
配置文件datax.json
//从pg迁移数据到oceanbase:{"job": {"setting": {"speed": { #迁移速度设置"channel": 16,"bytes": 10737418240, #10GB},"errorLimit": { #脏数据控制"record": 10000, #"percentage": 0.1}},"content": [{"reader": {"name": "postgresqlreader", #pgreader驱动,读取源端pg数据库"parameter": {"username": "cosmic","password": "allnewpasswd#2024","column": ["*"],"connection": [{"table": ["t_ar_finarbillentry"],"jdbcUrl": ["jdbc:postgresql://172.17.32.68:5432/biz_tpl_big_fi"]}]}},"writer": {"name": "oceanbasev10writer", #obwriter驱动,写入OceanBase数据库"parameter": {"obWriteMode": "insert","username": "ob_comm_fi@KdOracle#kdcluster","password": "ob_comm_fi","writerThreadCount": 5,"batchSize": 10000, #批量10000"useObproxy": true,"column": ["*"],"connection": [{"jdbcUrl": "jdbc:oceanbase://172.17.230.11:2883/ob_comm_fi?useLocalSessionState=true&allowBatch=true&allowMultiQueries=true&rewriteBatchedStatements=true&useCursorFetch=true","table": ["t_ar_finarbillentry"]}]}}}]}}
4.配置优化
1)jdbc超时设置(24h)//net_write_timeout=86400 #目标端net_read_timeout=86400 #源端, 按需配置--源端pg"jdbc:postgresql://172.17.32.68:5432/biz_tpl_big_fi?net_read_timeout=86400"--目标端ob"jdbcUrl": "jdbc:oceanbase://172.17.230.11:2883/ob_comm_fi?useLocalSessionState=true&allowBatch=true&allowMultiQueries=true&rewriteBatchedStatements=true&useCursorFetch=true&net_write_timeout=86400",2)JVM优化设置设置运行时JVM内存为8G(根据实际情况调节),默认配置比较小容易OOMpython datax.py --jvm="-Xms8G -Xmx8G -XX:-UseGCOverheadLimit" datax.json > datax.log &3)解决只能迁移单表问题多表需要定制脚本实现(注意脚本串行执行),如下:--3.1)创建表列清单,将需要同步的表写入配置table_list.txtT1T2T3--3.2)配置批量脚本batch_datax.sh,如下#!/bin/bash#Author:BoLeng#Date:2024/04/18#Purpose:Batch datax sync serialize running#"TABLE_NAME" as input#"table": ["TABLE_NAME"]#for table in `cat table_list.txt`dodt=$(date +'%F %H:%M:%S')#echo ${table}cat datax.json |sed 's/TABLE_NAME/'"${table}"'/g' > datax_${table}.json#Doing data sysncecho "---------------------------------------------"echo "Now time is :${dt}"echo "Begin sync table : ${table}......"python datax.py datax_${table}.json --jvm="-Xms8G -Xmx8G -XX:-UseGCOverheadLimit" > datax_${table}.logif [ $? -eq 0 ];thenecho "Succeed table: ${table} !"elseecho "Failed table :${table}!"fidone#End bacth_datax.sh
5.使用方法:
--sh batch_datax.sh开始执行并打印同步表日志
--查看当前同步表进展状态
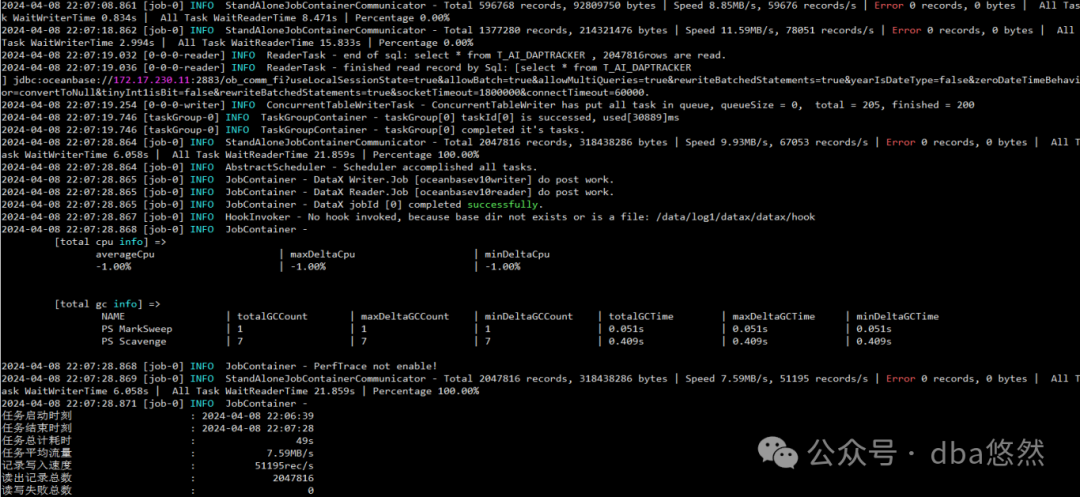
备注:上图仅为参考,经测试DataX实际上最高迁移速度可达10w+rows/s,迁移性能几乎可以追上DataPump。
PART3:结束语
值得一提的是:目前DataX工具只能进行数据迁移,因此在数据迁移前,需要将表结构等元数据同步到目标端。
好了,关于DataX就分享到此,如在使用过程中有疑问,请联系我!