




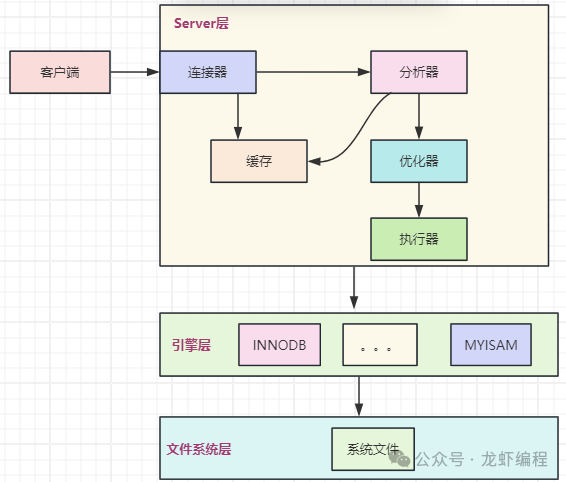
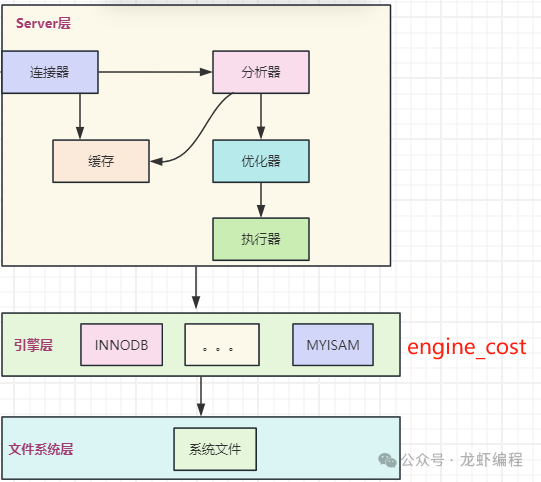
Mysql的架构我们都知道它是分为服务层、引擎层和文件系统层,其架构图如下所示:
一条完成的sql执行流程图如下所示:
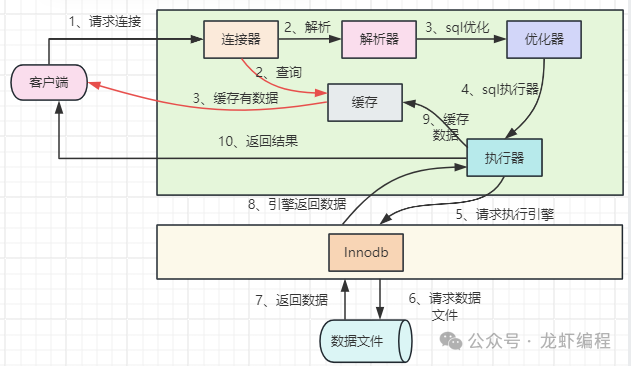
优化器组件根据sql的结构生成不同的执行计划,执行器最终选择最优或者执行效率最高的执行计划执行sql并返回数据。那么这个最优的执行计划是如何选择的呢?
1、初识Mysql的执行计划
创建表(order)的信息如下所示:
CREATE TABLE `order` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',`user_id` bigint NOT NULL COMMENT '用户id',`order_id` bigint NOT NULL COMMENT '订单id',,`num` int DEFAULT NULL COMMENT '订单数量',,PRIMARY KEY (`id`),KEY `idx_userId` (`user_id`) COMMENT '用户id索引') ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
添加测试数据:
(1)使用二级索引的执行计划
执行sql如下所示:
EXPLAIN format = tree SELECT * from `order` where user_id = 1234;
sql的执行结果如下所示:
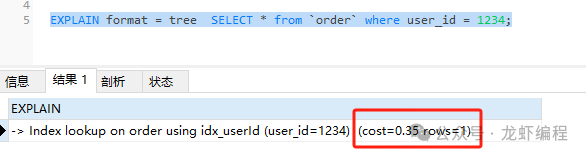 执行结果中的cost=0.35,Mysql认为我们当前的sql执行的成本是0.35。
执行结果中的cost=0.35,Mysql认为我们当前的sql执行的成本是0.35。
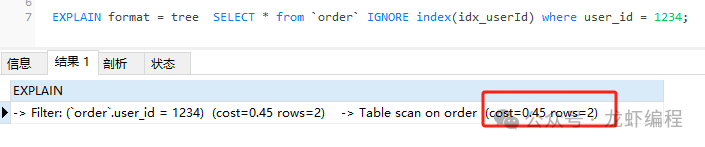
(2)禁用二级索引的执行计划
执行忽略二级索引的sql如下所示:
EXPLAIN format = tree SELECT * from `order` IGNORE index(idx_userId) where user_id = 1234;
执行的结果如下所示:
(3)查询最终的sql执行计划
EXPLAIN SELECT * from `order` where user_id = 1234;
执行的结果如下所示:

通过上面的分析我们可以得知道sql:
SELECT * from `order` where user_id = 1234;
可以生成两条执行计划,一个是走索引(idx_userId)的执行计划,另一个是全表扫描的执行计划,并且通过sql分析我们发现两者的cost值不一样的,cost的值如下所示:
| 执行方式 | cost |
| 索引执行计划 | 0.35 |
| 全表扫面执行计划 | 0.45 |
然后Mysql就选择cost最小的执行计划来执行我们的sql。
2、Mysql选择执行计划的原理
Index lookup on order using idx_userId (user_id=1234) (cost=0.35 rows=1)
cost = io_cost + engine_cost = 0.35
io_cost
IO的传输成本,如MyISAM、InnoDB存储引擎都是将数据和索引都存储到磁盘上的,当客户端查询表中的记录时需要先把数据或者索引加载到内存,从磁盘加载到内存的过程损耗的时间称之为IO成本。
engine_cost(存储引擎扫描的成本)
数据在查询出来之后,存储引擎需要进一步进行对比然后返回到服务层,如下图所示:
一个查询语句的执行要经过server层和存储引擎层,这两层在Mysql中对应了不同的常数表,以Mysql8.0.39为案例介绍,如下所示:
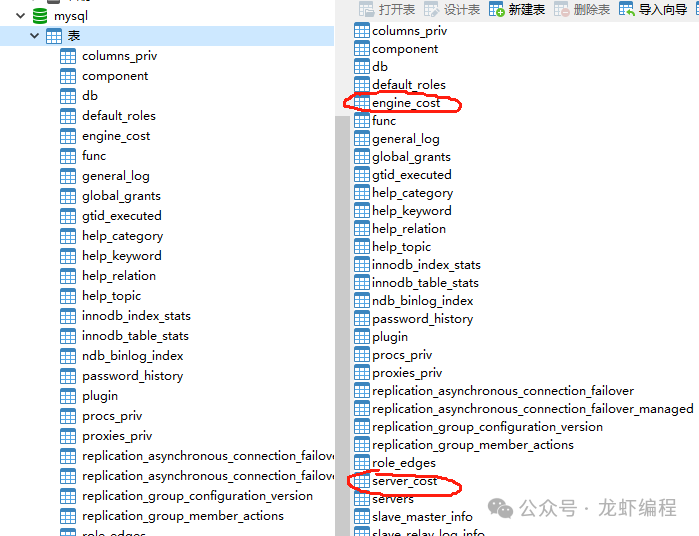
server_cost是server层成本参数表,表字段和数据如下所示:
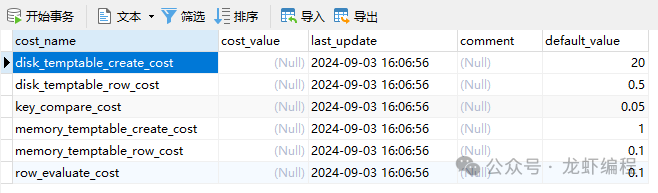
disk_temptable_create_cost:默认值是20,表示创建基于磁盘的临时表的成本,如果增大这个值会让优化器尽量少的创建基于磁盘的临时表。
disk_temptable_row_cost:默认值0.5,向基于磁盘的临时表写入或读取一条记录的成本,如果增大这个值就会让优化器尽量少的创建基于磁盘的临时表。
key_compare_cost:默认值0.05,两条记录做比较操作的成本,多用在排序操作上,如果增大这个值的话会提升filesort的成本,让优化器可能更倾向于使用索引完成排序而不是filesort。
memory_temptable_create_cost:默认值 1.0,创建基于内存的临时表的成本,如果增大这个值的话会让优化器尽量少的创建基于内存的临时表。
memory_temptable_row_cost:默认值0.1,向基于内存的临时表写入或读取一条记录的成本,如果增大这个值的话会让优化器尽量少的创建基于内存的临时表。
row_evaluate_cost:检测一条记录是否符合搜索条件的成本,不管读取记录时需不需要检测是否满足搜索条件,即使是空数据,其成本都算是0.1。
engine_cost是存储引擎层的参数表,表字段和数据如下所示:

io_block_read_cost:默认值 1.0,从磁盘上读取一个块对应的成本。对于 InnoDB存储引擎来说,一个页就是一个块,不过对于MYISAM 存储引擎来说,默认是以 4096 字节作为一个块的。
memory_block_read_cost: 默认值0.25, 衡量的是从内存中读取一个块对应的成本。
无论是engine_cost表还是server_cost表中的字段对应的值,都是可以根据实际需要进行重新设置的。
有了这些表的数据的记录之后,我们使用json方式查询信息更为全面的执行计划返回的情况,如下所示:
EXPLAIN format = json SELECT * from `order` IGNORE index(idx_userId) where user_id = 1234;
执行的结果:
{"query_block": {"select_id": 1,"cost_info": {"query_cost": "0.45"},"table": {"table_name": "order","access_type": "ALL","rows_examined_per_scan": 2,"rows_produced_per_join": 2,"filtered": "100.00","cost_info": {"read_cost": "0.25","eval_cost": "0.20","prefix_cost": "0.45","data_read_per_join": "64"},"used_columns": ["id","user_id","order_id","num"],"attached_condition": "(`longxia`.`order`.`user_id` = 1234)"}}}
rows_examined_per_scan:查询一次全表扫面的行数
rows_produced_per_join:扇出数量
query_cost:查询总成本
cost_info:成本明细信息
prefix_cost:查询总成本 = read_cost(0.25) + eval_cost(0.20),也就是我们上面看到的cost=0.45的全表扫描成本的来源。
总结:
(1)Mysql的执行计划是Mysql根据cost来选择值最小的计划来执行的。
(2)Mysql中的表server_cost中记录server层执行计划相关的参数;engine_cost表记录了存储引擎层执行计划相关的参数。
(3)查询的sql前面添加format = json的方式可以获取到执行计划的详细信息,我们需要读懂执行计划中的参数含义。
(4)有时候明明添加了查询条件的索引但为什么没有走索引,此时我们不仅要考虑索引是否失效问题,也需要考虑是否为Mysql的执行计划中走索引的cost是否比全表扫面的cost大导致Mysql使用了全表扫描的执行计划。
