





1、非常少的外部依赖,安装使用超简单;
2、已经有非常多的系统集成 例如:docker HAProxy Nginx JMX等等;
3、服务自动化发现;
4、直接集成到代码;
5、设计思想是按照分布式、微服务架构来实现的;
6、多维数据模型:由度量名称和键值对标识的时间序列数据;
7、支持多种exporter采集数据;
8、PromQL:一种灵活的查询语言,可以利用多维数据完成复杂的查询;
9、不依赖分布式存储,单个服务器节点可直接工作(不需要安装数据库,直接使用即可,内置集成了数据库不需要重新的部署);
10、基于HTTP的pull方式采集时间序列数据;
11、推送时间序列数据通过PushGateway组件支持,目标主机上报数据到PushGateway,普罗米修斯从PushGateway拉取数据,这个是可以跨网段的;
12、通过服务发现或静态配置发现目标;
13、多种图形模式及仪表盘支持(grafana);
14、高效的存储,每个采集数据占用3.5bytes左右,300万的时间序列,30s的时间间隔,保留60天,消耗磁盘大约200G;
15、做高可用,对数据进行异地备份。联邦集群,部署多套普罗米修斯,每套普罗米修斯可以在不同的机房,然后将这些普罗米修斯汇总到一个普罗米修斯,那么就可以将各个地方的数据,整体收集上来了。
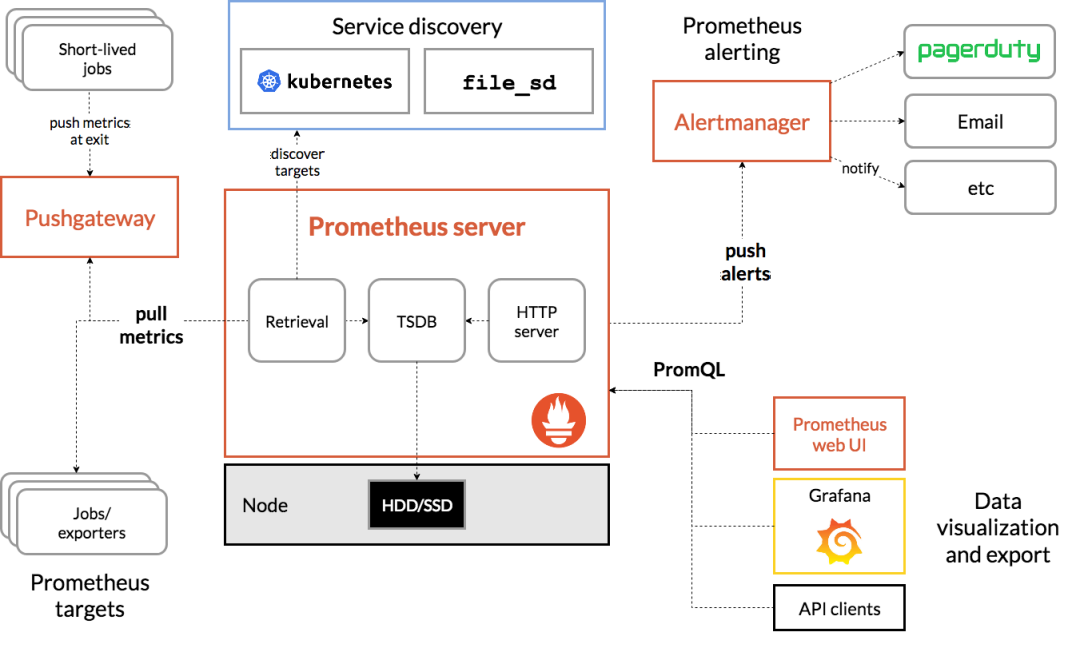
1、主要的Prometheus server,用于存储时间序列数据。
2、用于检测应用程序代码的客户端库。
3、用于支持short-lived工作的推送网关(push gateway)。
4、针对HAProxy,StatsD,Graphite等服务的exporters。
5、一个alertmanager处理警报管理器。
6、各种支持工具。
大多数Prometheus组件都是用Go编写的,因此很容易构建和部署为静态二进制文件。
1)Prometheus Server:收集指标和存储时间序列数据,并提供查询接口(采集,存储,查询);
2)ClientLibrary:客户端库;
3)Push Gateway:短期存储指标数据。主要用于临时性的任务,各个目标主机可以上报数据到pushgateway,,然后prometheus server统一从pushgateway拉取数据;
4)Exporters:采集已有的第三方服务监控指标并暴露metrics(类似于zabbix agent,但是exporter有很多种,针对不同的监控指标);
5)Alertmanager:从prometheus server端收到alters之后,会进行去重,分组,并且路由到接收方,发出报警,常见的接收方式有:电子邮件,微信,钉钉;
6) Web UI:简单的Web控制台;
2)另外一种就是主要使用持久性的应用,比如nginx,mysql还要微服务jar包,这些都属于持久性运行任务的;
Prometheus 根据配置的作业,直接从数据源pull拉取或者通过中间推送网关(push gateway),获取度量值Metrics。它在本地存储所有获取的样本,并在此数据上运行规则,以从现有数据聚合和记录新的时间序列,或者生成警报。Grafana或其他API使用者可用于可视化收集的数据。
服务端采集好之后就会存储在tsdb数据库当中,可以通过其ui去查看,因为其通过了http服务就可以访问其ui了。在ui上可以通过promql完成数据的查询。(export--->prometheus(TSDB)---->promsql);
告警是由altermanager提供的,在普罗米修斯这里定义告警规则,普罗米修斯这里会周期的评估当前采集的指标是否触发了告警规则,如果触发了会将事件推送给altermanger。altermanger会根据自己相关的逻辑处理后发给接收人,提供email
普罗米修斯实现了服务的发现,也就是可以自动的找到被监控端,这个需要在普罗米修斯的配置文件里面去配置。有了服务发现就不要一个一个的去配置了,让被监控端自动纳入监控。
普罗米修斯从目标主机拉取数据的时候有两种方式,一种是静态的,也就是我们部署exporter,静态的采集指标,也可以配置服务发现,自动的发现指标数据。通过服务发现和exporter采集到的数据的方式都是采用了默认的pull方式拉取指标的,也可以使用pushgateway上报到prometheus当中。
数据模型:
1)Prometheus将所有数据存储为时间序列(存储的时候都会记录时间,并且存储到时序的数据库里面,也就是内置的TSDB);
2)具有相同度量名称以及标签属于同一个指标(指标名称是一样,但是标签是不一样的);
3)每个时间序列都由度量标准名称和一组键值对(称为标签)唯一标识;
通过标签查询指定指标。
指标格式 : 指标名称加上多个标签
<metric name>{<label name>=<label value>,...}
在配置被监控端这里,要配置监控谁,在配置被监控端,必须要暴露指标出来,这种指标以https的方式给暴露出来,暴露出来之后在配置文件当中配置被监控端,最后就会被普罗米修斯给采集到,如果以上正确配置,在普罗米修斯的图形界面targets可以看到被监控端,也可以通过指标名称查看采集的数据了。
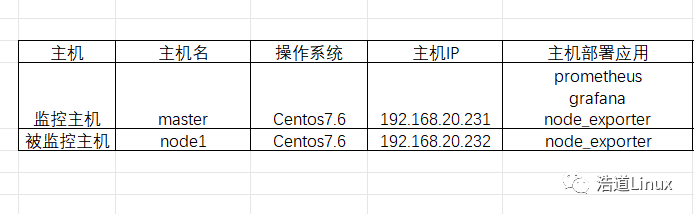
1)基础环境准备,两台主机,规划信息如下:
2)关闭selinux;
vi编辑 /etc/selinux/config 文件,修改SELINUX的值为disabled
#注意修改完毕之后需要重启linux服务
SELINUX=disabled
3)关闭防火墙。
# 1 关闭firewalld服务systemctl stop firewalldsystemctl disable firewalld# 2 关闭iptables服务systemctl stop iptablessystemctl disable iptables
4)prometheus官网下载:
https://prometheus.io/download/
这里下载最新版本:
https://github.com/prometheus/prometheus/releases/download/v2.45.0/prometheus-2.45.0.linux-amd64.tar.gz
5)node_exporter下载地址:
https://prometheus.io/download/
这里下载最新版本:
https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
6)grafana官网下载 :
https://grafana.com/grafana/download
这里下载最新版本:
https://dl.grafana.com/enterprise/release/grafana-enterprise-10.0.2-1.x86_64.rpm
2、prometheus安装
1)下载prometheus
wget https://github.com/prometheus/prometheus/releases/download/v2.45.0/prometheus-2.45.0.linux-amd64.tar.gz
我这里下载保存在 /opt目录下,完成如下所示:
[root@master opt]# ls -lh总用量 87M-rw-r--r--. 1 root root 87M 7月 19 17:21 prometheus-2.45.0.linux-amd64.tar.gz[root@master opt]#
2)解压安装prometheus
[root@master opt]# tar -xzvf prometheus-2.45.0.linux-amd64.tar.gz[root@master opt]# mv prometheus-2.45.0.linux-amd64 prometheus[root@master opt]# ls -lh总用量 87Mdrwxr-xr-x. 4 1001 123 132 6月 23 23:45 prometheus-rw-r--r--. 1 root root 87M 7月 19 17:21 prometheus-2.45.0.linux-amd64.tar.gz[root@master opt]#
[root@master opt]# cd prometheus[root@master prometheus]# ./prometheusts=2023-07-19T09:32:03.885Z caller=main.go:534 level=info msg="No time or size retention was set so using the default time retention" duration=15dts=2023-07-19T09:32:03.886Z caller=main.go:578 level=info msg="Starting Prometheus Server" mode=server version="(version=2.45.0, branch=HEAD, revision=8ef767e396bf8445f009f945b0162fd71827f445)"ts=2023-07-19T09:32:03.887Z caller=main.go:583 level=info build_context="(go=go1.20.5, platform=linux/amd64, user=root@920118f645b7, date=20230623-15:09:49, tags=netgo,builtinassets,stringlabels)"ts=2023-07-19T09:32:03.887Z caller=main.go:584 level=info host_details="(Linux 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 master (none))"ts=2023-07-19T09:32:03.887Z caller=main.go:585 level=info fd_limits="(soft=4096, hard=4096)"ts=2023-07-19T09:32:03.887Z caller=main.go:586 level=info vm_limits="(soft=unlimited, hard=unlimited)"ts=2023-07-19T09:32:03.893Z caller=web.go:562 level=info component=web msg="Start listening for connections" address=0.0.0.0:9090ts=2023-07-19T09:32:03.896Z caller=main.go:1019 level=info msg="Starting TSDB ..."ts=2023-07-19T09:32:03.901Z caller=tls_config.go:274 level=info component=web msg="Listening on" address=[::]:9090ts=2023-07-19T09:32:03.901Z caller=tls_config.go:277 level=info component=web msg="TLS is disabled." http2=false address=[::]:9090ts=2023-07-19T09:32:03.913Z caller=head.go:595 level=info component=tsdb msg="Replaying on-disk memory mappable chunks if any"ts=2023-07-19T09:32:03.913Z caller=head.go:676 level=info component=tsdb msg="On-disk memory mappable chunks replay completed" duration=15.4µsts=2023-07-19T09:32:03.913Z caller=head.go:684 level=info component=tsdb msg="Replaying WAL, this may take a while"ts=2023-07-19T09:32:03.914Z caller=head.go:755 level=info component=tsdb msg="WAL segment loaded" segment=0 maxSegment=0ts=2023-07-19T09:32:03.914Z caller=head.go:792 level=info component=tsdb msg="WAL replay completed" checkpoint_replay_duration=41.9µs wal_replay_duration=1.1234ms wbl_replay_duration=11.2µs total_replay_duration=1.3374msts=2023-07-19T09:32:03.916Z caller=main.go:1040 level=info fs_type=XFS_SUPER_MAGICts=2023-07-19T09:32:03.916Z caller=main.go:1043 level=info msg="TSDB started"ts=2023-07-19T09:32:03.916Z caller=main.go:1224 level=info msg="Loading configuration file" filename=prometheus.ymlts=2023-07-19T09:32:03.928Z caller=main.go:1261 level=info msg="Completed loading of configuration file" filename=prometheus.yml totalDuration=11.5929ms db_storage=15.8µs remote_storage=19.2µs web_handler=10.7µs query_engine=14µs scrape=1.0045ms scrape_sd=52.4µs notify=42.7µs notify_sd=29.6µs rules=11.8µs tracing=32.6µsts=2023-07-19T09:32:03.928Z caller=main.go:1004 level=info msg="Server is ready to receive web requests."ts=2023-07-19T09:32:03.928Z caller=manager.go:995 level=info component="rule manager" msg="Starting rule manager..."
http://192.168.20.231:9090/
5)为prometheus服务创建service并设置开机自动启动
vim usr/lib/systemd/system/prometheus.service
[root@master ~]# cat usr/lib/systemd/system/prometheus.service[Unit]Description=prometheusDocumentation=https://prometheus.io/After=network.target[Service]Type=simpleUser=rootGroup=rootExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.ymlRestart=on-failure[Install]WantedBy=multi-user.target[root@master ~]#
使service生效并且设置开机自启动
systemctl daemon-reload
systemctl enable prometheus
[root@master ~]# systemctl status prometheus● prometheus.service - prometheusLoaded: loaded (/usr/lib/systemd/system/prometheus.service; enabled; vendor preset: disabled)Active: active (running) since 三 2023-07-19 09:55:33 CST; 43s agoDocs: https://prometheus.io/Main PID: 5976 (prometheus)CGroup: system.slice/prometheus.service└─5976 opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml7月 19 09:55:34 master prometheus[5976]: ts=2023-07-19T01:55:34.433Z caller=head.go:676 level=info component=tsdb msg="On-disk memory mappable chunks replay completed" duration=55.101μs7月 19 09:55:34 master prometheus[5976]: ts=2023-07-19T01:55:34.433Z caller=head.go:684 level=info component=tsdb msg="Replaying WAL, this may take a while"7月 19 09:55:34 master prometheus[5976]: ts=2023-07-19T01:55:34.437Z caller=head.go:755 level=info component=tsdb msg="WAL segment loaded" segment=0 maxSegment=07月 19 09:55:34 master prometheus[5976]: ts=2023-07-19T01:55:34.437Z caller=head.go:792 level=info component=tsdb msg="WAL replay completed" checkpoint_replay_duration=1.016…ion=3.831257ms7月 19 09:55:34 master prometheus[5976]: ts=2023-07-19T01:55:34.439Z caller=main.go:1040 level=info fs_type=XFS_SUPER_MAGIC7月 19 09:55:34 master prometheus[5976]: ts=2023-07-19T01:55:34.439Z caller=main.go:1043 level=info msg="TSDB started"7月 19 09:55:34 master prometheus[5976]: ts=2023-07-19T01:55:34.439Z caller=main.go:1224 level=info msg="Loading configuration file" filename=/opt/prometheus/prometheus.yml7月 19 09:55:34 master prometheus[5976]: ts=2023-07-19T01:55:34.444Z caller=main.go:1261 level=info msg="Completed loading of configuration file" filename=/opt/prometheus/prometheus.yml…μs7月 19 09:55:34 master prometheus[5976]: ts=2023-07-19T01:55:34.444Z caller=main.go:1004 level=info msg="Server is ready to receive web requests."7月 19 09:55:34 master prometheus[5976]: ts=2023-07-19T01:55:34.444Z caller=manager.go:995 level=info component="rule manager" msg="Starting rule manager..."Hint: Some lines were ellipsized, use -l to show in full.[root@master ~]#
yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-10.0.2-1.x86_64.rpm
[root@master opt]# ll总用量 174664-rw-r--r--. 1 root root 87661825 7月 19 10:03 grafana-enterprise-10.0.2-1.x86_64.rpmdrwxr-xr-x. 5 1001 123 144 7月 19 2023 prometheus-rw-r--r--. 1 root root 91189594 7月 19 2023 prometheus-2.45.0.linux-amd64.tar.gz[root@master opt]# yum install grafana-enterprise-10.0.2-1.x86_64.rpm
[root@master ~]# systemctl daemon-reload[root@master ~]# systemctl start grafana-server[root@master ~]# systemctl status grafana-server● grafana-server.service - Grafana instanceLoaded: loaded (/usr/lib/systemd/system/grafana-server.service; disabled; vendor preset: disabled)Active: active (running) since 三 2023-07-19 10:11:15 CST; 25s agoDocs: http://docs.grafana.orgMain PID: 6945 (grafana)CGroup: system.slice/grafana-server.service└─6945 usr/share/grafana/bin/grafana server --config=/etc/grafana/grafana.ini --pidfile=/var/run/grafana/grafana-server.pid --packaging=rpm cfg:default.paths.logs=/var/log/gr...7月 19 10:11:15 master grafana[6945]: logger=ngalert.state.manager t=2023-07-19T10:11:15.24341291+08:00 level=info msg="Warming state cache for startup"7月 19 10:11:15 master grafana[6945]: logger=caching.service t=2023-07-19T10:11:15.24445863+08:00 level=warn msg="Caching service is disabled"7月 19 10:11:15 master grafana[6945]: logger=report t=2023-07-19T10:11:15.244980141+08:00 level=warn msg="Scheduling and sending of reports disabled, SMTP is not configured ... to enable."7月 19 10:11:15 master grafana[6945]: logger=http.server t=2023-07-19T10:11:15.250259745+08:00 level=info msg="HTTP Server Listen" address=[::]:3000 protocol=http subUrl= socket=7月 19 10:11:15 master grafana[6945]: logger=sqlstore.transactions t=2023-07-19T10:11:15.267350682+08:00 level=info msg="Database locked, sleeping then retrying" error="data...e is locked"7月 19 10:11:15 master grafana[6945]: logger=ngalert.state.manager t=2023-07-19T10:11:15.268604707+08:00 level=info msg="State cache has been initialized" states=0 duration=25.191797ms7月 19 10:11:15 master grafana[6945]: logger=ticker t=2023-07-19T10:11:15.268828111+08:00 level=info msg=starting first_tick=2023-07-19T10:11:20+08:007月 19 10:11:15 master grafana[6945]: logger=ngalert.multiorg.alertmanager t=2023-07-19T10:11:15.268860012+08:00 level=info msg="starting MultiOrg Alertmanager"7月 19 10:11:16 master grafana[6945]: logger=grafana.update.checker t=2023-07-19T10:11:16.035234839+08:00 level=info msg="Update check succeeded" duration=795.319198ms7月 19 10:11:16 master grafana[6945]: logger=plugins.update.checker t=2023-07-19T10:11:16.117663666+08:00 level=info msg="Update check succeeded" duration=874.346258msHint: Some lines were ellipsized, use -l to show in full.[root@master ~]#
3)将grafana-server服务设置为开机自启动
systemctl enable grafana-server
4)通过以下地址访问garfana,并且配置相应的数据源
http://192.168.20.231:3000/login
登录界面如下所示,默认用户名及密码分别是admin,admin
5)登录进入grafana系统后,对数据源进行配置,点击,add your first data source,进入添加数据源页面:
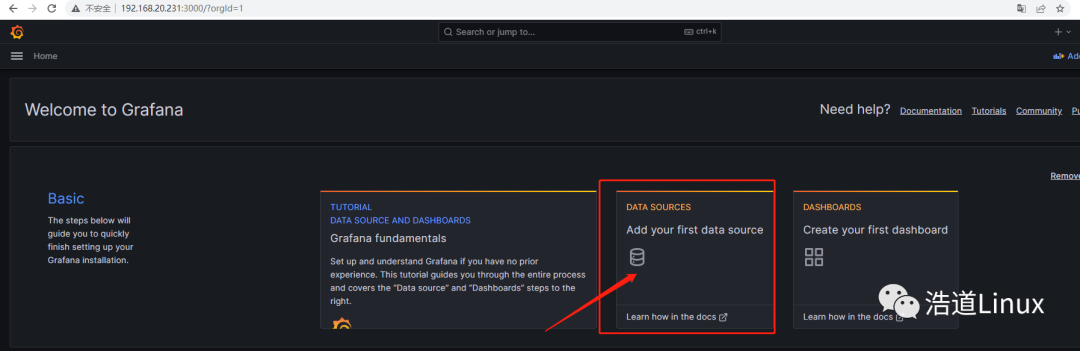
6)进入后,点击Prometheus,进入配置页面;
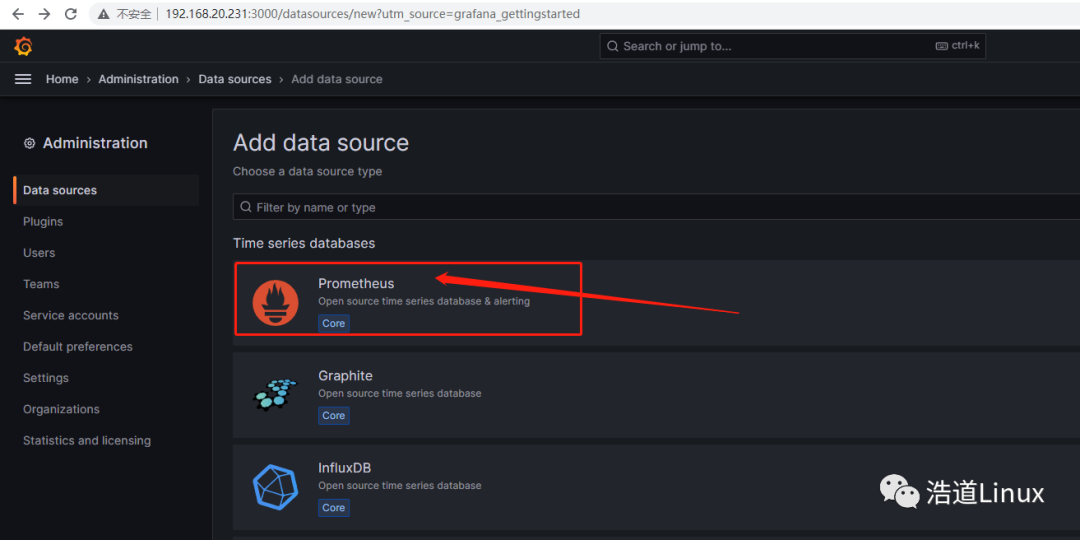
7)编辑HTTP下的URL,这里是主机IP是192.168.20.231,所以填:http://192.68.20.231:9090
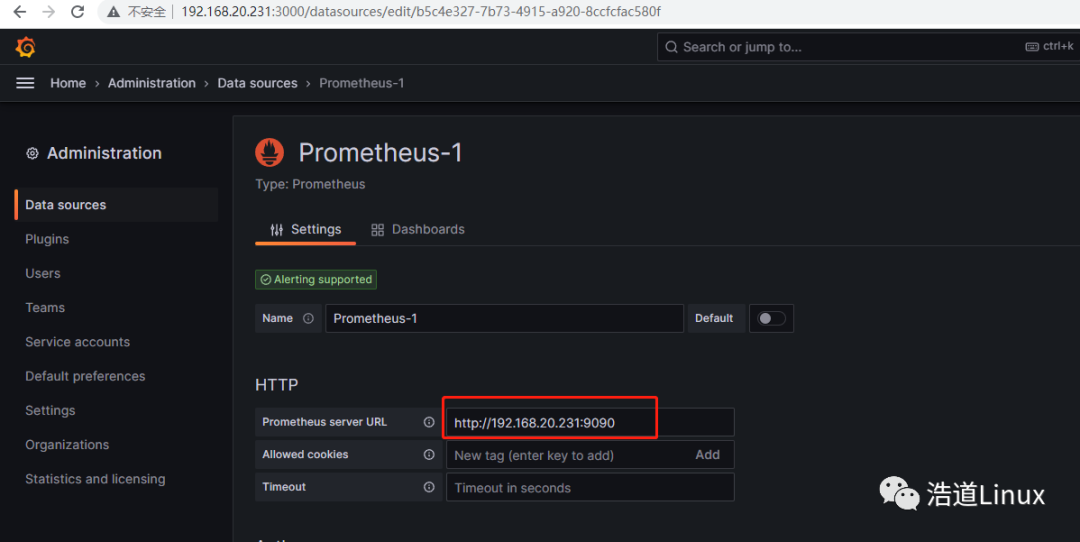
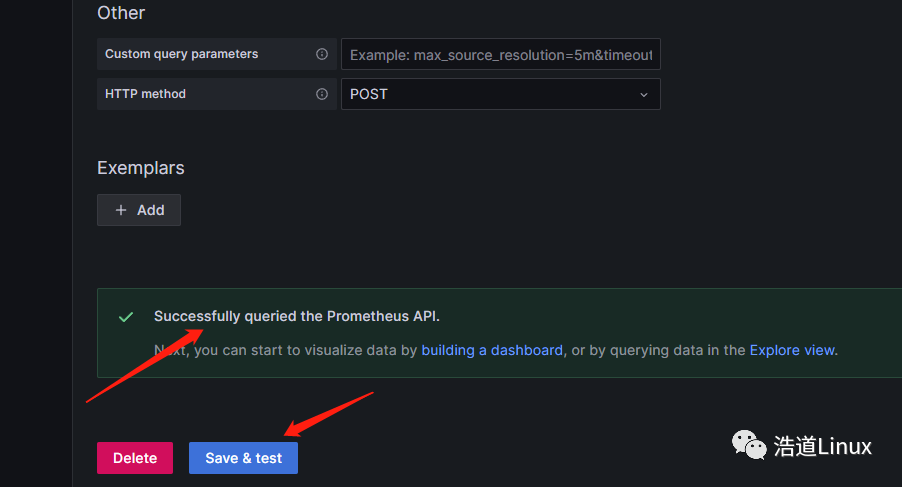
8)拉到最底部进行保存,如下所示即为保存成功。
4、监控主机中安装node_exporter
首先在监控主机192.168.20.231上进行安装该组件。
1)下载最新的node_exporter版本
wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
下载完成后如下图所示:

2)对软件压缩包进行解压,并且将安装包放到自己系统安装目录下,我自己放在/usr/local/目录中
[root@master ruanjianfile]# tar -xzf node_exporter-1.6.1.linux-amd64.tar.gz[root@master ruanjianfile]# mv node_exporter-1.6.1.linux-amd64 usr/local/
3)将安装包中的可执行文件node_exporter拷贝到/usr/local/bin目录中
mv usr/local/node_exporter-1.6.1.linux-amd64/node_exporter usr/local/bin/
4)为node_exporter服务创建service服务
vim usr/lib/systemd/system/node_exporter.service
大家根据自己实际安装目录,写入cat命令相关内容到上述文件中。
[root@master ruanjianfile]# cat usr/lib/systemd/system/node_exporter.service[Unit]Description=node_exporterDocumentation=https://prometheus.io/After=network.target[Service]Type=simpleUser=rootGroup=rootExecStart=/usr/local/bin/node_exporterRestart=on-failure[Install]WantedBy=multi-user.target
5)为node_exporter设置自动启动并启动服务
systemctl daemon-reloadsystemctl enable node_exportersystemctl start node_exporter
6)查看node_exporter服务状态,如下服务状态为正常状态
[root@master ~]# systemctl status node_exporter● node_exporter.service - node_exporterLoaded: loaded (/usr/lib/systemd/system/node_exporter.service; enabled; vendor preset: disabled)Active: active (running) since 三 2023-07-19 14:25:07 CST; 3min 0s agoDocs: https://prometheus.io/Main PID: 7146 (node_exporter)CGroup: /system.slice/node_exporter.service└─7146 usr/local/bin/node_exporter7月 19 14:25:07 master node_exporter[7146]: ts=2023-07-19T06:25:07.181Z caller=node_exporter.go:117 level=info collector=thermal_zone7月 19 14:25:07 master node_exporter[7146]: ts=2023-07-19T06:25:07.181Z caller=node_exporter.go:117 level=info collector=time7月 19 14:25:07 master node_exporter[7146]: ts=2023-07-19T06:25:07.181Z caller=node_exporter.go:117 level=info collector=timex7月 19 14:25:07 master node_exporter[7146]: ts=2023-07-19T06:25:07.181Z caller=node_exporter.go:117 level=info collector=udp_queues7月 19 14:25:07 master node_exporter[7146]: ts=2023-07-19T06:25:07.181Z caller=node_exporter.go:117 level=info collector=uname7月 19 14:25:07 master node_exporter[7146]: ts=2023-07-19T06:25:07.181Z caller=node_exporter.go:117 level=info collector=vmstat7月 19 14:25:07 master node_exporter[7146]: ts=2023-07-19T06:25:07.181Z caller=node_exporter.go:117 level=info collector=xfs7月 19 14:25:07 master node_exporter[7146]: ts=2023-07-19T06:25:07.181Z caller=node_exporter.go:117 level=info collector=zfs7月 19 14:25:07 master node_exporter[7146]: ts=2023-07-19T06:25:07.182Z caller=tls_config.go:274 level=info msg="Listening on" address=[::]:91007月 19 14:25:07 master node_exporter[7146]: ts=2023-07-19T06:25:07.182Z caller=tls_config.go:277 level=info msg="TLS is disabled." http2=f...::]:9100Hint: Some lines were ellipsized, use -l to show in full.[root@master ~]#
1)vi编辑修改prometheus中相关配置文件;
主要在对应该控件软件安装目录下/opt/prometheus/prometheus.yml这个文件中;
在原文件的scrape_configs模块下增加如下配置内容:
- job_name: 'master_prometheus'static_configs:- targets: ['192.168.20.231:9100']
修改后/opt/prometheus/prometheus.yml如下所示:
[root@master prometheus]# cat prometheus.yml# my global configglobal:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configurationalerting:alertmanagers:- static_configs:- targets:# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files:# - "first_rules.yml"# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:# Here it's Prometheus itself.scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ["localhost:9090"]- job_name: 'master_prometheus'static_configs:- targets: ['192.168.20.231:9100']
2)检查配置是否正确:
养成好习惯,每次修改配置文件完成,用promtool检测配置文件是否正确。如下检查配置文件正确方可执行下一步。
[root@master prometheus]# opt/prometheus/promtool check config opt/prometheus/prometheus.ymlChecking opt/prometheus/prometheus.ymlSUCCESS: opt/prometheus/prometheus.yml is valid prometheus config file syntax[root@master prometheus]#
3)重启prometheus服务进行相关测试
systemctl restart prometheus
打开如下测试地址
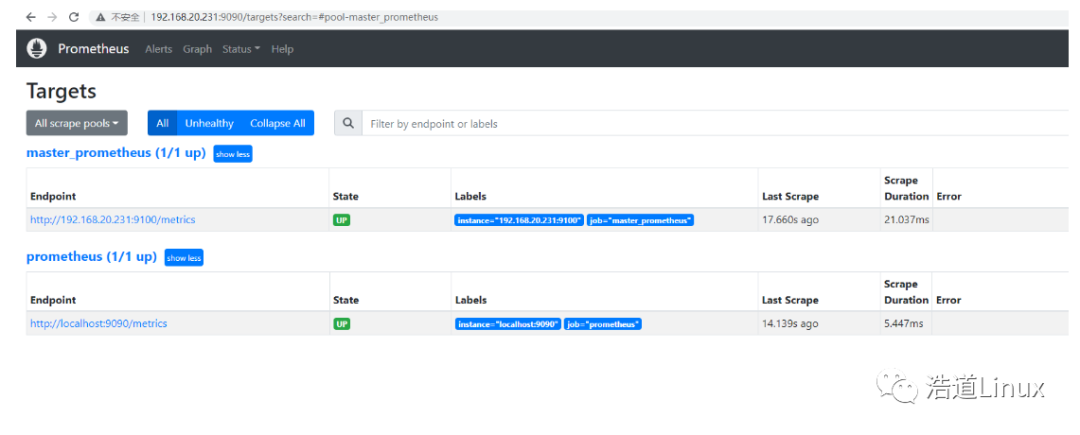
http://192.168.20.231:9090/targets
如下图所示,可以看到targets已经增加了对监控主机master_prometheus的监控。
6、被监控主机中安装node_exporter及进行参数配置
首先在被监控主机192.168.20.232上进行安装该组件。
1)安装步骤参考监控主机中node_exporter安装这个章节,安装方法步骤一样。
2)在监控主机192.168.20.231上修改对应配置文件,
修改/opt/prometheus/prometheus.yml这个文件后面,添加如下内容:
- job_name: "node1-prometheus"static_configs:- targets: ['192.168.20.232:9100']
[root@master prometheus]# /opt/prometheus/promtool check config /opt/prometheus/prometheus.ymlChecking /opt/prometheus/prometheus.ymlSUCCESS: /opt/prometheus/prometheus.yml is valid prometheus config file syntax[root@master prometheus]# systemctl restart prometheus
4)待服务起来后,打开下面地址进行测试
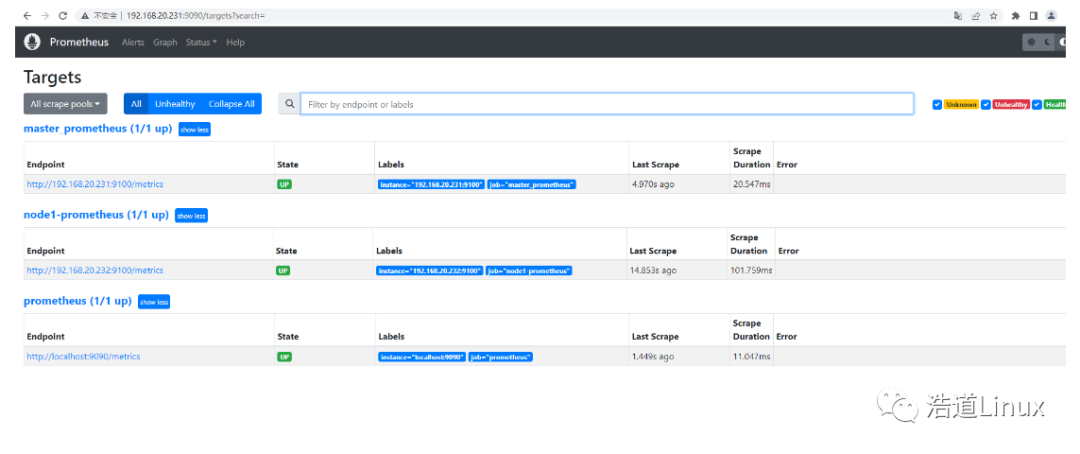
http://192.168.20.231:9090/targets
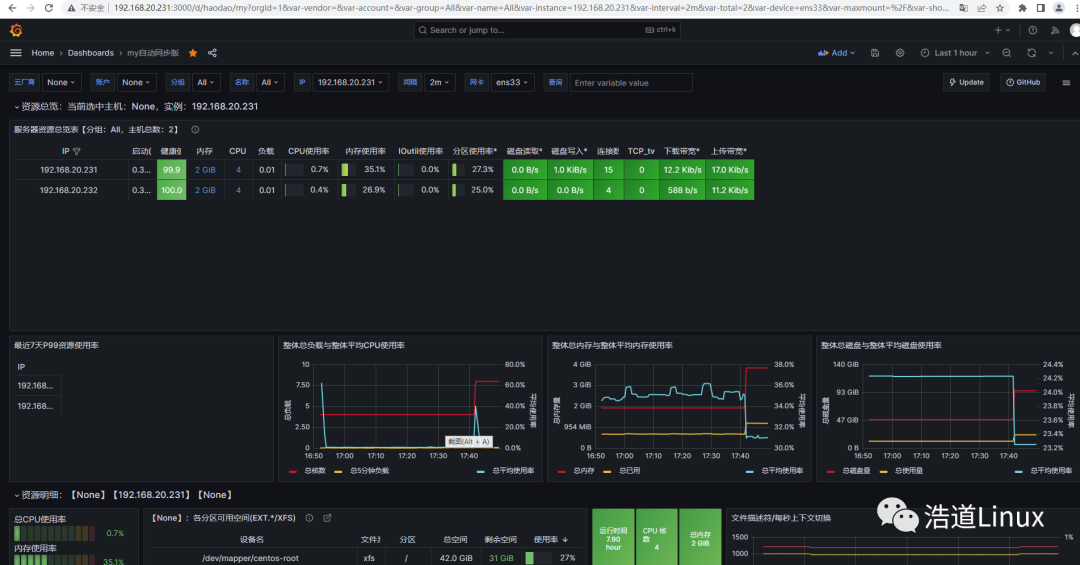
正常如下图所示,targets已经增加了对被监控主机node1的监控。
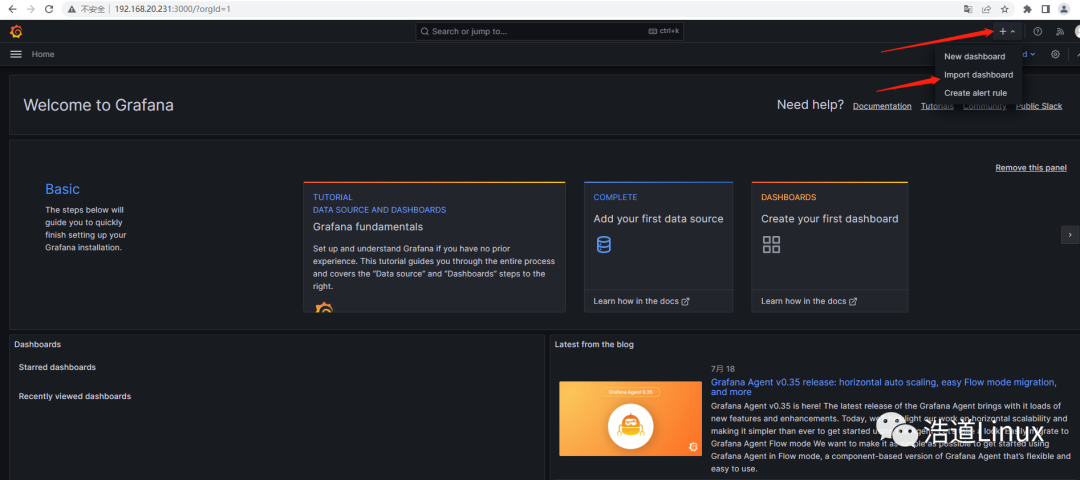
1)如图点击“+”号后,选择import dashboard
2)如下图,搜索系统默认模板8919,然后点击Load
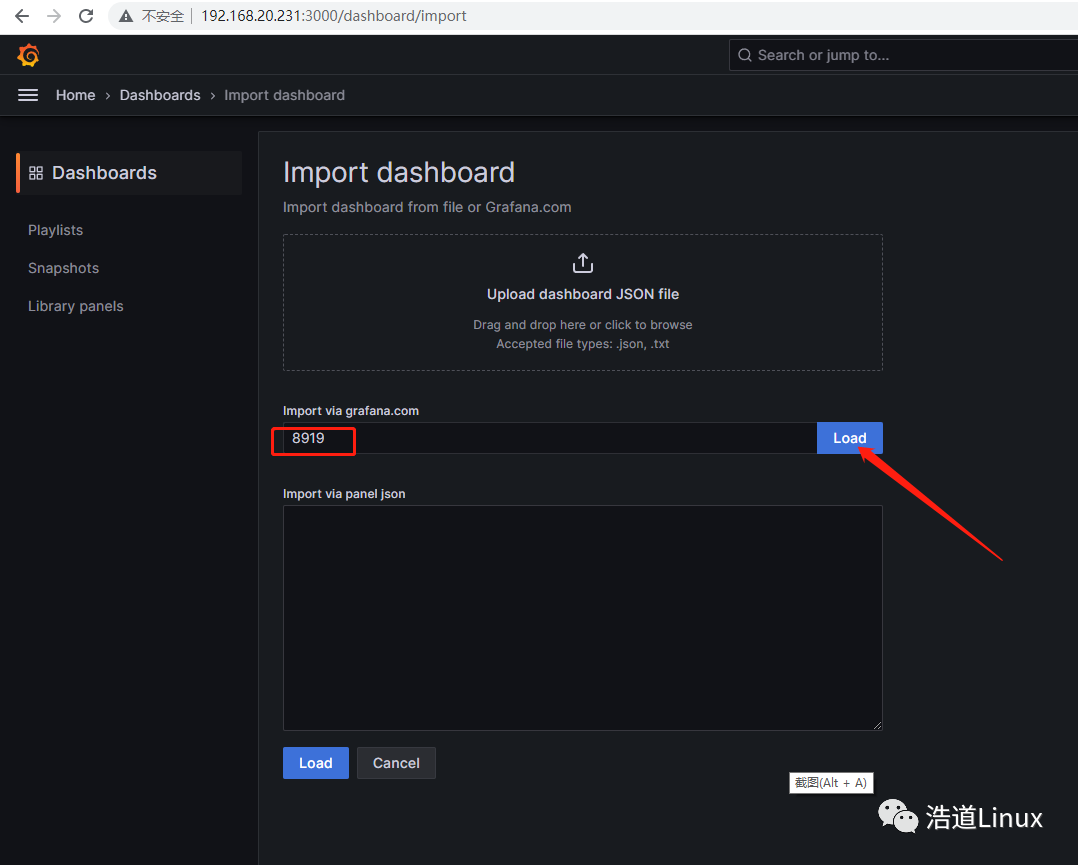
3)点Load后,稍等会,grafana会直接从官方网站导入编号为8919的面板如下图所示:
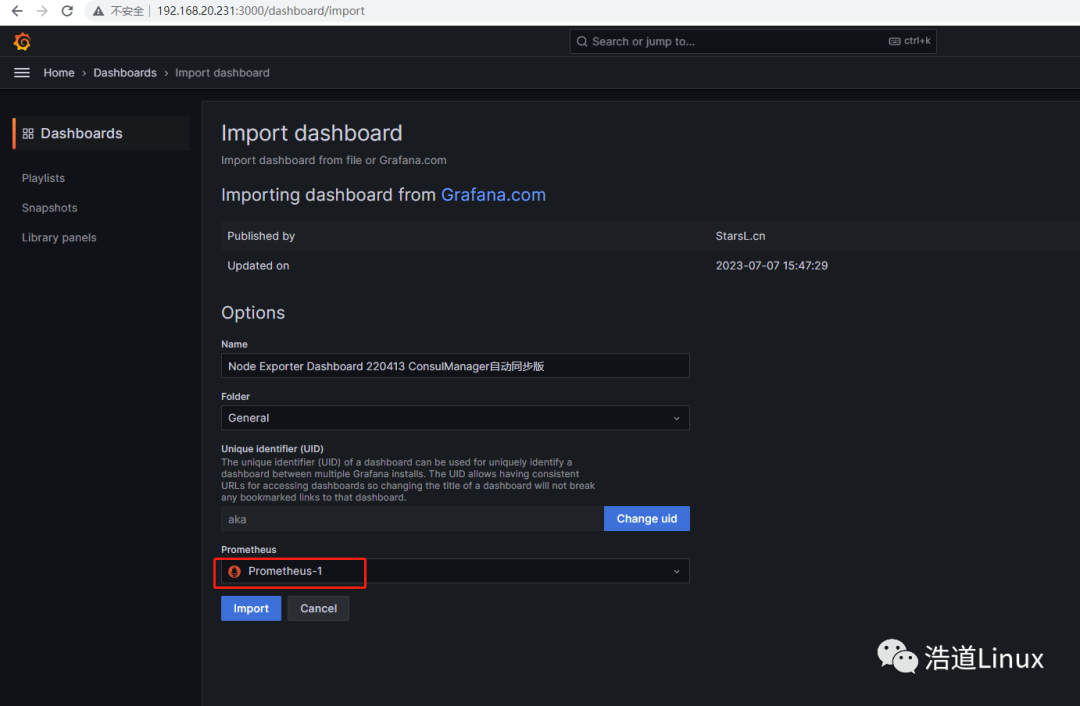
4)选择数据源Prometheus-1,点击“Import”,显示master和node1监控界面显示如下图所示:
四、总结
到此、整套Prometheus监控系统已经部署完毕,并且已经可以正常监控。但是其展示的只是它本身最基本的功能,其它组件及模块相关的功能配置,要靠大家自行去研究学习,那样方可发挥出它强大的监控系统功能。相信能够看到最后面内容的小伙伴都是热爱学习,对生活有所追求的人儿呀!
- EOF -
1、CentOS7下部署开源IT资产管理软件GLPI+FusionInventory
看完本文有收获?请分享给更多人
推荐关注「Linux 运维进阶之路」,提升Linux技能


