






阿里云瑶池旗下的云原生关系型数据库PolarDB MySQL版的列存索引(IMCI)技术专为 OLAP 场景下的大数据量复杂查询而设计。通过列存索引,PolarDB MySQL版可以实现实时事务处理与实时数据分析的一体化能力,成为一站式的 HTAP(Hybrid Transactional/Analytical Processing)数据库解决方案。
在原来的使用方式中,如果要对慢查询涉及的表进行加速,需要手动为这些表添加列索引。一般做法是通过 CREATE TABLE 或 ALTER TABLE 在表的 COMMENT 字段中添加 COLUMNAR=1 ,列索引就绪后,优化器会根据查询代价自动决定是否使用列索引。但如果用户的SQL模板数量众多、SQL逻辑复杂,这种手动方式在实际使用中并不友好。
为此,PolarDB 现推出自动建列索引功能(AutoIndex):它可根据慢查询情况自动对目标表添加列索引,从而加速查询。本篇文章将介绍该功能的技术背景、实现原理与使用方法,帮助大家深入了解如何通过自动化手段提升数据库查询性能。
1. 自动 Load/Unload:根据查询执行情况自动创建列索引并加速慢查询;对于不常用或占用资源过多的列索引会自动删除,减少空间消耗。
2. 自动 Encode:根据每列数据分布自动选择最优的编码算法,进一步压缩存储空间。
3. 自动选取 Distribute Key:使数据在 MPP 场景下分布更均衡,减少数据倾斜,同时优化分布式 GroupBy 与 Join 的数据 Shuffle。
1. 写入影响更小:行存索引过多会显著影响主节点写入性能,而 IMCI 在主节点上并不物化列存数据;新增列索引后,只需通过 Redo 将写入操作同步到列存只读节点,对写入性能几乎不造成影响。
2. 更高压缩率:列索引一般能达到 3~5 倍的压缩率,因此新增索引在存储空间上的开销也相对更小。
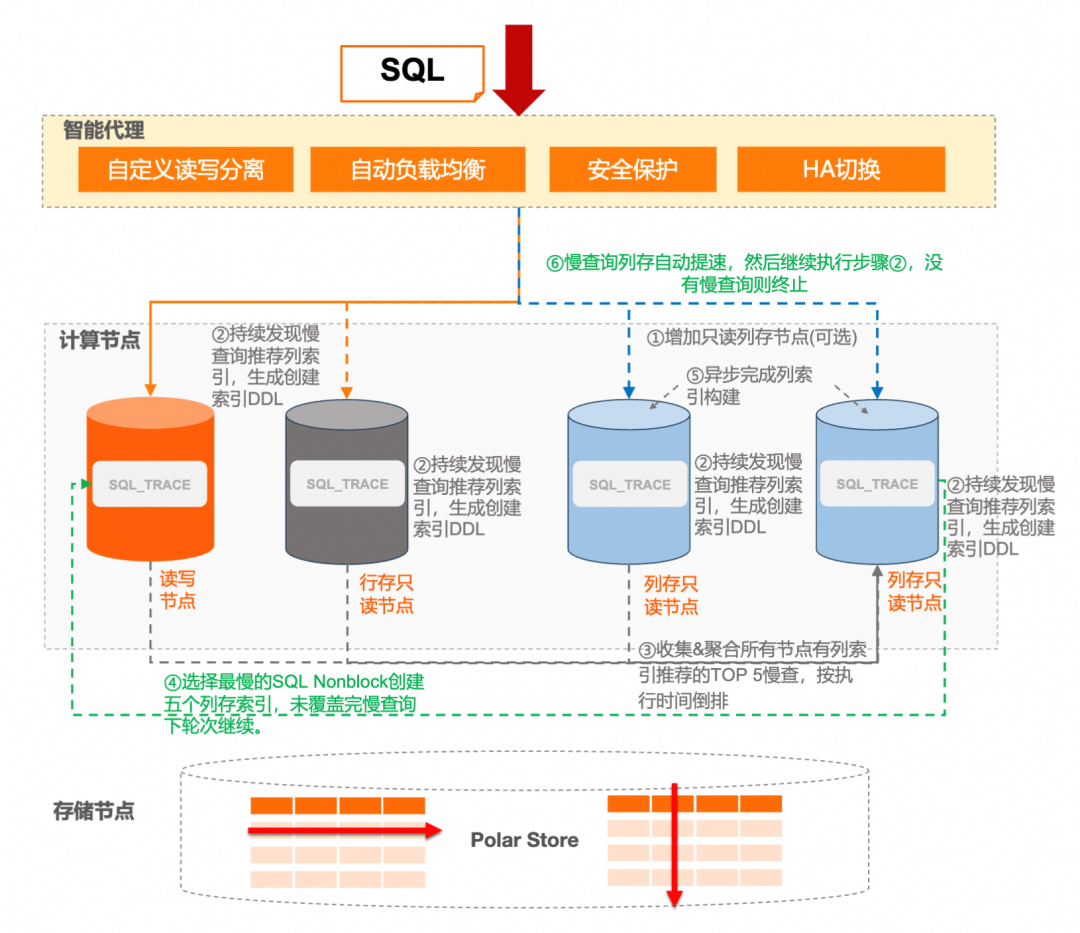
3.1 慢查跟踪与 DDL 语句生成
PolarDB MySQL 版集群各节点使用 SQL Trace 功能采集慢查询,对符合条件的 SQL 自动生成创建列索引的 DDL 语句。具体流程如下:
4. 查看生成记录:可通过直连至各节点,查询 information_schema.imci_autoindex 系统表,了解已追踪并生成 DDL 语句集合的慢查询信息。例如:
mysql> SELECT * FROM information_schema.imci_autoindex\G
也可结合 information_schema.sql_sharing 获取更详细的 SQL 执行信息:
mysql> SELECT *FROM information_schema.imci_autoindex autoindex, information_schema.sql_sharing shareWHERE autoindex.sql_id = share.sql_idAND share.type = 'SQL'\G
3.2 慢查收集聚合与 DDL 语句执行
集群中的列存只读节点(若有多个,则其中一个担任 Leader 角色)会收集并汇总各节点上存在列索引推荐的慢查询,并按执行时间倒序排序,依次执行推荐的 DDL 语句,直至达到单轮可执行的 DDL 数量阈值。此过程要点如下:
添加列索引的操作在主节点是 Instant DDL,只需修改数据字典,并不会在主库做实际数据改动。 对应的 Redo 会复制到列存只读节点,由后者在后台构建列索引。
普通 DDL 在等待获取 MDL-X 锁期间会阻塞新事务进入;而 Nonblock DDL 在获取锁失败时,会先允许新事务进入,再不断重试获取锁。 对于 AutoIndex 场景而言,DDL 并非“紧急”操作,一旦本轮失败,可在下轮自动调度中继续尝试,因此 Nonblock DDL 能够很好地与自动建索引需求相结合。 可通过集群地址查询 information_schema.imci_autoindex_executed 系统表,查看最近执行成功的列索引推荐语句及关联慢查询(最多保留 128 条记录)。
默认情况下,轮次间隔为 1 分钟,每轮最多执行 5 条 DDL 语句。 未在本轮被覆盖的列索引需要等待后续慢查询再次命中才能被重试。 列存只读节点在构建列索引时会受资源管控,虽然会引起资源指标上升,但不会打满节点资源。 本轮次列索引在列存节点上构建完成后,才会开始调度下一轮次。
3.3 列索引生效与使用
列存索引常见问题:
要使用 IMCI AutoIndex,只需在控制台开启“自动列存索引提速”开关即可。若当前集群没有列存只读节点,系统将引导至列存只读节点购买页面。
以下为基于 tpch100g 测试集的示例:
环境准备:每隔 1 分钟执行一遍 22 条 tpch 测试查询;集群地址开启 HTAP 配置、行列自动分流,行存并行度设为 8(主要用于缩短测试时间)。 测试结果:如下表所示,后续轮次的查询速度提升非常明显。在第一轮执行后半部分查询时(约第 12 条开始),AutoIndex 已经完成了对大多数表的列索引创建,优化器自动将这部分查询路由至列存节点。
从测试数据可见,AutoIndex 在 HTAP 场景下能够非常直观地提升查询性能,大幅缩短执行时间。
100%兼容MySQL:支持MySQL所有数据类型,完全兼容MySQL协议。 优秀的HTAP性能:分析场景性能普遍可以达到1-2个数量级提升。 行列混合存储,降低成本:行列存储保证事务一致性。列索引在某些查询场景性能更优,成本更低。
自动提速操作简单:一键开启自动性能提升,无需复杂配置和调整。
节约运维工作量:自动为慢查询创建列索引,减少手动慢查询优化工作。
节约IT成本:无需为所有库和表创建列索引,只针对慢查询优化,节省内存和存储资源。
总结
本篇文章介绍了PolarDB MySQL版 IMCI AutoIndex 功能的技术背景、实现原理、使用方法和核心优势。通过自动化的列索引创建与管理机制,AutoIndex 在 HTAP 场景下能有效提升慢查询的执行效率,且对数据库正常事务性能影响极小。对于日常需要分析大量业务数据的场景,这是一种降本增效的实用方案。
希望本文能帮助您快速了解并上手使用 AutoIndex,加速PolarDB中的慢查询。如果对具体实现细节或使用中遇到问题,欢迎参考官方文档或与我们进一步交流。




点击了解 云原生数据库PolarDB

