




DeepSeek-R1 是一款功能强大且经济高效的 AI 模型,擅长复杂的推理任务。当与 Amazon OpenSearch Service 结合使用时,它可以支持强大的检索增强生成 (RAG) 应用程序。本文将向您展示如何在 Amazon SageMaker 上使用 DeepSeek-R1 设置 RAG,并将 OpenSearch Service 矢量数据库作为知识库。此示例为希望增强其 AI 功能的企业提供了一种解决方案。
OpenSearch Service 为 RAG 使用案例以及向量嵌入驱动的语义搜索提供了丰富的功能。您可以在 OpenSearch 中使用灵活的连接器框架和搜索流管道来连接到由 DeepSeek、Cohere 和 OpenAI 托管的模型,以及托管在 Amazon Bedrock 和 SageMaker 上的模型。在本文中,我们将构建与 DeepSeek 的文本生成模型的连接,支持 RAG 工作流以生成对用户查询的文本响应。
解决方案概述
下图说明了解决方案体系结构。
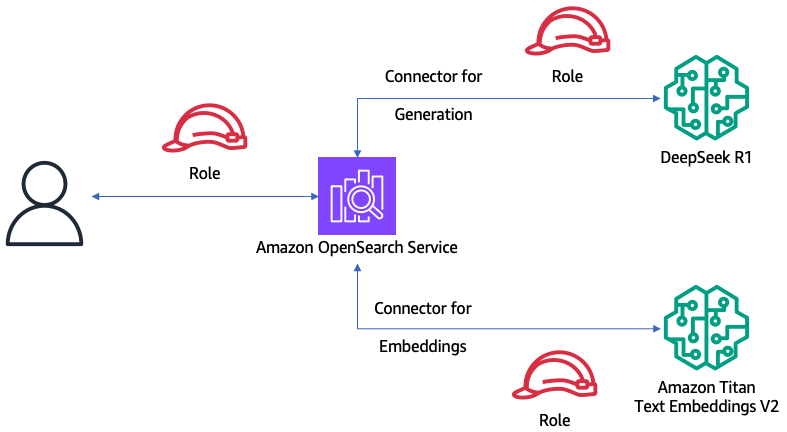
在本演练中,您将使用一组脚本来创建上述架构和数据流。首先,您将创建一个OpenSearch Service域,并将 DeepSeek-R1 部署到 SageMaker。您将执行脚本来创建用于调用 SageMaker 的 AWS Identity and Access Management (IAM) 角色,并为您的用户创建一个角色来创建 SageMaker 的连接器。您将创建一个 OpenSearch 连接器和模型,该模型将使 OpenSearch 中的 retrieval_augmented_generation 处理器能够执行用户查询、执行搜索并使用 DeepSeek 生成文本响应。您将使用 Amazon Titan 文本嵌入 V2 创建到 SageMaker 的连接器,以便为一组包含人口统计数据的文档创建嵌入。最后,您将执行查询以比较迈阿密和纽约市的人口增长。
先决条件
我们已经创建并开源了一个 GitHub 存储库,其中包含您需要遵循文章并自行部署的所有代码。您将需要以下先决条件:
- Git – 在 https://github.com/Jon-AtAWS/opensearch-examples.git 克隆存储库。
- Python – 该代码已使用 Python 版本 3.13 进行了测试。
- 一个 AWS 账户 – 您需要能够创建一个 OpenSearch Service 域和两个 SageMaker 终端节点。
- 集成开发环境 (IDE) – 像 Visual Studio Code 这样的 IDE 很有帮助,尽管它不是绝对必要的。
- AWS CLI – 确保使用您计划使用的账户配置 AWS Command Line Interface (AWS CLI)。或者,您可以按照 Boto 3 文档进行作,以确保您使用正确的凭证。
在 Amazon SageMaker 上部署 DeepSeek
您需要拥有或部署带有 Amazon SageMaker 终端节点的 DeepSeek。要了解有关在 SageMaker 上部署 DeepSeek-R1 的更多信息,请参阅使用 Amazon SageMaker AI 在 AWS 上部署 DeepSeek-R1 Distill 模型。
创建 OpenSearch Service 域
有关如何创建域的说明,请参阅创建 Amazon OpenSearch Service 域。记下域 Amazon 资源名称 (ARN) 和域终端节点,这两者都可以在 OpenSearch Service 控制台上每个域的 General information 部分找到。
下载并准备代码
从具有 Python 和 git 的本地计算机或工作区运行以下步骤:
- 如果尚未克隆,请使用以下命令将存储库克隆到本地文件夹:
git clone https://github.com/Jon-AtAWS/opensearch-examples.git- 创建 Python 虚拟环境:
cd opensearch-examples/opensearch-deepseek-rag
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt示例脚本使用环境变量来设置一些常用参数。现在使用以下命令设置这些参数。请务必使用您的 AWS 区域、SageMaker 终端节点 ARN 和 URL、OpenSearch Service 域的终端节点和 ARN 以及域的主要用户和密码进行更新。
export DEEPSEEK_AWS_REGION='<your current region>'
export SAGEMAKER_MODEL_INFERENCE_ARN='<your SageMaker endpoint’s ARN>'
export SAGEMAKER_MODEL_INFERENCE_ENDPOINT='<your SageMaker endpoint’s URL>'
export OPENSEARCH_SERVICE_DOMAIN_ARN='<your domain’s ARN>’
export OPENSEARCH_SERVICE_DOMAIN_ENDPOINT='<your domain’s API endpoint>'
export OPENSEARCH_SERVICE_ADMIN_USER='<your domain’s master user name>'
export OPENSEARCH_SERVICE_ADMIN_PASSWORD='<your domain’s master user password>'您现在拥有了代码库并设置了虚拟环境。您可以检查 opensearch-deepseek-rag 目录的内容。为了明确目的和阅读,我们将七个步骤中的每一个都封装在自己的 Python 脚本中。这篇文章将指导您运行这些脚本。我们还选择使用环境变量在脚本之间传递参数。在实际解决方案中,您将代码封装在类中,并在需要的地方传递值。以这种方式编码更清晰,但效率较低,并且不遵循编码最佳实践。使用这些脚本作为示例来提取。
首先,您将为 OpenSearch Service 域设置权限以连接到您的 SageMaker 终端节点。
设置权限
您将创建两个 IAM 角色。第一个将允许 OpenSearch 调用您的 SageMaker 终端节点。第二个将允许您对 OpenSearch 进行创建连接器 API 调用。
- 在 create_invoke_role.py 中检查代码。
- 返回命令行,并执行脚本:
python create_invoke_role.py- 从脚本的输出执行命令行以设置 INVOKE_DEEPSEEK_ROLE 环境变量。
您创建了一个名为 invoke_deepseek_role 的角色,具有允许 OpenSearch Service 代入该角色的信任关系,以及允许 OpenSearch Service 调用您的 SageMaker 终端节点的权限策略。该脚本输出您的角色和策略的 ARN,此外还输出一个命令行命令,用于将角色添加到您的环境中。在运行下一个脚本之前执行该命令。记下角色 ARN,以备日后需要返回时使用。
现在,您需要为用户创建一个角色,以便能够在 OpenSearch Service 中创建连接器。
- 在 create_connector_role.py 中检查代码。
- 返回命令行并执行脚本:
python create_connector_role.py- 从脚本的输出执行命令行以设置 CREATE_DEEPSEEK_CONNECTOR_ROLE 环境变量。
您创建了一个名为 create_deepseek_connector_role 的角色,该角色与当前用户具有信任关系,并有权写入 OpenSearch Service。您需要这些权限才能调用 OpenSearch create_connector API,该 API 将连接打包到远程模型主机,在本例中为 DeepSeek。该脚本打印策略和角色的 ARN,此外还会打印用于将角色添加到您的环境的命令行命令。在运行下一个脚本之前执行该命令。同样,请记下角色 ARN,以防万一。
现在您已经创建了角色,您将告诉 OpenSearch 有关这些角色的信息。精细访问控制功能包括一个 OpenSearch 角色 ml_full_access,该角色将允许经过身份验证的实体在 OpenSearch 中执行 API 调用。
- 在 setup_opensearch_security.py 中检查代码。
- 返回命令行并执行脚本:
python setup_opensearch_security.py您设置了 OpenSearch Service 安全插件以识别两个AWS角色:invoke_create_connector_role 和 LambdaInvokeOpenSearchMLCommonsRole。稍后,当您连接嵌入模型并将数据加载到OpenSearch中以用作 RAG 知识库时,您将使用第二个角色。现在,您已获得权限,可以创建连接器。
创建连接器
您可以使用指示 OpenSearch 如何连接的配置创建一个连接器,为目标模型主机提供凭证,并提供提示详细信息。有关更多信息,请参阅为第三方 ML 平台创建连接器。
- 在 create_connector.py 中检查代码。
- 返回命令行并执行脚本:
python create_connector.py- 从脚本的输出执行命令行以设置 DEEPSEEK_CONNECTOR_ID 环境变量。
该脚本将创建连接器以调用 SageMaker 终端节点并返回连接器 ID。连接器是一个 OpenSearch 构造,它告诉 OpenSearch 如何连接到外部模型主机。您不直接使用它;您为此创建一个 OpenSearch 模型。
创建 OpenSearch 模型
当您使用机器学习 (ML) 模型时,在 OpenSearch 中,您可以使用 OpenSearch 的 ml-commons 插件创建模型。ML 模型是一种 OpenSearch 抽象,可让您执行 ML 任务,例如在索引期间发送文本以进行嵌入,或调用大型语言模型 ()LLM 以在搜索管道中生成文本。模型接口在模型组中为您提供模型 ID,然后您可以在提取管道和搜索管道中使用该 ID。
- 在 create_deepseek_model.py 中检查代码。
- 返回命令行并执行脚本:
python create_deepseek_model.py- 从脚本的输出执行命令行以设置 DEEPSEEK_MODEL_ID 环境变量。
您创建了一个OpenSearch ML模型组和模型,可用于创建摄取和搜索管道。_register API 将模型放置在模型组中,并通过您创建的连接器 (connector_id) 引用您的 SageMaker 终端节点。
验证您的设置
您可以运行查询来验证您的设置,并确保您可以连接到 SageMaker 上的 DeepSeek 并接收生成的文本。请完成以下步骤:
- 在 OpenSearch Service 控制台上,选择导航窗格中托管集群下的 Dashboard。
- 选择您的域的控制面板。
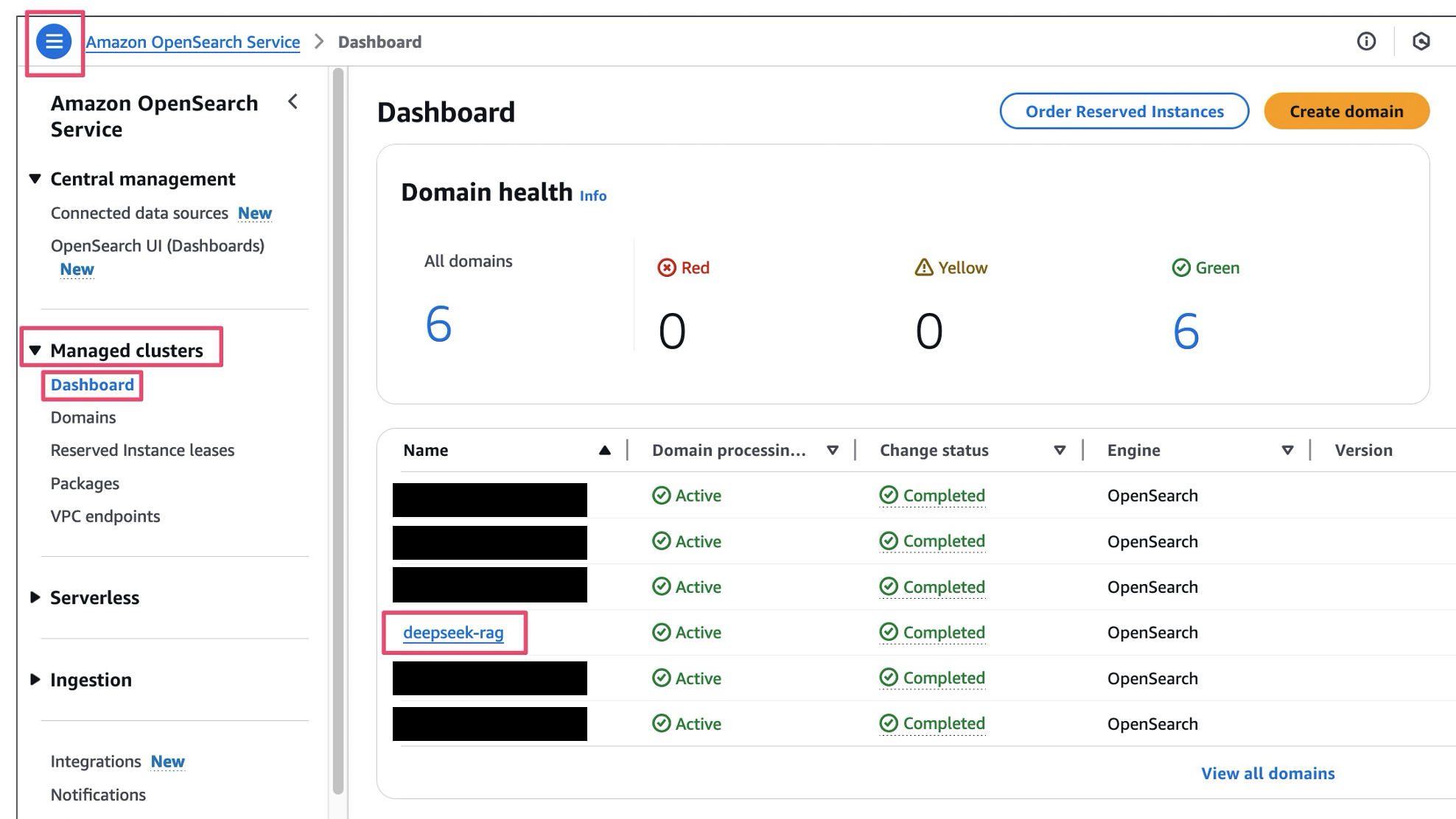
- 选择 OpenSearch Dashboards URL (dual stack) (OpenSearch 控制面板 URL(双堆栈)) 链接以打开 OpenSearch 控制面板。
- 使用您的主要用户名和密码登录 OpenSearch 控制面板。
- 选择 Explore on my own (自行浏览) 来关闭欢迎对话框。
- 关闭“新外观”对话框。
- 在 Select your tenant 对话框中确认全局租户。
- 导航到 Dev Tools 选项卡。
- 关闭欢迎对话框。
您还可以通过展开导航菜单(三行)以显示导航窗格,然后向下滚动到 Dev Tools 来访问 Dev Tools。
Dev Tools (开发工具) 页面提供了一个左窗格,您可以在其中输入 REST API 调用。您执行命令,右窗格显示命令的输出。在左窗格中输入以下命令,将 your_model_id 替换为您创建的模型 ID,然后通过将光标放在命令中的任意位置并选择运行图标来运行命令。
POST _plugins/_ml/models/<your model ID>/_predict{ "parameters": { "inputs": "Hello" }}您应该会看到类似于以下屏幕截图的输出。
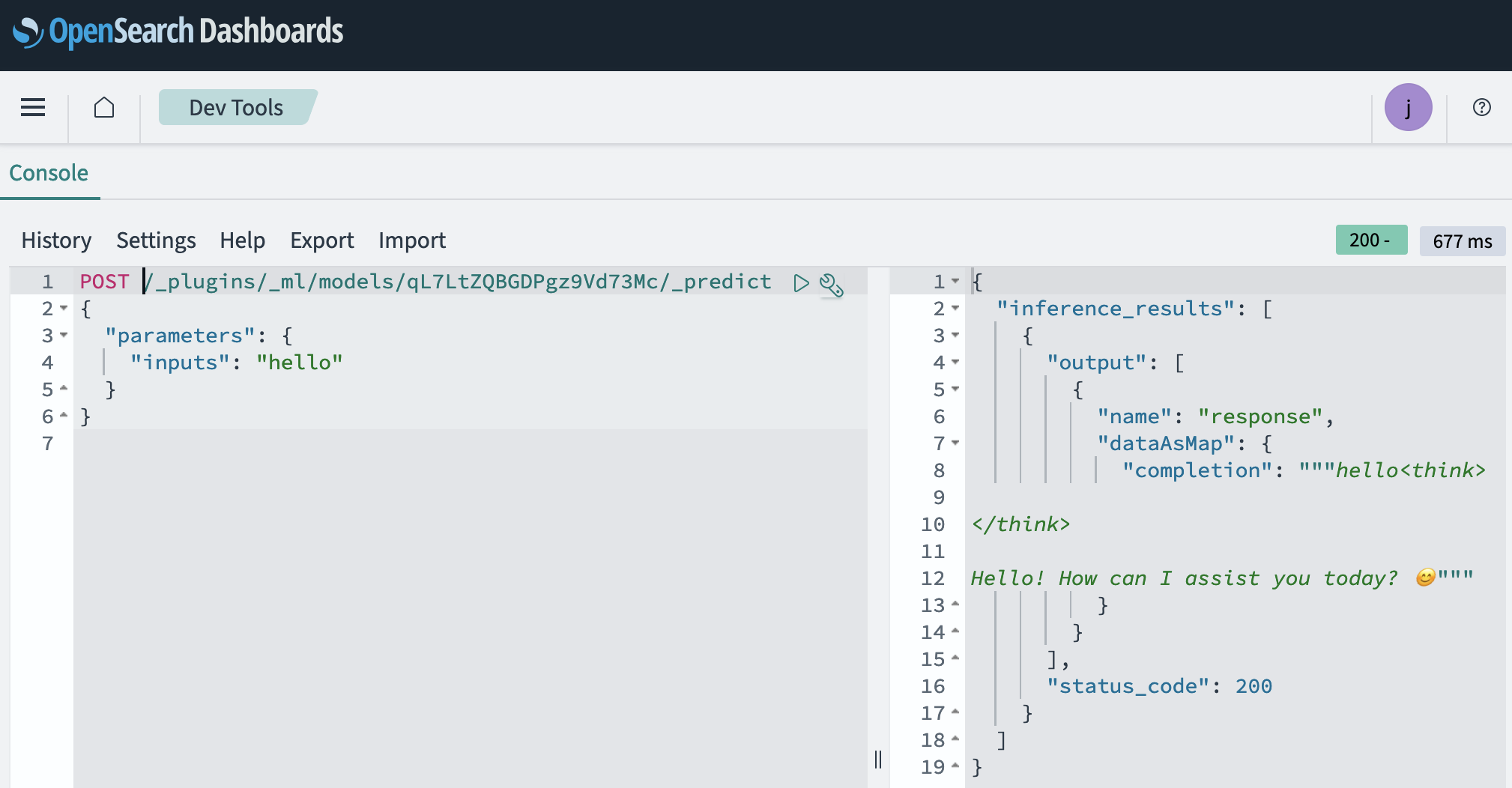
祝贺! 您现在已经创建并部署了一个 ML 模型,该模型可以使用您创建的连接器来调用 SageMaker 终端节点,并使用 DeepSeek 生成文本。接下来,您将在 OpenSearch 搜索管道中使用您的模型来自动化 RAG 工作流程。
设置 RAG 工作流程
RAG 是一种向 Prompt 添加信息的方法,以便LLM生成响应更加准确。像聊天机器人这样的整体生成式应用程序会编排对外部知识库的调用,并使用来自这些来源的知识来增强 Prompt。我们创建了一个包含人口信息的小型知识库。
OpenSearch 提供搜索管道,这些管道是一组 OpenSearch 搜索处理器,按顺序应用于搜索请求以构建最终结果。OpenSearch 具有用于混合搜索、重新排名和 RAG 等的处理器。您定义处理器,然后将查询发送到管道。OpenSearch 以最终结果进行响应。
在构建 RAG 应用程序时,您需要选择知识库和检索机制。在大多数情况下,您将使用 OpenSearch Service 向量数据库作为知识库,执行 k 最近邻 (k-NN) 搜索,以将语义信息与向量嵌入相结合。OpenSearch Service 提供与 Amazon Bedrock 和 SageMaker 中托管的向量嵌入模型的集成(以及其他选项)。
确保您的域运行的是 OpenSearch 2.9 或更高版本,并且已为域启用精细访问控制。然后完成以下步骤:
- 在 OpenSearch Service 控制台上,选择导航窗格中的 Integrations。
- 在 Integration with text embedding models through Amazon SageMaker 下选择 Configure domain (配置域)。
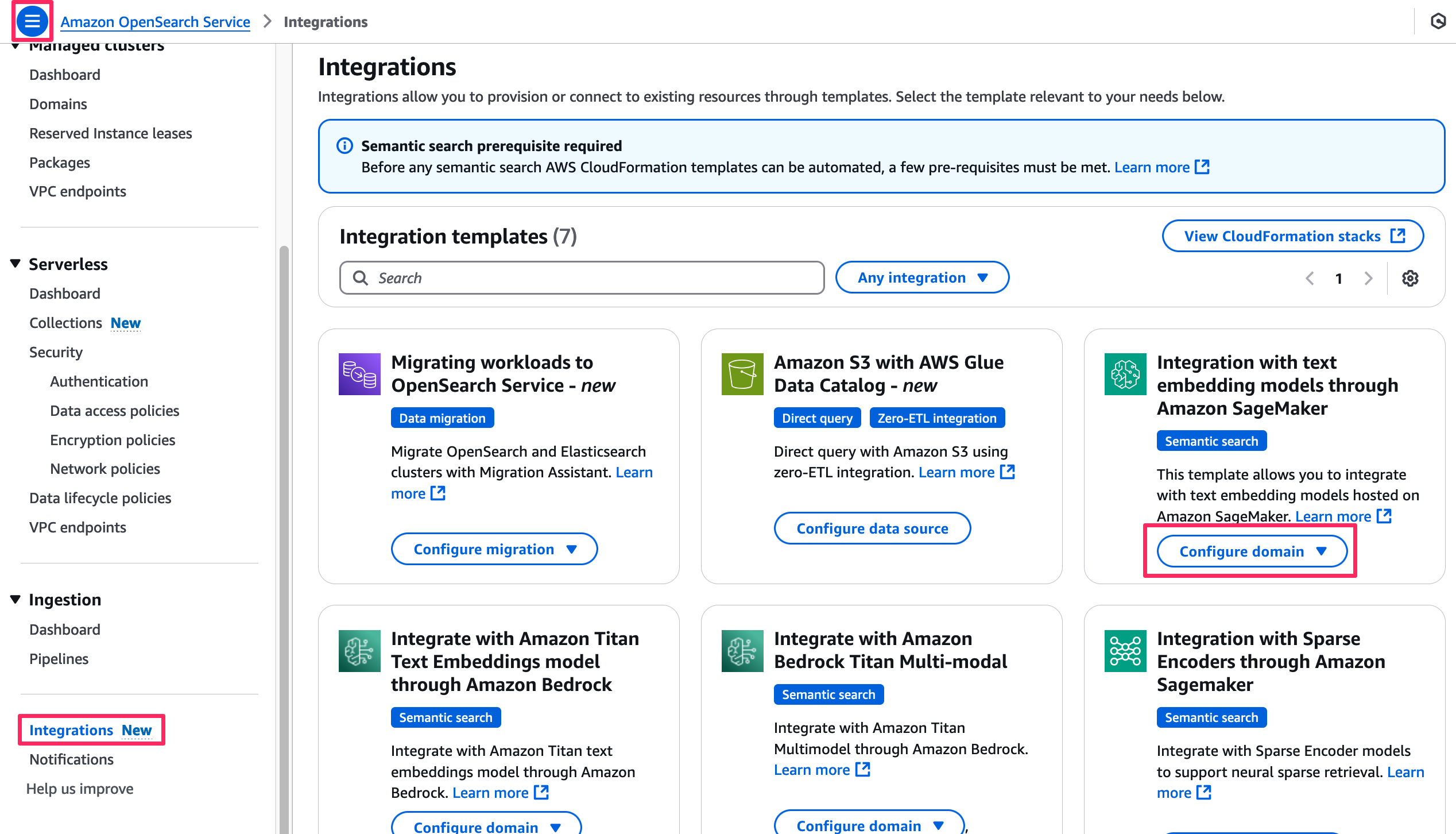
- 选择 Configure public domain (配置公有域)。
- 如果您创建了 Virtual Private Cloud (VPC) 域,请选择 Configure VPC domain (配置 VPC 域)。
您将被重定向到 AWS CloudFormation 控制台。
- 对于 Amazon OpenSearch Endpoint (Amazon OpenSearch 终端节点),输入您的终端节点。
- 将其他所有内容保留为默认值。
CloudFormation 堆栈需要一个角色来创建托管在 SageMaker 上的全 MiniLM-L6-v2 模型的连接器,称为 LambdaInvokeOpenSearchMLCommonsRole。您在运行 setup_opensearch_security.py 时为此角色启用了访问权限。如果您更改了该脚本中的名称,请务必在 Lambda Invoke OpenSearch ML Commons Role Name (Lambda 调用 OpenSearch ML Commons 角色名称) 字段中更改它。
- 选择 I acknowledge that AWS CloudFormation might create IAM resources with custom names(我确认 AWS CloudFormation 可能会创建具有自定义名称的 IAM 资源),然后选择 Create stack(创建堆栈)。
为简单起见,我们选择使用托管在 SageMaker 上的开源全 MiniLM-L6-v2 模型来生成嵌入。为了实现生产工作负载的高搜索质量,您应该微调轻量级模型(如全 MiniLM-L6-v2),或使用 OpenSearch Service 与模型的集成,例如 Amazon Bedrock 上的 Cohere Embed V3 或 Amazon Titan Text Embedding V2,这些模型旨在提供开箱即用的高质量。
等待 CloudFormation 部署您的堆栈,并将状态更改为 Create_Complete。
- 在 CloudFormation 控制台上选择堆栈的 Outputs(输出)选项卡,然后复制 ModelID 的值。
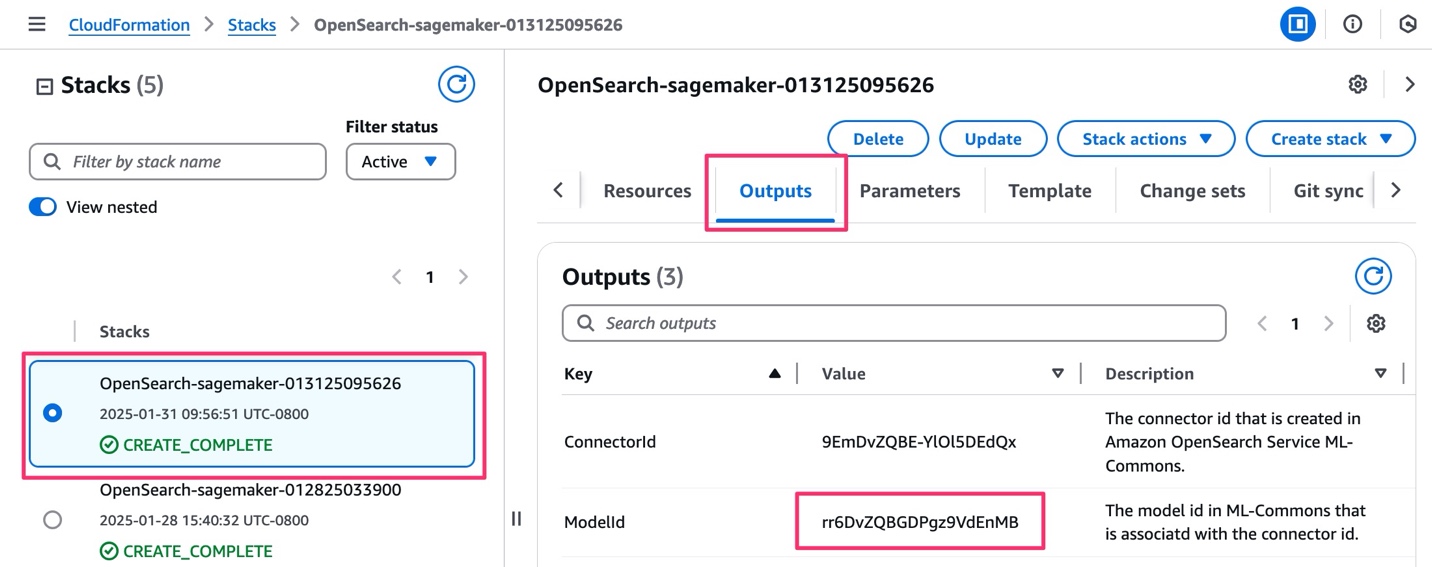
您将使用此模型 ID 与嵌入模型连接。
- 在 load_data.py 中检查代码。
- 返回命令行并使用嵌入模型的模型 ID 设置环境变量:
export EMBEDDING_MODEL_ID='<the model ID from CloudFormation’s output>'- 执行脚本以将数据加载到域中:
python load_data.py该脚本创建 population_data 索引和 OpenSearch 提取管道,该管道使用嵌入模型 ID 引用的连接器调用 SageMaker。提取管道的字段映射告诉 OpenSearch 每个文档嵌入的源字段和目标字段。
现在,您已经准备好了知识库,可以运行 RAG 查询。
- 在 run_rag.py 中检查代码。
- 返回命令行并执行脚本:
python run_rag.py该脚本使用 OpenSearch retrieval_augmented_generation 处理器创建搜索管道。该处理器自动运行 OpenSearch k-NN 查询以检索相关信息并将该信息添加到提示中。它使用 SageMaker 上 DeepSeek 模型的generation_model_id和连接器为用户的问题生成文本响应。OpenSearch 神经查询(run_rag.py 的第 55 行)负责使用 embedding_model_id为 k-NN 查询生成嵌入。在查询的 ext 部分中,您为 LLM.llm_model设置为 bedrock/claude,因为参数化和作与 DeepSeek 相同。您仍在使用 DeepSeek 生成文本。
检查 OpenSearch Service 的输出。用户提出了问题“从 2021 年到 2023 年,纽约市的人口增长是多少?与迈阿密相比,趋势如何?结果的第一部分将命中(OpenSearch 从语义查询中检索到的文档)显示为纽约市和迈阿密的人口统计数据。响应的下一部分包括提示以及 DeepSeek 的答案。
Okay, so I need to figure out the population increase of New York City from 2021 to 2023 and compare it with Miami's growth.
Let me start by looking at the data provided in the search results.
From SEARCH RESULT 2, I see that in 2021, NYC had a population of 18,823,000.
In 2022, it was 18,867,000, and in 2023, it's 18,937,000.
So, the increase from 2021 to 2022 is 18,867,000 - 18,823,000 = 44,000.
Then from 2022 to 2023, it's 18,937,000 - 18,867,000 = 70,000.
Adding those together, the total increase from 2021 to 2023 is 44,000 + 70,000 = 114,000.
Now, looking at Miami's data in SEARCH RESULT 1. In 2021, Miami's population was 6,167,000, in 2022 it was 6,215,000, and in 2023 it's 6,265,000.
The increase from 2021 to 2022 is 6,215,000 - 6,167,000 = 48,000. From 2022 to 2023, it's 6,265,000 - 6,215,000 = 50,000.
So, the total increase is 48,000 + 50,000 = 98,000.Comparing the two, NYC's increase of 114,000 is higher than Miami's 98,000.
So, NYC's population increased more over that period."祝贺! 您已经连接到嵌入模型,创建了一个知识库,并使用该知识库和 DeepSeek 生成了对纽约市和迈阿密人口变化问题的文本响应。您可以调整本文中的代码,以创建自己的知识库并运行自己的查询。
收拾
为避免产生额外费用,请清理您部署的资源:
- 删除 DeepSeek 的 SageMaker 部署。有关说明,请参阅清理。
- 如果您的 Jupyter 笔记本丢失了上下文,您可以删除终端节点:
- 在 SageMaker 控制台上,在导航窗格中的 Inference 下,选择 Endpoints。
- 选择您的终端节点,然后选择 Delete (删除)。
- 删除用于连接到嵌入模型的 SageMaker 的 CloudFormation 模板。
- 删除您创建的 OpenSearch Service 域。
结论
OpenSearch 连接器框架是一种灵活的方式,可让您访问在其他平台上托管的模型。在此示例中,您连接到您在 SageMaker 上部署的开源 DeepSeek 模型。DeepSeek 的推理功能通过 OpenSearch Service 向量引擎中的知识库进行了增强,使其能够回答比较纽约和迈阿密人口增长的问题。
了解有关 OpenSearch Service 的 AI/ML 功能的更多信息,并让我们知道您如何使用 DeepSeek 和其他生成模型进行构建!
作者简介
 Jon Handler 是 Amazon Web Services 的搜索服务解决方案架构总监,总部位于加利福尼亚州帕洛阿尔托。Jon 与 OpenSearch 和 Amazon OpenSearch Service 密切合作,为拥有 OpenSearch 搜索和日志分析工作负载的广泛客户提供帮助和指导。在加入 AWS 之前,Jon 的软件开发人员职业生涯包括四年的大型电子商务搜索引擎编码工作。Jon 拥有宾夕法尼亚大学的文学学士学位,以及西北大学的计算机科学和人工智能理学硕士和博士学位。
Jon Handler 是 Amazon Web Services 的搜索服务解决方案架构总监,总部位于加利福尼亚州帕洛阿尔托。Jon 与 OpenSearch 和 Amazon OpenSearch Service 密切合作,为拥有 OpenSearch 搜索和日志分析工作负载的广泛客户提供帮助和指导。在加入 AWS 之前,Jon 的软件开发人员职业生涯包括四年的大型电子商务搜索引擎编码工作。Jon 拥有宾夕法尼亚大学的文学学士学位,以及西北大学的计算机科学和人工智能理学硕士和博士学位。
 Yaliang Wu 是 AWS 的软件工程经理,专注于 OpenSearch 项目、机器学习和生成式 AI 应用程序。
Yaliang Wu 是 AWS 的软件工程经理,专注于 OpenSearch 项目、机器学习和生成式 AI 应用程序。
作者 Jon Handler 和 Yaliang Wu
发表于 日
