






DeepSeek的成功颠覆了AI行业的底层逻辑——从依赖算力堆砌转向算法驱动效率。但强如DeepSeek仍在技术报告中表示,频繁的数据移动仍然制约了计算效率,建议硬件设计采用近内存计算方法,将计算逻辑放置在HBM(高带宽存储器)附近。



DeepSeek等强调推理的大模型更注重计算效率、延迟和性价比。且AI推理需要在不同的端侧应用,不能单纯堆砌GPU数量。因此内存计算技术等提高计算性能的方法,将成为未来人工智能基础设施长期的探索的方向。
为什么需要内存计算?

内存计算是为了打破冯·诺依曼架构瓶颈而提出的,旨在降低“存储-内存-计算/处理单元”过程数据搬移带来的开销。
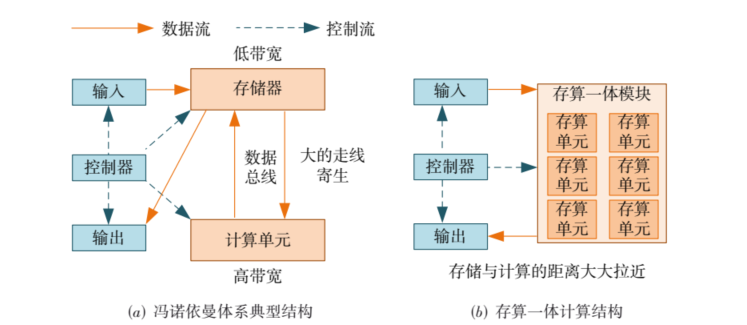
在冯·诺依曼架构中,存储模块是为计算服务的,因此设计上会考虑存储与计算的分离与优先级。具体来讲,数据从存储单元外的存储器获取,处理完毕后再写回存储器,计算核心与存储器之间有限的总带宽直接限制了交换数据的速度,计算核心处理速度和访问存储器速度的差异进一步减缓处理速度。
所以如果能减少数据移动对于性能和功耗的提升是巨大的。
而在过去二十年,处理器性能以每年大约55%的速度提升,内存性能的提升速度每年只有10%左右。长期下来,不均衡的发展速度造成了当前的存储速度严重滞后于处理器的计算速度。

为了逾越“存—算”之间的巨大鸿沟,内存计算的概念应运而生。
内存计算有两种技术类型。一种是横向扩展,主要是全内存分布式计算,例如柏睿数据RapidsDB所代表的技术路线,以内存为数据存储的载体构建新型的系统架构,同时对数据缓存、高效算法以及并行运算等部分开展优化工作,能够达到PB级规模数据存储与实时在线分析,3000亿条数据查询秒级响应。这是一种软件的方案。
另一种是纵向扩展,又分为两种。其一是在架构层面的近数据端处理,包括近存储计算和近内存计算。也就是DeepSeek在技术报告中提到的硬件建议,将计算逻辑放置在HBM(高带宽存储器)附近。如此,使得数据处理能够在数据驻留的地方进行,而非在传统架构中先将数据从内存取出、经过较慢的总线传送到处理器、进行计算后再返回内存。
其二是存算一体,则是在物理层面将计算和访存融合,在存储单元内实现计算,从体系结构上消除了访存操作,从而避免了访存延迟和访存功耗。例如清华大学发布的全球首颗忆阻器存算一体芯片。

内存计算对AI发展的魔力
在AI推导最佳答案的思考过程中,数据的移动和运算会反复进行。AI模型的效率取决于芯片中多个设备间“数据移动的速度”。CPU、GPU、DRAM(动态随机存储器)间数据移动的速度越快,计算时间就越短,能耗也就越低。如果CPU、GPU、DRAM等在物理上彼此相距较远,或者数据传输通道(带宽)较窄,就会在数据传输过程中出现延迟和瓶颈现象。进而造成GPU计算能力浪费、AI训练效率的下降。
内存计算技术大大减少了数据在存储单元和计算单元之间的传输,显著地降低了计算延时和能耗。以其卓越的数据处理速度、效率提升及成本控制能力,在人工智能存储系统中展现出广阔的应用前景。
01
加速模型训练与推理
AI模型的训练和推理过程涉及大量数据的反复读写和计算。内存计算技术通过减少数据在存储器和处理器之间的传输,显著加快参数更新速度,缩短训练时间,同时提高推理过程的响应速度和准确性。例如,在自动驾驶场景中,系统需迅速分析传感器数据以做出即时反应,内存计算技术的高速数据处理能力对此至关重要。
02
降低存储需求与成本
AI大模型需要存储大量数据和模型参数,传统计算架构下,数据频繁传输会占用大量存储器带宽和容量。内存计算直接在存储器中执行计算,减少了数据传输需求,降低了存储需求和成本。此外,内存计算还能高效实现数据压缩与处理,进一步优化存储资源利用。
03
降低能效
内存计算技术通过减少数据传输,降低了计算过程中的能耗。这对于高耗电量的AI应用尤为重要,如数据中心和高性能计算(HPC)场景。三星电子的HBM-PIM技术通过集成可编程计算单元(PCU),在语音识别等AI应用中实现了能耗的大幅降低。



推荐阅读



