




本文对中国人民大学团队论文《ChatPipe: Orchestrating Data Preparation Program by Optimizing Human-ChatGPT Interactions》进行解读,全文共3133字,预计阅读需要10至15分钟。
数据准备是机器学习流程中不可或缺的环节,但其过程通常耗时且需要专业知识。传统工具依赖用户手动编写代码或使用图形化界面,而大型语言模型(如ChatGPT)的出现为自然语言驱动的自动化编程提供了可能。然而,用户在与ChatGPT交互时面临两大挑战:
● 提示(Prompt)的复杂性:用户需要提供具体的提示来指导ChatGPT生成和改进数据准备程序,这要求用户具备一定的编程技能、数据集知识和机器学习任务的理解。
● 版本管理的困难:一旦生成了程序,用户很难回滚到之前的版本或在不重新开始的情况下对程序进行修改。
ChatPipe:ChatPipe通过提供有效的操作建议,帮助用户与ChatGPT协作生成数据准备程序,并允许用户轻松回滚到之前的版本,从而加速数据准备的过程。
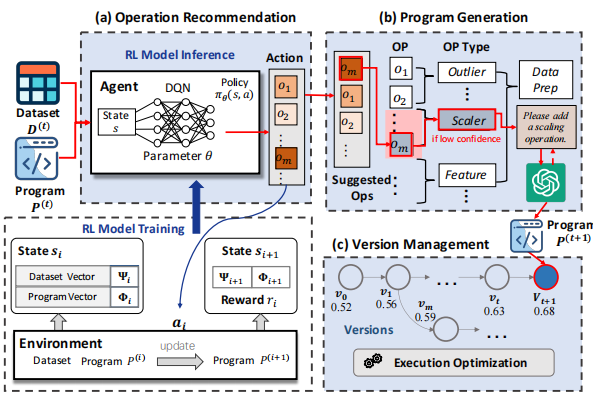
CharPipe架构图
ChatPipe的核心目标是通过优化用户与ChatGPT的交互,帮助用户快速编排高质量的数据准备程序。ChatPipe通过以下三个关键模块实现这一目标:
● 操作推荐(Operation Recommendation):根据当前程序和数据集,ChatPipe推荐最有效的操作来改进机器学习任务的性能。
● 程序生成(Program Generation):ChatPipe与ChatGPT交互,生成无错误的数据准备程序,并有效实现推荐的操作。
● 版本管理(Version Management):ChatPipe可视化由用户与ChatGPT交互生成的多个程序版本,并允许用户快速回滚到之前的版本,以便进行更高效的实验和测试。
1. 操作推荐
核心挑战:操作推荐模块的核心挑战在于如何从众多可能的操作中选择最合适的操作。数据准备操作种类繁多,且每种操作类型下又有多种具体操作(如MinMaxScaler和StandardScaler)。此外,推荐的策略高度依赖于具体的数据集和任务。
问题解决:为了解决这个问题,ChatPipe采用了强化学习(Reinforcement Learning, RL)的方法。具体来说,ChatPipe将操作推荐问题建模为一个序列决策过程,通过离线训练学习如何推荐操作。在推理阶段,给定数据集和当前程序,ChatPipe使用训练好的模型来推荐最合适的操作。
● 状态(State):状态由当前程序和生成的数据集表示。ChatPipe使用统计信息作为数据集特征,并利用预训练的代码表示模型(如UniXcoder)提取程序特征,然后将这些特征拼接起来表示状态。
● 动作(Action):动作是从预定义的操作集合中选择一个操作,该操作将程序转换为下一个程序。
● 奖励(Reward):奖励用于评估所执行的操作是否有效。ChatPipe通过执行程序来评估其性能(如分类器的F1分数)。
DQN:ChatPipe使用深度Q网络(Deep Q-Network, DQN)来优化策略函数。DQN通过神经网络近似值函数,该网络以状态为输入,输出每个动作(即操作)的值。训练过程中,ChatPipe采用 -贪婪策略,通过多轮训练学习如何推荐操作。
-贪婪策略,通过多轮训练学习如何推荐操作。
2. 程序生成
核心挑战:程序生成模块的核心挑战是如何通过自然语言提示指导ChatGPT生成无错误且有效的数据准备程序。ChatPipe通过以下三个组件实现这一目标:
● 操作增强(Operation Augmentation):ChatPipe将操作组织为一个两层层次结构。底层是预定义的细粒度操作(如sklearn.preprocessing.MinMaxScaler),上层是操作类型。根据推荐操作的置信度,ChatPipe选择细粒度操作或粗粒度操作生成提示。
● 程序优化(Program Refinement):用户可以通过注入领域知识或数据准备经验来优化生成的程序。。
● 程序检查(Program Checking):ChatPipe在将生成的程序发送给用户之前,首先在本地运行时环境中运行该程序。如果发现错误,ChatPipe将错误日志发送给ChatGPT,ChatGPT会修复错误并提供更新后的程序。
3. 版本管理
版本管理模块:用户与ChatGPT的交互会生成多个程序版本,包括生成的数据集和相应的提示。为了使用户能够轻松回滚到之前的版本,ChatPipe设计了版本管理模块。该模块包括两个组件:
程序版本控制(Program Versioning):ChatPipe使用关系数据库存储每个机器学习任务的版本信息,包括程序、执行结果和提示。用户可以通过树状结构查看不同版本,并选择任意两个版本进行比较。
数据缓存(Data Caching):由于不同版本的程序可能共享大量代码块,ChatPipe通过缓存中间变量来加速版本切换。ChatPipe使用深度神经网络预测哪些变量值得缓存,并通过抽象语法树(AST)分析变量的计算路径,判断何时可以重用缓存的数据。
1. 强化学习在操作推荐中的应用
强化学习:ChatPipe的操作推荐模块采用了强化学习(Reinforcement Learning, RL)的方法。强化学习是一种通过与环境交互来学习最优策略的机器学习方法。在ChatPipe中,强化学习的应用主要体现在以下几个方面:
● 状态表示:ChatPipe将当前程序和生成的数据集作为状态。为了表示状态,ChatPipe使用了数据集的统计信息和程序的代码特征。代码特征通过预训练的代码表示模型提取,这些特征能够捕捉程序的语义信息。
● 动作空间:动作空间由预定义的操作集合组成。每个操作都会将当前程序转换为下一个程序。操作的选择基于强化学习模型的输出,模型会为每个操作计算一个值,表示该操作对当前状态的潜在贡献。
● 奖励机制:奖励机制是强化学习中的关键部分。ChatPipe通过执行程序来评估其性能,并将该性能作为奖励信号。奖励信号用于更新强化学习模型的参数,从而优化操作推荐策略。
2. 程序生成中的自然语言交互
ChatPipe:ChatPipe的程序生成模块通过与ChatGPT的自然语言交互来实现。ChatGPT是一个基于Transformer架构的大型语言模型,能够根据用户提供的提示生成代码。ChatPipe通过以下方式优化与ChatGPT的交互:
● 提示生成:ChatPipe根据推荐的操作生成相应的提示。提示可以是细粒度的(如“使用StandardScaler进行特征缩放”)或粗粒度的(如“生成交互特征”)。ChatPipe根据操作的置信度选择提示的粒度,从而确保生成的代码既准确又灵活。
● 错误修复:ChatPipe在生成代码后,会首先在本地运行时环境中执行代码。如果发现错误,ChatPipe会将错误日志发送给ChatGPT,ChatGPT会根据错误信息修复代码并生成更新后的程序。这一过程可以迭代进行,直到生成的代码无错误为止。
3. 版本管理中的数据结构与优化
版本管理模块:版本管理模块是ChatPipe的重要组成部分,它允许用户轻松回滚到之前的程序版本,并通过数据缓存加速版本切换。为了实现高效的版本管理,ChatPipe采用了以下技术:
● 版本树:ChatPipe使用关系数据库存储每个机器学习任务的版本信息,并将版本组织为树状结构。每个版本节点包含程序、执行结果和提示信息。用户可以通过树状结构查看不同版本,并选择任意两个版本进行比较。
● 数据缓存:由于不同版本的程序可能共享大量代码块,ChatPipe通过缓存中间变量来加速版本切换。ChatPipe使用深度神经网络预测哪些变量值得缓存,并通过抽象语法树(AST)分析变量的计算路径,判断何时可以重用缓存的数据。
实际应用:为了展示ChatPipe的实际应用效果,本文提供了多个案例分析。其中一个典型案例是糖尿病预测任务。该任务的目标是根据患者的诊断测量数据预测其是否患有糖尿病。ChatPipe通过以下步骤帮助用户完成数据准备:
● 初始代码生成:用户上传糖尿病数据集,并通过ChatPipe生成初始代码。初始代码包括数据加载、特征提取和标签准备等基本操作。
● 操作推荐与代码更新:ChatPipe分析数据集,检测到Glucose和BloodPressure列中的异常值(如0值),并推荐用户进行异常值处理。用户确认操作后,ChatPipe生成更新后的代码,并执行该代码以评估性能。
● 版本管理与回滚:ChatPipe存储所有更新和执行的程序版本,用户可以查看不同版本的执行结果(如F1分数),并通过版本树回滚到之前的版本。
通过这一案例,ChatPipe展示了其在数据准备程序编排中的强大能力。用户无需具备深厚的编程技能,即可通过自然语言交互生成高质量的数据准备程序。
优势:ChatPipe通过优化用户与ChatGPT的交互,显著简化了数据准备程序的编排过程。它不仅能够推荐有效的操作,还能生成无错误的程序,并允许用户轻松管理多个版本。ChatPipe的出现为领域专家提供了一个强大的工具,使他们能够更高效地完成机器学习任务中的数据准备工作。
未来,ChatPipe可以在以下几个方面进行进一步改进:
● 扩展操作支持:ChatPipe可以扩展支持更多类型的操作,如数据增强、数据采样等,以满足更广泛的数据准备需求。
● 自动化提示生成:当前的提示生成依赖于用户输入的领域知识。未来可以探索如何自动生成更智能的提示,减少用户的手动输入。
● 跨领域通用性:虽然ChatPipe在多个领域的数据集上进行了测试,但其通用性仍需进一步验证。未来可以在更多领域的数据集上进行测试,以确保其广泛适用性。
总结:ChatPipe为数据准备程序的编排提供了一种全新的解决方案,极大地降低了数据准备的复杂性和时间成本,使得领域专家能够更高效地完成机器学习任务。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





