




关注我们
开篇
数据仓库是大数据应用最重要的一个使用场景,目前几乎所有的信息化公司都已将企业中传统的数仓转变升级为大数据数仓。其中不止数据量的变化,还有数据形态和技术栈的改变。
下面我们以某电商数据仓库的技术架构搭建为样例,来学习了解大数据数仓的技术应用。其中根据实际情况,用到了大数据应用的主要技术栈,供大家整体了解应用的方方面面。
该电商大数据应用平台主要服务于大数据统计和上层决策。
目录
01
数仓的描述
02
搭建大数据平台的技术架构
03
数据仓库分层的描述
04
可视化展示
01
数仓的描述
既然我们通篇是围绕数据仓库来写的, 那就先以官方的一段定义来复习下数据仓库的定义:
数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
数据仓库,并不是数据的最终目的地,而是为数据最终的目的地做好准备。这些准备包括对数据的:清洗,转义,分类,重组,合并,拆分,统计等等。
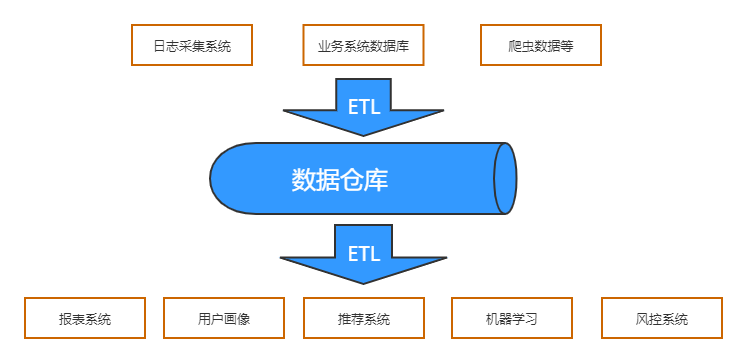
如下图描述,清晰的展示了数据仓库,在业务场景中所处的位置和核心作用。
02
搭建大数据平台的技术架构
我们在做该大数据平台搭建中,会用到现时主流的应用组件,让读者明白平时说的大数据技术栈的各个组件,在工程中所处的具体位置。
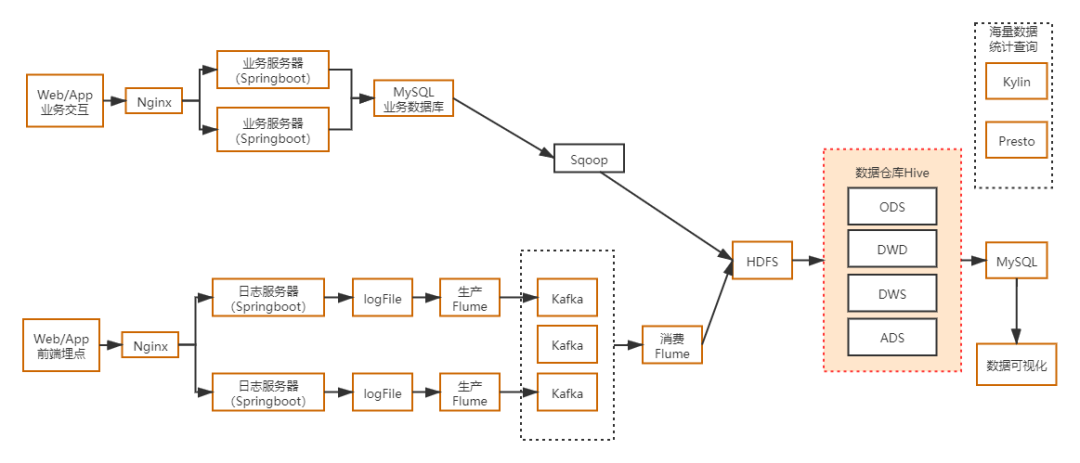
如下为搭建该大数据平台的技术架构:
2.1、数据输入
数据平台最核心的数据来源可以分为两类:
·业务交互数据
业务流程中产生的登录、订单、用户、商品、支付等相关的数据,通常存储在关系型数据库中,包括MySQL、Oracle、DB2等。
·埋点用户行为数据
用户在使用产品过程中,与客户端产品交互过程中产生的数据,比如页面浏览、点击、停留、评论、点赞、收藏等,这些数据为日志数据。包括行为、时间戳等。
2.2、数据转换
从技术架构图中我们看到,对于业务交互数据,因为数据比较规整,由业务系统直接产生,可进入结构化数据库MySQL。然后通过Sqoop组件,从MySQL数据库导入HDFS文件系统。
对于用户行为数据,日志服务器从Nginx日志获得,结构相对复杂,一般以json形式存储。通过Flume组件,将日志文件数据导入到HDFS文件系统中。
因为日志数据量巨大,导入HDFS前一般会使用分布式Kafka消息队列,主要起到数据削峰的作用
2.3、数据存储
分布式文件系统HDFS作为海量数据的存储系统。
2.4、数据仓库Hive
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
数据仓库的搭建,都以分层的结构来进行。如下图为常见的一种分层结构:
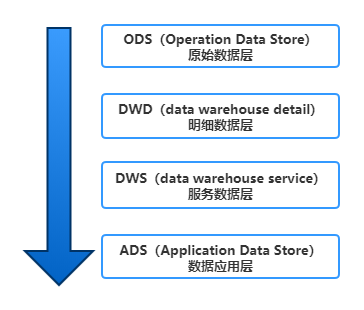
ODS层: 原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理。
DWD层:结构和粒度与原始表保持一致,对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据)
DWS层:以DWD为基础,进行轻度汇总。
ADS层:为各种统计报表提供数据
在Hive数仓中的分层,是通过不同的schema来进行区分不同层级。
数据仓库分层基于如下的好处
(1)把复杂问题简单化
将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单、并且方便定位问题。
(2)减少重复开发
规范数据分层,通过的中间层数据,能够减少极大的重复计算,增加一次计算结果的复用性。
(3)隔离原始数据
不论是数据的异常还是数据的敏感性,使真实数据与统计数据解耦开。
2.5、数据查询
关系数据库MySQL存储聚合后的统计数据,用于给可视化展示平台提供数据接口。
在Hive数仓中的查询,除了通过Hive SQL进行即席查询外。可以通过Presto、Druid、Kylin等工具辅助查询,这些工具提供性能更好延迟更低的结果查询方式。
03
数据仓库分层的详细描述
在做数据仓库规划时,我们都希望企业的数据能够有秩序的流转,数据的整个生命周期能够清晰明确的被设计者和使用者感知到。直观来讲,就是不同的表之间要层次清晰、依赖关系直观。
但是大多数情况下,随着业务的深入和项目设计复杂度提高,我们完成的数据体系会变得依赖复杂、层级混乱。我们很可能随着时间推进,做出一套表依赖结构混乱,甚至出现循环依赖的数据体系。
因此,我们需要一套行之有效的数据组织和管理方法来让我们的数据体系更有序,而数据分层就是解决这一问题的很好方法。
2.4节我们已经描述了数据分层的好处。我们以实际应用中所用数据表的划分来看下各个分层中具体放了哪些数据。
3.1、ODS层(原始数据层)
原始数据层存放原始数据,直接加载原始日志和数据,数据保持原貌不做处理。
主要是考虑到后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可,至于数据的去噪、去重、异常值处理等过程放到后面的DWD层来做。
对于行为日志数据,从日志服务器获得的一般为日志文件,比如服务器上按日存储的日志文件
/origin_data/operate_log/2020-09-10
/origin_data/opreate_log/2020-09-11
/origin_data/operate_log/2020-09-12
我们通过Flume组件,将其导入HIVE数据表ods_operate_log, 数据保持原样,一般以json格式保存为一个大字段,并设置时间戳作为分区字段。
ods_operate_log 2020-09-10
2020-09-11
2020-09-12
....
而对于业务交互数据的ODS层,完全按照业务数据库中的表字段,一模一样的创建ODS层对应表。并设置时间戳作为分区字段。
比如订单信息表在ODS层的创建:
hive (business)>drop table if exists ods_order_info;create external table ods_order_info (`id` string COMMENT '订单编号',`total_amount` decimal(10,2) COMMENT '订单金额',`order_status` string COMMENT '订单状态',`user_id` string COMMENT '用户id',`payment_way` string COMMENT '支付方式',`out_trade_no` string COMMENT '支付流水号',`create_time` string COMMENT '创建时间',`operate_time` string COMMENT '操作时间') COMMENT '订单表'PARTITIONED BY (`dt` string)row format delimited fields terminated by '\t'location '/warehouse/business/ods/ods_order_info/';
3.2、DWD层(明细数据层)
结构和粒度与原始表保持一致,并且提供一定的数据质量保证。对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据)。
对于行为日志数据,会将ODS层中JSON数据串进行解析,分成具体的每个字段,并对脏数据做简单的处理。然后加载到DWD层的表中。
如下为在Hive数据仓库中的DWD层创建日志行为表的样例:
hive (business)>drop table if exists dwd_operate_log;CREATE EXTERNAL TABLE dwd_operate_log(`mid_id` string,`user_id` string,`version_code` string,`version_name` string,`lang` string,`source` string,`os` string,....)PARTITIONED BY (dt string)location '/warehouse/business/dwd/dwd_operate_log/';
而业务交互数据的DWD层,对ODS层数据进行判空过滤。并对分类表等进行维度退化,多个级联维度表进行合并成一个大的维度宽表。
如下为在Hive数据仓库中的DWD层创建订单信息表的样例:
hive (business)>drop table if exists dwd_order_info;create external table dwd_order_info (`id` string COMMENT '',`total_amount` decimal(10,2) COMMENT '',`order_status` string COMMENT ' 1 2 3 4 5',`user_id` string COMMENT 'id',`payment_way` string COMMENT '',`out_trade_no` string COMMENT '',`create_time` string COMMENT '',`operate_time` string COMMENT '')PARTITIONED BY (`dt` string)stored as parquetlocation '/warehouse/business/dwd/dwd_order_info/'tblproperties ("parquet.compression"="snappy");
3.3、DWS层(服务数据层)
以DWD为基础,进行轻度汇总。一般聚合到以用户当日,设备当日、商家当日、商品当日等的粒度。
在这一层通常会有以某一个维度为线索、组成跨主题的宽表,比如,一个用户的当日的签到数、收藏数、评论数、抽奖数、订阅数、点赞数、浏览商品数、支付数、退款数、点击广告数等组成的多列表。
以电商为例,这一层通常会有如下表:

我们可以看到,这些DWS层的数据表,做了轻度汇总,基本还是保留在明细数据层面。该层的数据明细已经很容易进行聚合和业务查询分析了。
3.4、ADS层(数据应用层)
ADS层,为各种统计报表提供数据。
相对DWS层,这一层提供更多的数据聚合和计算。统计报表可以直接从这一层数据中抽取数据进行可视化展示。减少了统计报表的计算消耗。
以电商为例,这一层通常会有如下表:

04
数据查询和展示
对于数仓应用层的数据,统计报表会以可视化形式,给到数据分析人员,或顶层决策人员查看。
另外对于各层海量数据的明细查询和聚合查询,也有大量的查询工具辅助使用。
常用的有Presto、Druid、Kylin等。
