





一、为什么要SMP
在HexaDB数据库中,执行计划是通过一系列算子运算来实现的。对于符合设计规范的关系型数据来说,数据行之间不存在依赖关系。这种特征提供给数据库大部分类型算子并行数据处理的机会。
在HexaDB中,存在两种并行数据处理:进程间并行处理与进程内并行处理。所谓进程间并行处理,是通过多个数据处理节点Datanode(即DN)各自管理和处理归属于自己的数据来实现。而进程内并行(即SMP),则是在DN内部,进一步通过实时启动多线程、分割、并行处理所管理的数据。
一般来说,HexaDB完成部署后,DN数目保持不变(扩缩容操作可以改变DN数目,本文中暂不涉及)。这样,进程间并行处理的并发度也就固定不变。显而易见,对具有不同的数据规模、不同的数据分布特征的不同查询作业来说,单一的并发度难免顾此失彼,不是一个普适最优的选择。
与进程间并行处理的并发度保持不变不同,进程内并行通过实时启动线程,分割、并行处理数据。其并行度可以由优化器根据彼时计算机资源利用率来实时调整,或者由用户输入来指定。这就可以根据不同的作业需求,提供不同的并行处理的并发度,以取得预期的系统响应时间、或系统资源利用率。
二、如何实现SMP
在一个完美的并行处理场景中,不仅基础数据之间不存在依赖关系,甚至在计算过程中中间数据也保持相互独立。
这个说法比较拗口,举例来说:在“计算某列MIN/MAX值”的场景中,数据分割后,基表的数据之间不存在依赖关系,但最终MIN/MAX值,需要通过各分割后数据处理结果的汇总、比较才能计算出来。在“获取满足某列条件(比如columnA等于常量A)所有行”的场景中,各分割后数据处理结果并不需要汇总、比较。第二个场景即为完美并行处理场景。(当然第二个场景中最终结果也需要汇总操作,但这里汇总操作并不属于数据库必需操作,只是方便用户使用的操作。其实可以由客户端而不是数据库来完成。)
如上所述,实现SMP的第一步,即实现处理数据的分割。数据分割的要求是:
1. 分割方式是完备的,即所有数据都会被分割、并行处理。不会有数据遗漏。
2. 分割后的数据尽可能均衡。这样可以充分利用计算资源,不会出现资源利用短板。
3.分割方式是确定的,即数据分割后的所属是确定的。通常来说,基表数据可以根据数据文件来进行分割,而中间数据则可以根据它的分布列Hash值来分割。
在实际数据库应用中,不完美的并行处理场景反而更为常见。也就是说,我们需要在SMP中提供数据交换机制,这也是实现SMP的第二步。在HexaDB中,数据交互机制通过Stream算子实现。Stream算子的作用是在不同进程、不同线程(包括同一进程中的不同线程和不同进程中的不同线程)之间交换数据。HexaDB支持如下类型Stream算子:
Redistribute Stream算子:数据交换的双方均为多个线程。
Broadcast Stream算子:数据发送方单一线程,而接收方为多个线程。
Gather Stream算子:与Broadcast相反,数据接收方单一线程,而发送方为多个线程。
三、哪些场景可以应用SMP
如果数据库启用workload自适应管理,或者用户指定Session参数query_dop,HexaDB根据查询SQL结构特征,判断是否可以应用SMP。
这里我们通过例子,说明几类常见的SMP应用场景:
1. 并行扫描
SeqScan与CStoreScan均支持并行扫描。如下例子为CStoreScan并行扫描:
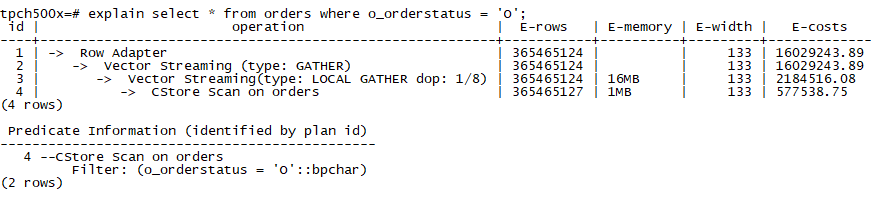
在这个例子中,DN启动8个worker线程对基表执行CstoreScan。
2. 并行扫描+聚合运算
聚合计算包括常见AGG计算。如下例子为并行扫描+SUM/AVG/COUNT计算:
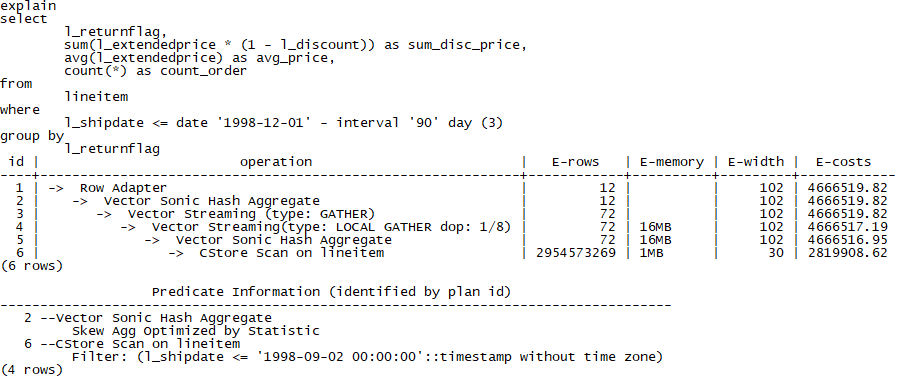
3. 并行扫描+Join
Join可以包括常见Inner/Outer/Anti Join。如下例子为并行扫描+Inner Join:
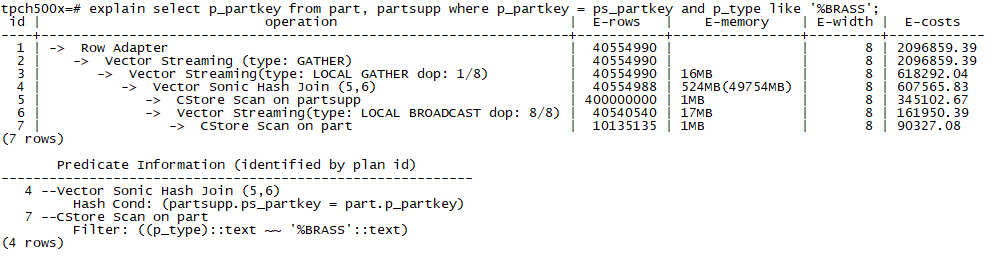
这个例子只有一个Join算子。其实HexaDB支持多层Join算子的SMP处理。这种复杂的例子我们就不再列举了。
四、SMP有哪些限制
基于成本与收效等因素考虑,SMP主要支持AP处理场景。如下操作在通常数据库应用中比较常见,但SMP并不支持(注意这里的列表并不完整。完整的列表可以参考HexaDB产品手册):
1. 索引扫描不支持并行执行。这里的索引扫描既包括单索引扫描,也包括Bitmap索引扫描。
2. Merge Join不支持并行执行。反之NestLoop,Hash Join支持SMP。
3. Cursor不支持并行执行。
4. 存储过程和函数内的查询不支持并行执行。

