




点击下方卡片,关注“慢慢学AIGC”
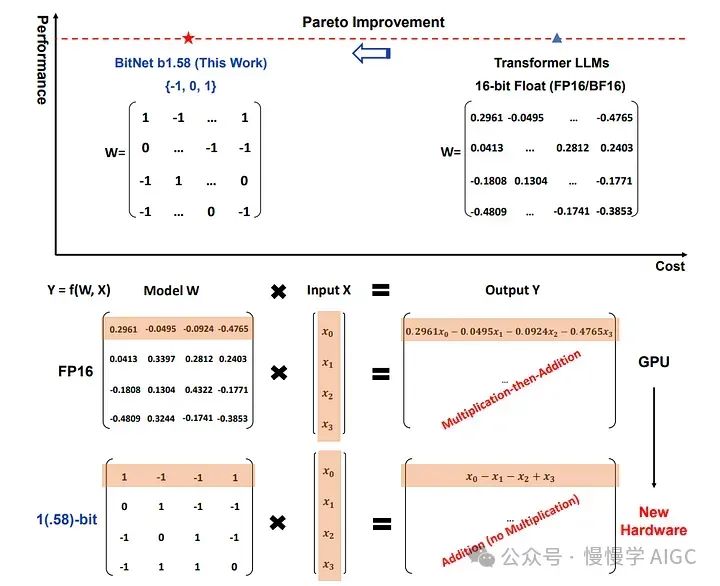
不再使用浮点数,1.58 比特大语言模型的时代
大语言模型(LLM)的世界正在经历一场范式转变,这可能会重新定义这些模型的结构和操作方式。在本文中,我们将深入探讨该领域的一项突破性发展:1.58 比特 LLM 的出现。这一创新挑战了深度学习的传统规范,开辟了效率和可及性的全新途径。
LLM 的现状
在深入探讨 1 比特 LLM 之前,让我们先了解一下 LLM 的现状。LLM 本质上是深度学习模型,实际上是深度神经网络。这些网络由多层神经元组成,层层堆叠在一起,以处理和解释大量数据。
这些网络的运行依赖于所谓的“权重”。这些权重在训练过程中被微调,以类似于矩阵乘法的方式进行相乘。
这一过程需要大量的计算资源,通常需要使用 Nvidia 配备 CUDA 技术的 GPU(图形处理单元)来处理高性能矩阵乘法。
传统 LLM 的局限性
传统的 LLM 主要是 32 位或 16 位模型。这意味着模型中的每个参数都由 32 位或 16 位浮点数表示。浮点数本质上是小数点值,与表示整数的整数不同。位深度(32 位或 16 位)表示这些浮点数的精度水平。然而,这种高精度需要大量的计算能力和内存,使得 LLM 资源密集且不易访问。
1 比特 LLM 的概念
现在,让我们探索 1 比特 LLM 的革命性概念。其核心思想既简单又深远。与其将每个参数表示为 32 位或 16 位浮点数,1 比特 LLM 将其表示为三元值:-1、0 或+1。这一概念并非全新;它借鉴了早期研究如 Microsoft 的 1 比特 Transformer(原始论文见:Arxiv:2310.11453,https://arxiv.org/pdf/2310.11453.pdf)。然而,在 LLM 背景下的实现是一个新颖且具有变革性的步骤。
1 比特 LLM 的影响
减少计算需求:1 比特 LLM 最直接的影响是显著减少计算资源的需求。这使得 LLM 更易于访问和负担得起,有可能使先进的 AI 技术更加民主化。
能源效率:由于计算需求减少,1 比特 LLM 本质上更加节能。在 AI 系统能耗日益成为关注焦点的时代,这是朝着可持续 AI 发展的关键一步。
边缘计算的潜力:1 比特 LLM 的低资源需求使其成为边缘计算应用的理想选择,因为边缘计算资源有限。
性能:令人惊讶的是,论文表明 1 比特 LLM 的性能可与传统 LLM 媲美。这意味着我们可以在大幅减少资源消耗的情况下实现相似的效率和准确性。
通过将零作为潜在值之一,除了 +1 和 -1 之外,我们从纯粹的二元表示(如在 1 比特 Transformer 中看到的)转变为三元表示。这种从 1 比特到所谓的 1.58 比特(log2(3)=1.5849625……)的转变不仅仅是一个数字上的调整;它在模型的学习能力上引入了根本性的变化。
数学基础
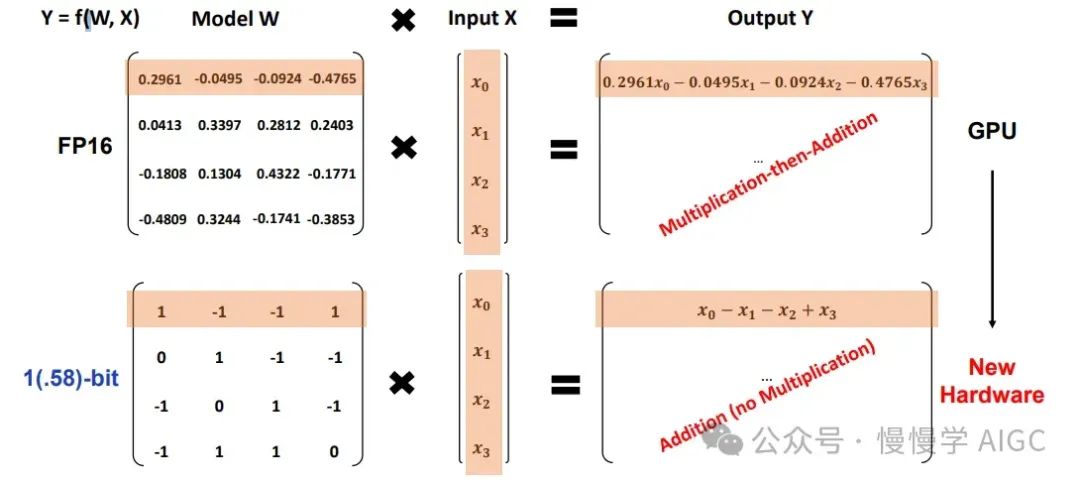
在传统深度学习神经网络中,计算的核心在于矩阵乘法,通常表示为点积。这涉及按方程Y=f(W, X)将模型的权重(W)与输入(X)相乘和相加。这一过程虽然有效,但计算密集,形成了传统 LLM 对 GPU 依赖的基础。
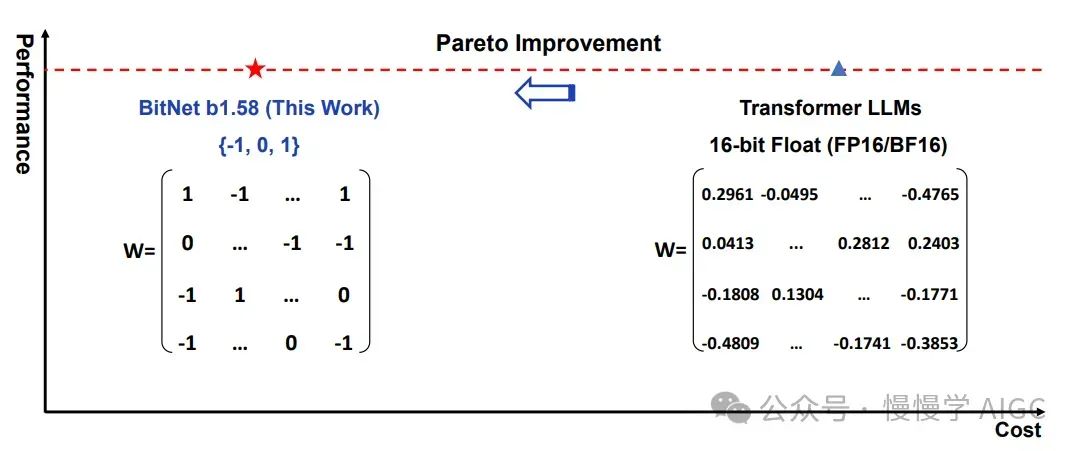
三元值(+1、-1、0)的引入从根本上改变了这个方程。使用这些整数表示,模型可以显著减少,甚至在某些情况下完全消除乘法的需求,主要依赖于加法。这种减少不仅是计算上的方便;它代表了 LLM 结构和执行方式的范式转变。
对硬件和性能的影响
通过减少乘法的需求,1.58 比特 LLM 大大减少了对专用硬件如 GPU 的依赖。这为专门为这些新型计算过程优化的新型硬件打开了大门。如 Groq 等公司已经在这一领域率先开发针对这些新计算过程优化的硬件。
1.58 比特 LLM 的潜力
1.58 比特方法不仅减少了计算需求;还增强了模型的学习能力。零值的加入允许更细致地表示参数,可能导致更高效的学习过程。这种效率并不以性能为代价;早期迹象表明这些 1.58 比特模型可以达到其高位对手的性能。
深度学习中 GPU 的故事提供了一个有见地的平行。最初为游戏设计,后来被加密货币矿工采用,GPU 由于其处理矩阵乘法的效率而成为 AI 的主要工具。这一转变部分归功于 Nvidia 的 CUDA 技术,使其 GPU 成为深度学习应用的理想选择。
软件和算法创新
除了硬件,软件和算法也有巨大的创新潜力。1.58 比特架构挑战现有规范,鼓励开发新的优化技术。这篇论文不仅仅是理论上的练习;它实证展示了 LLM 如何在高性能和成本效益之间取得平衡。
性能、延迟和能效
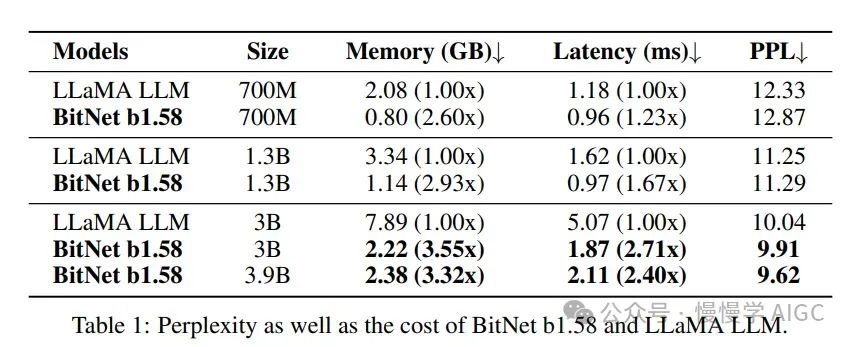
为了将这些理论付诸实践,研究人员将 1.58 比特模型与基于 Llama 的 LLM 架构进行了比较。为了确保公平,他们从头开始在类似 Llama 数据集的数据集上训练模型。结果令人印象深刻,不仅在生成连贯文本(通过困惑度衡量)方面,还在执行如问答等下游任务时表现出色。
在分析 1.58 比特 LLM 的性能时,与 Llama LLM 在各种参数上的比较显示了惊人的结果。研究检查了 700M、13 亿和 30 亿参数的模型,发现 1.58 比特模型在许多情况下不仅匹配而且超过了等效的 Llama 模型的性能。
困惑度和下游任务
困惑度是衡量模型预测下一个词能力的关键指标。困惑度越低,模型性能越好。1.58 比特 LLM 在困惑度方面几乎相当,有些情况下甚至低于 Llama LLM,尤其是在最大的 30 亿参数模型中。除了下一个词预测,这些模型还在各种下游任务如问答和文本摘要上进行了测试,使用如 ARCe、HS 等指标。1.58 比特模型在这些方面表现也很出色。
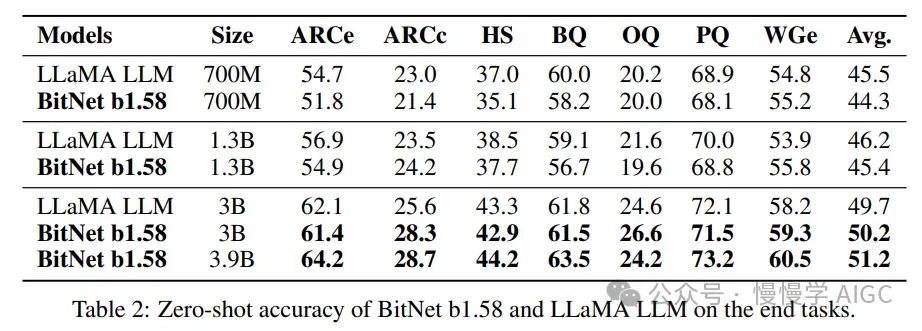
Transformer 架构以及 Bit Linear 层
值得注意的是,Llama 和 1.58 BitNet 均基于 Transformer 架构。关键区别在于权重中的数字表示和计算方法。1.58 BitNet 使用 Bit Linear 层代替传统的矩阵乘法,显著简化了计算过程。
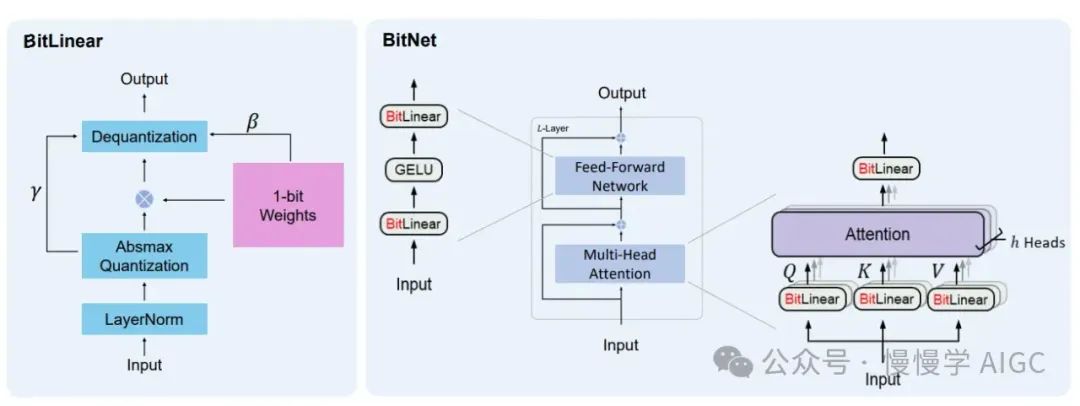
延迟和吞吐量的改进

1.58 比特模型的一个最显著优势是延迟和吞吐量的改进。研究显示,延迟改进了 2.7 倍到 2.4 倍,吞吐量则惊人地提高了九倍,70B 参数模型生成速度达 2977 tokens/s。这一性能明显高于当前行业标准,包括 Groq 设定的标准。
多样化硬件平台的潜力
1.58 比特架构的简洁性可能减少了对复杂硬件如 GPU 的需求,开启了在各种平台上运行这些模型的可能性,包括移动和边缘设备。这一发展可能会使 AI 民主化,使强大的 LLM 在较弱的硬件上也能访问。
缩放定律和未来前景
这一突破重新定义了 LLM 的缩放定律,展示了如何在大大减少硬件需求的情况下有效运行模型。使用 1.58 比特架构,传统上以 16 位浮点值表示的 40 亿参数模型现在可以以更高效的方式表示。这一转变意味着效率的 8-15 倍改进,这是 AI 和深度学习领域的巨大进步。
结论
1.58 比特 LLM 的出现标志着 AI 技术进化中的一个关键时刻。凭借其令人印象深刻的性能指标、减少的硬件需求和能源效率,这些模型有望革新 LLM 的开发和部署方式。这一创新为更易访问、更高效和可持续的 AI 铺平了道路,开辟了新的应用和研究途径。我们热切期待在这一突破性工作基础上进一步发展的进展。请继续关注 AI 这一激动人心领域的更多见解和发展。
