




点击下方卡片,关注“慢慢学AIGC”

大型语言模型的力量比你想象的更强大
在开始这篇文章之前,我想说我没有任何偏见。如果你在网上进行批判性搜索,你会发现无数其他文章和经历都在解释强化学习根本无法用于真实世界的用例。唯一说相反观点的是该领域的课程创建者和学者。
我是真心希望强化学习能成功的。5 年前,当我第一次听说强化学习时,人们许诺它将革新整个世界。只需一个设计巧妙的奖励机制,就能优化任何事物,这种算法似乎可以被广泛应用于从设计药物到高级机器人等各个领域。2016年,当 AlphaGo 在围棋比赛中击败李世石时,这应该是强化学习开始主导的转折点。
然而,8 年后的今天,这一切都没有实现。强化学习在现实世界中一事无成。它在玩具问题和电子游戏上占据主导地位,但仅此而已。强化学习在过去 8 年里唯一值得注意的进展是"人类反馈强化学习"(RLHF),它被用于训练像 ChatGPT 这样的大型语言模型。但在我看来,我们不会长期使用它,因为其他算法做得更好。
我糟糕的强化学习经历
我也曾被强化学习的炒作所迷惑。这源于我在康奈尔大学上的一门"人工智能导论"课程。我们简单地讨论了强化学习以及它能解决什么样的问题,我对此产生了浓厚的兴趣。我决定在阿尔伯塔大学线上学习一门深入的强化学习课程。我获得了该课程的证书,这证明了我在这一领域的专业知识和水平。

从康奈尔大学毕业后,我去了卡内基梅隆大学攻读软件工程硕士学位。由于对深度学习感兴趣,我选修了著名的困难课程"深度学习导论"。正是在这门课中,我得以将强化学习应用于一个真实世界的问题。
在该课程中,我们有一个期末项目。我们可以自由实现任何深度学习算法,并撰写一篇论文分享经验。我决定将我对金融的热爱与对强化学习的兴趣结合,实现一种用于股市预测的深度强化学习算法。
该项目彻底失败了。搭建环境极其困难,而一旦完成,总会出现各种各样的问题。调试问题也很痛苦,因为一旦所有东西都编译运行,你就不知道是哪个部分出了问题。可能是学习状态到行动映射的 Actor 网络出了问题,也可能是学习这些状态-行动对的"价值"的 Critic 网络出了问题,也可能是神经网络的超参数设置不当,或其他任何原因。
我不是因为项目失败而对强化学习感到生气。如果一组研究生在一个学期就能制作出一个广泛盈利的股票交易机器人,那将颠覆整个股市。不,我之所以对强化学习感到生气,是因为它太糟糕了。我将在下一节解释更多。
查看该项目的源代码可在此仓库【1】找到。你也可以在这篇论文【2】中阅读更多技术细节。
为什么强化学习很糟糕?
强化学习存在着许多问题,这使它无法应用于现实世界场景。首先,它极其复杂。虽然传统的强化学习还勉强说得通,但深度强化学习完全说不通。
作为回顾,我上过常春藤盟校。大多数朋友和熟人都会说我很聪明。但深度强化学习让我感到很蠢。它涉及了太多专业术语,除非你正在攻读相关的博士学位,否则你无法完全理解。有"Actor 网络"、"Critic 网络"、"策略"、"Q 值"、"剪裁的替代目标函数"等等听起来没有任何意义的术语,每当你尝试做任何实际操作时都需要查阅字典。
它的复杂性不仅体现在难以理解的术语上。每当你试图为比 CartPole 更复杂的问题设置强化学习时,它就不起作用了,而你也不知道为什么。
例如,当我做那个使用强化学习预测股市的项目时,我尝试了几种不同的架构。我不会在这里过多讨论技术细节,如果你想了解的话,可以查看这篇文章【3】《即使失败也是一种成功 - (未能)创建一个强化学习股票交易智能体》。但无论我尝试什么,都没有成功。在文献中,你可以看到强化学习存在许多问题,包括计算量大、稳定性和收敛性问题,以及样本效率低下,这很荒谬,因为它使用了深度学习,而深度学习以擅长处理高维大规模问题而闻名。就我的交易项目而言,最终影响结果的是神经网络的初始化种子,这实在太可悲了。
为什么 Transformer 将取代强化学习算法?
Transformer 解决了传统强化学习算法的所有问题。首先,它可能是最简单、最实用的人工智能算法了。一旦你理解了注意力机制,就可以开始在 Google Colab 上实现 Transformer 了。最棒的是,它真的有用。
我们都知道 Transformer 在实现类似 ChatGPT 这样的模型时很有用。但大多数人没有意识到,它也可以用来取代传统的深度强化学习算法。
我最喜欢的论文之一是 Decision Transformer。我是如此喜欢这篇论文,以至于我给作者们发了电子邮件。Decision Transformer 提供了一种全新的思考强化学习的方式。与其使用涉及多个神经网络、敏感的超参数以及没有理论基础的启发式算法进行复杂的优化,不如使用一种已被证明在许多问题上行之有效的架构——Transformer。
"Decision Transformer"的架构
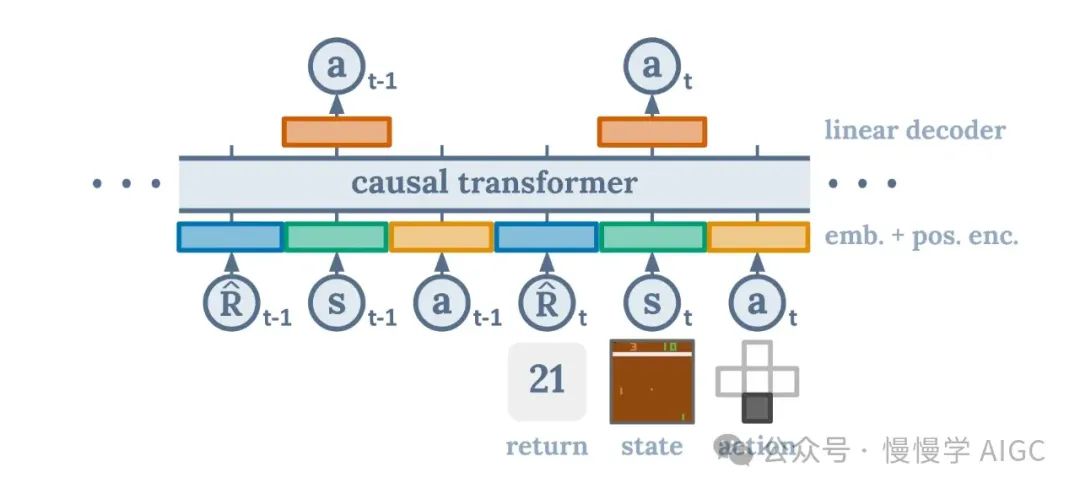
我们基本上希望将强化学习重新构建为一个序列建模问题。我们仍然拥有状态、行为和奖励,就像传统强化学习一样。我们只是以不同的方式来构建问题。我们以自回归的方式展开状态、行为和奖励序列。这导致了一个非常自然和高效的框架,在这里 Transformer 理解和预测序列的能力被利用来找到最佳行为。通过这种方式构建问题,Decision Transformer 能够有效地解析状态、行为和奖励的序列,并直观地预测最佳行为路径。这种算法优雅地绕过了传统强化学习方法中经常遇到的复杂性和不稳定性,无缝地发现最有效的策略。
为了保持透明,这是一种离线算法,这意味着它无法实时工作。然而,还有一些额外的工作正在进行,以便 Decision Transformer 能够以在线方式使用。即使是这种离线版本的算法,也比传统的强化学习算法好得多。这篇论文表明,这种架构更加健壮,尤其是在奖励稀疏或有干扰的情况下。此外,这种架构非常简单,只需要一个网络,并且与最先进的强化学习基线算法相匹配或更胜一筹。
要了解更多关于 Decision Transformer 的细节,你可以查看原始论文【4】或 Yannic Kilcher 制作的这个极为有帮助的视频【5】。
总结
传统强化学习太糟糕了。除非该行业推出一种全新的、稳定的、样本高效的算法,而且不需要博士学位就能理解,否则我永远不会改变这种看法。Decision Transformer 才是新的强化学习,它只是目前还不太流行。我期待有一天研究人员开始采用它,并将其应用于各种任务,包括人类反馈强化学习。
谢谢您的阅读!
作者简介

作者 Austin Starks,Medium 专栏《Artificial Intelligence in Plain English》作家, 高度技术性和有抱负。正在构建一个无代码算法交易平台和一个人工智能应用生态系统:https://nexusgenai.io。
参考资料
【1】https://github.com/austin-starks/Deep-RL-Stocks
【2】Deep Reinforcement Learning on the Stock Market for Real-World Trading, Google Docs link :
https://drive.google.com/file/d/1x67IaLpErVw9SwSBjWAdDtNEOcQSgje_/view?pli=1
【3】Even a Failure is a Success — (Failing to) Create a Reinforcement Learning Stock Trading Agent, https://nexustrade.io/blog/even-a-failure-is-a-success--failing-to-create-a-reinforcement-learning-stock-trading-agent-20231211
【4】Decision Transformer: Reinforcement Learning via Sequence Modeling. https://arxiv.org/pdf/2106.01345
【5】Decision Transformer: Reinforcement Learning via Sequence Modeling (Research Paper Explained)
https://www.youtube.com/watch?v=-buULmf7dec
点击下方卡片,关注“慢慢学AIGC”
