




点击下方卡片,关注“慢慢学AIGC”

昨天被英伟达铺天盖地的报道刷屏,只有零星的有关 AMD 的信息。6 月 3 日上午,Lisa Su(苏姿丰,业内人称“苏妈”)博士在 2024 年 Computex 开场主题演讲中阐述了 AMD 及其合作伙伴如何通过下一代高性能 PC、数据中心和 AI 解决方案来推动创新的最新进展。
太长不看版
这次发布会主要有三个重要更新:

世界上最强大的桌面游戏处理器
推出新的 AMD Ryzen 9950X 桌面 PC 处理器,这是发烧友最先进和最强大的选择,堪称世界之最。
面向 AIPC 的 Ryzen™ AI 300系列处理器
在由 AMD Ryzen AI 300 处理器驱动的先进人工智能 PC 上,沉浸于生成式人工智能工具和数字助理的世界。
扩展数据中心加速器 AMD Instinct™ MI300X
新的 AMD Instinct™ MI325X 加速器有助于在单个 AMD Instinct 平台上容纳 1 万亿参数的模型。
接下来我们仔细观摩下苏妈带来的重磅内容。
桌面游戏处理器:Ryzen 9950X

世界各地数亿游戏玩家使用 AMD 技术。从最新的索尼和微软游戏主机,到高端游戏 PC,再到新的掌机设备如 Steam Deck、Legion Go 和 ROG Ally。全新的 Ryzen 9000 CPU 是世界上最快的消费级 PC 处理器,将 AMD Zen 5 核心带到了 AM5 平台,支持最新的 IO 和内存技术,包括 PCIe 5 和 DDR5。

Zen 5 实际上是高性能 CPU 的又一重大飞跃。这是一款从头开始设计的产品,不仅性能出众,而且能效卓越。从超级计算机到数据中心和 PC 等各个领域看到 Zen 5 的身影。
拥有新的并行双流水线前端,可提高分支预测准确性并降低延迟。它还使我们能够在每个时钟周期提供更多性能。Zen 5 设计了更宽的 CPU 引擎和指令窗口,以并行运行更多指令,实现领先的计算吞吐量和效率。

与 Zen 4 相比,在广泛的应用程序基准测试和游戏中,指令每周期性能(IPC)平均提高了 16%。

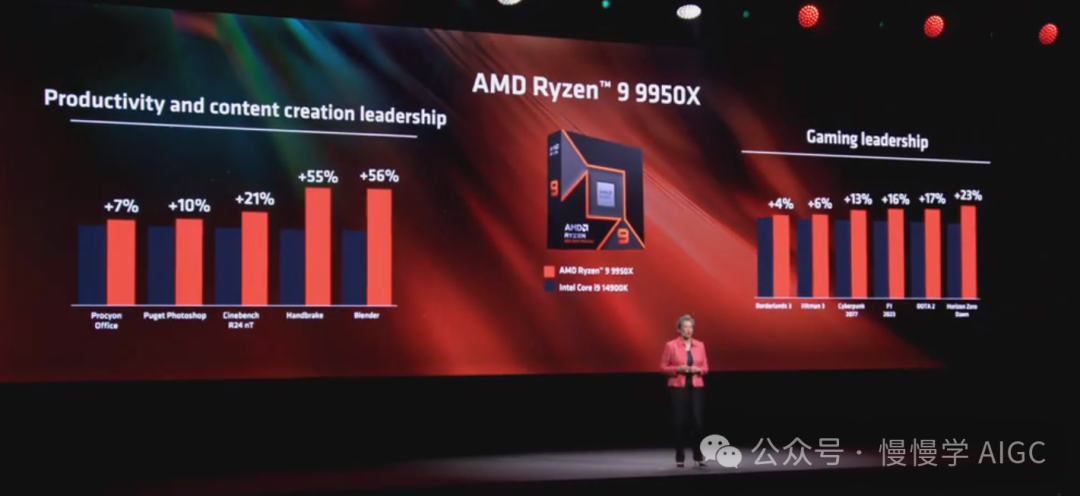
旗舰 Ryzen 9 9950X 拥有 16 个 Zen 5 核心、32 个线程、高达 5.67 GHz 的增强频率、80 MB 缓存,TDP 为 170 瓦。这是世界上最快的消费级 CPU。


与竞争对手相比,9950X 在广泛的内容创作软件中提供了明显更高的计算性能。在某些软件中,如 Blender,它利用了 AVX 512 指令吞吐量,实际上比竞争对手快 56%。在 1080P 游戏中,9950X 在各种流行游戏中提供了一流的游戏性能。
最初的 Ryzen 平台 Socket AM4 于 2016 年推出,现在已接近第九年,在该平台上共推出了 145 款 CPU 和 APU,分属 11 个不同的产品系列。下个月将推出几款 Ryzen 5000 CPU。AMD 在 Socket AM5 上采用了完全相同的策略,计划支持到 2027 年及以后。

除了旗舰 Ryzen 9950X 之外,AMD 还推出了 12 核、8 核和 6 核版本,以将 Zen 5 的领先性能带到主流价位,所有这些产品将于 2024 年 7 月上市。

AI PC 处理器:Ryzen AI
苏妈全程气定神闲,成竹在胸。和老黄演讲中的天马行空奇思妙想最大的不同在于,她似乎总能猜到大家在想什么,谈笑间充满了普通人生活烟火气息。

话锋一转,从台式机转向笔记本电脑。今年 Computex 有很多关于笔记本电脑的讨论。自从去年 1 月推出了第一代 Ryzen AI 以来,AMD 实际上一直在推动向 AI PC 的过渡。
AI 正在彻底改变我们与 PC 交互的方式。它支持更智能、更个性化的体验,将使 PC 成为我们日常生活更不可或缺的一部分。AI PC 能够实现以前根本不可能实现的许多新体验。这些包括:
实时翻译,让我们能够以新方式协作;
生成式 AI 功能,可加速内容创作;
每个人自己定制的数字助理,真正帮助我们决策下一步的行动。
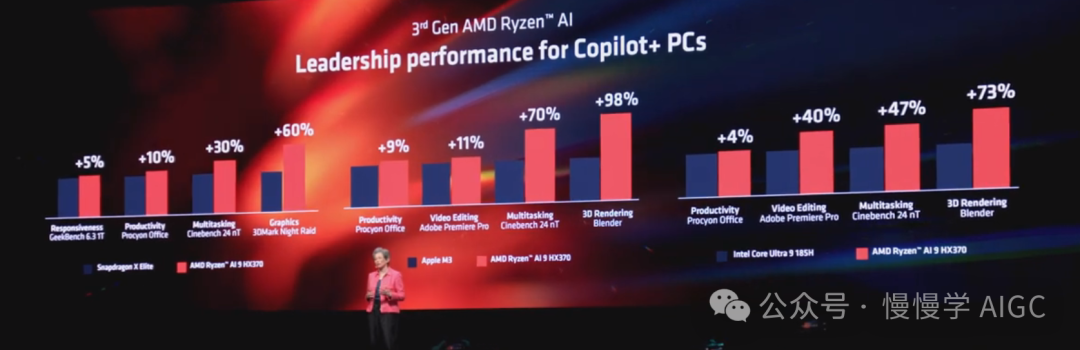
要实现所有这些,我们实际上需要更出色的AI硬件。这就是第三代 Ryzen AI 处理器的用武之地。新的 Ryzen AI 系列在计算和 AI 性能方面有了重大提升,为协作 PC 设定了新标准。Strix 是面向超薄和高端笔记本电脑的下一代处理器,它结合了 AMD 新的 Zen 5 CPU、更快的 RDNA 3.5 显卡和新的 XDNA 2 NPU。


全新的 NPU 可提供业界领先的 50 TOPS 计算能力。新的 Zen 5 核心为超薄笔记本带来强大的计算性能,以及更快的 RDNA 3.5 显卡带来一流的应用加速和主机级游戏体验。

旗舰 Ryzen 9 HX370 拥有 12 个 Zen 5 核心、24 个线程、36 MB 缓存、业界最大整合 NPU,以及最新的 RDNA 显卡。

与上一代相比,XDNA 2 拥有 32 个 AI 阵列,多任务处理性能翻倍。这也是一种极其高效的架构,在运行生成式 AI 工作负载时,能效比上一代提高两倍。

与市场上其他搭载新 NPU 的芯片进行对比,XDNA 2 提供了最高的 INT8 AI 性能(再次强调 50TOPS)。

在生成式 AI 能力方面,并非所有 NPU 都是一样的。不同的 NPU 实际上支持不同的数据类型,这关系到设备的精度和性能。对于生成式 AI,16 位浮点数据类型能带来很高的精度,但牺牲了性能。而目前 NPU 的标准是 8 位整数数据类型,注重性能但牺牲了精度。这意味着开发人员在提供更精确或更高性能的解决方案之间难以权衡。

现在 XDNA 2 是第一款支持区块 16 位浮点数据类型的 NPU。这意味着区块 FP16 结合了 16 位数据的精度和 8 位数据的性能。

这代表了 AI 能力的一大飞跃,使开发人员能够在全速下本地运行复杂模型,无需任何量化步骤。换言之,不做任何折衷。说到这里,苏妈立即演示了它的效果。

这些是使用流行的 Stable Diffusion XL Turbo 生成 AI 模型生成的三张图像。使用相同的提示,没有任何量化或重新训练,唯一的区别就是数据类型。左边是 INT8,这是大多数 NPU 所使用的数据类型。中间是区块 FP16,是 XDNA 2 所支持的数据类型。右边则是更传统的 FP16 格式。可以看到,两张 16 位数据类型生成的图像看起来要好得多,而两者之间实际上没有明显区别。Ryzen AI 可以在生成低质量 INT8 图像所需的相同时间内生成质量明显更高的图像。
讲到这里,苏妈又拉来了外援——微软 Windows 设备公司副总裁 Pavan Davuluri。

微软一直在与 AMD 密切合作,以在 Strix 上推出协作 PC。
微软在过去的宣布了一种专为 AI 打造的全新 PC 类别--协作 PC。为充分发挥 AI 在 PC 上的威力,从芯片到 Windows 的每一层都进行了重新设计。

除了与微软的合作,AMD 还与包括 Adobe、Epic Games、SolidWorks、索尼、Zoom 在内的所有领先软件开发商展开合作,以加速 AI Copilot PC 应用。到 2024 年底有望有超过 150 家独立软件供应商为 AMD AI 平台开发内容创作、消费者、游戏和生产力应用。
无论单线程响应能力、生产力应用、内容创作还是多任务处理能力,第三代 Ryzen AI 处理器在广泛的使用场景中,其性能领先竞争对手两位数的百分比。
苏妈接下来陆续邀请惠普总裁兼 CEO 恩里克·洛里斯、联想集团总裁卢卡·罗西、华硕董事长施崇棠等为其站台。



首批 AMD Ryzen AI 处理器加持的笔记本将于 7 月上市,与华硕、惠普、联想、微星等厂商达成了 100 多款消费者和商用笔记本的设计认证。精彩可期!

边缘计算平台
随后苏妈游刃有余地将话题从 PC 转向边缘计算领域。AMD AI 平台已在边缘领域广泛部署。

在医疗保健领域,AMD 芯片通过增强医学成像分析、加速研究和辅助精准手术机器人来改善病人的治疗效果。
在汽车领域,AMD AI 解决方案正为最先进的安全系统提供支持。
在工业领域,客户正利用 AMD 技术用于 AI 辅助机器人和机器视觉应用。
AMD 目前在自适应计算领域处于领先地位,数以千计的公司已采用 XDNA AI 自适应和嵌入式技术为其产品和服务赋能。

Illumina 是基因组学领域的全球领导者,他们使用 EPIC 和 AMD 自适应 SoC 与他们的 Splice AI 软件一起使用,来识别患有罕见遗传疾病患者体内之前无法检测到的突变。

在汽车领域,视睿(Vayree)的行业领先眼视 ADAS 系统使用 Versal 芯片分析由前置摄像头捕获的每一帧图像,从而可识别并提醒驾驶员潜在的安全隐患。

ABB 使用 AMD 自适应计算产品在他们广泛部署的高压直流输电解决方案中检测潜在的电力问题,以防在它们扩大并导致停电之前将其解决。

佳能已采用 Versal 来驱动基于 AI 的自由视角视频系统,可同时从 100 多个摄像头捕捉高分辨率视频,让观众可从任意角度体验现场活动。

边缘人工智能实际上是一个很难的问题。它需要在设备内完成预处理、推理和后处理的能力。只有 AMD 拥有加速端到端边缘 AI 所需的全部这些部件。

AMD 将自适应计算引擎用于预处理传感器和其他数据,将 AI 引擎用于推理,然后利用高性能嵌入式计算内核进行后处理决策制定。要做到这一点需要三种独立的芯片,而新的 Versal AI Edge 第 2 代系列将全部这些领先的计算能力整合到单一芯片中,成为第一款集成了预处理、推理和后处理的自适应解决方案。

数据中心 CPU:EPYC
从边缘到数据中心,AMD 正在重塑整个现代计算范式,建立了业内最广泛的高性能 CPU、GPU 和网络产品组合。
现代数据中心实际上运行着许多不同的工作负载,从传统 IT 应用到较小的企业大语言模型,再到大规模 AI 应用。用户需要不同的计算引擎来处理每一种工作负载,只有 AMD 拥有全套高性能 CPU 和 GPU 产品组合来应对所有这些工作负载。从的 EPYC 处理器(可为通用和混合推理 AI 工作负载提供领先性能)到专为大规模加速 AI 应用而打造的 Instinct GPU。苏妈接下来分享了 AMD 下一代数据中心 CPU 和 GPU 产品的细节。

在现在的 CPU 市场,EPYC 是云计算的首选处理器,为所有最大的超大规模云提供商的内部工作负载提供支持,并且在所有主要云提供商那里有 900 多种公有云实例。每天,世界各地数十亿人使用由 EPYC 提供支持的云服务,其中包括 Facebook、Instagram、LinkedIn、Microsoft Teams、Zoom、Netflix、微信(WeChat)、WhatsApp 等等。

AMD 在 2017 年推出了 EPYC,随着每一代产品,越来越多的客户采用了EPYC,因为领先的性能、领先的能源效率和领先的总体拥有成本。苏妈自豪地说,AMD 现在占有 33% 的市场份额,并且还在增长。

最新一代服务器 CPU 的虚拟化性能比传统处理器高出五倍。即使与当今竞争对手的最佳处理器相比,EPYC 的性能也快 1.5 倍。

如今许多企业实际上都在寻求现代化其通用计算基础设施并在同一空间内添加新的 AI 功能。通过使用第四代 EPYC 进行数据中心更新,可以做到这一点。实际上可以用一台服务器取代五台传统服务器,从而减少 80% 的机架空间,并消耗 65% 更少的能源。

许多企业客户还希望在不添加 GPU 的情况下运行结合通用和 AI 工作负载。在运行业标准 TPCx-AI 基准测试时(该测试跨不同用例和算法测量端到端 AI pipeline 性能),EPYC 的速度比竞争对手快 1.7 倍。

苏妈有备而来,上面第四代 EPYC CPU 只是开胃小菜,接下来向大家展示即将推出的第五代 EPYC 处理器"Turin"。


Turin 拥有 192 个内核和 384 个线程,由采用 3 纳米和 5 纳米制程技术生产的 13 个不同芯片组成。Turin 支持所有最新的内存和 IO 标准,并且可以直接替换现有的第四代 EPYC 平台。Turin 将延续 EPYC 在通用和高性能计算工作负载方面的领先地位。

接下来看看性能表现。
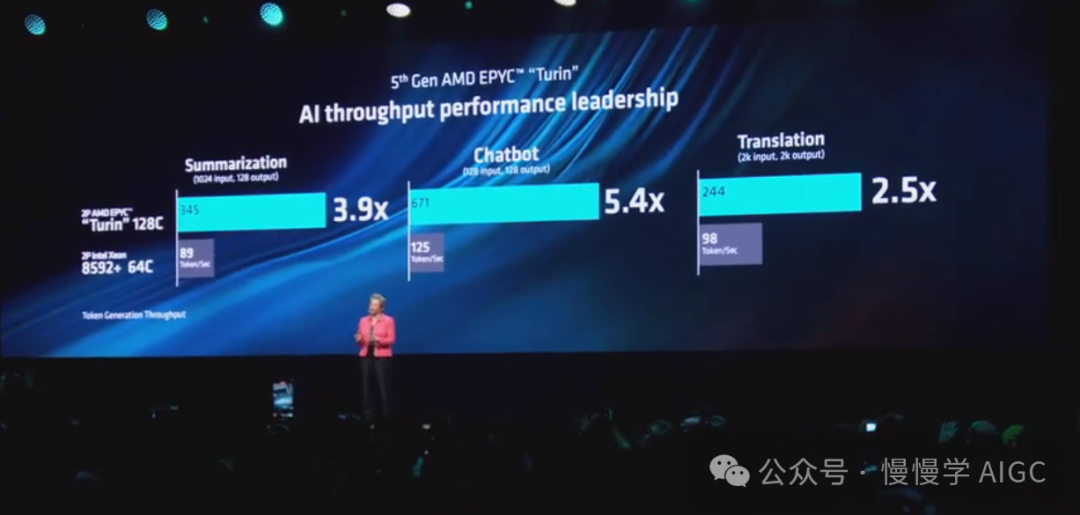
NMD 是一种非常计算密集型的软件,可以模拟复杂的分子系统和结构。在模拟 2000 万原子模型时,128 核心版本的 Turin 比竞争对手的最佳产品快 3 倍多,让研究人员可以更快地完成模型,从而有可能在药物研究、材料科学和其他领域取得突破。

当运行较小的大型语言模型时,Turin 在 AI 推理性能方面也表现出色。下面这个演示比较的是,当运行具有最小保证延迟(以确保高质量用户体验)的典型企业部署 LLaMA 2 虚拟助手时 Turin 的性能。两台服务器都开始通过加载多个 LLaMA 2 实例,每个助手被要求对上传的文档进行总结。可以看到右边的 Turin 服务器在相同的时间内添加了双倍数量的会话,同时响应用户请求的速度也明显比竞争对手快。当另一台服务器达到可支持的最大会话数量时,你会看到它很快就停止了,因为它基本上无法再满足延迟要求。而 Turin 继续扩展,提供近乎4倍于竞争对手的持续 tokens 吞吐量。这意味着使用 Turin 时,用户只需少量硬件就能完成同样的工作。

除了在总结性能上的领先地位外,Turin 在许多其他企业 AI 用例中也展现出领先性能,包括在翻译大型文档时性能提高 2.5 倍,在运行支持聊天机器人时性能提高 5 倍以上。
以上为第五代 EPYC CPU 预览。AMD 计划在今年下半年正式推出 Turin 产品。
硬磕 NVIDIA!AMD Instinct 重磅更新
接下来是 AMD 数据中心 GPU 和 Instinct 加速器上的一些重大更新。
AMD 去年 12 月推出了 MI300X,它迅速成为 AMD 历史上发展最快的产品。微软、Meta 和 Oracle 都已采用 MI300X。所有主要服务器 OEM 都在提供 MI300X 平台,AMD 也与广泛的生态系统 CSP 和 ODM 合作伙伴建立了深入的合作关系。

MI300X 可以开箱即用地支持所有最常见的模型,包括 GPT、LLaMA 2 & 3、Mistral、Yi 等等。

在过去一年里,AMD 在 ROCm 软件栈方面取得了巨大进展,与开源社区在每个层面紧密合作,同时添加了新功能,使客户能够非常轻松地在其软件环境中部署 AMD Instinct。

在过去六个月里,增加了对更多 AMD AI 硬件和操作系统的支持,整合了诸如 vLLM 的开源库和 JAX 等框架,启用了对最先进注意力算法的支持,改进了计算和通信库,所有这些都为 MI300X 的生成式 AI 性能带来了显著提升。凭借这些最新的 ROCm 更新,与竞品 H100 相比,MI300X 在一些行业内最具挑战性和最受欢迎的模型上提供了更好的推理性能。在 Meta 最新 LLaMA 3-700 亿参数模型上,MI300X 的性能比 H100 高 1.3 倍,在 Mistral 的 70 亿参数模型上性能高出 1.2 倍。

AMD 还扩大了与开源 AI 社区的合作。现在有 70 多万个 Hugging Face 模型可以直接使用 ROCm 在 MI300X 上运行。业界也在提高开发人员编码到 GPU 的抽象层次方面取得了重大进展。AMD 与 OpenAI 的密切合作确保了 MI300X 与 Triton 编程语言的全面支持,为快速开发高性能大语言模型内核提供了一个供应商中立的选择。AMD 为领先的框架如 PyTorch、TensorFlow 和 Jax 增加对 AMD AI 硬件的支持。

AMD 也在与领先的 AI 开发者紧密合作,优化他们的模型以在 MI300X 上运行。苏妈请来了重要合作伙伴 Stability AI 的 CTO 兼联席 CEO Christian Lafort。

Stability AI 以提供突破性的稳定扩散(Stable Diffusion)开源 AI 模型而闻名。

万众期待的 Stable Diffusion 3 的等待就要结束了。Stability AI 宣布 6 月 12 日将发布 Stable Diffusion 3 中型模型供所有人下载。SD3 medium 是 SD3 的一个优化版本,能实现前所未有的视觉质量,社区将能够根据自己的具体需求对其进行改进,帮助我们发现生成 AI 的下一个前沿。它可以在 MI300X 上超快运行。而且它也够小巧,可以在刚刚宣布的 Ryzen AI 笔记本上运行。

下面这是一张使用 Stable Diffusion 3 生成的图像,挑战它来描绘著名的台湾夜市是什么样子的。

初看起来不错。如果你仔细看,你会注意到它还不完全写实,但它很好地捕捉了文本提示的不同元素。当你想到它比实际输入这个很长的文本提示生成得更快时,这就更加令人印象深刻了。它捕捉到了行人在走动,街道是用石头铺成的,这是在夜晚,还有树木等等。
所以基本上 SD3 能够利用一些新的创新来做到这一点,包括多模态扩散转换器架构(Diffusion Transformer,DiT)使其能够比以前的模型更好地理解视觉概念和文本提示。它支持简单的提示,所以你不需要成为专家就能使用,但你也可以使用更复杂的提示,它会尝试将它们的不同元素结合起来。SD3 擅长各种艺术风格和写实主义。
接下来将 SD3 与不到一年前发布的上一代 Stable Diffusion XL 进行了比较。这个例子特别具有挑战性,因为它涉及到手部,对于这些模型来说手部一直是难以复制的。它包含重复的图案,比如琴弦、吉他和品格条。所有这些对于这些模型来说理解和准确绘制都是非常具有挑战性的。请注意,SD3 生成了更真实的细节,比如吉他的形状和手部。如果你非常非常仔细看,你可能会注意到有一些小瑕疵。所以它还不算完美,但比上一代有了很大改进。

Christian Lafort 盛赞 MI300X,称 192 GB 的 HBM 是游戏规则的改变者。就像拥有更多内存通常可以为用户解锁新的模型一样,它往往是帮助用户训练更大型模型、提高速度和效率的最主要因素之一。
Christian Lafort 举了个例子。Stability AI 的 API 中有一个创意上采样功能,它的工作原理是将旧照片和小于 100 万像素的旧图像的分辨率真正放大,同时提高质量。

对于这个创意上采样功能,在 H100 上最高达到 3000 万像素。将代码移植到 MI300X 上几乎不需要任何努力就能达到 1 亿像素。内容创作者总是渴望更多像素。所以这带来了巨大的差异。这是一个巨大的进步。研究人员和工程师们真的会钟爱 AMD Instinct GPU 一开箱即可提供的惊人内存容量和带宽优势。
苏妈目送 Christian Lafort 离开。远在千里之外的另一位神秘嘉宾也即将揭晓。
苏妈演讲的前半部分加入了微软的 Pavan Davuluri,分享了 Co-Pilot Plus PC 方面的出色合作成果。微软也是 AMD 最重要的数据中心合作伙伴之一,双方一直在 EPYC 和 Instinct 产品线上紧密合作。
苏妈邀请了微软董事长兼 CEO 萨蒂亚·纳德拉(Satya Nadella)线上分享同 AMD 合作伙伴关系,以及微软如何在基础架构中使用 MI300X 的更多内容。
“非常感谢您,Lisa。很高兴与各位相聚在 Computex。我们正处于一个大规模的 AI 平台转型时期,它有望改变我们的生活和工作方式。我们致力于与整个行业广泛合作,将这一愿景变为现实。这就是为什么我们与 AMD 的深度合作关系如此重要,该合作关系已经涵盖了从 PC 到为 Xbox 定制芯片,再到 AI 的多个计算平台。
正如 Pavan 所强调的,我们很高兴与您合作,提供这些新的采用 Ryzen AI 的 Co-Pilot Plus PC。我们也很高兴上个月宣布,我们是第一家提供使用 AMD MI300X 加速器的虚拟机的云服务商。这是我们两家公司的一个重大里程碑,它让我们的客户能够访问令人印象深刻的性能和效率,用于他们最苛刻的 AI 工作负载。
事实上,它今天为 GPT 工作负载提供了领先的性能价格比。这只是个开始。我们对与 AMD 的合作有着坚定的承诺,我们将继续在云和边缘环节携手推进 AI 进程,为我们共同的客户带来新的价值。
谢谢各位。”
苏妈在表达了对纳德拉谢意之后,强调 MI300X 目前提供了 GPT-4 工作负载的最佳性能价格比,并广泛部署在微软的 AI 计算基础架构中。随后,现场演示了一个 MI300X 用于支持 OpenAI 基于 GPT-4 构建的 Wanderlust 旅游助理的例子。

苏妈首先告诉这个工具,对台湾感兴趣,将参加 Computex。问谁是开场主旨演讲人的问题,它迅速返回正确答案。接着苏妈问 Wanderlust 在台北还有哪些有趣的景点值得一游?几乎立即就得到了许多在会展中心附近可做的事情选择。
苏妈效仿老黄,在演讲最后放出大招,向所有人展示了非常令人兴奋的产品路线图。

AMD 也将数据中心产品路线图扩展到了每年一更新,意味着每年都会有一个新的产品系列。今年晚些时候计划推出 MI325X,具有更快的速度和更大的内存,紧接着在 2025 年推出 MI350 系列,它将采用新的 CDNA 4 架构。MI325X 和 350 系列都将与 MI300X 采用相同的行业标准通用主板 OCP 服务器设计,这意味着客户可以非常快速地采用这项新技术。然后在 2026 年将采用全新的 CDNA Next 架构,推出 MI300X 系列的下一代产品 MI400。
MI325X 通过高达 288 GB 的超快 HBM3e 内存和每秒 6 TB 的内存带宽,延续了 AMD 在生成式 AI 领域的领先地位。它使用与 MI300X 相同的基础架构,这使客户过渡到它变得很容易。(效仿老黄 H100 -> H200)

苏妈展示了一些数据。与竞品相比,MI325X 提供了两倍的内存、1.3 倍的更快内存带宽和 1.3 倍的更高峰值计算性能。

正如 Christian 所说,内存容量的重要性。一台配备 8 块 MI325X 加速器的服务器就可以运行高达一万亿参数的高级模型。这是一台 H200 服务器所支持规模的两倍。
在 2025 年 AMD 将推出 CDNA 4 架构,它将带来我们有史以来最大的一代 AI 性能飞跃。MI350 系列将采用先进的 3 纳米工艺制造,支持 FP4 和 FP6 数据类型,并且再次可以无缝融入 MI300X 和 MI325X 的同一基础架构中。

AMD 推出 CDNA 3 时,与上一代相比 AI 性能提高了 8 倍。

而对于 CDNA 4 有望实现 35 倍的性能增幅。也就是说比 CDNA 3 高出 35 倍。

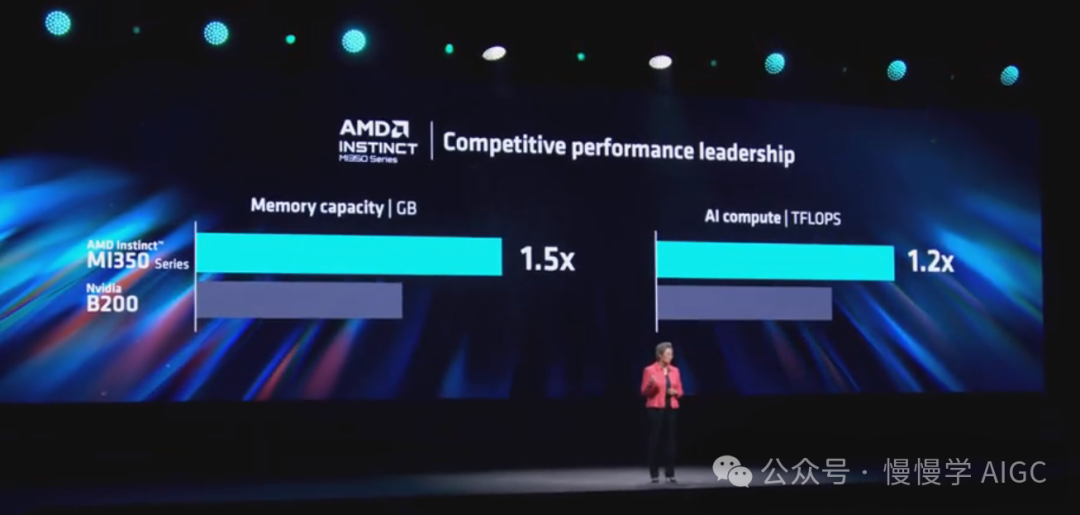
当你将 MI350 系列与 Nvidia B200 进行比较时,Instinct 支持高达 1.5 倍的内存,并提供 1.2 倍的整体性能。(编者按:武林至尊,宝刀屠龙,号令天下,莫敢不从。倚天不出,谁与争锋!)
开放的网络基础设施:Ultra Accelerator Link 和 Ultra Ethernet
除了计算硬件,AMD 在推动高性能 AI 网络基础设施系统的发展方面也取得了重大进展。

AI 网络系统需要支持高切换率和极低延迟,并且必须能够扩展以连接数千个加速器节点。AMD 认为 AI 网络的未来必须是开放的,开放给行业内的每个人,让大家一起推动并产生最佳解决方案。因此,对于推理和训练而言,扩展数百个加速器的性能实际上都是至关重要的,将机架或 Pod 中的 GPU 通过极快、高度可靠的互连连接起来,以便它们可以协同工作为单个计算节点,运行最大规模的模型并获得最快响应。
上周苏妈联合许多最大的芯片、云和系统公司走到一起,宣布计划开发一种高性能互连标准,可以正式连接数百个加速器,称之为"超加速器链路"或 UA 链路,这是一种经过优化的负载/存储互连,设计用于高数据速率运行,并利用 AMD 经过验证的 Infinity Fabric 技术。

UA 链路将成为扩展各种类型加速器(不仅仅是 GPU)的最佳解决方案,并将成为专有选择之外的一个极好选择。UA 链路 1.0 标准即将在今年晚些时候发布,多家供应商已开发支持 UA 链路的芯片产品。
训练大型模型的另一部分需求是扩展性能,将多个加速器 Pod 连接在一起协同工作,而大规模部署通常要连接数十万个 GPU。
去年,一个由行业领导者组成的广泛群体成立了 Ultra Ethernet 联盟(Ultra Ethernet Consortium,UAC),旨在应对这一挑战。UAC 是一种高性能技术,具有领先的信号传输速率。它具有 RoCE 等 RDMA 扩展,可有效在节点间移动数据,并拥有专门为 AI 超级计算机开发的一系列新创新技术。它具有令人难以置信的可扩展性,提供来自 Broadcom、Cisco 和 Marvell 等领先供应商的最新交换机技术,最重要的是,它是开放的。开放意味着,作为一个行业,我们可以在 UAC 之上进行创新,解决所需的问题,整个行业可以共同努力,为 AI 和 HPC 构建最佳的高性能互联解决方案。

展望未来,AMD 拥有了所有的部件,包括 UA 链路和 Ultra Ethernet,现在拥有了完整的网络解决方案,可以构建高性能、高度互操作和高度可靠的 AI 数据中心,能够运行最先进的前沿模型。

AMD 是唯一一家能够提供 CPU、GPU 和网络解决方案的完整组合来满足现代数据中心的所有需求的公司,加速了 Instinct 和 EPYC 产品线的路线图,以提供更多创新,同时还与其他领导者组成的开放生态系统合作,提供业界领先的网络解决方案。

总结
AMD 展示了很多新产品,从最新的 Ryzen 9000 台式机和第三代 Ryzen AI 笔记本处理器(具有领先的计算和 AI 性能),到即将带来更多边缘 AI 功能的单芯片 Verso Gen 2 系列,再到延续了 EPYC 产品线领先地位和效率的下一代 Turin 处理器,以及将每年提供更高性能的扩展 Instinct 加速器系列。

这是科技行业令人难以置信的时代。创新步伐令人兴奋,苏妈表示对 AMD 在高性能和 AI 计算方面将共同努力的所有工作感到无比兴奋。
最后,苏妈感谢所有合作伙伴,特别是到场的微软、惠普、华硕、联想和Stability.ai。
关于 AMD
50 多年来,AMD 一直在推动高性能计算、图形和可视化技术的创新。全球数十亿人、领先的财富 500 强企业以及最前沿的科研机构每天都依赖 AMD 的技术来改善生活、工作和娱乐。AMD 员工专注于构建领先的高性能和适应性产品,不断推进可能性的边界。
点击下方卡片,关注“慢慢学AIGC”
