




点击下方卡片,关注“慢慢学AIGC”
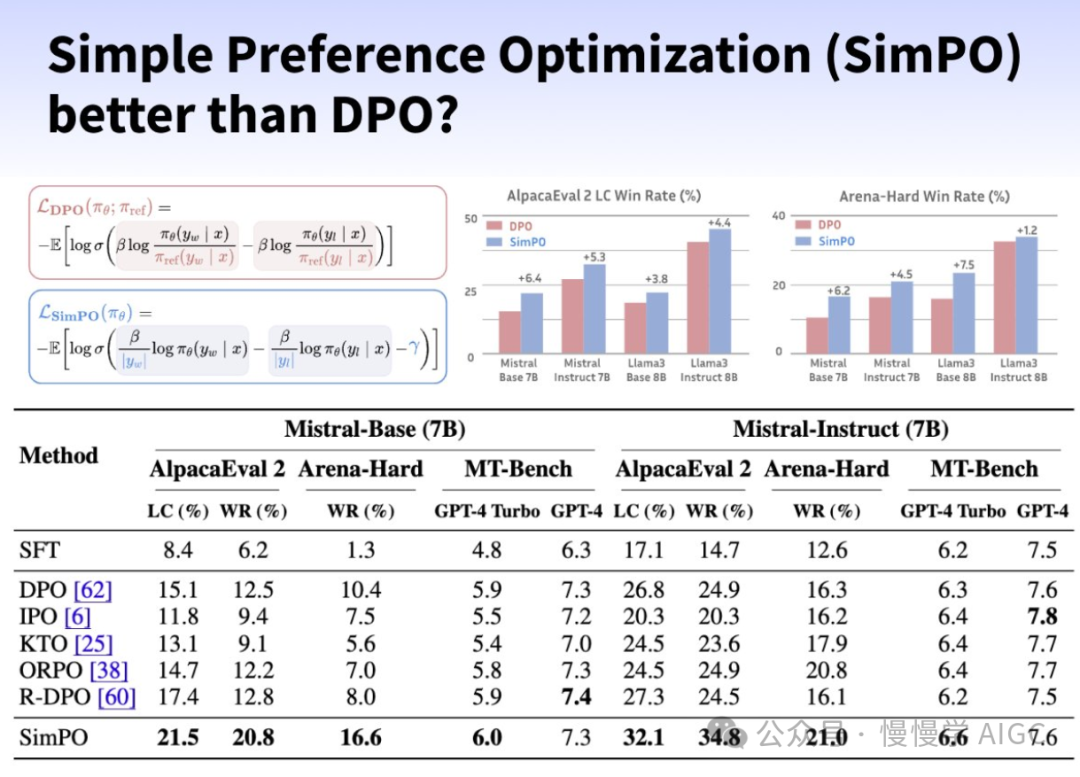
SimPO (简单偏好优化)是一种新的 RLHF(基于人工反馈的强化学习)方法,旨在提高离线偏好调优的简单性和训练稳定性,同时优于 DPO 或 ORPO。SimPO 与 DPO 非常相似,都是无奖励的方法,但 SimPO 使用序列的平均对数概率作为隐式奖励。SimPO 类似于 DPO,但有以下不同之处:
使用序列的平均对数概率作为奖励
不需要参考模型,减少了计算和内存需求
采用长度归一化奖励公式,惩罚过长的响应
引入目标奖励边际,鼓励选择和拒绝响应之间的较大差距
目标是最大化累积奖励,即选择响应的平均对数概率与拒绝响应的平均对数概率之差,减去目标奖励边际
见解:
与 DPO 相比,时间缩短约 20%,GPU 显存减少约 10%
在关键基准测试(AlpacaEval 2、Arena-Hard)上优于 DPO
在 AlpacaEval 2 上提高多达 6.4 分,在 Arena-Hard 上提高多达 7.5 分
SimPO 与 DPO 模型相比,响应长度没有显著增加
强制执行更大的目标奖励边际可有效提高奖励准确性
在学术基准测试(如 MMLU、GSM8k)上保持性能
由@huggingface构建
论文 https://huggingface.co/papers/2405.14734
Github: https://github.com/princeton-nlp/SimPO
模型:https://huggingface.co/collections/princeton-nlp/simpo-66500741a5a066eb7d445889
向普林斯顿大学的团队表示祝贺,更值得赞赏的是他们不仅发布了代码,还发布了所有模型检查点。
补充背景知识
基于人类反馈的强化学习(RLHF)
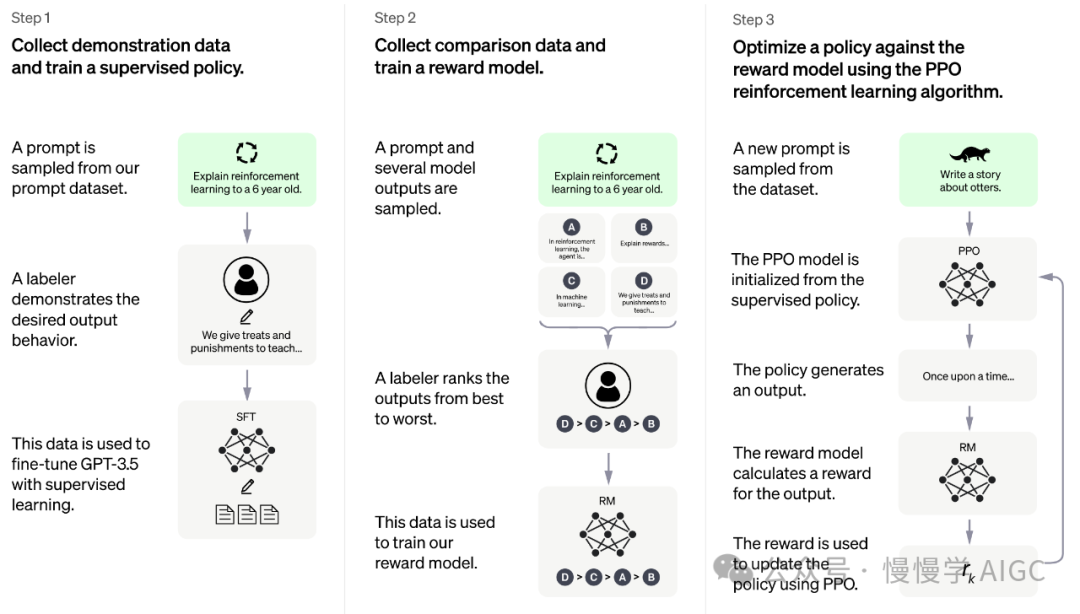
RLHF 是一种技术,可将大型语言模型与人类偏好和价值观相一致。典型的 RLHF 流程(来自 InstructGPT 论文)通常包括三个阶段:监督细调、奖励模型训练和策略优化。RLHF 框架广泛应用于各种应用,如缓解毒性、确保安全性、增强有用性、搜索和浏览网络以及提高模型推理能力。
邻近策略优化(PPO) 是 RLHF 第三阶段广泛使用的算法,需要同时运行 Actor、Critic、RM、SFT 四个模型进行策略优化。
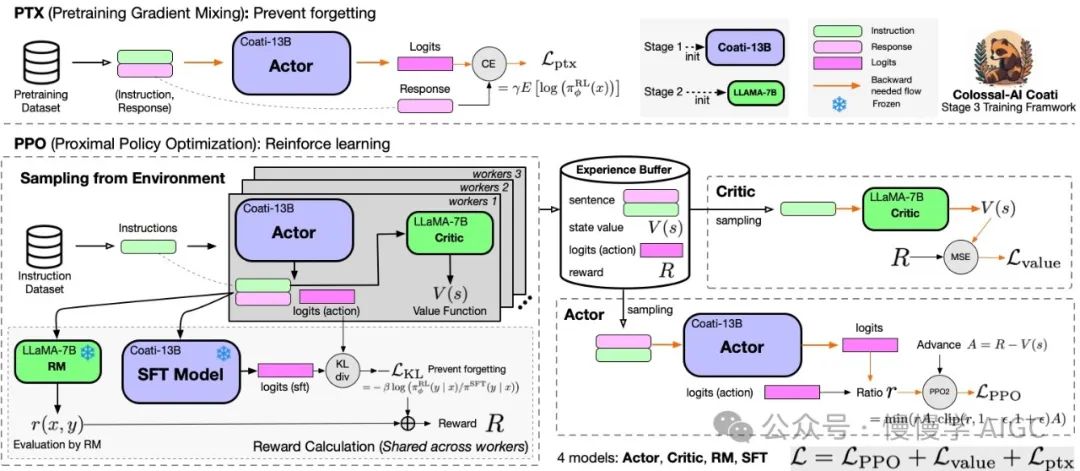
(图片来源:ColossalAI)
直接偏好优化(DPO)是一种广泛使用的离线偏好优化算法,它从人类反馈(RLHF)中重新参数化了强化学习中的奖励函数,以增强简单性和训练稳定性。
开发团队介绍

普林斯顿大学自然语言处理组致力于自然语言处理研究,旨在让计算机有效地理解和使用人类语言。我们开发新颖的算法、设计新的框架并探索理论基础,以解决语言理解中的挑战性问题,借助深度神经网络和强化学习等技术。我们的工作旨在推进人工智能的边界,同时也能在实际文本处理应用领域取得进展,从而对各种现实世界问题产生广泛影响。我们最新的努力集中在问答系统、对话系统、语言理解、知识表示与推理、表示学习以及弱监督学习算法等方面。
点击下方卡片,关注“慢慢学AIGC”
