




点击下方卡片,关注“慢慢学AIGC”

圣诞快乐,这要感谢"黄老爷"(指英伟达CEO黄仁勋)。尽管英伟达的 Blackwell GPU 因为硅片、封装和背板问题而多次延期(正如在这里和加速器模型中多次讨论的那样),但这并没有阻止英伟达继续其势如破竹的前进步伐。
他们正在推出一款全新的 GPU - GB300 和 B300,这距离 GB200 和 B200 的发布仅仅 6 个月。虽然表面上看起来只是渐进式升级,但实际上内涵远不止表面所见。
这些改变尤其重要,因为它们大幅提升了推断模型(笔者注:reasoning 工具翻译为“推理”,为了和“inference”的中文表述加以区分,下文将采用“推断”,请加以鉴别)的推理和训练性能。这是英伟达给所有大规模云服务提供商(特别是亚马逊)、供应链中的某些参与者、内存供应商以及他们的投资者的特别圣诞礼物。随着向 B300 的转移,整个供应链正在重组和转变,这让一些参与者收获丰厚,而另一些则可能颗粒无收。
B300 和 GB300 - 不仅仅是渐进式升级
B300 GPU 是在台积电 4NP 工艺节点上全新流片的产品,也就是说,这是一个经过优化的计算芯片设计。这使得该 GPU 在产品层面上的 FLOPS 性能比 B200 提高了 50%。部分性能提升来自于额外增加的 200W 功耗,GB300 和 B300 HGX 的 TDP 分别达到 1.4 KW 和 1.2 KW(相比之下 GB200 和 B200 分别为 1.2 KW 和 1 KW)。
其余的性能提升将来自架构改进和系统级优化,比如 CPU 和 GPU 之间的功率调配。所谓功率调配,就是 CPU 和 GPU 之间动态重新分配功率。
除了更高的 FLOPS,内存也从 8-Hi 升级到了 12-Hi HBM3E,使每个 GPU 的 HBM 容量增加到 288 GB。不过,引脚速度将保持不变,因此每个 GPU 的内存带宽仍然是 8 TB/s。值得注意的是,三星在这次"圣诞礼物"中似乎并不走运,因为他们至少在未来 9 个月内都无法进入 GB200 或 GB300 的供应链。
此外,由于英伟达正沉浸在圣诞气氛中,其定价策略相当有趣。这改变了 Blackwell 的利润率,但关于定价和利润率的讨论我们稍后再谈。首先最重要的是讨论性能变化。
为推断模型推理而生
内存的改进对于 OpenAI O3 风格的 LLM 推断训练和推理至关重要,因为随着序列长度的增加,KV 缓存也在增长,这限制了关键批处理大小和延迟。我们在之前关于扩展法则的分析文章中已经讨论过推断模型训练、合成数据、推理等诸多方面。(延伸阅读:《AI 扩展定律的演进》)
下面的图表展示了英伟达不同代 GPU 在处理 1k 输入令牌和 19k 输出令牌时的效率改进情况,这类似于 OpenAI 的 o1 和 o3 模型中的思维链推断过程。这个示范性的性能上限模拟是在 LLAMA 405B 模型上以 FP8 精度运行的,因为这是我们能够模拟的最好的公开模型。模拟使用了我们能够接触到的 H100 和 H200 GPU。
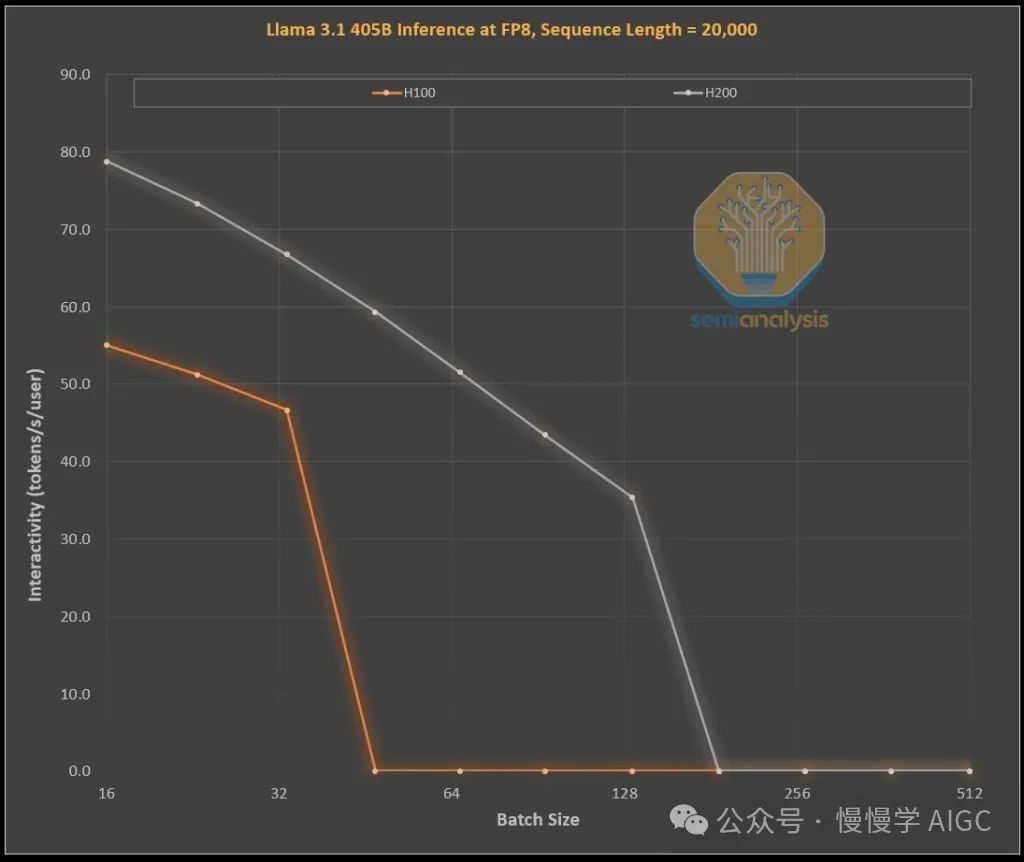
从 H100 升级到 H200 时,仅仅是增加了更多更快的内存,就产生了两个效果:
1. 由于更高的内存带宽(H200 为 4.8 TB/s,而 H100 为 3.35 TB/s),在所有可比较的批处理大小下,交互性普遍提高了 43%。
2. 由于 H200 可以运行更大的批处理大小,使其每秒能够生成 3 倍于 H100 的令牌数量,从而使成本降低了约 3 倍。这种差异主要是因为 KV 缓存限制了总批处理大小。
更大的内存容量带来的显著益处令人惊叹。这两款 GPU 在实际运营中的性能和经济差异远超规格表所示:
1. 推断模型可能会因请求和响应之间的显著等待时间而带来糟糕的用户体验。如果能够提供明显更快的推理时间,这将增加用户使用和付费的倾向。
2. 3 倍的成本差异是巨大的。硬件仅通过一次世代中期的内存升级就实现 3 倍性能提升,这简直令人难以置信,远超摩尔定律、黄氏定律或我们见过的任何硬件改进速度。
3. 我们观察到,最强大和最具差异化的模型能够比稍逊一筹的模型收取显著更高的溢价。前沿模型的毛利率超过 70%,而在面临开源竞争的落后模型上,毛利率低于 20%。推断模型不必局限于单一思维链。搜索功能的存在可以通过扩展来提升性能,就像在 O1 Pro 和 O3 中那样。这使得模型更智能,能够解决更多问题,并显著提高每个 GPU 的收入。
当然,英伟达并不是唯一能够提升内存容量的公司。ASIC 芯片也可以做到这一点,事实上 AMD 可能处于有利地位,因为他们的内存容量普遍高于英伟达,比如 MI300X 的 192 GB、MI325X 的 256 GB 和 MI350X 的288 GB...不过,"圣诞老人"黄仁勋还有一个叫做 NVLink 的"红鼻子驯鹿"。(延伸阅读:《MI300X vs H100 & H200 基准测试对比》)
当我们展望 GB200 NVL72 和 GB300 NVL72 时,基于英伟达系统的性能和成本都有了巨大改善。在推理中使用 NVL72 的关键点在于它能让 72 个 GPU 以极低的延迟共享内存协同工作处理同一个问题。世界上没有其他加速器拥有全对全的交换连接能力。也没有其他加速器能够通过交换机进行全规约运算。
英伟达的 GB200 NVL72 和 GB300 NVL72 对实现一些关键能力极其重要:
1. 大幅提高交互性,降低每个思维链的延迟。
2. 可以在 72 个 GPU 之间分散 KV 缓存,实现更长的思维链(提升智能水平)。
3. 相比典型的 8 GPU 服务器,具有更好的批处理大小扩展性,从而大幅降低成本。
4. 可以对同一问题进行更多样本搜索,以提高准确性和最终的模型性能。
因此,使用 NVL72 的经济效益提升了 10 倍以上,特别是在长推理链方面。KV 缓存占用内存是经济性的一大杀手,但 NVL72 是唯一能够在大批量处理时将推理长度扩展到 10 万以上令牌的方案。
为 GB300 重组的 Blackwell 供应链
在 GB300 中,英伟达提供的供应链和内容发生了巨大变化。对于 GB200,英伟达提供完整的 Bianca 主板(包括 Blackwell GPU、Grace CPU、512 GB 的 LPDDR5X 内存、集成在一块 PCB 上的电压调节模块内容),以及交换机托盘和铜质背板。
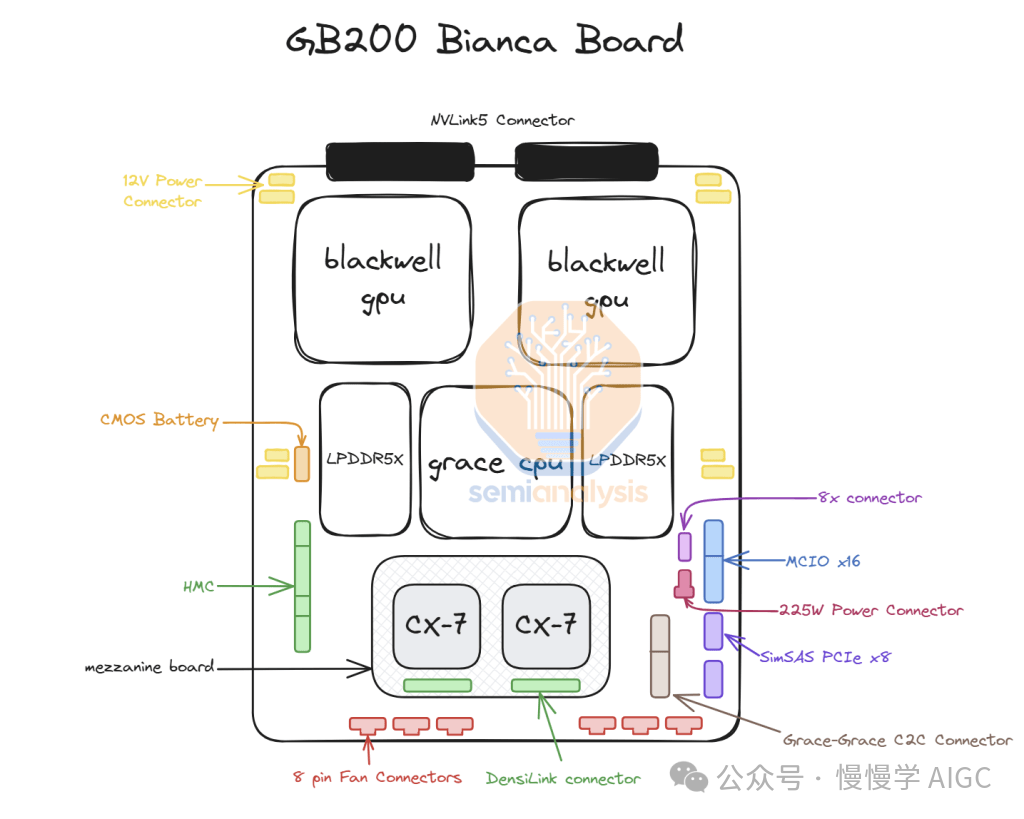
对于 GB300,英伟达不再提供完整的 Bianca 主板,而是只提供安装在"SXM Puck"模块上的 B300、BGA 封装的 Grace CPU,以及 HMC(主板管理控制器)——这次改用美国初创公司 Axiado 的产品,而不是 GB200 使用的 Aspeed 产品。
最终客户现在将直接采购计算主板上的其余组件,而第二级内存将使用 LPCAMM 模块,取代原来直接焊接的 LPDDR5X 内存。美光将成为这些模块的主要供应商。
交换机托盘和铜质背板保持不变,这些组件仍完全由英伟达供应。
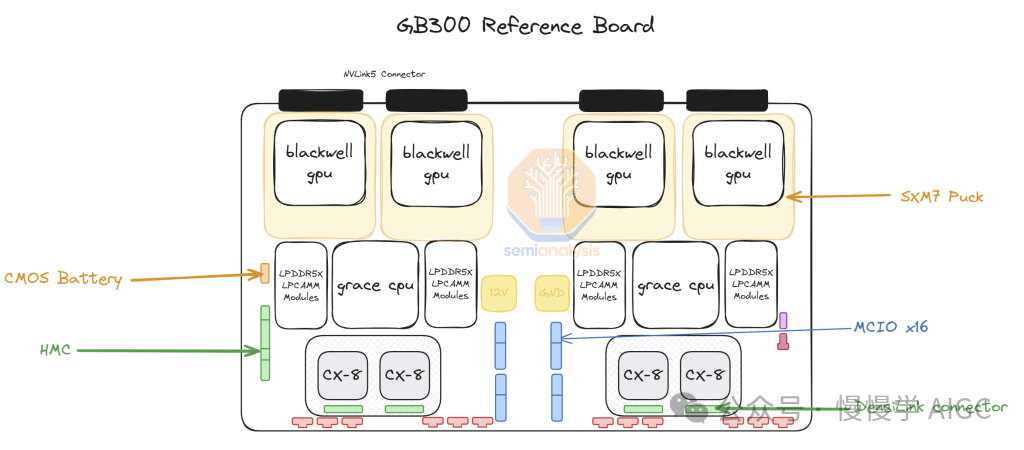
转向 SXM Puck 为更多 OEM 和 ODM 厂商参与计算托盘制造创造了机会。此前只有纬创和富士康工业互联网(FII)能够制造 Bianca 计算主板,现在更多 OEM 和 ODM 可以参与其中。在 ODM 厂商中,纬创是最大的输家,因为他们失去了 Bianca 主板的市场份额。对于 FII 来说,虽然在 Bianca 主板层面失去了份额,但由于他们是 SXM Puck 和其配套插座的独家制造商,这种损失得到了补偿。英伟达正在尝试为 Puck 和插座引入其他供应商,但目前尚未下达任何其他订单。
另一个重大转变是在电压调节模块(VRM)方面。虽然 SXM Puck 上有一些 VRM 内容,但大部分板载 VRM 将由超大规模云服务商/OEM 直接从 VRM 供应商采购。10 月 25 日,我们向核心研究订阅者发送了一份关于 B300 如何重塑 VRM 供应链的报告。我们特别指出了 Monolithic Power Systems 将如何因商业模式转变而失去市场份额,以及哪些新进入者正在获得市场份额。在我们向客户发送报告后的一个月内,由于市场意识到我们前瞻性研究中的事实,MPWR 股价下跌超过 37%。
英伟达还在 GB300 平台上提供 800G ConnectX-8 网卡,在 InfiniBand 和以太网上提供两倍的扩展带宽。由于上市时间复杂性和放弃在 Bianca 主板上启用 PCIe Gen 6,英伟达前段时间取消了 GB200 的 ConnectX-8。
ConnectX-8 相比 ConnectX-7 有巨大改进。它不仅带宽翻倍,而且有 48 条 PCIe 通道而不是 32 条,这使得空气冷却的 MGX B300A 等独特架构成为可能。此外,ConnectX-8 支持 SpectrumX,而在之前的 400G 世代,SpectrumX 需要效率低得多的 Bluefield 3 DPU。
GB300 对超大规模云服务商的影响
GB200 和 GB300 的延期意味着从第三季度开始的许多订单转向了英伟达这款更贵的新 GPU。截至上周,所有超大规模云服务商都决定采用 GB300。部分原因是 GB300 由于更高的 FLOPS 和更多内存而性能提升,但部分也是因为能够掌控自己的命运。
由于上市时间的挑战以及机架、冷却和供电密度的重大变化,超大规模云服务商不被允许在服务器层面对 GB200 做太多改动。这导致 Meta 放弃了从博通和英伟达多源采购网卡的希望,转而完全依赖英伟达。在谷歌等案例中,他们放弃了自家网卡,转而只采用英伟达的产品。
对于习惯于从 CPU 到网络,再到螺丝和钣金都要优化成本的超大规模云服务商的数千人团队来说,这简直令人难以接受。
最典型的例子是亚马逊,他们选择了一个比参考设计 TCO 更差的次优配置。具体来说,由于使用 PCIe 交换机和需要风冷的效率较低的 200G 弹性网络适配器,亚马逊无法像 Meta、谷歌、微软、Oracle、X.AI 和 CoreWeave 那样部署 NVL72 机架。由于其内部网卡的原因,亚马逊不得不使用 NVL36,这也因为更高的背板和交换机成本而导致每个 GPU 的成本更高。总的来说,由于定制化的限制,亚马逊的配置是次优的。
现在有了 GB300,超大规模云服务商可以定制主板、冷却系统等更多内容。这使得亚马逊能够构建自己的定制主板,将此前风冷的组件(如 Astera Labs PCIe 交换机)集成到水冷系统中。更多组件的水冷,加上在 2025 年第三季度终于实现 K2V6 400G 网卡的大规模量产,意味着亚马逊可以重返 NVL72 架构并大幅改善其 TCO。
不过也有一个很大的缺点,就是超大规模云服务商需要设计、验证和确认更多内容。这无疑是超大规模云服务商需要设计的最复杂平台(除了谷歌的 TPU 系统)。某些超大规模云服务商能够快速完成设计,但团队较慢的其他公司则落后了。总的来说,尽管市场有取消报告,我们认为微软因设计速度问题是 GB300 部署最慢的之一,他们在第四季度仍在购买一些 GB200。
随着组件从英伟达的利润堆叠中抽出转向 ODM,客户支付的总价格差异很大。ODM 的收入受到影响,最重要的是,英伟达的毛利率也会在年内发生变化。
延伸阅读:
扫描下方二维码,关注“慢慢学AIGC”

