




DeepSeek火热已经持续一段时间,各个行业掀起了AI大模型对接的热潮,数据库作为基础架构的核心自然也不例外。早在2024年5月份数据库巨头Oracle便宣布全面支持AI向量数据库,并将其新一代数据库产品命名为23ai,向世界宣示其AI能力以及未来向AI方向发展的决心。国产数据库方面也有一些厂商在快速跟进,今天我们来聊聊这方面的情况。
OceanBase SQL+AI,构建AI助手
2024年下半年发布的OceanBase 4.3.3 GA版本中新增了向量检索能力,支持向量数据类型、向量索引以及基于向量索引的搜索能力,只需要一套数据库即可满足文档存储、标量过滤、向量检索和全文检索等多种需求。
OceanBase在gitee上给出了一个Workshop (https://gitee.com/oceanbase-devhub/ai-workshop-2024) ,使用通用语义向量模型BGE-M3 (那时候DeepSeek还没火起来^_^),提供多语言检索、不同粒度文本输入及多向量检索能力,可以基于这个Workshop搭建一个简易的AI助手。
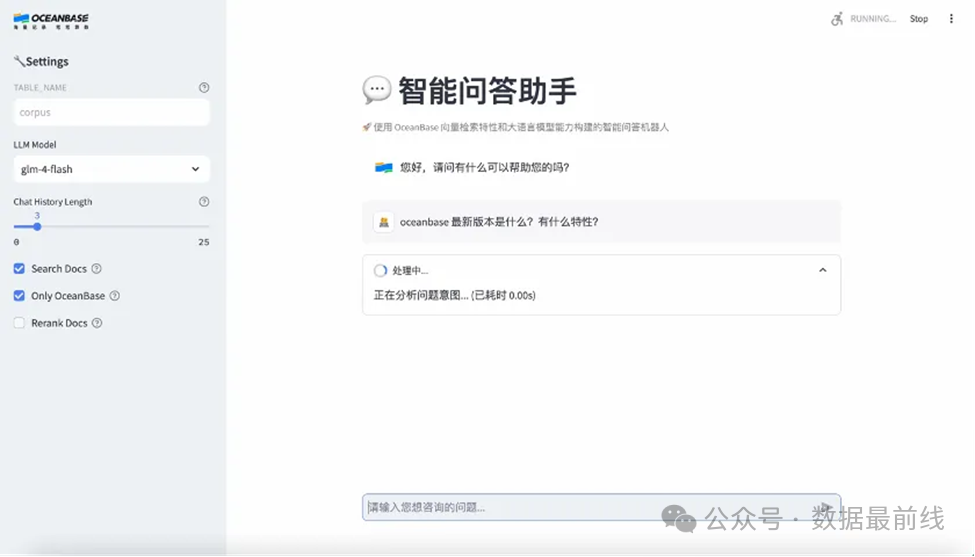
GBase 8c + DeepSeek 构建本地知识库
近期GBase数据库公众号发表文章,展示了利用GBase 8c + DeepSeek来构建本地知识库的案例。其中文本嵌入模型选用的是开源的nomic-embed-text,在处理短文和长文本任务方面有较大的优势;文本生成模型则选用DeepSeek-r1,能够更好的捕捉文本中的语义信息,为文本生成带来更出色的效果;而数据库则用于在本地存储私域知识库,实现快速向量化检索的同时提供更加稳定、安全的数据防护。
在仅使用DeepSeek进行提问时,模型的回答显得有些不着边际,毕竟国产数据库还是非常专业的一个领域。
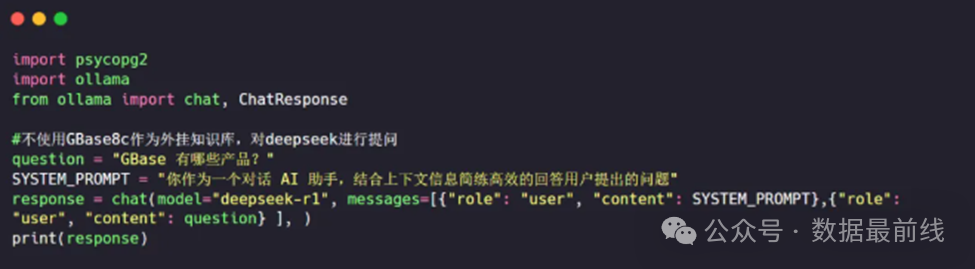
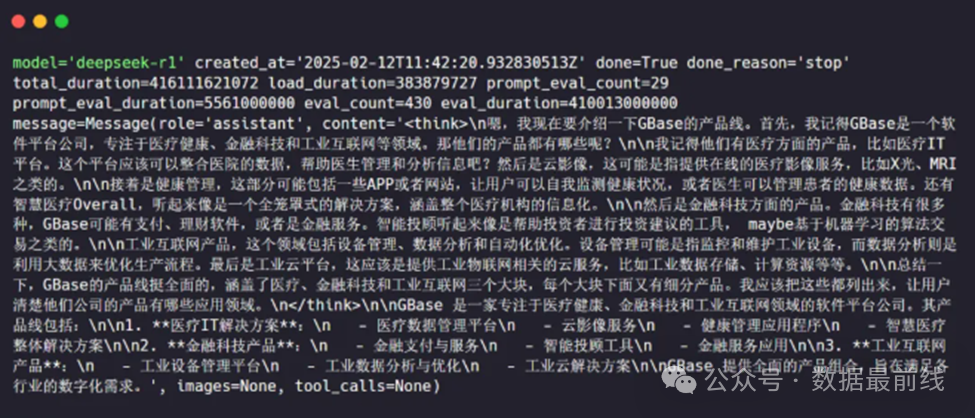
将问题转换为向量,在知识库中进行检索,将检索结果作为上下文再进行提问,回复结果复合预期。
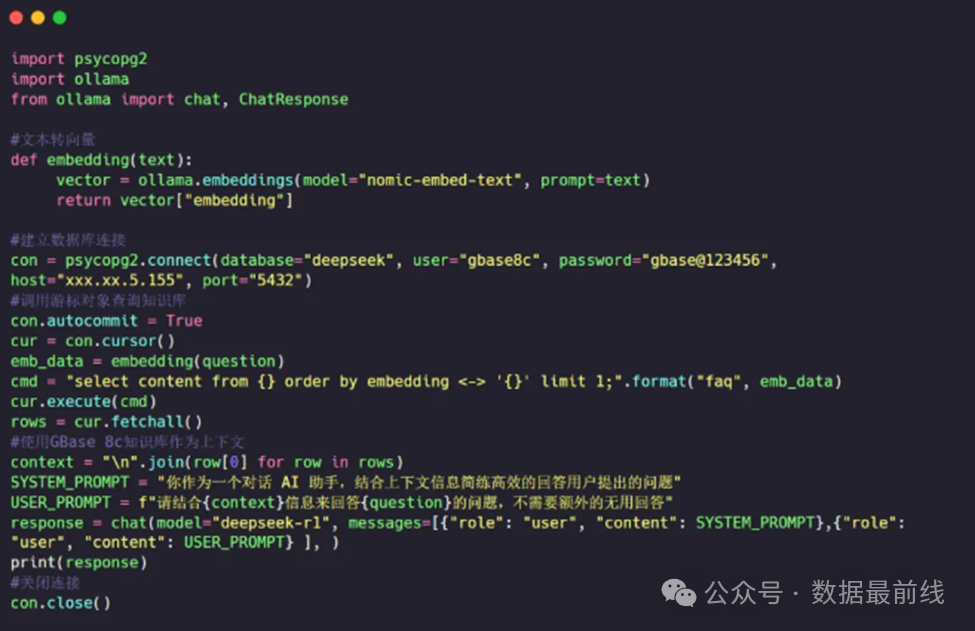
GBase 8c是基于openGauss数据库构建的分布式数据库,openGauss以及PostgreSQL 数据库均具备向量化的存储和检索能力,构建出这样的知识库并不困难。
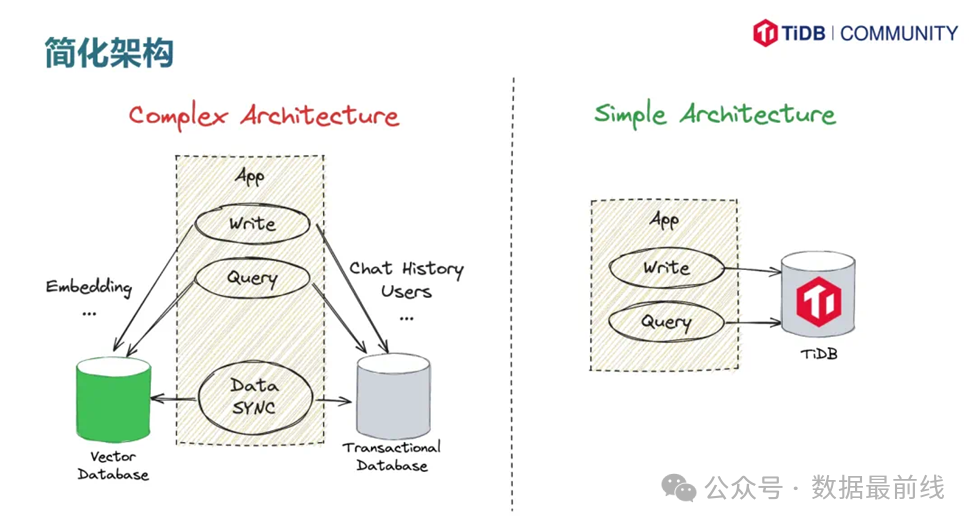
tidb.ai 使用知识图谱增强 RAG 能力
早在ChatGPT火热之际,TiDB就推出了基于RAG构建的TiDB知识图谱工具 -- tidb.ai,可以回答问题、查阅文档甚至编写代码,从而帮助用户从海量的文档中快速构建出自己的知识体系。
tidb.ai利用DSPy库进行知识图谱的自动化构建,TiDB数据库则用来存储大规模的知识图谱数据,提供向量检索和高并发的查询需求。
写在最后
ChatGPT引爆了大语言模型的概念,将人工智能推进到前所未有的高度,但是由于其高昂的训练和使用成本,规模化使用存在很多的限制。而DeepSeek的横空出世,极大的降低了人工智能的门槛,各行各业都在使用AI构建自己的使用场景。
数据库作为重要的IT基础架构,对海量知识库提供向量化存储和检索能力,是构建私域知识库不可或缺的重要组成。
目前不少的国产数据库厂商都推出了自己的AI解决方案,由于血缘关系的不同实现难度上会有所差别,PG系对向量的支持较早实现起来也较为便利,而MySQL只在9.0之后才开始支持向量,这部分厂商实现的成本会更高。但不论如何,AI是未来的方向,相信各个厂商都会在这个方向上投入资源跟进。
公众号:
