






在AI大模型训练推理中,网络高速传输需求始终贯彻在整个算力架构中。RDMA技术可以有效访问其他服务器的内存和资源,提高GPU间数据传输效率,成为在大规模并行 AI 计算集群最优选择。柏睿数据通过自主研发的RDMA Socket技术,结合专利化的底层系统优化方案,最终在3200 Gbps网络环境下实现2946 Gbps的传输速度,达到光介质理论带宽的98.2%,为大规模分布式计算场景提供了高性能网络解决方案。

技术挑战

在追求极致3200Gbps传输速度的过程中,柏睿数据遇到了几个关键的技术挑战:
1.高带宽需求:为了满足现代深度学习基础设施的需求,我们需要确保在不同机器之间高效地传输大量非连续GPU内存区域的数据。
2.支持点对点通信模式:以适应多样化的应用场景需求。
尽管NVIDIA的NCCL库是分布式深度学习的事实标准,但在面对特定的应用场景时,如需更高的灵活性及控制力时,它并不总是最佳选择。因此,柏睿数据决定开发一套自定义的高性能网络解决方案。

解决方案
要理解我们的解决方案,首先需要了解现代高性能网络与传统网络的主要区别。传统的TCP/IP协议依赖于操作系统内核进行数据传输,这导致了多次数据复制和上下文切换,严重影响了效率。相比之下,RDMA(Remote Direct Memory Access)技术能够绕过CPU直接访问远程服务器的内存,从而实现真正的零拷贝数据传输。
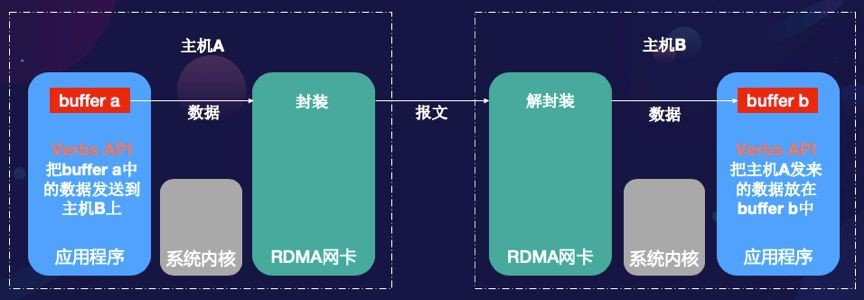
1.RDMA Socket技术:原生RDMA需手动管理内存注册、异步操作与完成队列,开发门槛高,难以快速部署。柏睿数据通过Socket接口封装,开发者沿用同步编程模型,同时享受RDMA的高性能与低时延,兼容现有系统生态。
2.硬件拓扑优化:基于NUMA架构与PCIe交换机布局,实现CPU核心绑定、内存注册与多线程资源分片,最大化硬件协同效率。
3.动态资源管理:支持大规模集群节点的动态扩缩容,适应Kubernetes等云原生环境的弹性需求。
此外,柏睿数据还采用了基于轮询的完成通知机制,代替传统的中断驱动方式,进一步降低了系统调用开销,并提高了响应速度。
优化过程与结果
在整个开发过程中,柏睿数据实施了一系列优化措施,包括但不限于:
1.操作排队:维持一个应用层的队列来管理网络操作,增强了系统的鲁棒性。
2.网络预热:预先建立连接,提高了启动性能。
3.多线程与CPU核心绑定:为每个GPU的网络操作分配专用线程,并将其绑定到特定的CPU核心,避免了NUMA效应和缓存未命中问题。
4.状态分片与操作批量提交:减少线程间的争用,并提高资源利用率。
5.延迟操作提交与NUMA感知资源分配:确保网络资源的有效利用,同时减少内存访问延迟。
经过这些细致入微的优化,最终我们在基于6台服务器与3200 Gbps RoCE交换机的测试环境,柏睿RDMA Socket实现了2946 Gbps的传输速度。

结论
柏睿数据通过RDMA Socket技术,成功将3200 Gbps网络数据传输速度推向新高度。证明通过技术创新与深度优化,企业可充分释放硬件潜力,在超高速网络时代抢占先机。其核心价值在于:
1.极致性能:2946 Gbps传输速度逼近理论极限,满足AI训练、分布式数据库等场景的严苛需求。
2.无缝兼容:标准Socket接口设计,无需重构代码即可集成现有应用,大幅降低技术迁移成本。
3.弹性扩展:支持动态节点调整与云原生部署,为大规模集群提供灵活高效的基础设施支撑。

柏睿数据通过覆盖集群资源管理、数据处理与存储、数据异步读取、分布式并行计算等核心领域的专利布局,构建了RDMA技术生态链,为高性能网络提供了底层支撑。包括《分布式计算系统中的分布式管道配置方法》《一种基于高频数据处理进行数据并行查询加速的方法和设备》等。此外,通过提炼柏睿RDMA技术方案形成的《一种快速拆装式RDMA存储装置》正在申请中。未来,柏睿数据将继续致力于技术创新,推动网络传输性能向着更高层次迈进。

推荐阅读



