




一、数值类型
1、整数类型
UInt8,UInt16,UInt32,UInt64: 无符号整数范围(0~2n-1),分别占用 8、16、32、64 位。
Int8,Int16,Int32,Int64: 有符号整数范围(-2n-1~2n-1-1),分别占用 8、16、32、64 位。
固定长度的整型,包括有符号整型或无符号整型。
2、浮点数类型
Float32: 32 位浮点数(单精度)。
Float64: 64 位浮点数(双精度)。
建议尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。
3、定点数类型
Decimal32(s):相当于Decimal(9-s,s),有效位数为1~9。Decimal64(s):相当于Decimal(18-s,s),有效位数为1~18 。Decimal128(s):相当于Decimal(38-s,s),有效位数为1~38。
Decimal(P, S)
: 定点数,P
表示总位数,S
表示小数位数。例如 Decimal(10, 2)
表示总共 10 位数,其中 2 位是小数。
有符号的浮点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)。使用场景:一般金额字段、汇率、利率等字段为了保证小数点精度,都使用Decimal进行存储。
String:字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
FixedString(N):固定长度N 的字符串,N 必须是严格的正自然数。当服务端读取长度小于N 的字符串时候,通过在字符串末尾添加空字节来达到N 字节长度。当服务端读取长度大于N 的字符串时候,将返回错误消息。
与String相比,极少会使用FixedString,因为使用起来不是很方便。使用场景是名称、文字描述、字符型编码。固定长度的可以保存一些定长的内容,比如一些编码,性别等但是考虑到一定的变化风险,带来收益不够明显,所以定长字符串使用意义有限。
包括Enum8 和Enum16 类型。Enum 保存'string'= integer 的对应关系。
Enum8 用'String'= Int8 对描述。Enum16 用'String'= Int16 对描述。
用法演示
创建一个带有一个枚举Enum8('hello' = 1, 'world' = 2) 类型的列。这个x列只能存储类型定义中列出的值:'hello'或'world。如果尝试保存任何其他值,ClickHouse 抛出异常。
CREATE TABLE t_enum(x Enum8('hello' = 1, 'world' = 2))ENGINE = TinyLog;
INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello');


使用场景
对一些状态、类型的字段算是一种空间优化,也算是一种数据约束。但是实际使用中往往因为一些数据内容的变化增加一定的维护成本,甚至是数据丢失问题。所以谨慎使用。
Date接受年-月-日的字符串比如‘2019-12-16’Datetime接受年-月-日时:分:秒的字符串比如‘2019-12-16 20:50:10’Datetime64接受年-月-日时:分:秒.亚秒的字符串比如‘2019-12-16 20:50:10.66’
日期类型,用两个字节存储,表示从1970-01-01 (无符号) 到当前的日期值。还有很多数据结构,可以参考最下方官方文档。
Array(T):由T 类型元素组成的数组。T可以是任意类型,包含数组类型,例如 Array(Int32)
表示一个包含 32 位整数的数组。但不推荐使用多维数组,ClickHouse 对多维数组的支持有限。例如,不能在MergeTree表中存储多维数组。
创建方式一:使用array函数 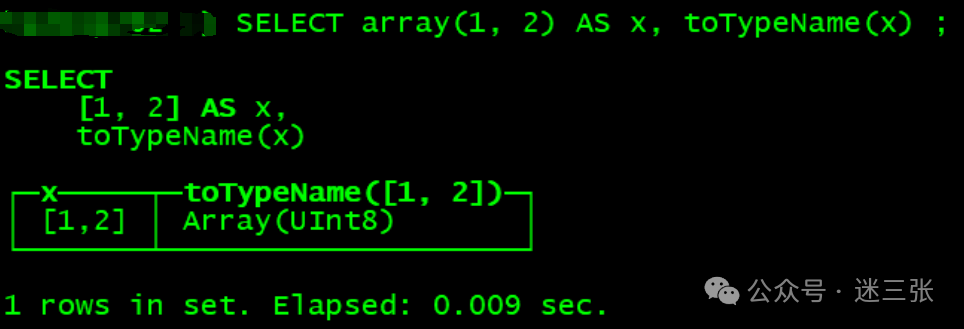
创建方式二:使用方括号 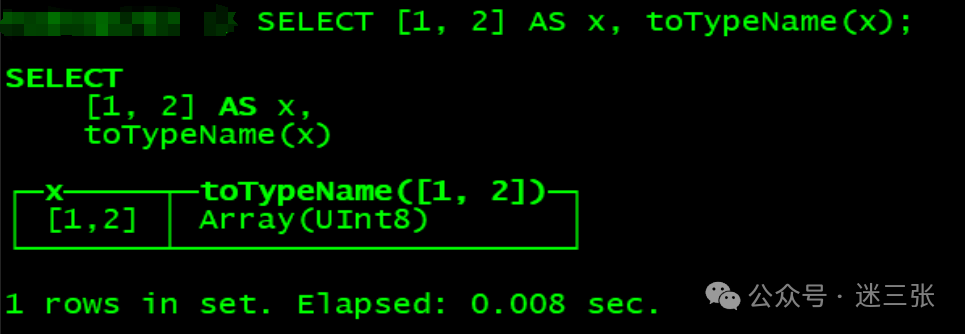
六、元组类型
Tuple(T1, T2, ...): 元组类型,可以存储多个不同类型的值。例如Tuple(String, Int32, Float64) 表示一个包含字符串、32 位整数和 64 位浮点数的元组。
用法演示一
CREATE TABLE user_profile (user_id UInt32,user_info Tuple(name String, age UInt8, email String),location Tuple(latitude Float64, longitude Float64)) ENGINE = MergeTree()ORDER BY user_id;
user_info
是一个元组,包含 name
(字符串)、age
(8 位整数)和 email
(字符串)。
location
是一个元组,包含 latitude
和 longitude
(64 位浮点数)。
INSERT INTO user_profile VALUES(1, ('Alice', 25, 'alice@example.com'), (37.7749, -122.4194)),(2, ('Bob', 30, 'bob@example.com'), (34.0522, -118.2437));
插入数据时,元组的值需要用括号 ()
括起来,并用逗号分隔。
SELECTuser_id,user_info.name,user_info.age,location.latitude,location.longitudeFROM user_profile;
┌─user_id─┬─name──┬─age─┬─latitude─┬─longitude─┐│ 1 │ Alice │ 25 │ 37.7749 │ -122.4194 ││ 2 │ Bob │ 30 │ 34.0522 │ -118.2437 │└─────────┴───────┴─────┴──────────┴───────────┘
可以通过 元组名.字段名
的方式访问元组中的具体字段。
用法演示二
SELECTuser_id,tuple(user_info.name, user_info.age) AS name_age,tuple(location.latitude, location.longitude) AS coordinatesFROM user_profile;
┌─user_id─┬─name_age──────────┬─coordinates────────────────────┐│ 1 │ ('Alice',25) │ (37.7749,-122.4194) ││ 2 │ ('Bob',30) │ (34.0522,-118.2437) │└─────────┴───────────────────┴───────────────────────────────┘
元组可以用于 临时存储多个值,例如在查询中组合多个字段。当然还有很多玩法,元组多层嵌套,元组作为函数参数等请查看最下方官网~~~~~~~。
使用场景
存储复合数据:当需要将多个相关的值组合在一起时,可以使用元组。例如,存储一个人的姓名和年龄,或者一个地理位置的经度和纬度。
简化表结构:如果某些字段总是成对或成组出现,可以将它们组合成一个元组,从而减少表的列数,使表结构更简洁。
函数返回值:某些 ClickHouse 函数会返回多个值,这些值可以存储在元组中。
临时数据结构:在查询中,元组可以用于临时存储多个值,方便后续处理。
没有单独的类型来存储布尔值。UInt8 通常用于表示布尔值,0
表示 False
,1
表示 True
。
八、Nullable 类型
Nullable(T)
: 允许存储 NULL
值的数据类型。T
可以是任意数据类型。例如 Nullable(Int32)
表示可以存储 32 位整数或 NULL
。
九、Map 类型
Map(key, value)
: 用于存储键值对的数据结构。key
和 value
可以是任意数据类型。
用法演示
CREATE TABLE user_setting (user_id UInt32,settings Map(String, String)) ENGINE = MergeTree()ORDER BY user_id;
settings
是一个 Map 类型,键和值都是字符串类型。
INSERT INTO user_setting VALUES(1, {'theme': 'dark', 'language': 'en', 'notifications': 'on'}),(2, {'theme': 'light', 'language': 'fr'});
插入数据时,Map 的值需要用花括号 {}
括起来,键值对用冒号 :
分隔,多个键值对用逗号 ,
分隔。
SELECTuser_id,settings['theme'] AS theme,settings['language'] AS languageFROM user_setting;
┌─user_id─┬─theme─┬─language─┐│ 1 │ dark │ en ││ 2 │ light │ fr │└─────────┴───────┴──────────┘
可以通过 Map字段['键']的方式访问 Map 中的具体值。INSERT INTO user_setting VALUES(1, {'theme': 'light', 'language': 'en', 'notifications': 'off'});SELECT * FROM user_settings WHERE user_id = 1;
┌─user_id─┬─settings────────────────────────────────────┐│ 1 │ {'theme':'light','language':'en','notifications':'off'} │└─────────┴────────────────────────────────────────────────────────┘
ClickHouse 不支持直接更新 Map 中的某个键值对,但可以通过插入新数据来覆盖旧数据
SELECTmapAdd({'a': 1, 'b': 2}, {'b': 3, 'c': 4}) AS added_map,mapSubtract({'a': 1, 'b': 2}, {'b': 3, 'c': 4}) AS subtracted_map,mapContains({'a': 1, 'b': 2}, 'b') AS contains_key;
┌─added_map──────────────┬─subtracted_map───┬─contains_key─┐│ {'a':1,'b':5,'c':4} │ {'a':1} │ 1 │└────────────────────────┴──────────────────┴──────────────┘
mapAdd
:合并两个 Map。
mapSubtract
:从一个 Map 中移除另一个 Map 的键。
mapContains
:检查 Map 是否包含某个键。
当然更多玩法map嵌套、map的更多函数请查看最下方官网~~~~~~~。
使用场景
动态属性存储:当某些对象的属性是动态的、不固定的,可以使用 Map 类型存储。例如,存储用户的个性化设置或产品属性。
标签或元数据存储:适用于存储对象的标签、分类或元数据。例如,存储文章的标签或商品的属性。
稀疏数据存储:当某些字段的值在大多数情况下为空时,可以使用 Map 类型来避免存储大量空值。
JSON 数据存储:如果数据是半结构化的(如 JSON),可以使用 Map 类型来存储。
临时数据处理:在查询中,Map 类型可以用于临时存储和处理键值对数据。
十、UUID 类型
UUID
: 用于存储 UUID(通用唯一标识符)。
示例
CREATE TABLE demo(id UInt32,name String,age UInt8,salary Decimal(10, 2),birth_date Date,created_at DateTime,is_active UInt8,tags Array(String),address Tuple(city String, zip_code String),ip_address IPv4,uuid UUID) ENGINE = MergeTree()ORDER BY id;
总结
ClickHouse 提供了丰富的数据类型来满足不同的数据存储需求。选择合适的数据类型可以提高存储效率和查询性能。在实际使用中,应根据数据的特性和查询需求来选择最合适的数据类型。
https://clickhouse.com/docs/zh/sql-reference/data-types
clickhouse数据类型官方地址

欢迎微信扫描二维码,关注我的公众号~~
