




引言
Chatbot Arena测评
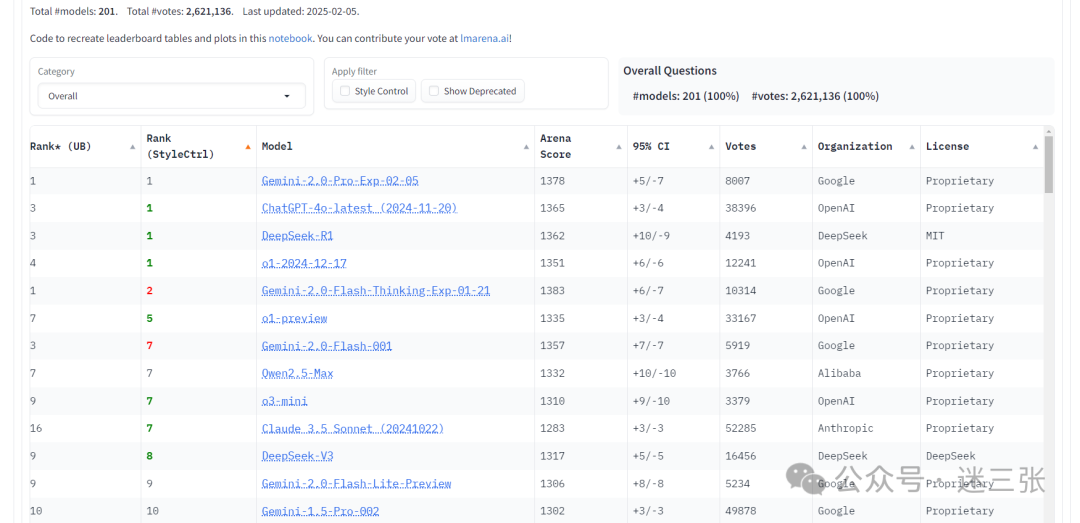
Chatbot Arena 是由 LMSYS Org 推出的大模型性能测试平台,目前集成了190多种模型。该榜单采用匿名方式将大模型两两组队,交给用户进行盲测,用户根据真实对话体验对模型能力进行投票。因此,Chatbot Arena LLM Leaderboard 成为业界公认的最公正、最权威榜单之一,也是全球顶级大模型的最重要竞技场。
Chatbot Arena 官方评价称:阿里巴巴的 Qwen2.5-Max 在多个领域表现强劲,特别是专业技术向的(编程、数学、硬提示等)。
全球榜单:数学和编程项目

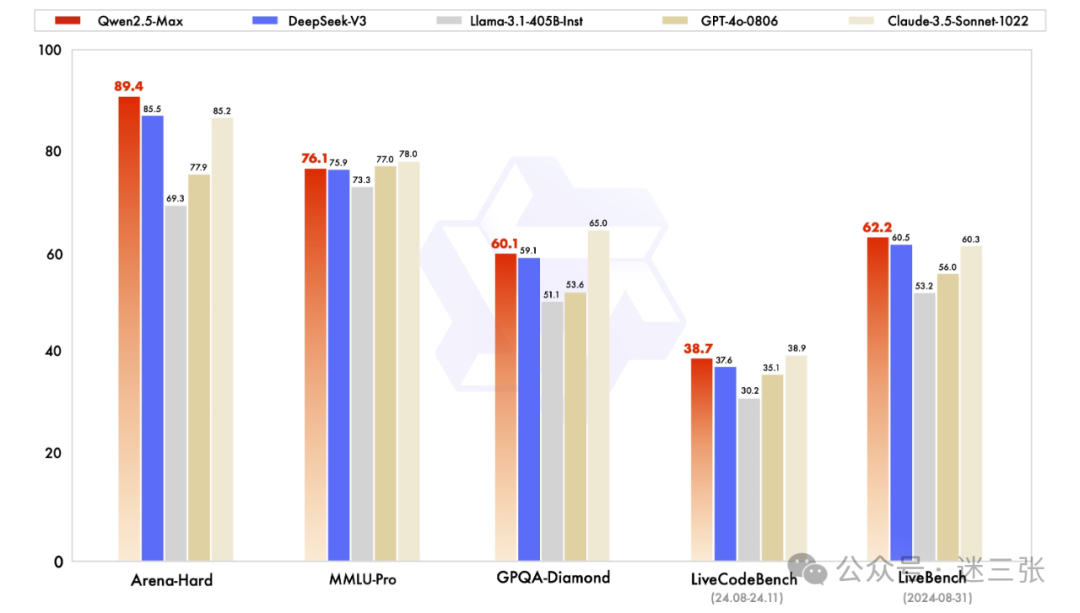
LiveBench 是由图灵奖得主、Meta 首席 AI 科学家杨立昆(Yann LeCun)联合 Abacus.AI、纽约大学等机构推出的第三方评测榜单。它以权威性和客观性著称,是当前 AIGC 领域最具公信力的评测之一。
与传统榜单不同,LiveBench 的题目每月更新,基于最新的 arXiv 论文、新闻文章、IMDb 电影概要等动态生成问题,避免了数据污染问题。因此,它被称为「全球首个无法被操纵的 LLM 基准测试。
总结
有从业者在惊叹新模型强大性能的同时,也兴奋地表示:“我们可以告别 ChatGPT 了!”。
小建议:
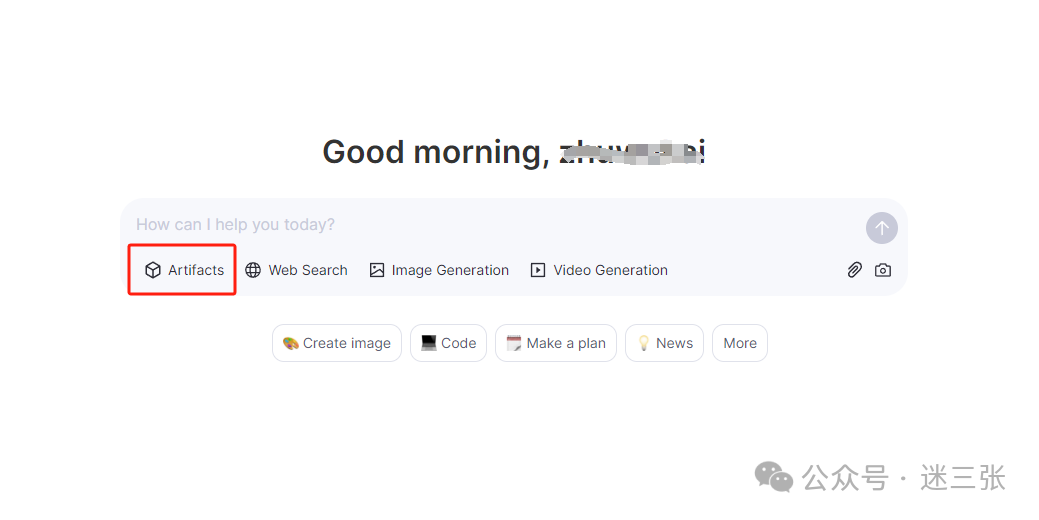
如果你准备跑一些在线运行的编程类问题,一定要勾选下面这个“Artifacts”功能。
体验
网页端:
https://chat.qwenlm.ai/
API 调用:
在阿里云百炼平台上可以直接调用 API 服务

欢迎微信扫描二维码,关注我的公众号~~
探索 AGI 的路上并不孤单,期望中国AI模型 DeepSeek 和 Qwen 携手并进,逐日摘星。
最后修改时间:2025-02-17 12:52:12
文章转载自迷三张,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
